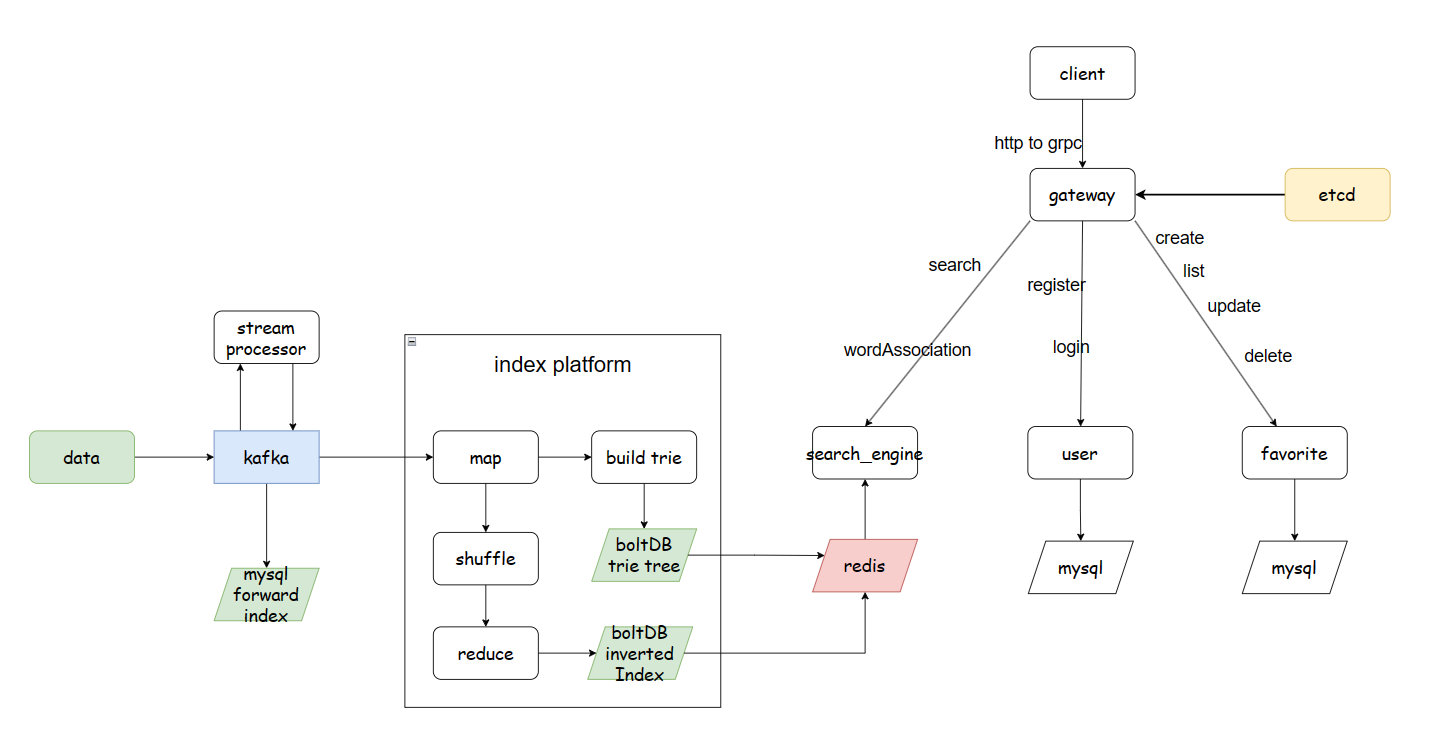
- 服务发现与注册
使用etcd作为服务注册中心,每个服务实例在启动时将自己的地址和其他必要信息注册到etcd中。这样,服务消费者可以从etcd查询当前可用的服务实例,实现动态的服务发现。
- 负载均衡
在微服务架构中,可能有多个实例提供相同的服务。通过etcd,客户端可以获取所有可用服务实例的列表,并实现客户端侧的负载均衡,如轮询或随机选择服务实例。
- 故障恢复与健康检查
结合gRPC的健康检查机制,可以实时监控服务实例的健康状态,并在etcd中更新其状态。这样,不健康的实例可以从服务目录中自动剔除,增强系统的整体可靠性。
服务端启动时,需要将自己的地址注册到etcd中。这样,客户端就可以通过查询etcd来发现服务的地址。
- 连接到etcd:服务启动时,首先建立与etcd的连接。
- 注册服务地址:将服务的地址(通常是IP和端口)作为键值对存储到etcd。键可以是服务名称,值是服务地址。
- 心跳机制:定期更新etcd中的键值对,以表明服务仍然存活。如果服务停止更新,etcd可以通过过期机制自动移除该服务,从而实现服务的健康检查。
客户端使用自定义解析器来查询etcd,发现服务地址,并建立连接。
- 使用自定义解析器:客户端在初始化时指定使用的解析器和服务名称。这个解析器负责查询etcd,找到服务的实际地址。
- 建立gRPC连接:客户端通过解析器返回的地址,使用gRPC的
Dial函数建立到服务的连接。
在gRPC中,自定义解析器是用于实现服务发现的关键组件。它允许客户端动态地发现和连接到服务端的实例,特别是在使用像etcd这样的服务注册中心时。自定义解析器需要实现gRPC的resolver.Resolver接口,并通过gRPC的解析器注册机制注册使用。
实现resolver.Resolver接口
自定义解析器至少需要实现以下方法:
Build(target resolver.Target, cc resolver.ClientConn, opts resolver.BuildOptions) (resolver.Resolver, error): 当gRPC客户端尝试连接到某个服务时,这个方法被调用。它负责创建解析器的实例,并开始服务发现过程。ResolveNow(o resolver.ResolveNowOptions): 这个方法被设计为让解析器有机会对解析请求做出响应。在某些实现中,这个方法可能不会做任何事情。Close(): 当解析器不再需要时,这个方法被调用,用于执行清理工作,比如停止后台goroutine。
注册自定义解析器
在使用自定义解析器之前,需要将其注册到gRPC的解析器注册机制中。这通常在程序的初始化阶段完成。例如:
import (
