中文wiki百科问答系统,本项目使用了torchserver部署模型(不推荐用torchserve,如果你可以的话,用flask就好了,debug也比较方便)
知识库:wiki百科中文数据
模型:使用了的NER(CCKS2016数据)和阅读理解模型(CMRC2018),还有Word2Vec词向量搜索。
详细内容可以参考文章:WIKI+ALBERT+NER+W2V+Torchserve+前端的中文问答系统开源项目

-
ChineseWiki-master
功能:清洗wiki中文数据
相关项目:https://github.com/mattzheng/ChineseWiki -
NER 功能:从问题中识别实体
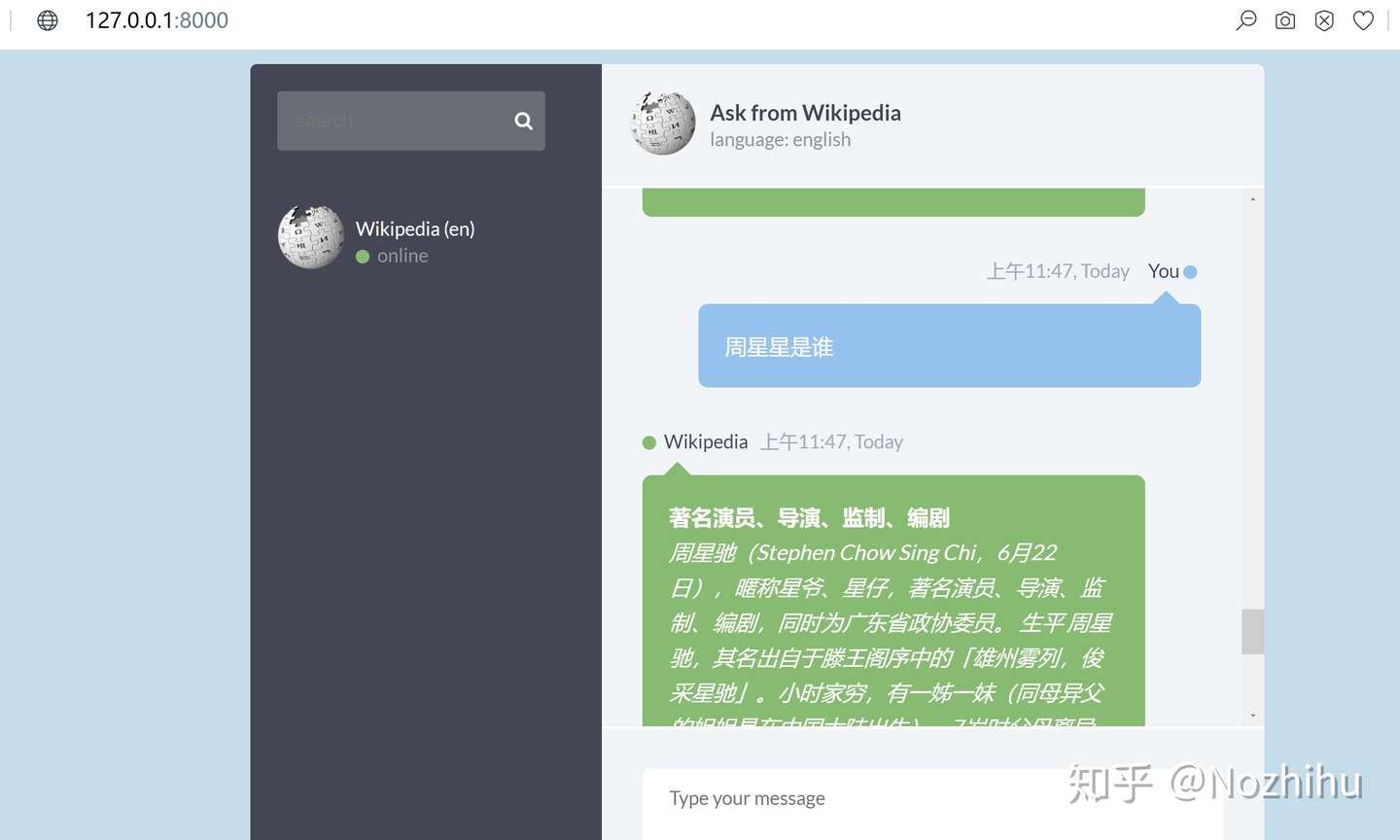
例子:qurry:周董是谁? 》》 entiy:周董
模型:ALBERT 数据集:CCKS2016KBQA
相关项目:https://github.com/997261095/bert-kbqa -
Word2vec 功能:如果实体不在知识库,则用W2V搜索近似实体
例子:entity:周董 >> ['周杰伦','JAY','林俊杰']
相关项目:https://github.com/Embedding/Chinese-Word-Vectors -
Entity linking 功能:根据NER或W2V得到的mention entity搜索知识库
-
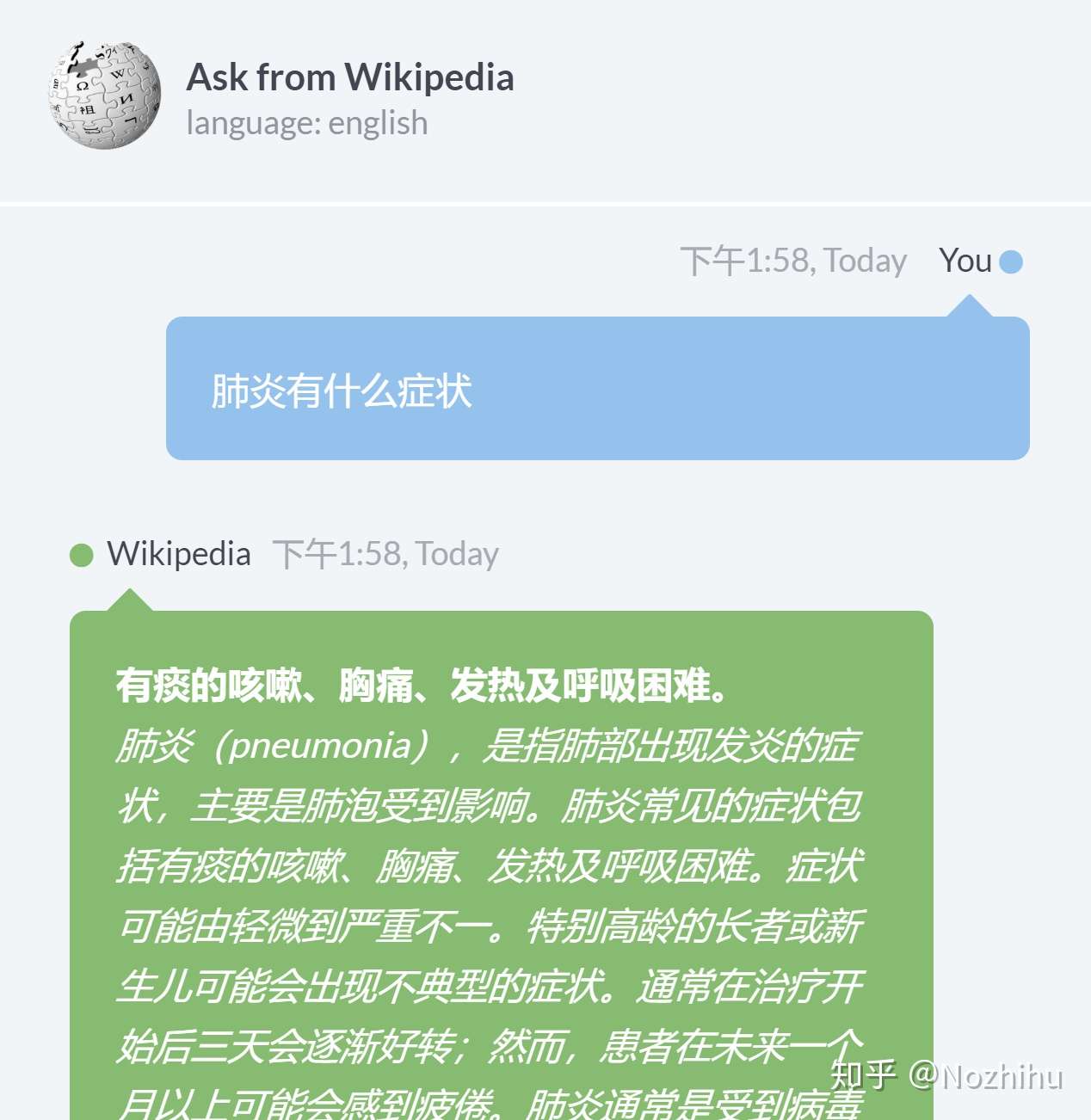
Reader 功能:阅读理解文段,精确定位答案。
例子:参考SQuAD 模型:ALBERT
数据集:CMRC2018
相关项目:https://github.com/CLUEbenchmark/CLUE -
Web 功能:web服务,前端交互和结果呈现
相关项目:https://github.com/zaghaghi/drqa-webui
-
下载项目
windows直接下载,linux可用git clone https://github.com/nocoolsandwich/wikiCH_QA.git
-
安装torchserve
参考install-torchserve windows注意openjdk 11的安装方法不一样,可参考这个文章
-
安装requirements.txt
使用豆瓣源快些
pip install -U -r requirements.txt -i https://pypi.douban.com/simple/
