Braid provenance system
-
Embrace automation in data analysis, retention, decision-making
-
Enable users to trace back to how decisions were made
-
Necessitates recording what went into model training, including external data, simulations, and structures of other learning and analysis activity
-
Envision a versioned database for ML model states with HPC interfaces
-
Develop recursive and versioned provenance structures:
-
Models may be constructed via other models (estimates, surrogates)
-
Models are constantly updated (track past decisions and allow updates)
-
-
Integrate with other Braid components


-
Perform data reduction at the edge
-
Train models on specific characteristics of experiment-specific data
-
Scientist configures experiment parameters
-
Workflow launches simulations with experiment parameters
-
Complete simulations by time experiment data collection is complete
-
Train model on simulation and experiment data
-
Run model on an FPGA to perform data reduction in production
-
Everything has typical metadata like timestamps
-
Records can be updated
-
Not immutable history like most provenance data
-
Old versions can be recovered and used
-
-
Scientist configures experiment parameters
-
APS collects raw scattering data
-
Run peak finding on raw data, label peaks
-
Train model on peaks to represent raw data
-
Reproduce and save peak locations
-
Scientists create a beamline.json and process.phil file
-
Analysis is performed on the input data using these configs to create int files
-
The int files are used with a prime.phil file to create a structure
{kind=link}
-
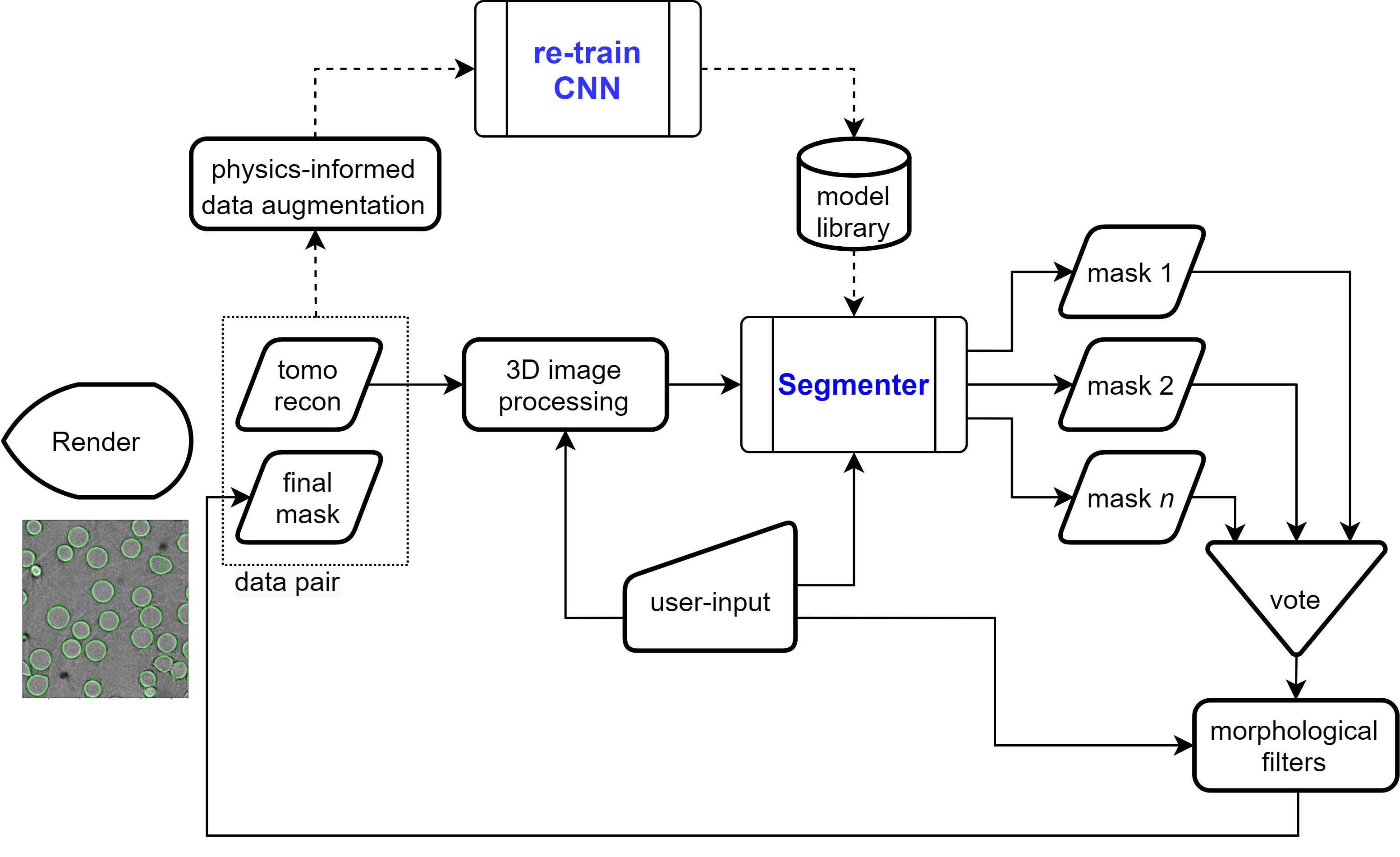
A tomo scan is obtained
-
Perform image processing, contrast adjustment, etc.