"google.golang.org/grpc/resolver"
)
func init() {
resolver.Register(&myResolverBuilder{})
}这里,myResolverBuilder是实现了resolver.Builder接口的类型,它负责创建自定义解析器的实例。resolver.Register函数用于将解析器构建器注册到gRPC中,使得gRPC能够使用这个自定义解析器来解析服务名称。
使用自定义解析器
在客户端代码中,通过指定服务名称的前缀来使用自定义解析器。这个前缀与自定义解析器在注册时使用的scheme相匹配。例如,如果你的解析器使用了"myScheme"作为scheme,那么在创建gRPC客户端连接时,可以这样指定服务名称:
conn, err := grpc.Dial("myScheme:///serviceName", grpc.WithInsecure(), grpc.WithBalancerName(roundrobin.Name))这里,"myScheme:///serviceName"指定了要连接的服务名称,其中myScheme是自定义解析器的scheme,serviceName是要查询的服务名称。grpc.Dial函数会使用与myScheme相匹配的解析器来解析serviceName。
自定义解析器允许gRPC客户端通过服务发现机制(如etcd)动态地发现服务端实例。通过实现resolver.Resolver接口,并将解析器注册到gRPC中,可以实现服务的动态发现和连接。这对于构建可扩展的微服务架构非常有用。
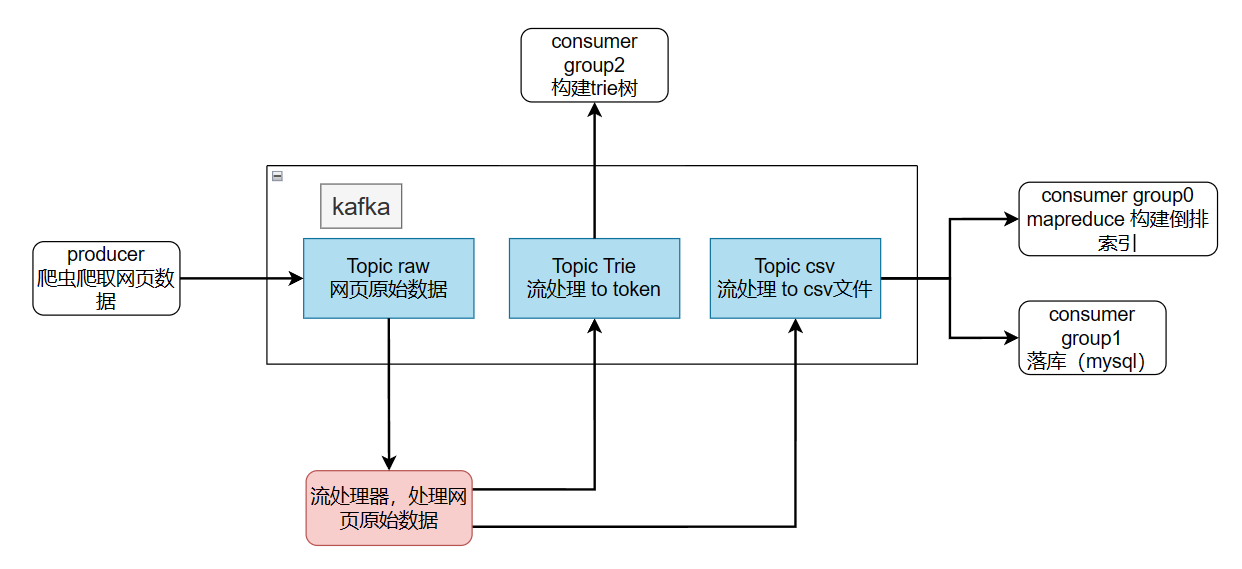
这样可以减少一段到kafka的数据流,我认为效率更高。
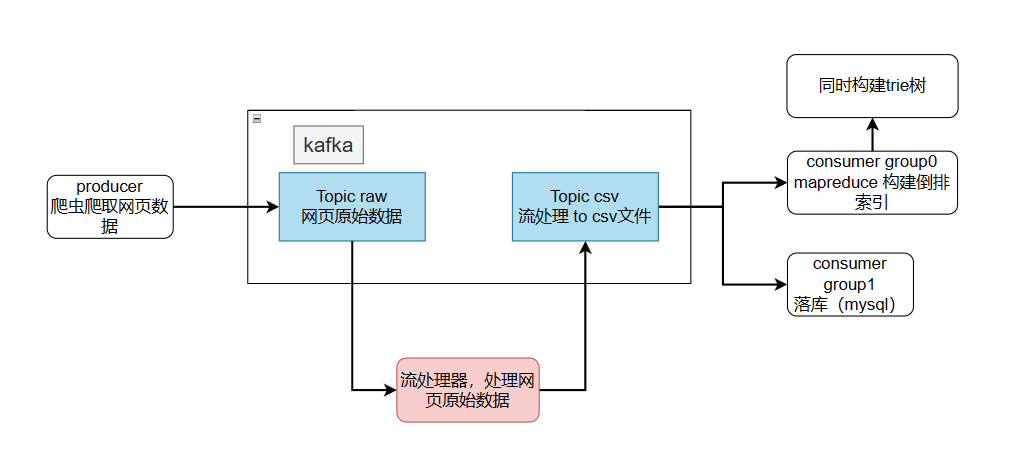
- 数据吞吐量和处理速度:
- 需要一个能够处理高吞吐量数据的消息队列来对数据处理过程进行解耦,尤其是在爬虫持续爬取大量网页内容时。
- 数据一致性和可靠性:
- 在数据转换和索引构建过程中,确保数据不丢失且可靠传输至MapReduce。
- 系统的伸缩性:
- 随着索引量的增加和查询量的变化,消息队列应能灵活地扩展和收缩。
- 解耦数据生产和处理
Kafka 作为一个中间层可以有效地解耦数据的生产(爬虫爬取的数据)和数据处理(使用 MapReduce 构建索引)的过程。这意味着爬虫程序只需关注数据的采集,而不需要管理数据的存储和处理。同样,数据处理组件可以独立于数据源运行,只需要从 Kafka 中读取数据。这种解耦使得系统各部分可以独立扩展和优化,提高了系统的灵活性和维护性。
- 缓冲和平滑高峰负载
