-
Why do we need containers?
So that all services we need should be in isolated environments and it can be shipped and installed with the same config as developed.
-
What are containers?
Containers are completely isolated environments.They have their own processes, own network interfaces and their own mount like VM. But they share the same OS kernel.
-
What is container orchestration?
Process of deploying and managing containers is called container orchestartion. It monitors if container is up/down and also help in automatically scale up/down based on the load.
-
Advantage of container orchestration?
-
Application is highly available as hardware failure will not bring down the application as there are multiple instances of application running on different nodes.
-
User traffic is load balances across various containers.
-
When demand increases, deploy more instances of applications within seconds.
-
Also can be done at service level when run out of hardware resources and scale the underlying nodes up/down without taking down the application.
-
All these can be done with the help of set of declerative config file which is know as kubernetes.
-
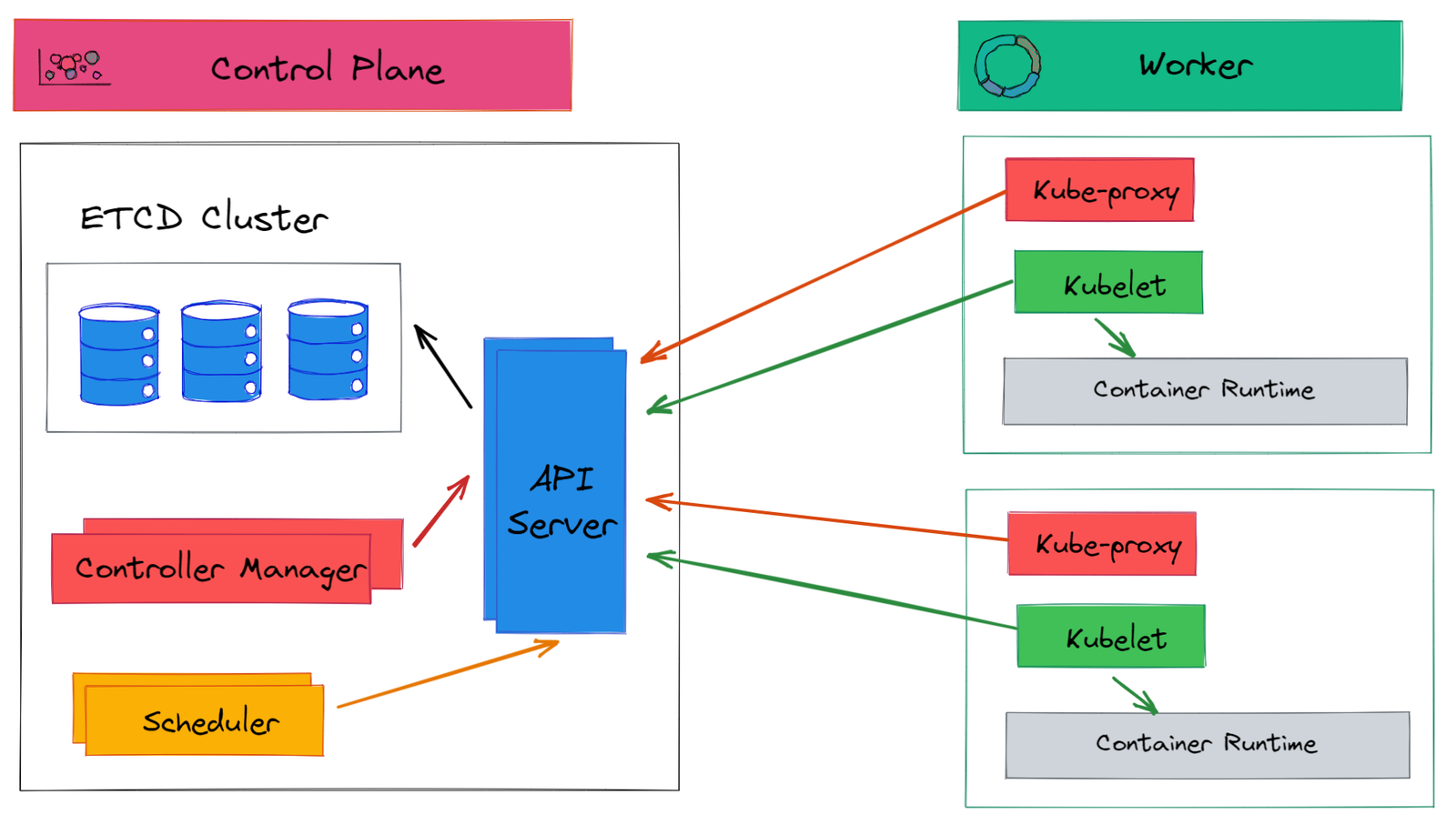
How kubernetes actually works?
