Reads raw .fec files to standardized .csv files organized by original filing schedule, using Evan Sonderegger's fecfile.
Most users will prefer the FEC's bulk files, which are easier to use and available here.
You may want to set the following variables in a local_settings.py file, which will override the settings.py values. The full download requires ~15GB and ~110GB for the zipped and unzipped directories respectively; the final extract schedules A and B amount to upwards of 75GB.
ELECTRONIC_ZIPDIR # where the zipped electronic filings go
RAW_ELECTRONIC_DIR # where the unzipped electronic filings go
SCHEDULE_A_OUTFILE # .csv of receipts from electronic filings
SCHEDULE_B_OUTFILE # .csv of expenditures from electronic filings
SCHEDULE_A_PAPER_OUTFILE # .csv of receipts from paper filings
SCHEDULE_B_PAPER_OUTFILE # .csv of expenditures from electronic filings
$ nohup python get_daily_filings.py &
Retrieves the zipfiles that are listed in the metadata/electronic_zipfiles.txt (or set in settings.ELECTRONIC_ZIPFILE_MANIFEST).
This may take a while; using nohup python get_daily_filings.py allows the process to continue on the server if our connection dies; the & detaches the terminal from the window. You can see the output in nohup.out as it runs with tail -f nohup.out.
Because there are some random names it's often easier to just grab this from the live ftp site and paste it into the manifest file.
The zipfiles are downloaded into settings.ELECTRONIC_ZIPDIR, which by default is zip/electronic/
The zipfile source is here
$ nohup python unzip_filings.py &
This just executes the unzip command using an old school os.system call, there's doubtless a better approach to this. This takes up a lotta space; over 100GB for the 21/22 cycle.
set the START_YEAR = DDDD in process_filing_headers.py before we run it, below.
$nohup python process_filing_headers.py &
Writes a .csv file to settings.HEADER_DUMP_FILE, by default headers/headers_raw.csv.
$ python amend_headers.py
Reads from settings.HEADER_DUMP_FILE and writes output to settings.AMENDED_HEADER_FILE. It includes filing_number,is_superseded,amended_by,last_amendment,report_number,filer_committee_id_number,form_type,date_signed,coverage_from_date,coverage_through_date, comment.
Filings that are not superseded by a later amendment are included, whereas those that have been replaced are not.
Currently we just read campaign receipts (mostly contributions) reported in Schedule A and campaign expenditures reported on Schedule B. This includes operational spending, but leaves out "independent expenditures" by super pacs and dodgy outside groups that don't report their donors. These are reported on schedule E and on form F57; we hope to have a unified output of these in the future.
The output is written to settings.SCHEDULE_A_OUTFILE and settings.SCHEDULE_B_OUTFILE. You'll probably want to reconfigure the settings for these to a directory with plenty of room; the complete output of schedule A is bigger than 44GB.
$python read_filings_from_amended_headers.py
The actual files are stamped with the year that the corresponding report comes from; in other words, contributions in reports filed covering 2007 appear in ScheduleA-2007.csv. A small fraction of line items include dates that do not match their file year, but we believe these are generally in error because they've been included in a file for that year.
The schedule output files include committee ids, but it's helpful for users to have the committee and candidate name (if applicable). This annotates the schedule a and b .csv files with this info. It adds to the overall file size, so it may not be helpful for all uses.
$python match_skeds_to_committees.py
This reads the output scheduleX-YYYY.csv files and outputs them as ScheduleX-YYYY_annotated.csv. Note that these files are even bigger than the originals.
Paper filing has become much less common--see the requirements for filing on paper.
Overall this process is very similar to dealing with the electronic filings, but amendments are more complex because A. they can be either full or partial replacements, although there's no indication given in the filing as to which they are and B. there's no listing of the "original" filing being fixed.
Very similar to the script to retrieve electronic filings.
$ python get_daily_paper_filings.py
retrieves the zipfiles that are listed in the metadata/paper_zipfiles.txt (or set in settings.PAPER_ZIPFILE_MANIFEST). This may take a while; you may want to run it as nohup python get_daily_paper_filings.py & to detach from the process on linux and make sure it keeps running if your connection goes.
Because there are some random names it's often easier to just grab this from the live ftp site and paste it into the manifest file.
