A curated list for Efficient Large Language Models
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System / Serving
- Tuning
- Efficient Training
- Survey or Benchmark
Please check out all the papers by selecting the sub-area you're interested in. On this main page, only papers released in the past 90 days are shown.
- May 29, 2024: We've had this awesome list for a year now 🥰!
- Sep 6, 2023: Add a new subdirectory project/ to organize efficient LLM projects.
- July 11, 2023: A new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs.
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.
For each topic, we have curated a list of recommended papers that have garnered a lot of GitHub stars or citations.
Paper from Sep 30, 2024 - Now (see Full List from May 22, 2023 here)
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System / Serving
- Tuning
- Survey















































































































































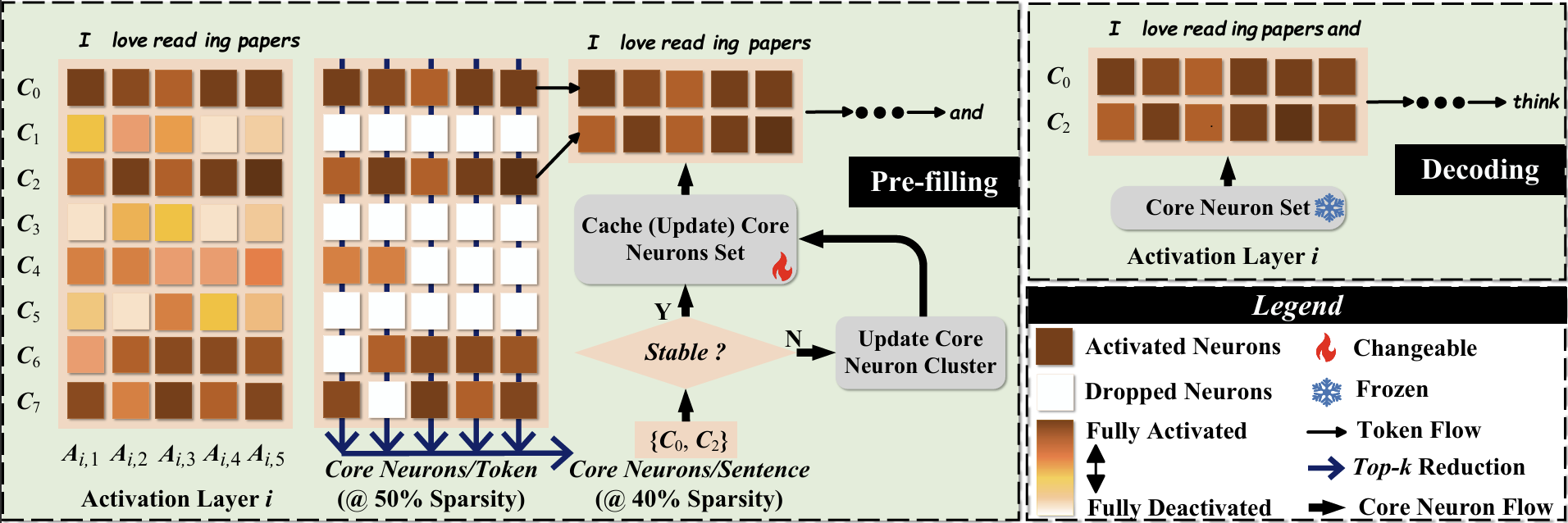











| Title & Authors | Introduction | Links |
|---|---|---|
 ⭐ Fast Inference of Mixture-of-Experts Language Models with Offloading Artyom Eliseev, Denis Mazur |
 |
Github Paper |
 Condense, Don't Just Prune: Enhancing Efficiency and Performance in MoE Layer Pruning Mingyu Cao, Gen Li, Jie Ji, Jiaqi Zhang, Xiaolong Ma, Shiwei Liu, Lu Yin |
 |
Github Paper |
| Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference Andrii Skliar, Ties van Rozendaal, Romain Lepert, Todor Boinovski, Mart van Baalen, Markus Nagel, Paul Whatmough, Babak Ehteshami Bejnordi |
 |
Paper |
 MoNTA: Accelerating Mixture-of-Experts Training with Network-Traffc-Aware Parallel Optimization Jingming Guo, Yan Liu, Yu Meng, Zhiwei Tao, Banglan Liu, Gang Chen, Xiang Li |
 |
Github Paper |
 MoE-I2: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Yuanlin Duan, Wenqi Jia, Miao Yin, Yu Cheng, Bo Yuan |