- When a user request to create a pod
- kube-api-server creates the pod as per the requirements
- then kube scheduler decides which node to assign for the pod based on several criterias
- then kube-api-server request kublet of the node to schedule the pod
- then kublet request Container Runtime(like Docker) to create the POD
- then kubelet replies to kube-api-server with status of the pod created
- then kube-api-server update the etcd about pod creation, on which node pod is created and other information
-
What is kubernetes?
It is an orchestration technology used to orchestrate deployment and management of hundred or thousands of container in clustered environment.
-
What are nodes?
It is a machine, physical or virtual on which kubernetes is installed. It is a worker machine where containers will be launched by kubernetes.
-
What are clusters?
It is a set of nodes grouped together.This way if one node fails your application will be still accessible from other nodes. Having multiple nodes helps in sharing the load as well.
We can setup clusters on local or cloud:
Local Cluster setup:
- Minikube: Single node, Used for educational purposes.
- Kubeadm: Multinode with single master, Used for development and testing purpose
Cloud Cluster Setup:
- Azure
- GCP
- AWS
-
What are Master Node?
It is another node with kubernetes installed and is configured as Master. The master watches over the nodes in cluster and is responsible for actual orchesteration of containers on the worker nodes.
-
What components we get after installing kubernetes on the system?
An API Server, etcd service, a kubelet service, a Container Runtime, Controllers and Schedulers.
-
What is an API Server?
It acts as the frontend for kubernetes. The users, management devices, command line interfaces all talk to API server to interact with kubernetes cluster.
-
What is an etcd key store?
It is a distrbuted reliable key value store by Kubernetes to store all data used to manage the cluster. When you have multiple nodes and multiple Masters in your cluster, etcd stores all that information is a distributed manner. It is also responsible for implementing locks within cluster to ensure that there are no conflicts between the masters.
-
What are Kube Scheduler?
The Kubernetes scheduler is a control plane process which assigns Pods to Nodes. The scheduler determines which Nodes are valid placements for each Pod in the scheduling queue according to constraints and available resources.
-
What are controllers?
They are brain behind orchesteration. The are reponsible for noticing and responding when nodes,container or end points goes down. It makes decisions to bring up new containers in such cases.
-
What is Container Runtime?
They are underlying software used to run containers. Ex. Docker.
-
Whate is kubelet?
It is an agent that runs on each node in the cluster. It is responsible for making sure containers are running on the nodes as expected.
-
Whate is kubectl?
It is a command line tool which is used to deploy and manage applications on a kubernetes cluster. To get the cluster information, to get the status of other nodes in the cluster.
kubectl run command is used to deploy an application on the cluster.
kubectl run hello-minikube -
Steps to setup Kubernetes:
- Install kubectl
- Intall minikube and start it
-
What are pods?
A Pod is the smallest deployable unit in Kubernetes, representing a single instance of an application.
Containers are not directly deloyed on the worker node by kubernetes. It is encapsulated with an object call pods. Pods is the smallest object in the kubernetes.
Each pod gets an internal IP of its own within kubernetes cluster
-
What should we do when more resources are added?
