
Image and speech recognition problems have been worked on extensively in recent years. The advances in neural and deep neural networks have greatly improved image recognition techniques. While speech recognition is a fairly common task, translating and generating speech based on external inputs is far more complicated, particularly when it comes to the semantics of different languages. A common solution to these problems are Long Short Term Memory networks, also known as LSTMs. In this project, we tackle both these problems and try to create an optimal Image Caption Generation model. We use transfer learning techniques to adapt pretrained image classification models and combine them with different LSTM architectures to ascertain performance for each of the combined frameworks
Modern day research in this field is being spearheaded by Google Brain team which proposed Show and Tell: A Neural Image Caption Generator. The paper presented by google replaced the encoder RNN by a deep convolution neural network (CNN). As CNN can be leveraged to produce a source for the model by embedding the image into a fixed length vector which can be later taken as an input for many other computer vision tasks and image based model. While Convolutional Networks can be broadly used for classification, localization and detection, feature extraction is the key to make an image captioning model. The Convolution Net is trained on image data for image classification task while the hidden layer acts as a source for the input to the Recurrent Neural Network (decoder), which generate a simple sentence describing the image.
Our project is inspired by and based off the work done in the Show and Tell paper by Google. The project has two major components. The first is using transfer learning to adapt a classification model and perform feature extraction on images. The final candidate models for this were InceptionV3 and MobileNet. The Flickr8k dataset was our choice for this project. For both the models, a recurrent neural network encodes the variable length input into a fixed dimensional vector, which is taken as the maximum length of the caption available mapped with the image and uses this representation to “decode” it to the desired output sentence.
Flickr-8K is a dataset with 8000 images from the flickr website and can be found here. There are 6000 training images, 1000 validation images and 1000 testing images. Each image has 5 captions describing it. These captions act as labels for the images. There is no class information for the objects contained within an image.
Link: https://forms.illinois.edu/sec/1713398
CNN+Inception V3: In the field of computer vision research, the ImageNet Project is aimed at labeling and categorizing images into almost 22,000 object categories. 1.2 million training images are used to build the model while another 50,000 images for validation and 100,000 images for testing. The Inception V3 model proposed by Szegedy et al. has a CNN based architecture and led to a new state of the art for classification and detection. The key feature of the model is its design which improved utilization of the computing resources. The design achieves this by allowing for increased depth and width of the model. The weights for Inception V3 are smaller than both VGG and ResNet, with the total size coming in at 96MB.

The Long Short-Term Memory network, or LSTM network, is a recurrent neural network that is trained using Backpropagation Through Time and overcomes the vanishing gradient problem. As such, it can be used to create large recurrent networks that in turn can be used to address difficult sequence problems in machine learning and achieve state-of-the-art results. Instead of neurons, LSTM networks have memory blocks that are connected through layers. A block has components that make it smarter than a classical neuron and a memory for recent sequences. A block contains gates that manage the block’s state and output. A block operates upon an input sequence and each gate within a block uses the sigmoid activation units to control whether they are triggered or not, making the change of state and addition of information flowing through the block conditional.
