Revised Multiple Zone Systems Tests
As summarized here, SANDAG staff (@wusun2) found that accessing TAP skims and MAZ to TAP pandas table data is much slower than accessing TAZ skims, which use direct position indexing. RSG staff (@toliwaga) made improvements to address this issue. This document describes test results of the improved software and comparisons of performance before and after the improvements.
The objectives of this effort are:
- Evaluate performance of improved software by mimicking SANDAG model settings as described in Multiple-Zone-Systems-Tests.
- Compare performances before and after software improvements.
- Summarize findings.
- Intel® Xeon® Processor E5-2650 v3 @ 2.30GHz; 256 RAM; 20 cores
- Windows Server 2012 R2 Std, 64-bit (SANDAG ABM server Highlander)
Tables 1 to 3 are performance summaries of each individual method by increasing test size from 10,000 to 50,000,000.
Table 1: Individual Method Performance before Software Improvements
| seconds | Before Software Improvements | ||||
|---|---|---|---|---|---|
| Test size | 10,000 | 100,000 | 1,000,000 | 10,000,000 | 50,000,000 |
| get_taz() | 0.008 | 0.048 | 0.722 | 40.92 | 1030.5 |
| get_tap() | 0.007 | 0.054 | 0.808 | 42.29 | 1030.3 |
| get_maz() | 0.023 | 0.183 | 1.695 | 53.53 | 1089.8 |
| taz_skims() | 0.004 | 0.034 | 0.326 | 3.36 | 18.8 |
| tap_skims() | 0.014 | 0.135 | 1.738 | 94.17 | 2188.7 |
| get_maz_pairs() | 2.867 | 1.213 | 5.367 | 78.57 | 1142.3 |
| get_maz_tap_pairs() | 0.084 | 0.244 | 1.928 | 50.73 | 1127.4 |
| get_taps_mazs() | 0.118 | 0.341 | 2.749 | 28.84 | 159 |
Table 2: Individual Method Performance after Software Improvements
| seconds | After Software Improvements | ||||
|---|---|---|---|---|---|
| Test size | 10,000 | 100,000 | 1,000,000 | 10,000,000 | 50,000,000 |
| get_taz() | 0.011 | 0.017 | 0.179 | 3.149 | 12.72 |
| get_tap() | 0.004 | 0.018 | 0.218 | 2.75 | 16.20 |
| get_maz() | 0.011 | 0.063 | 0.653 | 7.09 | 39.97 |
| taz_skims() | 0.004 | 0.031 | 0.326 | 3.29 | 17.20 |
| tap_skims() | 0.009 | 0.057 | 0.647 | 7.72 | 41.41 |
| get_maz_pairs() | 2.483 | 2.537 | 3.218 | 7.558 | 36.30 |
| get_maz_tap_pairs() | 0.06 | 0.088 | 0.397 | 4.715 | 28.42 |
| get_taps_mazs() | 0.101 | 0.326 | 2.643 | 28.572 | 163.49 |
Table 3: Individual Method Performance Before/After Comparisons
| ratio | Before Runtime/After Runtime | ||||
|---|---|---|---|---|---|
| Test size | 10,000 | 100,000 | 1,000,000 | 10,000,000 | 50,000,000 |
| get_taz() | 0.7 | 2.8 | 4.0 | 13.0 | 81.0 |
| get_tap() | 1.8 | 3.0 | 3.7 | 15.4 | 63.6 |
| get_maz() | 2.1 | 2.9 | 2.6 | 7.6 | 27.3 |
| taz_skims() | 1.0 | 1.1 | 1.0 | 1.0 | 1.1 |
| tap_skims() | 1.6 | 2.4 | 2.7 | 12.2 | 52.9 |
| get_maz_pairs() | 1.2 | 0.5 | 1.7 | 10.4 | 31.5 |
| get_maz_tap_pairs() | 1.4 | 2.8 | 4.9 | 10.8 | 39.7 |
| get_taps_mazs() | 1.2 | 1.0 | 1.0 | 1.0 | 1.0 |
Figure 1 Runtime before/after Software Improvement by Method (test size=50,000,000)

Tables 4 and 5 are performance summaries of each individual method per unit (10000) derived from Tables 1 and 2.