-
Create a new container instance within same pod
-
Create a new pod with new container instance of the same application
Pods usually have one to one relationship with containers running your application.
We can create multiple container in a single pod if both are of different kind.(Example helper container)
For scaling purpose we should always create new pod with new instance of container of same application.
-
-
Command to create pod using kubectl :
kubectl run nginx --image=nginxThis command will create a new pod with name nginx using docker image named nginx(from docker hub)
-
What is a Deployment in Kubernetes?
A Deployment in Kubernetes is a higher-level abstraction that manages the deployment of multiple Pods. It ensures that a specified number of replica Pods are running at any given time and allows for rolling updates and rollbacks. Deployments provide a declarative way to manage the state of applications and ensure consistency across environments.
-
What is a Service in Kubernetes?
Services enable communication between different parts of an application and provide load balancing and service discovery. They ensure that Pods are discoverable and accessible from other parts of the application, even if they are running on different nodes or have dynamic IP addresses.
-
What is a Kubernetes namespace?
It provides a way to partition and isolates resources within a cluster, allowing multiple teams or applications to share the same physical infrastructure. Namespaces provide a way to organize and manage resources based on their logical grouping and enable role-based access control and resource quotas.
- Names of resources need to be unique within a namespace, but not across namespaces.
- Namespaces cannot be nested inside one another and each Kubernetes resource can only be in one namespace.
- Not all objects are in a namespace like nodes and persistentVolumes
Initial namespaces:
- default: Its the default namespace assigned when no namespace is provided
- kube-system:
- kube-system is the namespace for objects created by the Kubernetes system.
- We should avoid putting anything personal in that namespace.
- It would contain pods like kube-dns, kube-proxy, kube-API, and others controllers.
- kube-public:
- Used for public resources and readable by all users
- This namespace is mostly reserved for cluster usage not recommended for other Kubernetes users.
- It contains the configmap that has cluster information.
- kube-node-lease:
- This namespace holds the heartbeats of nodes and each node is associated to lease object in the namespace.
- Node leases allow the kubelet to send heartbeats so that the control plane can detect node failure.
- It determines node availability.
Namespaces communicate with each other using the fully qualified domain name (FQDN).
<service-name>.<namespace-name>.svc.cluster.local -
What is a Kubernetes controller?
A Kubernetes controller is a core component of Kubernetes that manages the state of a cluster. It monitors resources in the cluster and ensures that the desired state is maintained, reconciling any discrepancies that arise. Controllers provide a declarative way to manage resources and ensure consistency across the cluster. Examples of controllers include Deployments, ReplicaSets, StatefulSets, and Jobs.
-
What is a StatefulSet in Kubernetes?
It ensures that each instance has a stable and unique hostname, persistent storage, and ordered deployment and scaling. StatefulSets provide a way to manage stateful applications in a declarative and consistent manner, enabling applications to be scaled up or down dynamically.
-
What is a ConfigMap in Kubernetes?
It provides a way to store key-value pairs, files, or command-line arguments that your application needs to run. ConfigMaps are typically used to store configuration data that is likely to change, such as database connection strings or environment variables. They enable you to manage configuration data separately from the application code, making it easier to update and maintain.
-
What is a Secret in Kubernetes?
It provides a secure way to store and distribute sensitive data to your application without exposing it to other parts of the system. Secrets are typically used to store credentials, TLS certificates, or other sensitive information that your application needs to function. They are encrypted at rest and can be mounted as files or environment variables in your application containers.
-
What is the difference between a DaemonSet and a Deployment in Kubernetes?
A DaemonSet in Kubernetes ensures that a Pod is running on all nodes in a cluster, while a Deployment manages the deployment of multiple Pods and ensures a specified number of replica Pods are running at any given time.
