

Scraping the movie review ✏️ using python programming language💻.






🔍Welcome to the IMDb Movie Review Scraper project! 🌟.
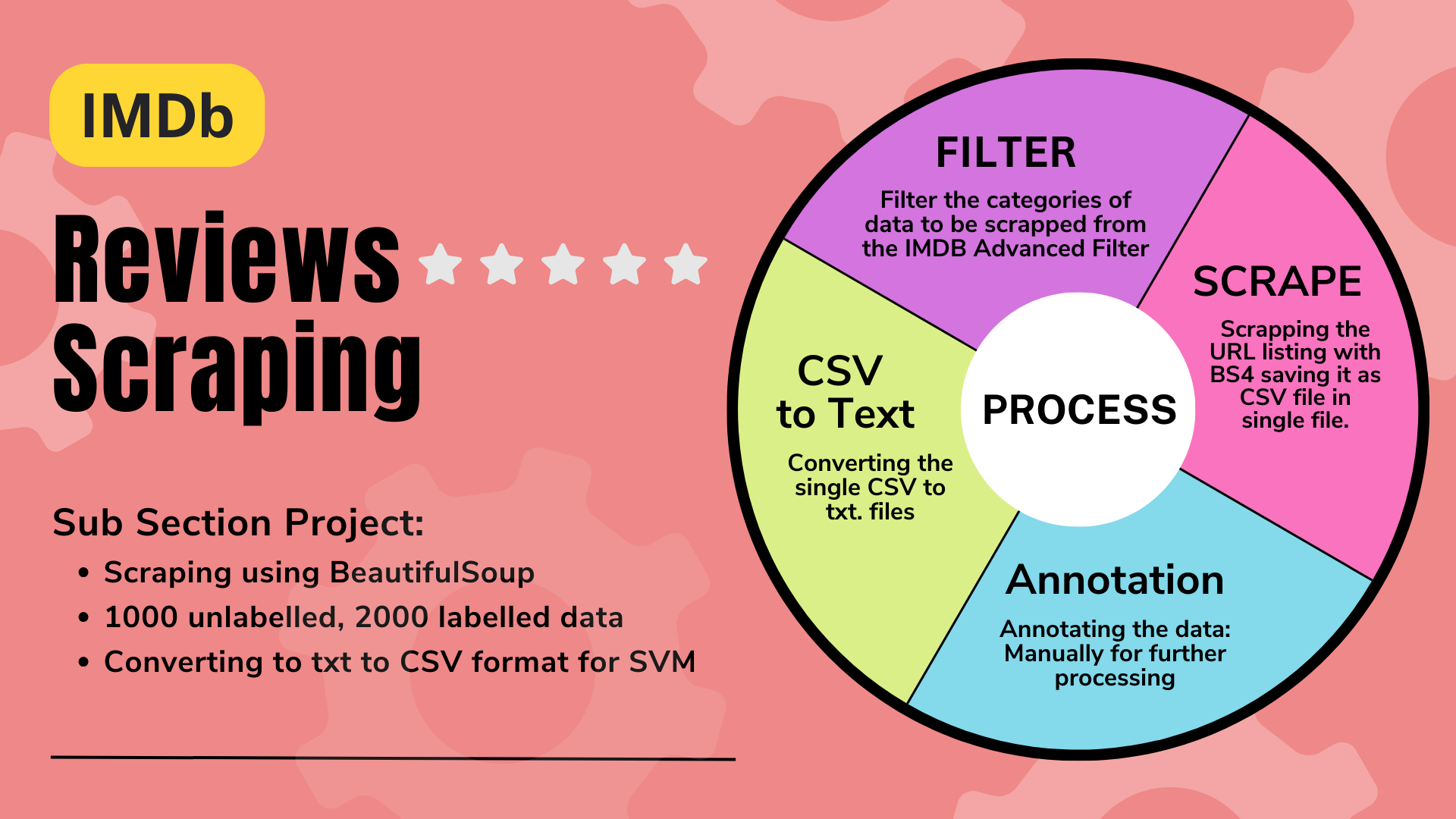
This Python script is designed to scrape movie reviews from IMDb, to facilitate analysis and research. The IMDb Movie Review Scraping project aims to gather a new dataset by automatically extracting movie reviews from IMDb. This dataset will support various natural language processing tasks, including sentiment analysis and recommendation systems. Using web scraping techniques, such as Beautiful Soup, movie reviews are collected, preprocessed, and structured into a CSV format suitable for analysis, including Support Vector Machine classification. 📈
Semi-supervised-sequence-learning-Project : replication process is done over here and for further analysis creation of new data is required.
- Scraping Movie Reviews 🕵️♂️
Movie_review_imdb_scrapping.ipynb- The script fetches user reviews from IMDb, providing access to a diverse range of opinions and feedback for different movies. It utilizes BeautifulSoup, a powerful Python library for web scraping, to extract data from IMDb's web pages efficiently and accurately. 🎥🔎
- Customizable Scraper 🛠️
rename_files.ipynb- Users can customize the scraper to target specific time periods, ratings, and other parameters, enabling focused data collection based on their requirements. This flexibility allows researchers, analysts, and enthusiasts to tailor the scraping process to their specific needs.