Table 4: Individual Method Performance per Unit (10000) before Software Improvements
| seconds | Before Software Improvements | ||||
|---|---|---|---|---|---|
| Test size | 10,000 | 100,000 | 1,000,000 | 10,000,000 | 50,000,000 |
| get_taz() | 0.0080 | 0.0048 | 0.0072 | 0.0409 | 0.2061 |
| get_tap() | 0.0070 | 0.0054 | 0.0081 | 0.0423 | 0.2061 |
| get_maz() | 0.0230 | 0.0183 | 0.0170 | 0.0535 | 0.2180 |
| taz_skims() | 0.0040 | 0.0034 | 0.0033 | 0.0034 | 0.0038 |
| tap_skims() | 0.0140 | 0.0135 | 0.0174 | 0.0942 | 0.4377 |
| get_maz_pairs() | 2.8670 | 0.1213 | 0.0537 | 0.0786 | 0.2285 |
| get_maz_tap_pairs() | 0.0840 | 0.0244 | 0.0193 | 0.0507 | 0.2255 |
| get_taps_mazs() | 0.1180 | 0.0341 | 0.0275 | 0.0288 | 0.0318 |
Table 5: Individual Method Performance per Unit (10000) after Software Improvements
| seconds | After Software Improvements | ||||
|---|---|---|---|---|---|
| Test size | 10,000 | 100,000 | 1,000,000 | 10,000,000 | 50,000,000 |
| get_taz() | 0.0110 | 0.0017 | 0.0018 | 0.0031 | 0.0025 |
| get_tap() | 0.0040 | 0.0018 | 0.0022 | 0.0028 | 0.0032 |
| get_maz() | 0.0110 | 0.0063 | 0.0065 | 0.0071 | 0.0080 |
| taz_skims() | 0.0040 | 0.0031 | 0.0033 | 0.0033 | 0.0034 |
| tap_skims() | 0.0090 | 0.0057 | 0.0065 | 0.0077 | 0.0083 |
| get_maz_pairs() | 2.4830 | 0.2537 | 0.0322 | 0.0076 | 0.0073 |
| get_maz_tap_pairs() | 0.0600 | 0.0088 | 0.0040 | 0.0047 | 0.0057 |
| get_taps_mazs() | 0.1010 | 0.0326 | 0.0264 | 0.0286 | 0.0327 |
Figure 2 Method get_taz() Runtime per Unit (10000) before/after Software Improvement

Figure 3 Method tap_skims() Runtime per Unit (10000) before/after Software Improvement
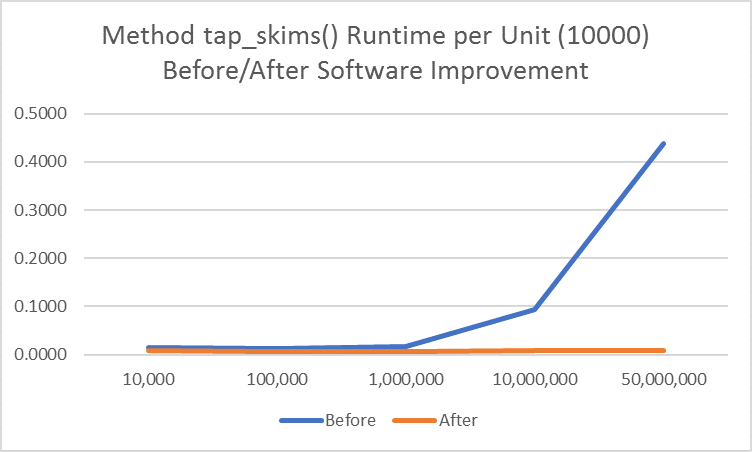
Table 6 is a performance summary by model component.
