redten - A Platform for Distributed, Self-hosted LLM RAG and Reinforcement Learning with Human Feedback (RLHF)

A platform for building and testing large language models. Multi-tenant model testing results are stored in a database for experts to review later using the review-answer.py tool. Supports running gguf models using llama-cpp-python.
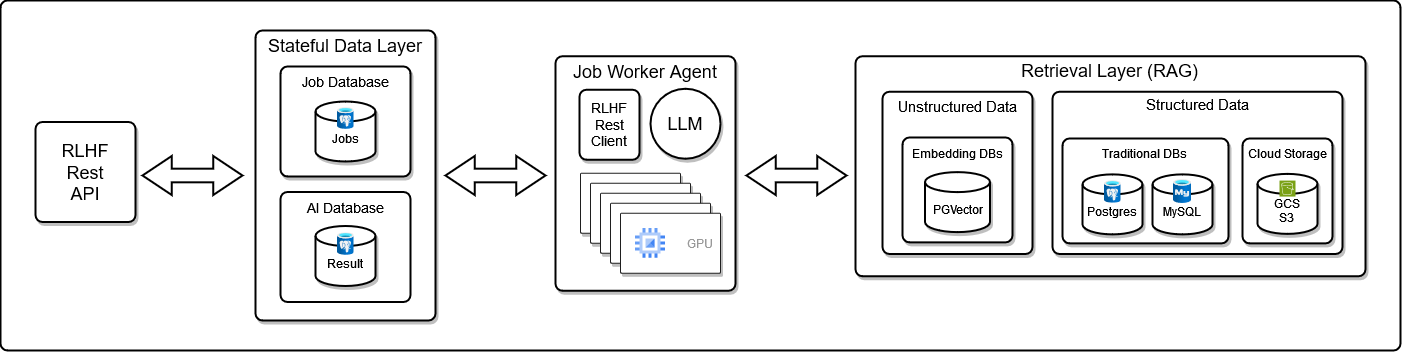
Python REST client for self-hosted llama building, testing and tuning platform at:
The redten RLHF REST api focuses on:
- leveraging many remote LLM agents concurrently POST-ing results (question/answer pairs or synthetic datasets) to a secured backend for review at a later time (save costs and shut down the expensive GPU cluster when it’s not needed)
- enabling subject matter experts to review results and submit expert answers for RAG source analysis which improves overall LLM response quality over time (tracking dashboard examples coming soon) decoupling LLM/gpu workloads from reinforcement learning with human feedback and RAG workloads
- finding knowledge blindspots - search api for tracking LLM response quality across many dimensions: models, quantization, batches, context sizes, tokens, and embeddings (chunks, structured vs unstructured datasets and use cases)
- Embedding as a Service (EaaS) with a multi-tenant job engine built on the v2 rust restapi crate that supports POST-ing uploaded files to s3 using the optional 'sloc' header key and includes optional kafka fire-and-forget publishing using a persistent Postgres backend for tracking many concurrent ai workloads (e.g. question/answer, synthetic dataset generation) and results
- evaluating any open source llm model with coming-soon open question/answer datasets with more RAG data sources (pdfs/csvs/txt/parquet) in many pgvector embedding databases using an emerging Retrieval as a Service (RaaS) architecture
- building synthetic datasets from a RAG-customized LLM (lora/qlora coming soon!)
There's limited hardware for the building and testing on the public api platform. Right now there is only one model deployed for all question responses:
Feel free to open a github issue on this repo if you think there is something more interesting/worthwhile to focus on:
- how to run a remote LLM agent (on gcp or aws) and POST the ai processing results to the reinforcement learning rest api for review
- RLHF with RAG example(s)
- RAG with pgvector ingestion example(s)
- streamlit score tracking while testing different unstructured RAG data sources (various pdf’s/csv’s/text/powerpoint/email/db data sources loaded into a tls-secured pgvector embedding database)
- LLM response customization with LoRA/QLoRA support
Ask an llm a question or a question from a file and the rest api will reply with a job_id for tracking the progress. once the llm's finishes processing the question then the results are shown to stdout.