The zipfiles are downloaded into settings.PAPER_ZIPDIR, which by default is zip/paper/
$ python unzip_paper_filings.py
This just executes the unzip command using an old school os.system call, there's doubtless a better approach to this.
$ python process_paper_filing_headers.py
Writes a .csv file to settings.HEADER_PAPER_DUMP_FILE, by default headers/paper_headers_raw.csv.
$ python amend_paper_headers.py
Reads from settings.HEADER_PAPER_DUMP_FILE and writes output to settings.AMENDED_HEADER_FILE. It includes filing_number,is_superseded,amended_by,last_amendment,report_number,filer_committee_id_number,form_type,date_signed,coverage_from_date,coverage_through_date, comment. It also has file_size and file_linecount
Filings that are not superseded by a later amendment are included, whereas those that have been replaced are not. The logic of this is more complex, see the processing logic section below.
Read the most recent filings from step 4's output, but first set the years to process in read_filings_from_amended_headers.py. These restrict the transaction date to a specified time window, and are required to keep out duplicates from later amendments.
$python read_paper_filings_from_amended_headers.py
Same script as for electronic filings but with settings for the paper filings.
$python match_paper_skeds_to_committees.py
The FEC makes a wide variety of data available in bulk, but there are some limitations to the public release files.
These downloads do not include the street addresses of campaign donors and contractors. It's illegal to collect address information from campaign donors in order to make mailing lists of your own.
For journalists, investigators and citizens interested in tracking influence, however, addresses can provide critical confirmation of a linkage between corporate entities. These addresses can be found on the original filings displayed on FEC's web site, but this is of little use if you don't know which filing to reference.
To extract the most complete record of campaign finance available, it is necessary to download all of the originally submitted filings and process them. This is, in essence, what the FEC does to create the bulk files, although their process is more complex.
The FEC's bulk "detailed" release discloses PAC-to-PAC donations in a single file, but these transactions actually are reported in two places: by the giving PAC (on schedule B) and the receiving PAC (schedule A). One use of this data, therefore, is for comparing what PAC's say they donated to candidates versus what candidates say they received. This kind of discrepancy may suggest additional problems.
US election law requires "independent" election spenders to report large expenditures ahead of an election within 24 or 48 hours; candidates must also report large contributions received in the last 20 days of an election within 2 days.
These early notifications are intended to let the public know about the spending, but in exchange for their timeliness FEC tolerates less exact numbers. The "final" version of the transactions also appear in a monthly or quarterly periodic report, which also include special pre- and post- election periods.
This library disregards the 24 and 48 hour reports in favor of the periodic reports, as those are seen as more reliable. This means, however, that data extracted using this library will not be
US campaign finance rules allow filers to amend their filings as many times as they want. Filings that come under scrutiny may be amended a half dozen times. Most individual amendments introduce few changes.
Processing electronic filing amendment is relatively straightforward, because the file submission format requires amended filings to 1. provide the id of the filing they are amending and 2. replace the filing completely.
It's important to note that there's some ambiguity about how "chains" of amendments get listed. The logic used here is that if 2 amends 1 and 3 amends 2, filing 3 will sometimes list 1 or 2.
The basic approach we are taking is to identify all of the "most recent" electronic filings, and export the data from those filings only. This works because FEC requires filers to submit an complete replacement of the original filing in the amendment.
Paper filings are more of a challenge because 1. they are not required to fully replace the original filing and 2. because they are not required to specify the original.
This library assumes that multiple filings from the same committee covering the same time period are amendments.
To differentiate between full and partial amendments, this library only considers amendments with 10 lines or more and 80% of the number of lines of the original to be complete replacements. This means that a small number of reports may have out of date details, although most amendments introduce relatively few changes.