PODS with YAML:
It has 4 root level mandatory properties:
- apiVersion > Version of Kubernetes API using to create the objects. Ex: v1,apps/v1
- kind > Refers type of object. Ex: Pod,Service, ReplicaSet, Deployment
- metadata > Data about the objects. Ex: name,labels. Metadata does not accept any key-value pair, it should be some specific values
- spec > Additional information regarding object to be created
Example for pod YAML file:
// test.yml
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
-
To create pod using yaml file we use command:
kubectl apply -f test.yml -
To get information about pods:
kubectl get pods -
To get information of specific pod:
kubectl describe pod myapp-pod
REPLICATION CONTROLLER AND REPLICA SET
Replication Controller: It helps in running muliple instances of a single pod in kubernetes cluster, thus providing high availibilty. It make sure that that number of pods always exists.
-
It also helps in creating multiple pods to share the load across them.
-
If no. of users increases then we will deploy additional pod to balance the load across the two pods.
-
If further demand increases and we run out of resources on the first node we could deploy additional ports on other nodes in the cluster.
Replica Set:
-
Replicaset is interlinked with image version, if image version is changed then new replicaset will be created and old will be not deleted but its pod will be deleted
-
Only 1 replicaset will be active per deployment
-
ReplicaSet manages pods , if one pods goes down then it will create new pods
-
It will always try to match desired pod, even if you delete a pod it will be recreated to match the desired number of pods
-
To forcefully delete a pod use :
--grace-period=0 --forceProblems with Replicaset:
- Downtime if we change version of pods. It deletes all pods then create new pods
- Cannot rollback to previous version
ClusterIP: Accessible within the cluster
A ClusterIP service is the default Kubernetes service. It gives you a service inside your cluster that other apps inside your cluster can access. There is no external access.
We can access using Kubernetes proxy!
$ kubectl proxy --port=8080-
When to use:
- Debugging your services, or connecting to them directly from your laptop for some reason
- Allowing internal traffic, displaying internal dashboards, etc.
-
Drawbacks: This method requires you to run kubectl as an authenticated user, you should NOT use this to expose your service to the internet or use it for production services.
NodePort: Accessible from outside but only in the same network.
A NodePort service is the most primitive way to get external traffic directly to your service. NodePort, as the name implies, opens a specific port on all the Nodes (the VMs), and any traffic that is sent to this port is forwarded to the service.
-
When to use: If you are running a service that doesn’t have to be always available, or you are very cost sensitive, this method will work for you.
-
Drawbacks:
- You can only have one service per port
- You can only use ports 30000–32767
- If your Node/VM IP address change, you need to deal with that
LoadBalancer:
A LoadBalancer service is the standard way to expose a service to the internet. On GKE, this will spin up a Network Load Balancer that will give you a single IP address that will forward all traffic to your service.
-
When to use: If you want to directly expose a service, this is the default method. All traffic on the port you specify will be forwarded to the service. There is no filtering, no routing, etc. This means you can send almost any kind of traffic to it, like HTTP, TCP, UDP, Websockets, gRPC, or whatever.
-
Drawbacks: Each service you expose with a LoadBalancer will get its own IP address, and you have to pay for a LoadBalancer per exposed service, which can get expensive!