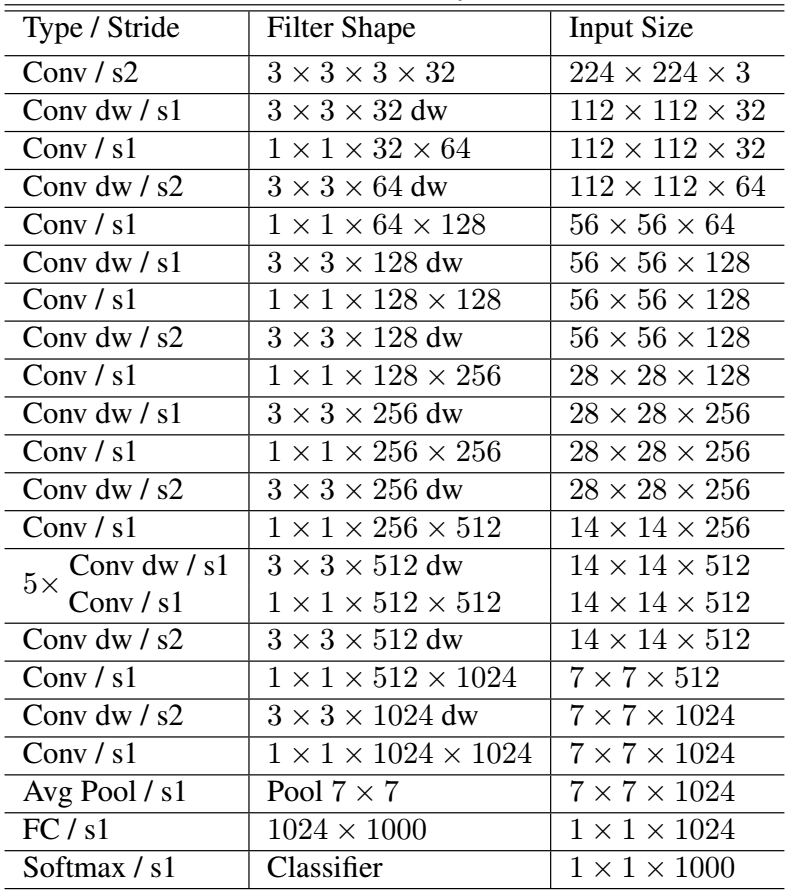
Computation efficacy is a key factor which drives deep learning algorithms. In 2017, Google’s Mobile Net came out as a model which can effectively maximize the accuracy while keeping a tab on resource usage of the device it is run on. The design of MobileNets are built for classification, image segmentation, detection and embedding, and work the same way as other ImageNet models work, however, MobileNets are designed to have a small size, low latency and low power consumption. Figure 3 details the architecture for the MobileNet model.
Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research.
Use Keras if you need a deep learning library that:
- Allows for easy and fast prototyping (through user friendliness, modularity, and extensibility).
- Supports both convolutional networks and recurrent networks, as well as combinations of the two.
- Runs seamlessly on CPU and GPU.
The core data structure of Keras is a model, a way to organize layers. The simplest type of model is the Sequential model, a linear stack of layers. For more complex architectures, you should use the Keras functional API, which allows to build arbitrary graphs of layers.
Here is the Sequential model:
from keras.models import Sequential
model = Sequential()Stacking layers is as easy as .add():
from keras.layers import Dense
model.add(Dense(units=64, activation='relu', input_dim=100))
model.add(Dense(units=10, activation='softmax'))Once your model looks good, configure its learning process with .compile():
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])If you need to, you can further configure your optimizer. A core principle of Keras is to make things reasonably simple, while allowing the user to be fully in control when they need to (the ultimate control being the easy extensibility of the source code).
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(lr=0.01, momentum=0.9, nesterov=True))You can now iterate on your training data in batches:
# x_train and y_train are Numpy arrays --just like in the Scikit-Learn API.
model.fit(x_train, y_train, epochs=5, batch_size=32)Alternatively, you can feed batches to your model manually:
model.train_on_batch(x_batch, y_batch)Evaluate your performance in one line:
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128)Or generate predictions on new data:
classes = model.predict(x_test, batch_size=128)Building a question answering system, an image classification model, a Neural Turing Machine, or any other model is just as fast. The ideas behind deep learning are simple, so why should their implementation be painful?
For a more in-depth tutorial about Keras, you can check out:
In the examples folder of the repository, you will find more advanced models: question-answering with memory networks, text generation with stacked LSTMs, etc.
Before installing Keras, please install one of its backend engines: TensorFlow, Theano, or CNTK. We recommend the TensorFlow backend.
- TensorFlow installation instructions.
- Theano installation instructions.
- CNTK installation instructions.
You may also consider installing the following optional dependencies:
- cuDNN (recommended if you plan on running Keras on GPU).
- HDF5 and h5py (required if you plan on saving Keras models to disk).
- graphviz and pydot (used by visualization utilities to plot model graphs).
Then, you can install Keras itself. There are two ways to install Keras:
- Install Keras from PyPI (recommended):
sudo pip install kerasIf you are using a virtualenv, you may want to avoid using sudo:
pip install keras- Alternatively: install Keras from the GitHub source:
First, clone Keras using git:
git clone https://github.com/keras-team/keras.gitThen, cd to the Keras folder and run the install command:
cd keras
sudo python setup.py installBy default, Keras will use TensorFlow as its tensor manipulation library. Follow these instructions to configure the Keras backend.