 |
Github Paper |
| HOBBIT: A Mixed Precision Expert Offloading System for Fast MoE Inference Peng Tang, Jiacheng Liu, Xiaofeng Hou, Yifei Pu, Jing Wang, Pheng-Ann Heng, Chao Li, Minyi Guo |
 |
Paper |
| ProMoE: Fast MoE-based LLM Serving using Proactive Caching Xiaoniu Song, Zihang Zhong, Rong Chen |
 |
Paper |
| ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference Xin He, Shunkang Zhang, Yuxin Wang, Haiyan Yin, Zihao Zeng, Shaohuai Shi, Zhenheng Tang, Xiaowen Chu, Ivor Tsang, Ong Yew Soon |
 |
Paper |
| EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference Yulei Qian, Fengcun Li, Xiangyang Ji, Xiaoyu Zhao, Jianchao Tan, Kefeng Zhang, Xunliang Cai |
Paper | |
 MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, Xiaojuan Qi |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 ⭐ MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan |
 |
Github Paper Model |
 ⭐ Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou |
 |
Github Paper |
| Taipan: Efficient and Expressive State Space Language Models with Selective Attention Chien Van Nguyen, Huy Huu Nguyen, Thang M. Pham, Ruiyi Zhang, Hanieh Deilamsalehy, Puneet Mathur, Ryan A. Rossi, Trung Bui, Viet Dac Lai, Franck Dernoncourt, Thien Huu Nguyen |
 |
Paper |
 SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Hayden Kwok-Hay So, Ting Cao, Fan Yang, Mao Yang |
 |
Github Paper |
 Basis Sharing: Cross-Layer Parameter Sharing for Large Language Model Compression Jingcun Wang, Yu-Guang Chen, Ing-Chao Lin, Bing Li, Grace Li Zhang |
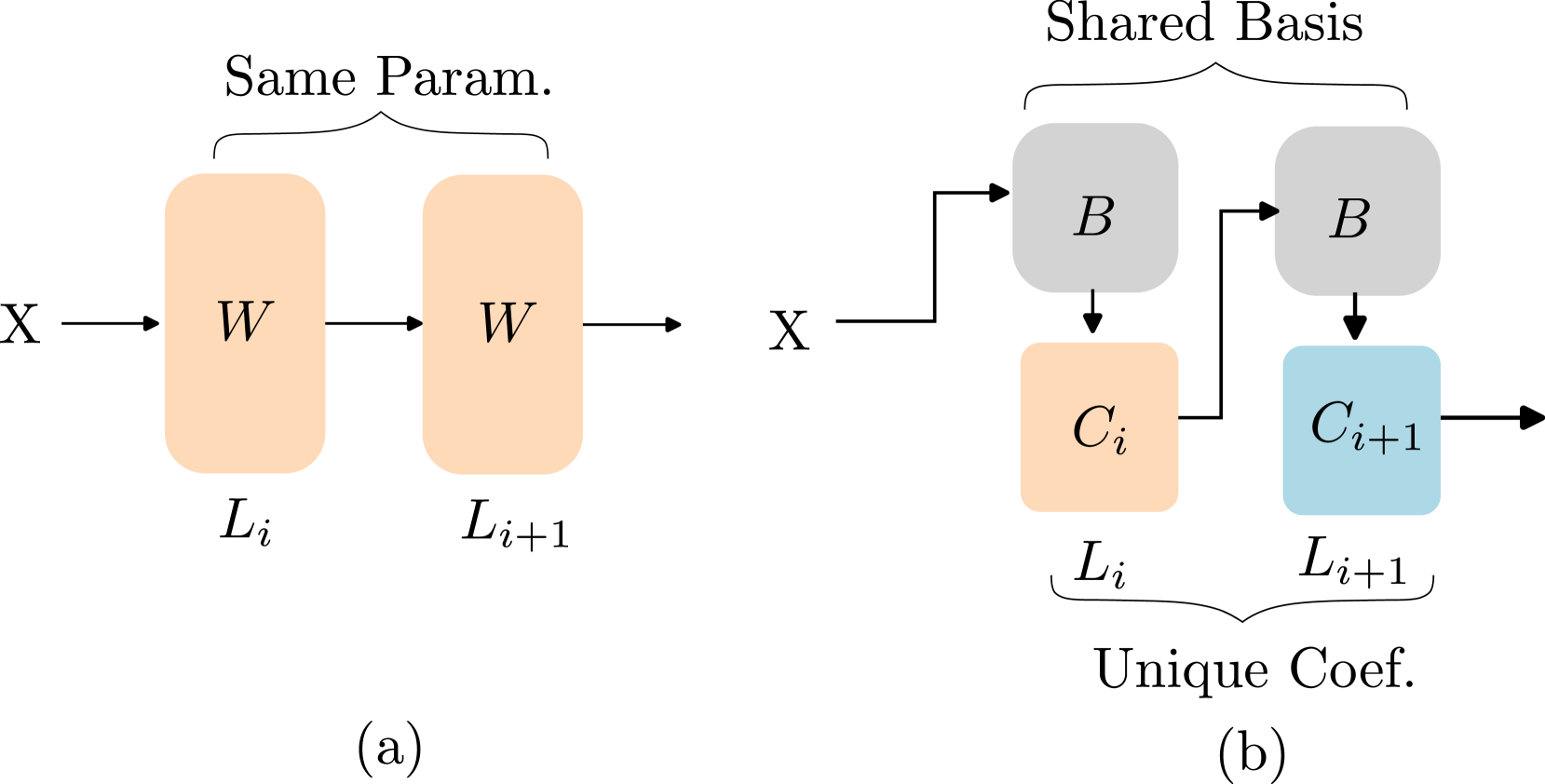 |
Github Paper |
| Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions Zhihao He, Hang Yu, Zi Gong, Shizhan Liu, Jianguo Li, Weiyao Lin |
 |
Paper |





































| Title & Authors | Introduction | Links |
|---|---|---|
 Natural GaLore: Accelerating GaLore for memory-efficient LLM Training and Fine-tuning Arijit Das |
