
We were invited to present this solution at Japanese Culture and AI Symposium 2019 in Tokyo, Japan on November 11.

Imagine the history contained in a thousand years of books. What stories are in those books? What knowledge can we learn from the world before our time? What was the weather like 500 years ago? What happened when Mt. Fuji erupted? How can one fold 100 cranes using only one piece of paper? The answers to these questions are in those books.
Japan has millions of books and over a billion historical documents such as personal letters or diaries preserved nationwide. Most of them cannot be read by the majority of Japanese people living today because they were written in “Kuzushiji”.
Even though Kuzushiji, a cursive writing style, had been used in Japan for over a thousand years, there are very few fluent readers of Kuzushiji today (only 0.01% of modern Japanese natives). Due to the lack of available human resources, there has been a great deal of interest in using Machine Learning to automatically recognize these historical texts and transcribe them into modern Japanese characters. Nevertheless, several challenges in Kuzushiji recognition have made the performance of existing systems extremely poor.
The hosts need help from machine learning experts to transcribe Kuzushiji into contemporary Japanese characters. With your help, Center for Open Data in the Humanities (CODH) will be able to develop better algorithms for Kuzushiji recognition. The model is not only a great contribution to the machine learning community, but also a great help for making millions of documents more accessible and leading to new discoveries in Japanese history and culture.

Please check the notebook: Kuzushiji Recognition Starter
From the beginning @ollieperree was using a 2-stage approach. Our approach to detection was directly inspired by K_mat's kernel, with the main takeaway being the idea of predicting a heatmap showing the centers of characters. Initially, we used a U-Net with a resnet18 backbone to predict a heatmap consisting of ellipses placed at the centers of characters, with the radii proportional to the width and height of the bounding box, with the input to the model being a 1024x1024 pixel crop of the page resized to 256x256 pixels. Predictions for the centers were then obtained by picking the local maxima (note that the width and height of the bounding box were not predicted). Performance was improved by changing the ellipses to circles of constant radius.

We tried using focal loss and binary cross-entropy as loss functions, but using mean squared error resulted in the cleanest predictions for us (though more epochs were needed to get sensible-looking predictions).
.png?generation=1571161817778557&alt=media)
One issue with using 1024x1024 crops of the page as the input were "artifacts" around the edges of the input. We tried a few things to try to counteract this, such as moving the sliding window over the page with a stride less than 1024x1024, then removing duplicate predictions by detecting when two predicted points of the same class were within a certain distance of each other. However, these did not give an improvement on the LB - we think that tuning parameters for these methods on the validation set, as well as the parameters for selecting maxima in the heatmap, might have caused us to "overfit".

These artifacts were related with the drawings and annotations! (See carefully the red dots at the images) How did we fix this? Check ensemble
We have a 2 stage model: detection and classification.
We used as starter code the great kernel: CenterNet -Keypoint Detector- by @kmat2019 Then I realized that @seesee had his own keras-centernet. At the end we used Hourglass and the output are boxes instead of only the centers (like the original paper).
Model
- Detection by hourglassnet
- Output heatmaps + width/height maps
- generate_heatmap_crops_circular(crop1024,resize256)
- Validation: w/o outliers GroupKFold
- resnet34
- MSELoss, dice and IOU (oss=0.00179, dice=0.6270, F1=0.9856, iou=0.8142)
- Augmentations: aug(randombrightness0.2,scale0.5)
- Learning rate: (1e-4:1e-6)
- 20epochs

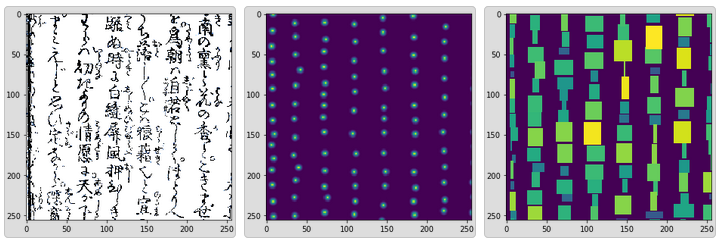
The classification model was a resnet18, pretrained on ImageNet, with the input being a fixed 256x256 pixel area, scaled down to 128x128, centered at the (predicted) center of the character. The training data included a background class, whose training examples were random 256x256 crops of the pages with no labelled characters. Training was done using the fastai library, with standard fastai transforms and MixUp. This model achieved a Classification accuracy of 93.6% on a validation set (20% of the train data, group split by book).
We are using standard augmentations from https://github.com/albu/albumentations/ library, including adjusting colors that helps simulate different paper styles
> Can you tell me wich one is the real one?

Code
import albumentations
colorize = albumentations.RGBShift(r_shift_limit=0, g_shift_limit=0, b_shift_limit=[-80,0])
def color_get_params():
a = random.uniform(-40, 0)
b = random.uniform(-80, -30)
return {"r_shift": a,
"g_shift": a,
"b_shift": b}
colorize.get_params = color_get_params
aug = albumentations.Compose([albumentations.RandomBrightnessContrast(contrast_limit=0.2, brightness_limit=0.2),
albumentations.ToGray(),
albumentations.Blur(),
albumentations.Rotate(limit=5),
colorize
])

We had a problem... our centers weren't ordered! so in order to improve the accuracy and delete false positives we thought in the following ensemble method. For the image IMG we take the most external centers from 3 predictions:
(xmin, ymin), (xmin, ymax), (xmax,ymin), (xmax,ymax)
At the picture this boxes are represented by 3 different colours (yellow, blue, red). Finally, we take the intersection of those 3 boxes, the black rectangle defined as (X,Y,Z,W), and we drop all the centers out of the black box! with this technique we could eliminate artifacts like predictions at the edges.
- Deep Learning for Classical Japanese Literature
- ROIS-DS Center for Open Data in the Humanities (CODH)
- CenterNet: Keypoint Triplets for Object Detection
- Albumentations: fast and flexible image augmentations
We would like to thank the organizers:
- Center for Open Data in the Humanities (CODH)
- The National Institute of Japanese Literature (NIJL)
- The National Institute of Informatics (NII)
- Kaggle
and the Official Collaborators: Mikel Bober-Irizar (anokas) Kaggle Grandmaster and Alex Lamb (MILA. Quebec Artificial Intelligence Institute)