-
下载准备文件
-
wiki中文数据,下载地址
linux可用
wget https://dumps.wikimedia.org/zhwiki/20201120/zhwiki-20201120-pages-articles-multistream.xml.bz2
文件大小约2G,无需解压,放入ChineseWiki-master根目录
-
NER的albert模型
模型我已训练好,文件总大小约16M,下载地址
drive baiduyun(提取码:1234) NER_model NER_model 下载后存放路径:
NER\model -
reader的albert模型
模型我已训练好,文件总大小约35M,下载地址
drive baiduyun(提取码:1234) reader_model reader_model 下载后存放路径:
reader -
W2V 下载地址
Word2vec/Skip-Gram with Negative Sampling (SGNS)下的Mixed-large 综合Baidu Netdisk/Google Drive的Word
或者通过这其中一个链接下载:
drive baiduyun W2V.file W2V.file 下载解压后将
sgns.merge.word存放路径:W2V
在W2V下执行运行to_pickle.py可以得到文件W2V.pickle,这一步是为了把读进gensim的词向量转换成pickle,这样后续启动torchserve的时候可以更加快速,运行to_pickle.py的时间比较久,你可以先往后做,同步进行也是没问题的。
-
wiki数据清洗
依次运行
1wiki_to_txt.py,2wiki_txt_to_csv.py,3wiki_csv_to_json.py,4wiki_json_to_DB.py输出:
ChineseWiki-master\DB_output\output.db,然后把output.db放入reader下 -
torchserve打包模型,启动torchserve服务
在
NER目录执行torch-model-archiver --model-name NER --version 1.0 \ --serialized-file ./Transformer_handler_generalized.py \ --handler ./Transformer_handler_generalized.py --extra-files \ "./model/find_NER.py,./model/best_ner.bin,./model/SIM_main.py,./model/CRF_Model.py,./model/BERT_CRF.py,./model/NER_main.py"在
reader目录执行torch-model-archiver --model-name reader --version 1.0 \ --serialized-file ./checkpoint_score_f1-86.233_em-66.853.pth \ --handler ./Transformer_handler_generalized.py \ --extra-files "./setup_config.json,./inference.py,./official_tokenization.py,./output.db"在
W2V目录执行torch-model-archiver --model-name W2V --version 1.0 --serialized-file ./W2V.pickle --handler ./Transformer_handler_generalized.py
在
wikiCH_QA目录执行mkdir model_store \ mv NER/NER.mar model_store/ \ mv W2V/W2V.mar model_store/ \ cp W2V/config.properties config.properties \ mv reader/reader.mar model_store/ \
启动服务
torchserve --start --ts-config config.properties --model-store model_store \ --models reader=reader.mar,NER=NER.mar,W2V=W2V.mar
-
启动web服务
在drqa-webui-master下执行gunicorn --timeout 300 index:app
- NER模块在CCKS2016KBQA准确率98%
- reader模块在CMRC2018EM:66%,F1:86%
- 你的知识库可以更换,只需要一个带有
id,doc字段的sqlite数据库即可,id为实体名,doc为实体对应的文档,文档尽可能小于512个字符,因为受限于bert的输入长度。
{kind=link}