Note
This project is still under development.
- Conducting Research on Patents Analysis, AI Methods, and Adoption/Innovation Models.
- Collecting patents data from the USPTO database.
- Modeling UAV Technologies using S-Curve Adoption/Innovation Difussion Model.
- Data Preprocessing: Data Cleaning, Formatting, Feature Engineering (
['SECTION','YEAR'])- One Hot Encoding
- Missing Values
- Exploratory Data Analysis (EDA)
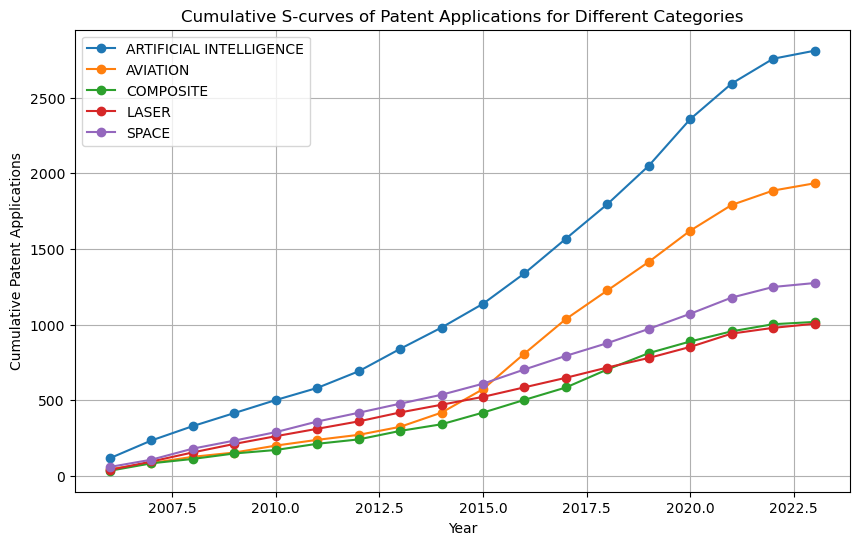
- Innovation Models (S-Curve, Logistic Growth Model)
- SSTT Taxonomy Classificator Model
- Cluster
This project implement machine learning - particularly deep learning methods - to model and predict the adoption process of technology. Utilizing feed-forward multilayered neural networks (such as CNN or RNN or combination). The aim is to compare and evaluate the results from adoption models such as S Curve, BASS Diffusion Model, Pearl, Gompertz, and Logistic Model. Hence, it is to understand, model, predict the rate of technology adoption and informing strategies for enhancing the integration of technologies.
forecasting-tech-adoption/
├── data/ # Data files
│ ├── raw/
│ └── processed/
├── img/ # Images
├── notebooks/ # Jupyter notebooks
├── src/ # Source code
├── docs/ # Project documentation
├── .gitattributes
├── .gitignore
└── README.md
-
DATA COLLECTION
- Data collection focused on patent databases from the United States Patent and Trademark Office (USPTO), the European Patent Office (EPO), and TÜRKPATENT for regional markets. Additionally, the World Intellectual Property Organization (WIPO) PatentScope, Google Patents, and academic research databases will be utilized for broader global coverage.
- The Harvard USPTO Dataset (HUPD)
is a large-scale, well-structured, and multi-purpose corpus of English-language utility patent applications filed to the United States Patent and Trademark Office (USPTO) between January 2004 and December 2018.
-
CLASSIFICATION/ TAXONOMY ALIGNMENT
- Turkish Defense Industry Technology Taxonomy (Savunma Sanayii Teknoloji Taksonomisi)
- Underpinning technologies (TEMEL TEKNOLOJİLER)
- Design technologies for platforms and weapons (PLATFORM VE SİLAHLAR İÇİN TASARIM TEKNOLOJİLERİ)
- Systems and products (SİSTEMLER VE ÜRÜNLER)
- Patent Categorization
- The goal is to categorize patent applications into predefined categories within the Turkish Defence Industry Technology Taxonomy.
- Turkish Defense Industry Technology Taxonomy (Savunma Sanayii Teknoloji Taksonomisi)
-
DATA ANALYSIS AND PREPROCESSING
- After the dataset is ready to use and classified according to SSTT, we will begin to process it.
- Data Analysis will be implemented to inspect, cleanse, transform, and model data to discover useful information, inform conclusions, and support decision-making.
-
PREDICTION MODELING
- The aim is to predict the adoption process of technology, informing strategies for enhancing technology integration.
- A time-series prediction model, such as a recurrent neural network (RNN) or a combination of architectures, potentially suitable for capturing temporal dependencies in the adoption process.