- CSV Output 📁
convert_texts_to_csv.ipynb- The scraped data is saved into a CSV file, allowing for easy import into data analysis software or further processing. The CSV format ensures compatibility with a wide range of tools and platforms, making it convenient to incorporate the scraped data into various workflows and projects. 💾💼



Dependencies
Make sure you have the following dependencies installed:
- Python 3.x
- BeautifulSoup (Install using
pip install beautifulsoup4 - Pandas (Install using
pip install pandas
Installation
-
Fork the
Semi-supervised-sequence-learning-Project/repository Link to `Semi-supervised-sequence-learning-Project' Follow these instructions on how to fork a repository -
Clone the Repository to your local machine
- using SSH:
git clone [email protected]:your-username/Semi-supervised-sequence-learning-Project.git - Or using HTTPS:
git clone https://github.com/your-username/Semi-supervised-sequence-learning-Project.git
- using SSH:
-
Navigate to the project directory.
cd Semi-supervised-sequence-learning-Project
If you encounter issues while installing dependencies such as BeautifulSoup or Pandas, try the following:
- Ensure you're using the correct version of Python (check the project's requirements).
- Use
pipto install the necessary libraries:pip install beautifulsoup4 pandas
- If you encounter permission errors, try adding
--userto the installation command:pip install --user beautifulsoup4 pandas
- For missing or outdated dependencies, create a virtual environment and install the required packages:
python -m venv env source env/bin/activate # On Windows use `env\Scripts\activate` pip install -r requirements.txt
If the script fails to fetch reviews or if there are changes to the website:
- Inspect the Website: The structure of the HTML may have changed. Use browser developer tools (F12) to inspect the elements you're scraping.
- Update Selectors: Modify the CSS selectors or XPath in the script to match the current structure of the webpage.
- Check for Blocked Requests: Websites may block scraping requests. Use headers in your requests to mimic a regular browser:
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3" } response = requests.get(url, headers=headers)
If you're facing problems with the CSV file format:
- Ensure Proper Formatting: Verify that the CSV file is correctly formatted. Each field should be separated by commas, and text fields should be enclosed in quotes if they contain commas.
- Check Encoding: Ensure the file is saved with UTF-8 encoding to prevent issues with special characters.
- Verify Column Names: If your script requires specific column names, ensure they match exactly.
Starting the Streamlit app
- Navigate to the Web_app directory
cd Web_app
- Install requirements with pip
pip install -r requirements.txt
- Run the Streamlit app
streamlit run Home_Page.py
Uploading the CSV file
When prompted by the app, upload a CSV (comma separated value) file containing the reviews.
Demo Link
Streamlit app link: https://scrape-review-analysis.streamlit.app



{kind=link}
{kind=link}
{kind=link}

🔬Here is the Link to Final Dataset: Drive Link containing the scraped IMDb movie reviews. This dataset can be used for analysis, research, or any other purposes you require. 📦

We are incredibly grateful for your dedication and hard work. Your contributions have been invaluable in making this project a success. Thank you for being a part of our journey!
Thank you for visiting! Feel free to reach out through any of the links above.