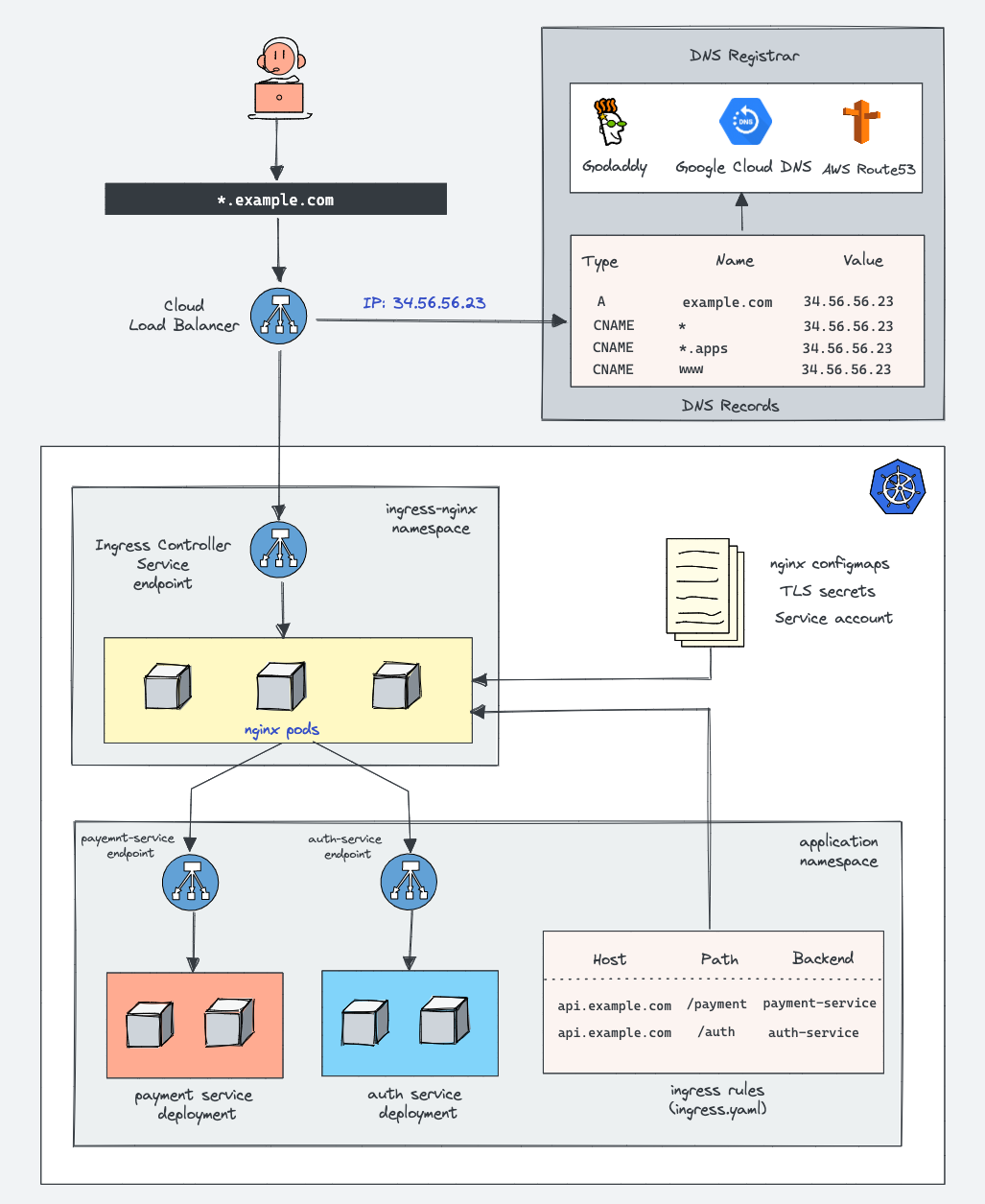
Ingress:
-
API object in k8s
-
Expose HTTP and HTTPS routes from outside the cluster
-
Path based routing and host based routing
-
Load Balancing and SSL Termination
-
Types of Ingress controllers: the Google Cloud Load Balancer, Nginx, Contour, Istio,etc.
-
Plugins for Ingress controllers, like the cert-manager, that can automatically provision SSL certificates for your services.
Advantages:
Ingress is the most useful if you want to expose multiple services under the same IP address, and these services all use the same L7 protocol (typically HTTP). You only pay for one load balancer if you are using the native GCP integration, and because Ingress is "smart" you can get a lot of features out of the box (like SSL, Auth, Routing, etc)
-
SSL Termination: For enabling it we have to perform various steps:
- Install cert-manager in cluster
- Create Issuers: Issuers and Cluster Issuers are kubernetes resources that represent certificate authorities (CA) that are able to generate signed certificates (ex. stage-issuer)
- Update Ingress Resources(annotations and tls)
- Create prod issuer
Kubernetes Security :
There are different types of users accessing this clusters- The admin, developers , end user accessing the application and other third party applications accessing the cluster for integration purpose.