Kafka 可以作为一个高效的缓冲区,存储大量即将被处理的数据。在数据生产速度高于消费速度的情况下(例如在网络爬虫快速爬取网页时),Kafka 可以平衡负载,避免在数据处理端发生拥塞。这是因为 Kafka 允许数据在被实际处理之前存储在其内部的队列中,从而平滑了处理过程中的高峰负载。
- 提高数据处理的可靠性
Kafka 提供数据持久性保证和高可用性特性,如数据复制和故障自动恢复。这意味着即使在某些组件失败的情况下,数据也不会丢失,系统的整体可靠性得以增强。此外,Kafka 保证了分区内消息的顺序,这对于确保数据一致性是非常重要的。
- 支持实时和批量处理
Kafka 不仅支持实时数据流的处理,也支持批量数据处理。在您的场景中,可以根据需要灵活地从 Kafka 读取数据:实时处理小批量数据以快速更新索引,或批量处理大量数据以优化性能和资源使用。这种灵活性使 Kafka 成为构建高效和响应迅速的搜索引擎索引系统的理想选择。
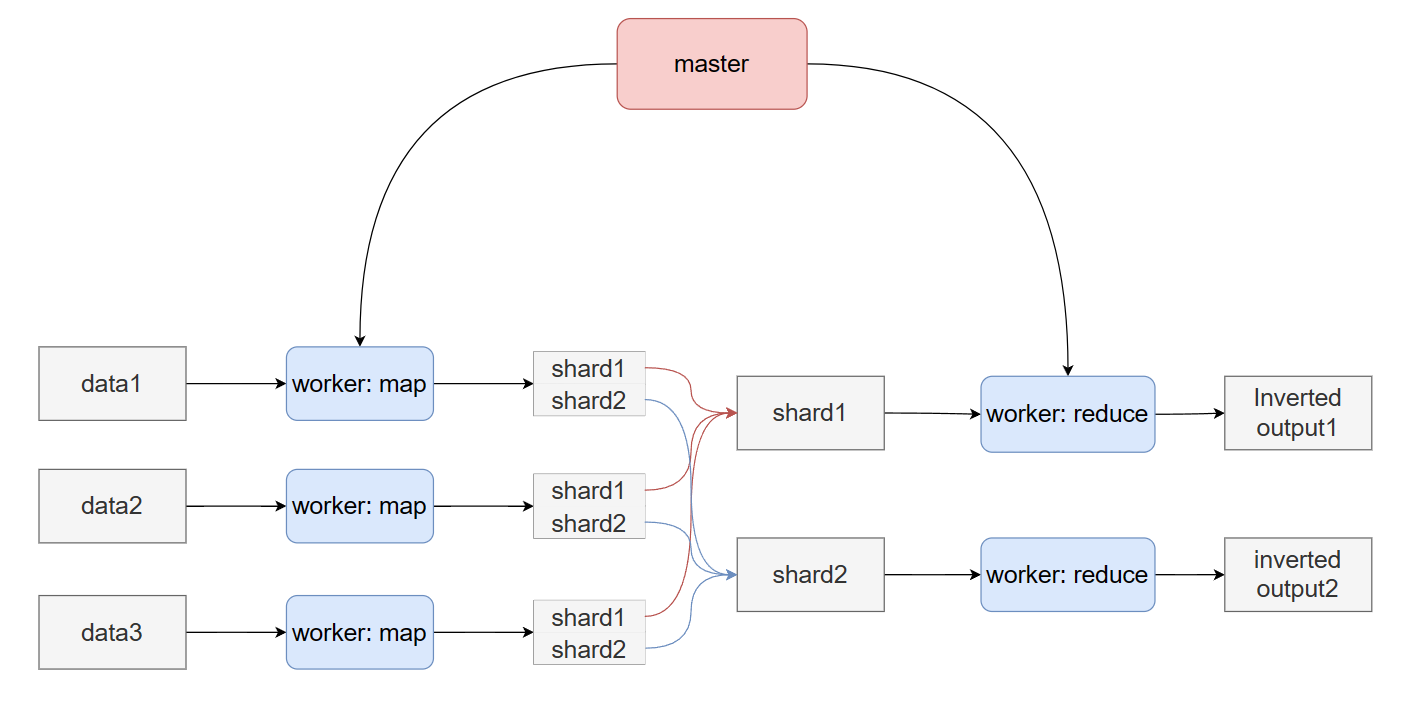
具体流程:
- 将文档分成 M 个数据片度,作为map函数的输入数据。
- master 分配任务,有 M 个 Map 任务和 R 个 Reduce 任务将被分配,master 将一个 Map 任务或 Reduce 任务分配给一个空闲的 worker。
- 被分配了 map 任务的 worker 程序读取相关的输入数据片段,从输入的数据片段中解析出文档数据,然后传递给用户自定义的 Map 函数,由 Map 函数生成并输出的中间 <term, docID>,并缓存在内存中。
- 缓存中的<term, docID> 通过分区函数分成 R 个区域,之后周期性的写入到本地磁盘上。缓存的<term, docID>在本地磁盘上的存储位置将被回传给 master,由 master 负责把这些存储位置再传送给 Reduce worker
- 当 Reduce worker 程序接收到 master 程序发来的数据存储位置信息后,使用 RPC 从 Map worker 所在主机的磁盘上读取这些缓存数据。当 Reduce worker 读取了所有的中间数据后,通过对 term 进行排序后使得具有相同 key 值的数据聚合在一起。由于许多不同的 term 值会映射到相同的 Reduce 任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序。
- Reduce worker 程序遍历排序后的中间数据,对于每一个唯一的中间 term 值,Reduce worker 程序将这个 term 值和它相关的中间 value 值的集合传递给用户自定义的 Reduce 函数。Reduce 函数的输出被追加到所属分区的输出文件。
