The UC_Irvine_datasets() object contains a pandas dataframe of all the datasets available on the UC-Irvine Machine Learning Repository. Many methods make it easy to peruse, export, and even import the datasets inside the object.
See below for examples of ways to use methods of UC_Irvine_datasets():
from ucidata import UC_Irvine_datasets, df_first_row_to_header
# Create an instance of the class, which loads the dataframe of UC Irvine datasets
ucid = UC_Irvine_datasets()The string property allows users to understand the current state of the class object.
print(ucid)
Look at what datasets area available with list_all_datasets()
ucid.list_all_datasets()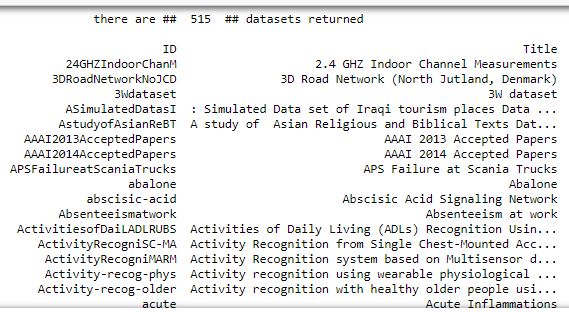
If you want to select only a single kind of dataset, limit to a single value with limit().
ucid.limit("Area", "Business")
print(ucid)
ucid.list_all_datasets()
Wow that's too many datasets all at once.
Let's just look at one with show_me_dataset(ID)
ds = UC_Irvine_datasets()
ds = ds.show_me_dataset("wine-quality")
print(ds)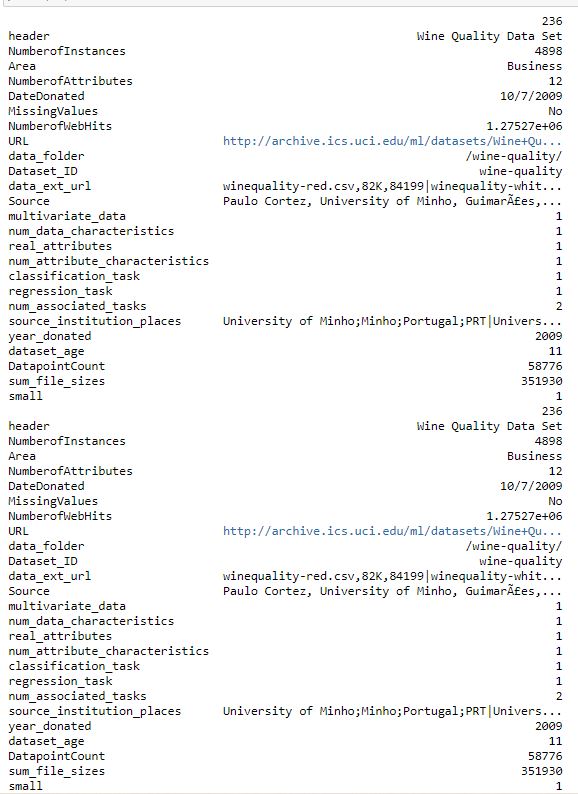
There's a flag set on this data set called small = 1.
In this case that means that our team decided the dataset was sufficiently small to safely import directly as a dataframe.
You can try to import any small dataset as load_small_dataset_df(ID)
Note that if there are multiple datasets available, only the first dataset is loaded.
test_load_df = ucid.load_small_dataset_df("wine-quality")
print(f"There are {len(test_load_df.index)} rows")
print(test_load_df.head())
Sometimes the datasets come with headers, and sometimes they don't.
df_first_row_to_header(df) will resolve this issue.
test_load_df = df_first_row_to_header(test_load_df)
print("\n\n### WITH HEADERS CORRECTED ###\n")
print(test_load_df.head())
object.small_datasets_only() will return a new object of only "small" datasets.
Let's see what returns from using it.
small_ucid = UC_Irvine_datasets().small_datasets_only()
small_uci = small_ucid.list_all_datasets()
print(small_ucid)
The object can also produce simple plots from the dataframe:
ucid.print_distribution("NumberofInstances")
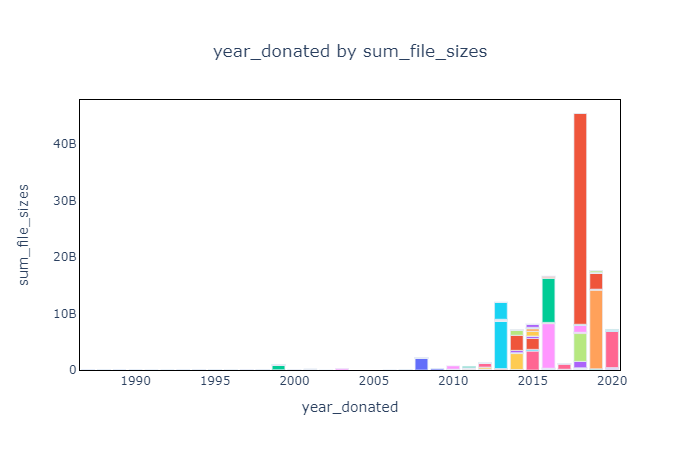
ucid.print_barplot("year_donated","NumberofWebHits", colorcol="header")