We have 2 types of users -
- Admin/Developers — User
- BOTS — Services/Process/Applications — Service Account
Kubernetes doesn’t manage the user account natively, it depends on external source like — file with user details, ldap , certificates to manage the users.
kubectl create user user1 //errorkubectl create serviceaccount sa1 //workingAll user access in kubernetes is managed by API Server whether we access using the kubectl tool or through API call all request go through the Kube-api server. The Kube api server Authenticate the request and process further.
-
Authentication:
- Static password file : Username name password in static password file.
- Static token file: User name and token in static token file.
- Certificates : Authenticate using certificates.
- Identity services: Like ldap.
-
Authorization:
- Node: the kubelet access the Kube-API server to Read- Services , endpoints, nodes , pods and also to Write the node status, Pod status ..etc. These requests are handled by special Authorizer called — Node Authorizer.
- ABAC (Attributes based Authorization): Associate user with some set of permission. In this for multiple users we have to create multiple rules for it.
- RBAC (Role Based Authorization): In RBAC , instead of directly associating a users or group to specific permission we define a Role. Whenever a change is required to user access, we can just modify role and it will immediately reflect for all users.
- Webhook: An external service for authorization.
Kubernetes RBAC :
RBAC (Role-Based Access Control) allows you to control access to resources within the cluster based on user roles and permissions.
Role :
A Role always sets permissions within a particular namespace; when you create a Role, you have to specify the namespace it belongs in.
The role.yaml file contains the configuration for creating a role named pod-reader. The role allows the user to perform actions like get, watch, and list on pods resources.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]To apply this role:
kubectl apply -f role.yamlTo check the created role:
kubectl get roleRole Binding :
The rolebinding.yaml file defines a role binding named read-pods that binds the pod-reader role to the user jack in the default namespace.
apiVersion: rbac.authorization.k8s.io/v1
# This role binding allows "jane" to read pods in the "default" namespace.
# You need to already have a Role named "pod-reader" in that namespace.
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
# You can specify more than one "subject"
- kind: User
name: jane # "name" is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
# "roleRef" specifies the binding to a Role / ClusterRole
kind: Role #this must be Role or ClusterRole
name: pod-reader # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.ioTo apply this role binding:
kubectl apply -f rolebinding.yamlTo check the created role binding:
kubectl get rolebindingTo check the permissions of the jack user:
kubectl auth can-i get pod --as jackCluster Role:
ClusterRole, by contrast, is a non-namespaced resource.
ClusterRoles have several uses. You can use a ClusterRole to grant access to:
- cluster-scoped resources (like nodes)
- non-resource endpoints (like /healthz)
- namespaced resources (like Pods), across all namespaces
The clusterrole.yaml file contains the configuration for creating a cluster role named secret-reader. This cluster role allows the user to perform actions like get, watch, and list on secrets resources.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
- apiGroups: [""]
#
# at the HTTP level, the name of the resource for accessing Secret
# objects is "secrets"
resources: ["secrets"]
verbs: ["get", "watch", "list"]To apply this cluster role:
kubectl apply -f clusterrole.yamlTo check the created cluster role:
kubectl get clusterroleRole Binding (Namespace-level): The rolebinding.yaml file defines a role binding named read-secrets that binds the secret-reader cluster role to the user dev in the development namespace.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-secrets
namespace: development
subjects:
- kind: User
name: dev
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.ioTo apply this role binding:
kubectl apply -f rolebinding.yamlTo check the created role binding:
kubectl get rolebindingTo check the permissions of the dev user in the development namespace:
kubectl auth can-i get secret --as dev -n developmentCluster Role Binding : The clusterrolebinding.yaml file contains the configuration for creating a cluster role binding named read-secrets-global. This cluster role binding binds the secret-reader cluster role to the user riya globally.