- 当所有的 Map 和 Reduce 任务都完成之后,master 唤醒用户程序。在这个时候,在用户程序里的对 MapReduce 调用才返回。
TF-IDF:
当然,TF-IDF的计算可以被简洁地表示为以下两个公式:
-
Term Frequency (词频):
$$ TF(t) = \frac{\text{Term在文档中出现的次数}}{\text{总的Term数}} $$ -
Inverse Document Frequency (逆文档频率):
$$ IDF(t) = \log_e\left(\frac{\text{文档总量}}{\text{包含Term的文档数}}\right) $$
然后,一个词的TF-IDF值就是它的TF值和IDF值的乘积:
首先计算词的频率(TF),然后乘以它的逆文档频率(IDF)。
BM25(Best Matching 25):
是一种用于信息检索(Information Retrieval)和文本挖掘的算法,它被广泛应用于搜索引擎和相关领域。BM25 基于 TF-IDF(Term Frequency-Inverse Document Frequency)的思想,但对其进行了改进以考虑文档的长度等因素。
一.基本思想
- TF-IDF 的改进: BM25 通过对文档中的每个词项引入饱和函数(saturation function)和文档长度因子,改进了 TF-IDF 的计算。
- 饱和函数: 在 BM25 中,对于词项的出现次数(TF),引入了一个饱和函数来调整其权重。这是为了防止某个词项在文档中出现次数过多导致权重过大。
- 文档长度因子: BM25 考虑了文档的长度,引入了文档长度因子,使得文档长度对权重的影响不是线性的。这样可以更好地适应不同长度的文档。
二.计算方程
BM25,全称Best Matching 25,是一种在信息检索中常用的评分函数,用于评估文档与查询之间的相关性。它是TF-IDF的一种改进,考虑了词频(TF)和逆文档频率(IDF)以及文档长度等因素。
BM25的基本思想是:对于一个查询,如果一个文档中的查询词出现得越频繁,且在其他文档中出现得越少,那么这个文档与查询的相关性就越高。
BM25的具体计算公式如下:
其中:
-
$D$ 是文档,$Q$ 是查询,$q_i$ 是查询中的第$i$ 个词。 -
$f(q_i, D)$ 是词$q_i$ 在文档$D$ 中的频率。 -
$|D|$ 是文档$D$ 的长度,$avgdl$ 是所有文档的平均长度。 -
$k_1$ 和$b$ 是自由参数,通常可取$k_1=2.0$ 和$b=0.75$ 。 -
$IDF(q_i)$ 是词$q_i$ 的逆文档频率,用于衡量词的重要性。其计算公式通常为$\log \frac{N-n(q_i)+0.5}{n(q_i)+0.5}$ ,其中$N$ 是文档总数,$n(q_i)$ 是包含词$q_i$ 的文档数。如果一个词在许多文档中都出现,那么它的重要性就低;反之,如果一个词只在少数文档中出现,那么它的重要性就高。