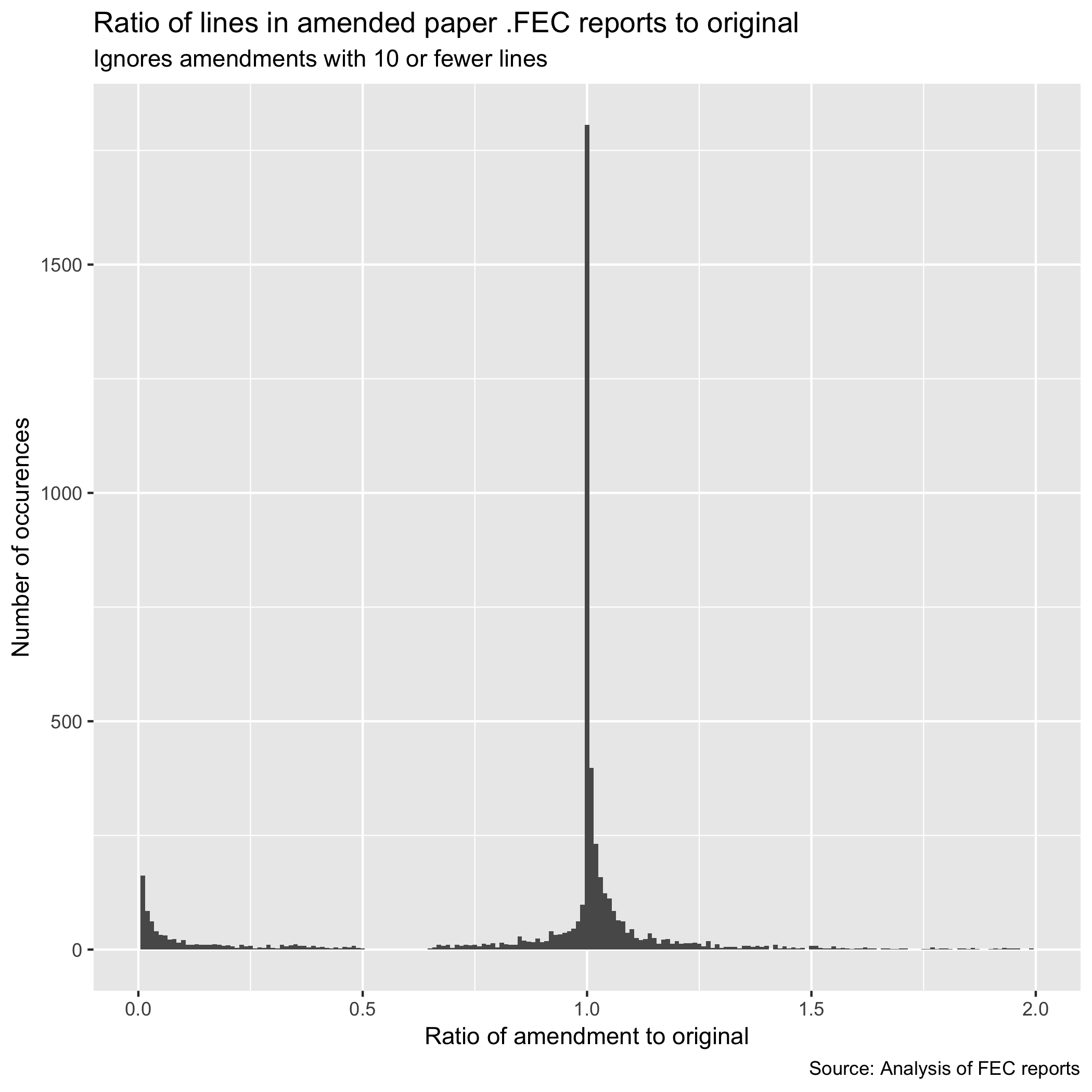
This approach was originally developed to support comprehensive search of this data rather than the ability to sum it. Because of the possible errors introduced, especially as detailed in the paper amendment processing section above, we urge users to treat this data as approximate, and consult other sources for more precise numbers: including the FEC's web site, the Center for Responsive Politics or the National Institute for Money in State Politics.
updates:
$ get_daily_filings.py $ get_daily_paper_filings.py
$ python unzip_filings.py $ python unzip_paper_filings.py
$ python process_filing_headers.py
--
Writing output to headers/headers_raw.csv error reading /data/fecfilings/electronic/20190429/1329024.fec: invalid literal for int() with base 10: '1225248d' error reading /data/fecfilings/electronic/20190208/1315131.fec: invalid literal for int() with base 10: '1312248*BD3773827d' error reading /data/fecfilings/electronic/20190129/1308726.fec: invalid literal for int() with base 10: '1303366BD52a'
python process_paper_filing_headers.py
python amend_headers.py; echo
-- did it work ?
python read_paper_filings_from_amended_headers.py; echo
--> at this point the file should be in:
$python match_skeds_to_committees.py $python match_paper_skeds_to_committees.py