apiVersion: rbac.authorization.k8s.io/v1
# This cluster role binding allows anyone in the "manager" group to read secrets in any namespace.
kind: ClusterRoleBinding
metadata:
name: read-secrets-global
subjects:
- kind: User
name: manager # Name is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.ioTo apply this cluster role binding:
kubectl apply -f clusterrolebinding.yamlTo check the created cluster role binding:
kubectl get clusterrolebindingTo check the permissions of the riya user across all namespaces:
kubectl auth can-i get secret --as manager -AImportant Note:
After you create a binding, you cannot change the Role or ClusterRole that it refers to. If you try to change a binding's roleRef, you get a validation error. If you do want to change the roleRef for a binding, you need to remove the binding object and create a replacement.
Network Policy :
The Kubernetes Network Policy lets users define a policy to control network traffic. By applying it, we can allow or restrict the traffic to/from any pod.
Network policies can be thought of as the firewall. However, Kubernetes lacks in an integrated ability to implement the network policy. To implement the network policy, we need to use a network plugin.
Supported plugins:
- Calico
- Cilium
- Kube-router
- Romana
- Weave Net
Unsupported plugins:
- Flannel
A Network Policy can work on all the pods within a namespace or we can use selectors to apply the rules to pods with a specific label. The Network policy can be applied to ingress as well as egress traffic.
By means of ingress and egress rules, we can define the incoming or outgoing traffic rules from/to:
- Pods with a specific label
- Pods belonging to a namespace with a particular label
- A combination of both rules restricts the selection of labelled pods in labelled namespaces
- Specific IP ranges
Ingress and Egress : We can secure the networking traffic by applying the ingress and egress rules to the Network Policy in Kubernetes.
- Ingress is incoming traffic to the pod.
- Egress is outgoing traffic from the pod.
Container Network Interface(CNI):
In Kubernetes, each Pod is assigned a unique IP address and can communicate with other Pods without requiring NAT. To provide networking to Pods, Kubernetes uses Container Network Interface (CNI), a library for configuring network interfaces in Linux containers.
The kubelet is responsible for setting up the network for new Pods using the CNI plugin specified in the configuration file located in the /etc/cni/net.d/ directory on the node.
The required CNI plugins referenced by the configuration should be installed in the /opt/cni/bin directory, which is the directory used by Kubernetes to store the CNI plugin binaries that manage network connectivity for Pods.
Pod Networking:
Base on the Kubernetes network model, the key concepts for Pod networking in Kubernetes include:
- Each Pod has a unique cluster-wide IP address.
- Pods can communicate with all other Pods across nodes without NAT.
- Agents on a node can communicate with all Pods on that node.

AutoScaling in Kubernetes
Autoscaling is a method that dynamically scales up / down the number of computing resources that are being allocated to your application based on its needs.

For Horizontal Pod Autoscaler ( HPA ) and Vertical Pod Autoscaler ( VPA ) to work it requires the metrics to be exported from the kubelet.
Metrics Server collects resource metrics from Kubelets and exposes them in Kubernetes apiserver through Metrics API for use by Horizontal Pod Autoscaler and Vertical Pod Autoscaler.