- 请求路由
- 作用: 网关负责将来自客户端的HTTP请求正确路由到相应的后端服务(如用户模块、收藏夹模块等)。这是通过HTTP框架gin实现的,它处理所有入站请求并根据路由配置将它们分发到适当的处理程序。
- 协议转换
- 作用: 网关需要处理协议转换,即将HTTP请求转换为gRPC请求,以便与使用gRPC框架的内部服务进行通信。这确保了不同服务之间的无缝数据交互。
- 负载均衡
- 作用: 网关可以与etcd服务发现结合使用,动态地了解后端服务的实例信息,并进行智能负载均衡。这有助于提高系统的整体性能和可用性。
- 安全性和认证
- 作用: 网关是所有请求的入口点,可以在这一层实现安全策略,如请求认证、权限验证和数据加密,保护系统免受未授权访问。
- 日志和监控
- 作用: 网关可以在此处实施日志记录和性能监控,为系统的稳定运行提供数据支持。
用户表
type User struct {
UserID int64 `gorm:"primarykey"`
UserName string `gorm:"unique"`
NickName string
PasswordDigest string
}
输入数据表
type InputData struct {
Id int64 `gorm:"primarykey"`
DocId int64 `gorm:"index"`
Title string `gorm:"type:longtext"`
Body string `gorm:"type:longtext"`
Url string
Score float64
Source int
IsIndex bool
}
收藏表
type Favorite struct {
FavoriteID int64 `gorm:"primarykey"` // 收藏夹id
UserID int64 `gorm:"index"` // 用户id
FavoriteName string `gorm:"unique"` // 收藏夹名字
FavoriteDetail []*FavoriteDetail `gorm:"many2many:f_to_fd;"`
}
收藏详细表
type FavoriteDetail struct {
FavoriteDetailID int64 `gorm:"primarykey"`
UserID int64 // 用户id
UrlID int64 // url的id
Url string // url地址
Desc string // url的描述
Favorite []*Favorite `gorm:"many2many:f_to_fd;"`