Please install the python 3 pip:
pip install llama-client-aicThe following environment variables are used to automatically create a new user (or service account) using the RLHF REST API:
export AI_USER="publicdemos100"
export AI_EMAIL="[email protected]"
export AI_PASSWORD="789987"
# an auto-updated
# collection of public, unstructured embeddings
# stored in a pgvector database
export AI_COLLECTION_ID="embed-security"ask-llm.py \
-c "${AI_COLLECTION_ID}" \
-q "question"ask-llm.py \
-c "${AI_COLLECTION_ID}" \
-q PATH_TO_FILE_WITH_QUESTIONask-llm.py -c embed-security -q "using std::namespace; int main() { std::cout << "hello" << std::endl; return 256;}"Find the log line showing the job id:
job_id: 236get-ai-result.py -i 236
2023-11-09 03:47:26.881 INFO run_get_ai_result - search result -
-- 1/1 job.id=236 ai_result.id=269 user_id=92
- question=using std::namespace; int main() { std::cout << hello << std::endl; return 256;}
- answer=There are a few things wrong with the code you've provided. First, you need to include <iostream> and <string> in your program, just like in the example you've provided.
```causes the data to be lost
- score=0.79
- model=mistral-7b-instruct-v0.1.Q8_0.gguf
- match_source=/d/embed/input/v1/security/cplusplus.pdf
- match_page=5
- collection=None
- session_id=6c3b0905361f43d0971b9841fd689e3b
- tags=None
- reviewed_answer=Noneimport client_aic.ask as ask
# if your user does not exist it will be created
username = "publicdemos"
email = "[email protected]"
password = "789987"
collection_id = "embed-security"
question = 'using std::namespace; int main() { std::cout << "hello" << std::endl; return 256;}'
wait_for_result = False
# ask the llm the question and let the
# llm use the collection_id embeddings to perform rag
# before responding
print('asking question')
(
user,
res_job,
res_ai) = ask.ask(
question=question,
collection_id=collection_id,
username=username,
email=email,
password=password,
wait_for_result=wait_for_result)
if not user:
print(
f'failed to find user with email={email}')
elif not res_job:
print('failed to find job result')
elif wait_for_result:
if res_ai:
print(
f'{email} - job_id={res_job.job_id} '
'result:\n'
f'question: {question}\n'
f'answer: {res_ai.answer}\n'
f'score: {res_ai.score}')
else:
print(
'failed to get ai result for '
f'job_id={res_job.job_id}')
else:
print(
'did not wait for '
f'user_id={user.id} '
f'job={res_job.job_id} '
'ai result '
'please use:\n\n'
f'get-ai-result.py -i {res_job.job_id}'
'\n')Review individual LLM responses with subject matter expert(s) and attach reviewed:
- reviewer answer/explanation/reasoning
- reviewer confidence score
Note: confidence score is a value between 0-100.0 that the reviewer uses to state how confident the reviewer's answer is versus the llm's response. Here's some guidelines for how confidence scores work with rlhf+rag:
-
0.0-64 - the reviewer is not confident in the answer
-
65-79 - the reviewer is somewhat confident in the answer
-
80-94 - the reviewer is confident in the answer
-
95-100.0 - the reviewer considers this answer to be a common knowledge, a known truth or something that is almost considered as a fact
review-answer.py -i 236 -a "additionally there are other issues with this code. it has an exploit and needs to address 1, 2, 3" -s 99.9get-ai-result.py -i 236 2>&1 | grep reviewed_Increase logging by exporting this environment variable:
export LOG=debugHere are two streamlit LLM examples showing how different web applications can leverage the same mistral-7b-instruct-v0.1.Q8_0.gguf LLM model while using multiple, different RAG data sources to customize the LLM response based on the use case. Note: this LLM is currently self-hosted on 16-23 cpus (without any gpu cards) and each response takes ~40-80 seconds.
Create personalized questions for a 2nd grader using an LLM to align with your child's recent lessons and homework
More streamlit and open source examples coming soon!