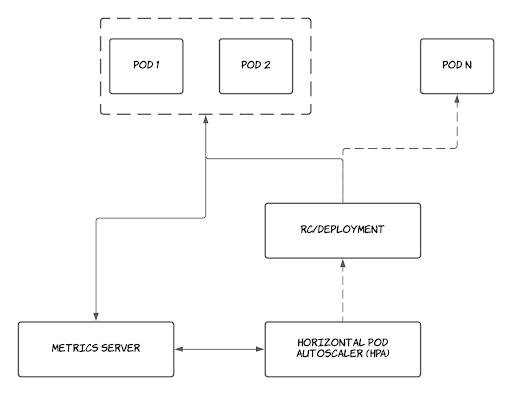
Horizontal Pod Autoscaler (HPA):
Horizontal Pod Autoscaler scales the number of Pods in a Deployment, Statefulset, ReplicaSet based on CPU/Memory utilization or any custom metrics exposed by your application.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: k8s-autoscaler
spec:
maxReplicas: 10
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: k8s-autoscaler
targetCPUUtilizationPercentage: 50So this HPA says that the deployment k8s-autoscaler should have a minimum replica count of 2 all the time, and whenever the CPU utilization of the Pods reaches 50 percent, the pods should scale to 10 replicas. And when the CPU utilization comes below 50 percent the replicas will scale back to 2.
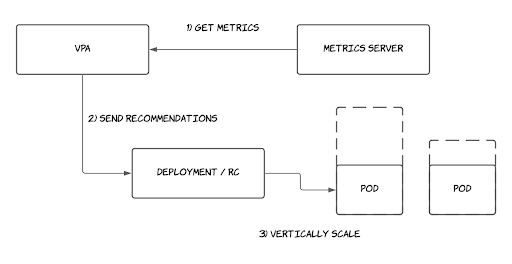
Vertical Pod Autoscaler (VPA):
Vertical Pod Autoscaler (VPA) automatically adjusts the CPU and Memory attributes for your Pods. The Vertical Pod Autoscaler (VPA) will automatically recreate your pod with the suitable CPU and Memory attributes. This will free up the CPU and Memory for the other pods and help you better utilize your Kubernetes cluster.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: k8s-autoscaler-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: k8s-autoscaler
updatePolicy:
updateMode: "Auto"The above Vertical Pod Autoscaler (VPA) says to automatically recreate the pods in the deployment with the CPU/Memory values given by Vertical Pod Autoscaler (VPA). If the updateMode is set to "Off" it will only give us the recommendations but it will not update the pods (in the deployments) automatically.
The VPA comes with a tool called VPA Recommender, which monitors the current and past resource consumption and use this data to provide recommended CPU and memory resources to be allocated for the containers.
There is a limitation with this approach. If you create a Vertical Pod Autoscaler with an updateMode of "Auto", the VerticalPodAutoscaler evicts a Pod if it needs to change the Pod’s resource requests. This may cause the pods to be restarted all at once causing inconsistency in our application. To limit the restarts and to maintain consistency this situation can be handled by PodDisruptionBudget (PDB’s).
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: k8s-autoscaler-pdb
spec:
minAvailable: 1
selector:
matchLabels:
run: k8s-autoscalerThis PDB ensures that the 1 replica of the deploy k8s-autoscaler runs all the time without any restarts. This will eventually ensure that our application is highly available and consistent across various cluster disruptions.
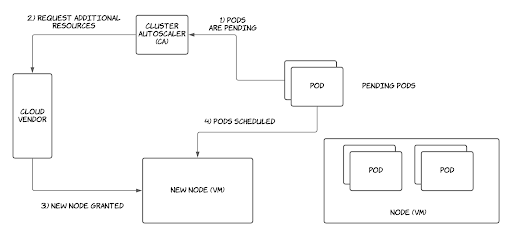
Cluster Autoscaler:
Cluster Autoscaler is a mechanism for scaling Kubernetes resources at the infrastructure level according to a given set of scaling rules. It works by constantly monitoring cluster status, and making infrastructure-level scaling decisions.
In Cluster Autoscaler, infrastructure-level scaling is triggered when one of the following events occur:
- Kubernetes pods go into a pending state in the cluster without being able to be scheduled into a node due to insufficient memory or CPU. This triggers scaling up with new nodes being provisioned.
- Kubernetes nodes are underutilized and the workloads running in those nodes can be safely rescheduled into another existing node. This triggers scaling down and removing provisioned nodes.