Table 6: Method Performance by Model Component
| Model Component | Relevant Methods | Test Size | Before | Before | After | After | Before/After |
|---|---|---|---|---|---|---|---|
| sec. | hr. | sec. | hr. | ||||
| Mandatory tour mode choice | taz_skims() | 68,374,080 | 24 | 0.01 | 23 | 0.006 | 1.0 |
| Stop location choice | get_maz_pairs() | 1,522,047,900 | NA | 1537 | 0.427 | NA | |
| Trip mode choice scenario 1 | taz_skims() | 568,231,216 | 209 | 0.06 | 220 | 0.061 | 0.9 |
| get_maz_pairs() | 5,073,493 | 36 | 0.01 | 5 | 0.001 | 6.9 | |
| best transit path | 1,014,699 | 23391 | 6.5 | 313 | 0.087 | 74.7 | |
| Total | ** ** | 23636 | 6.57 | 539 | 0.150 | 43.9 | |
| Trip mode choice scenario 2 | taz_skims() | 568,231,216 | 209 | 0.06 | 220 | 0.061 | 0.9 |
| get_maz_pairs() | 10,146,986 | 83 | 0.02 | 9 | 0.003 | 8.9 | |
| best transit path | 2,536,747 | NA | 887 | 0.246 | NA | ||
| Total | ** ** | ** ** | ** ** | 1116 | 0.310 | NA | |
| Trip mode choice scenario 3 | taz_skims() | 568,231,216 | 209 | 0.06 | 220 | 0.061 | 0.9 |
| get_maz_pairs() | 12,176,383 | 114 | 0.03 | 11 | 0.003 | 10.5 | |
| best transit path | 3,348,505 | NA | 1187 | 0.330 | NA | ||
| Total | ** ** | ** ** | ** ** | 1419 | 0.394 | NA | |
| Trip mode choice scenario 4 | taz_skims() | 568,231,216 | 209 | 0.06 | 220 | 0.061 | 0.9 |
| get_maz_pairs() | 15,220,479 | 161 | 0.04 | 13 | 0.004 | 12.6 | |
| best transit path | 5,073,493 | NA | 1906 | 0.530 | NA | ||
| Total | ** ** | ** ** | ** ** | 2140 | 0.594 | NA |
- For most tested methods, the improved software is 30-80 times faster, including get_taz(), get_tap(), get_maz(), tap_skims(), get_maz_pairs(), and get_maz_tap_pairs().
- In the previous tests, performance of most methods deteriorates when test size increases. This issue has been solved; runtime increases linearly as test size increases.
- Although method taz_skims() has a similar performance as before, it is not a bottleneck because it is fast even before the code improvements.
- Method get_taps_mazs() also has similar performance as before, indicating the need for further improvement. See issue #167.
- Two model components, stop location and trip mode choices are identified as bottlenecks in the previous tests. We were not able to complete most of the test scenarios that mimic SANDAG settings, except one trip mode choice scenario, due to the extreme runtime. With the software improvements, all tests finished within reasonable runtime, more specifically:
- We were not able to complete stop location choice test with 1,522,047,900 get_maz_paris() calls before. Now the runtime is less than 0.5 hour.
- We were not able to complete 3 of the 4 trip mode choice tests when transit virtual path building (TVPB) procedure calls are set to 2,536,747, 3,348,505, and 5,073,493. Now these tests finish in 0.3, 0.4, and 0.6 hour respectively.
- Although the TVPB is implemented like the one in CT-RAMP, the TVPB expression is simplified with no probability computation and no Monte Carlo choice. To have a better understanding of the performance of trip mode choice, a critical component, it is recommended to expand TVPB with a more realistic expression, probability computation, and Monte Carlo choices.