Github Paper |
|
| CompAct: Compressed Activations for Memory-Efficient LLM Training Yara Shamshoum, Nitzan Hodos, Yuval Sieradzki, Assaf Schuster |
 |
Paper |
ESPACE: Dimensionality Reduction of Activations for Model Compression Charbel Sakr, Brucek Khailany |
 |
Paper |



























| Title & Authors | Introduction | Links |
|---|---|---|
 LayerDropBack: A Universally Applicable Approach for Accelerating Training of Deep Networks Evgeny Hershkovitch Neiterman, Gil Ben-Artzi |
 |
Github Paper |
| AutoMixQ: Self-Adjusting Quantization for High Performance Memory-Efficient Fine-Tuning Changhai Zhou, Shiyang Zhang, Yuhua Zhou, Zekai Liu, Shichao Weng |
 |
Paper |
 Scalable Efficient Training of Large Language Models with Low-dimensional Projected Attention Xingtai Lv, Ning Ding, Kaiyan Zhang, Ermo Hua, Ganqu Cui, Bowen Zhou |
 |
Github Paper |
| Less is More: Extreme Gradient Boost Rank-1 Adaption for Efficient Finetuning of LLMs Yifei Zhang, Hao Zhu, Aiwei Liu, Han Yu, Piotr Koniusz, Irwin King |
 |
Paper |
 COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training Haocheng Xi, Han Cai, Ligeng Zhu, Yao Lu, Kurt Keutzer, Jianfei Chen, Song Han |
 |
Github Paper |
 BitPipe: Bidirectional Interleaved Pipeline Parallelism for Accelerating Large Models Training Houming Wu, Ling Chen, Wenjie Yu |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Closer Look at Efficient Inference Methods: A Survey of Speculative Decoding Hyun Ryu, Eric Kim |
 |
Paper |
 LLM-Inference-Bench: Inference Benchmarking of Large Language Models on AI Accelerators Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus et al |
Github Paper |
|
 Prompt Compression for Large Language Models: A Survey Zongqian Li, Yinhong Liu, Yixuan Su, Nigel Collier |
 |
Github Paper |
| Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Guohao Dai |
 |
Paper |