}
当我们执行migrate操作之后,就会在 Favorite 和 FavoriteDetail 之间建立一张f_to_fd多对多的关系表,这张表中,就记录了Favorite和FavoriteDetail两者的关联关系。
负责存储倒排索引、TrieTree
BoltDB是一个用Go语言编写的键值对存储库,他的数据存储在一个单独的文件中,内部使用了B+树这种数据结构来存储和管理数据。
BoltDB的底层实现
BoltDB的核心是一个B+树的实现。在BoltDB中,每个事务都对应一个B+树,这个B+树的根节点是一个bucket。bucket可以包含键值对,也可以包含其他bucket。这种设计使得BoltDB可以支持多级的键值对存储。
BoltDB使用内存映射文件(mmap)来将数据库文件映射到内存中,这样可以将文件I/O操作转化为内存操作,提高数据访问的效率。同时,BoltDB使用一种称为MVCC(多版本并发控制)的技术来处理并发访问,这样可以在不使用锁的情况下支持多个读事务并发执行。
BoltDB存储倒排索引的优势
- 支持大规模数据:BoltDB使用内存映射文件和MVCC技术,可以处理大规模的数据并支持高并发访问。
- **事务支持:**倒排索引的更新通常需要在多个步骤中完成,例如,首先从索引中删除一个文档,然后再添加一个新的文档。BoltDB的事务支持可以确保这些更新操作的原子性,防止在更新过程中出现数据不一致的情况。
- **持久化:**倒排索引通常需要持久化到磁盘,以便在程序重新启动时可以重新加载。BoltDB可以将数据持久化到磁盘,而无需进行复杂的序列化和反序列化操作。
使用roaring bitmap存储倒排索引,多词搜索时对每个词的bitmap取交集,而后对得到的文档进行打分。
选取roaring bitmap的原因:
- 高效的空间利用率
Roaring Bitmap以一种高度压缩的形式存储整数集合,这对于索引存储尤其重要。考虑到索引可能需要存储大量的文档ID集合,Roaring Bitmap能够有效减少所需的存储空间,同时保持快速访问能力。
- 快速的集合操作
搜索引擎在处理查询时经常需要执行集合操作(如并集、交集、差集等)。Roaring Bitmap针对这些操作进行了优化,能够提供比传统位图更快的操作速度,这对于提高查询响应时间至关重要。
- 适应性强
Roaring Bitmap能够高效处理不同密度的数据集。无论是稀疏还是密集的索引,Roaring Bitmap都能够自动选择最优的存储策略,确保性能和空间使用的平衡。
- 支持大规模数据
随着索引数据量的增长,Roaring Bitmap显示出良好的可伸缩性。它能够处理大量数据而不会显著降低性能,这对于全文搜索引擎来说是一个重要的特性。