-
Apply (labeling) "masks"
-
Run ensemble models in inference mode
-
Get new segmentations
-
Aggregate segmentation results
-
Re-train models and loop…
Note: Additional docs forthcoming to help get setup in a (mini)conda based environment.
-
Start by installing poetry per https://python-poetry.org/docs/#osx—linux—bashonwindows-install-instructions
-
Then, run
poetry installto setup a local virtual environment from which to run other applications -
Run,
poetry run pre-commit installto setup pre-commit hooks for code formatting, lining, etc. -
Tests can be run using scripts in the
testsdirectory. -
Unit tests can be run with the command
poetry run pytest pytests/which will run the pytest test driver from the current virtual environment on all then tests defined in thepytestsdirectory.
Using FuncX requires that the funcx-endpoint be installed in a working environment whether it is a conda, pip or otherwise installed process.
Setting up to run with funcx is a multi-step process:
-
Create a new funcX endpoint configured so that it can use the BraidDB library. This can be done with the shell script:
scripts/configure_funcx_endpoint.sh. Provide one command line argument: the name of the funcx endpoint to be created/configured. If no name is provided, the endpoint will be namedbraid_db. This endpoint will be configured such that it has access to the implementation stored in the.venvdirectory of the braid db project. -
Start the new endpoint with the command
funcx-endpoint start <endpoint_name>whereendpoint_nameis as configured in the previous step. Take note of the UUID generated for the new endpoint. -
If you want the funcx hosted braid db to store files in a different location, edit
src/braid_db/funcx/funcx_main.pyand change the value ofDB_FILEin the functionfuncx_add_record. If not edited the funcx-based operations will store their entries in the file~/funcx-braid.db. -
Register the function(s) to be exposed to funcx. This can be done with the command
.venv/bin/register-funcx(orpoetry run register-funcx). Note that this requires that the commandpoetry installhas previously been run so that the script is installed in the virtual environment (in the.venv/bindirectory). As before, take note of the UUID for the registered function. -
To test invoking the add record function via funcx, run the command:
.venv/bin/funcx-add-record --endpoint-id <endpoint_id> --function-id <function_id>using the value for endpoint id and function id output in the previous steps. This should output the record id. One can use a tool likesqlite3to verify that records are stored in the database file.
-
There is a high-level SQL API wrapper in db_tools called BraidSQL.
This API is generic SQL, it does not know about Braid concepts -
The high-level Braid Database API is called BraidDB
-
BraidDB is used by the Braid concepts: BraidFact, BraidRecord, BraidModel, …
-
The Braid concepts are used by the workflows
-
We constantly check the DB connection because this is useful when running workflows
- bin/braid-db-create
-
Creates a DB based on the structure in braid-db.sql
- bin/braid-db-print
-
Print the DB to text
Tests are in the test/ directory.
Tests are run nightly at:
They are also run via Github Actions for each push or pull request against the origin repo.