Repository for generating art using deep convolutional generative adversarial networks and convolutional variational autoencoder where training data is scraped from wikiart.
The motivation behind this small project is to explore the capabilities of generative adversarial networks and variational autoencoders in order to create new (fake) artificial images based on historical/available image data. In order to get to know the idea behind GANs have a look at this blogpost.
In contrast to Variational Autoencoders the generative adversarial network has a more different architecture where a generator (who will create fake images) and discriminator (who will decide whether an image is fake or not) are trained simultaneously in a stacked/adversarial network optimizing some min-max-criterion:
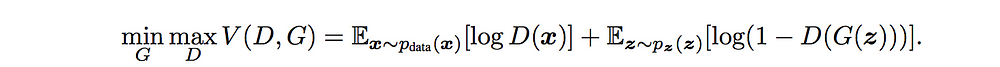
Whereas the variational autoencoder consists of encoder mapping the input data
As metric to be optimize one tries to minimize the Kullback-Leibler divergence when approximating p(z|x) with q(z|x). Hence we gain following loss function:

In both, DCGAN and VAE the default dimension of the latent space is 100.
The repository-folder is structured onto 3 folders named data, source, model and sample_generated_images (for documentation).
-
In
datathe scraped training images are stored. -
In
sourceall python-scripts are stored. There are 8 following scripts:data_scraping.py: this script fetches images from a specific wikiart genre and/or from a specific style . Currently the genre scraped is yakusha-e and style is Japanese Art.data_preprocess.py: this script executes some preprocessing steps like merging all images into onenumpy.ndarrayand scaling all images onto one shape, such that the deep learning algorithm can be trained in the next step. The default rescaling is range (128,128).__init__.py: this script exists in order to load class objects fromdcgan.pyandvae.pyintrain_model.py.dcgan.py: this script creates a DCGAN class object which itself consists of 3 generator and discriminator architectures.vae.py: this script creates a VAE class object which itself consists of 4 encoder and decoder architectures.try_init_models.py: this scripts is just for testing and initiates the 7 models in the main function when executing this script in the shell.train_model.py: this script initiates a generative model and trains it on the scraped data. In order to get good results I manually merged data fromyakusha-eandJapanese Artsubdirectory indataintodata/merged_japanese. Hence the data will be taken from this subdirectory. By default the second VAE model and trains it on 500 epochs with a batch size of 16 images. Every 250 epochs the model will be saved and images from the current model generated. Thetrain_model.pyhas several input arguments when exeuting in shell. Those are:{'model' = "VAE_2,'init_train' = True, start_epoch = 0,'cycle' = 1, 'epochs' = 500, 'batch_size'= 16,'save_intervals' = 250}create_batch_file.py: In order to overcome memory errors when training on a higher epoch and batch size, I came up with the idea to split the desired number of running epochs into chunks. E.g defining epochs=20000 and due to memory error one can only execute with tensorflow backend 500 epochs each, those 20000 epochs will be split into equal sized chunks of 500. Hence, this script creates a batch file for executing thetrain_model.pywith a desired number of epochs and batch size. Note that this procedure with training has to be tried out manually, to see how much your computer can process (e.g how many epochs in one exeuction run and what the most number of epochs is). For all 7 models a batch size of 16 and epochs of 500 were sufficient and alright. Going up with the number of epochs and batch size has led to memory error. -
In
modeldepending on the selected model[DCGAN_1, DCGAN_2, DCGAN_3, VAE_1, VAE_2, VAE_3, VAE_4]a subdirectory with the modelname will be created and there the weights for generator/encoder and discriminator/decoder networks saved. Thetrain_model.pyif executing with default arguments saves every 250 epochs the weights and 4 images of the current generative model. If the final epoch is reached, 10 images of the current generative model are generated in full-mode (128 x 128).
Hence, the model folder also contains the development of how the generative models are trained with respect to its weights, such that it should generate images which resemble the original training images. Note that the model weights are not uploaded on GitHub (see .gitignore file) because they are together too large. If you wish to work with my final weights, please contact me via eMail: [email protected]
Data is scraped from wikiart in the python-script data_scraping.py. In this version the genre yakusha-e is selected as genre and the style is Japanese Art, since I was/am interested into asian arts and there are not so many images available in the wikiart database. If you want to scrape another genre, simply change the string variable in line 98 genre_to_scrape = "yakusha-e" to any other genre of interest and or the style at line 131 style_to_scrape = "Japanese Art".
After scraping the yakusha-e and Japanese Art images are stored onto my local machine.
Here are some scraped image (in original size):




The generated images from both VAE and DCGAN unfortunately do not really resemble the yakusha-e genre, more an abstract version of it. I believe this lays in the complex structure of the input images. Even after rescaling from first (256,256) to shape (128,128) the results the results are still more abstract.
With this data base the VAE performs better generating artificial images than the DCGAN.
As an example below some output of the VAE_2 Model:




For the VAE find below the generated images over the epochs: [1000, 3000, 5000, 7000 , 10000, 12000, 15000, 20000, 22000, 25000]:
Epoch 1000:

Epoch 3000:

Epoch 5000:

Epoch 7000:

Epoch 10000:

Epoch 12000:

Epoch 15000:

Epoch 20000:

Epoch 22000:

Epoch 25000:

The code was executed using Python 3.6 and for deep learning keras-framework with tensorflow-backend.
Note that I ran the train_model.py script with local-GPU using NVIDIA GeForce GTX 1050 Ti. When runing this script with CPU-tensorflow, execution time might be longer. In order to obtain good generated images I created the batch_file with create_batch_file.py in order to chunk the epochs (trained all nets up to 20 000 epochs or even more).
This paragraph describes how to set up your environment locally. Make you have python-module virtualenv installed.
If you do not wish to run the training script on a virtual environment, make sure you have all modules/libraries properly installed and start from step 4 on.
Step 1 - Clone this repo:
git clone https://github.com/ptl93/deepArt-generation
cd deepArt-generation
Step 2 - create and activate a python virtual environment:
virtualenv deepArt-venv
source deepArt-venv/bin/activate
Step 2 (alternative) - create a conda environment:
conda create --name deepArt-venv python=3.6
source activate deepArt-venv
Step 3 - install needed modules/libraries:
pip install -r requirements.txt
This will download and install bs4, keras, numpy, tensorflow, scikit-learn and some other dependencies.
Step 4 - run the python scripts:
If you want to scrape another genre and/or style, make sure you changed the genre in codeline 98 and/or 131:
python data_scraping.pyIf you want to see the model architectures for each all 7 generative models execute `try_init_models.py
python try_init_models.pyIf you want to train on a high epoch you might want to split the total number of epochs into smaller epoch chunks. Important: Define the model parameters and training settings within this script before executing the command below.
python create_batch_file.pyBy default this will create a batch file with following input args for train_model.py:
write_batch_file(model="VAE_2", start_epoch=0, epochs=500, batch_size=16, save_intervals=250, final_epoch=15000)and finally train the generative network (either only default training in train_model.py) or execute batch-script:
python train_model.pyor
click on batchfile
Code under MIT license.