Hi,大家好,这里是我的工作日常记录(总结)部分内容来自于大佬,欢迎大家参观,主要内容分为:HTML(layout)、CSS、JS、性能优化问题、算法、网络安全、HTTP、浏览器、React 、闲聊问题。
介绍一下 BFC
一、常见定位方案
在讲 BFC 之前,我们先来了解一下常见的定位方案,定位方案是控制元素的布局,有三种常见方案:
普通流 (normal flow) 在普通流中,元素按照其在 HTML 中的先后位置至上而下布局,在这个过程中,行内元素水平排列,直到当行被占满然后换行,块级元素则会被渲染为完整的一个新行,除非另外指定,否则所有元素默认都是普通流定位,也可以说,普通流中元素的位置由该元素在 HTML 文档中的位置决定。
浮动 (float) 在浮动布局中,元素首先按照普通流的位置出现,然后根据浮动的方向尽可能的向左边或右边偏移,其效果与印刷排版中的文本环绕相似。
绝对定位 (absolute positioning)
在绝对定位布局中,元素会整体脱离普通流,因此绝对定位元素不会对其兄弟元素造成影响,而元素具体的位置由绝对定位的坐标决定。
二、BFC 概念
Formatting context(格式化上下文) 是 W3C CSS2.1 规范中的一个概念。它是页面中的一块渲染区域,并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。
那么 BFC 是什么呢?
BFC 即 Block Formatting Contexts (块级格式化上下文),它属于上述定位方案的普通流。
具有 BFC 特性的元素可以看作是隔离了的独立容器,容器里面的元素不会在布局上影响到外面的元素,并且 BFC 具有普通容器所没有的一些特性。
通俗一点来讲,可以把 BFC 理解为一个封闭的大箱子,箱子内部的元素无论如何翻江倒海,都不会影响到外部。
三、触发 BFC
只要元素满足下面任一条件即可触发 BFC 特性:
body 根元素
浮动元素:float 除 none 以外的值
绝对定位元素:position (absolute、fixed)
display 为 inline-block、table-cells、flex
overflow 除了 visible 以外的值 (hidden、auto、scroll)
DOM 渲染过程
DOM 渲染流程
渲染引擎——webkit 和 Gecko
Firefox 使用 Geoko——Mozilla 自主研发的渲染引擎
Safari 和 Chrome 都使用 webkit,Webkit 是一款开源渲染引擎
dom + cssom -> reder tree -> layout
浏览器渲染过程
二、渲染机制
1、DOCTYPE作用:用来声明文档类型和DTD规范,用途:文件的合法性验证
HTML4.0有一个严格模式(不包括展示性的和弃用的元素)和一个传统模式(包括)
2、浏览器如何渲染:
(1)解析HTML形成DOM Tree
(2)解析css产生css规则树(css rule tree)
(3)根据DOM Tree和css规则树来构造rendering Tree
(4)下一步操作称之为Layout,用来计算每个节点在屏幕中的位置
(5)绘制,即遍历render树,使用UI后端层绘制每个节点
Reflow:重排,当某个部分发生了变化影响了布局,就需要倒回去重新渲染
原因:
(1)增加、较少DOM节点
(2)修改css样式的时候
(3)修改网页的默认字体时
避免:
(1)HTML元素使用fixed或absolute,不会引起reflow
(2)使用预先定义好的css的class,修改DOM的className
Repaint:重绘,只改变某个元素的背景颜色,不影响元素周围或内部布局属性,将只会引起浏览器的repaint,重画某一部分
原因:
(1)操作DOM节点
(2)修改css样式
减少repaint:
(1)新建一个节点,将最终的结果放进去,一次性插入
DOM 渲染流程:
1、浏览器解析 html 源码,然后创建一个 DOM 树。
在 DOM 树中,每一个 HTML 标签都有一个对应的节点(元素节点),并且每一个文本也都有一个对应的节点(文本节点)。DOM 树的根节点就是 documentElement,对应的是 html 标签。
2、浏览器解析 CSS 代码,计算出最终的样式数据。
对 CSS 代码中非法的语法它会直接忽略掉。解析 CSS 的时候会按照如下顺序来定义优先级:浏览器默认设置,用户设置,外联样式,内联样式,html 中的 style(嵌在标签中的行间样式)。
3、创建完 DOM 树并得到最终的样式数据之后,构建一个渲染树。
渲染树和 DOM 树有点像,但是有区别。DOM 树完全和 html 标签一一对应,而渲染树会忽略不需要渲染的元素(head、display:none 的元素)。渲染树中每一个节点都存储着对应的 CSS 属性。
4、当渲染树创建完成之后,浏览器就可以根据渲染树直接把页面绘制到屏幕上。
data-name、data-age 等 HTML5 自定义属性
1、H5 自定义属性新特性。
title 的作用
网站标题信息
有利于 SEO 引擎搜索
更友好、语义化
script 是什么
类似于运行器 <script>标签,立刻唤醒 JavaScript 解析器来解析 js 代码。
defer 和 async 的区别
1、 <script src="script.js"> 没有 defer 或 async,浏览器会立即加载并执行指定的脚本,“立即”指的是在渲染该 script 标签之下的文档元素之前,也就是说不等待后续载入的文档元素,读到就加载并执行。
2、 <script async src="script.js"> 有 async,加载和渲染后续文档元素的过程将和 script.js 的加载与执行并行进行(异步)。
3、 <script defer src="myscript.js"> 有 defer,加载后续文档元素的过程将和 script.js 的加载并行进行(异步),但是 script.js 的执行要在所有元素解析完成之后,DOMContentLoaded 事件触发之前完成。
从实用角度来说,首先把所有脚本都丢到 </body> 之前是最佳实践,因为对于旧浏览器来说这是唯一的优化选择,此法可保证非脚本的其他一切元素能够以最快的速度得到加载和解析。
defer 和 async 在网络读取(下载)这块儿是一样的,都是异步的(相较于 HTML 解析)
它俩的差别在于脚本下载完之后何时执行,显然 defer 是最接近我们对于应用脚本加载和执行的要求的。
关于 defer,此图未尽之处在于它是按照加载顺序执行脚本的,这一点要善加利用
async 则是一个乱序执行的主,反正对它来说脚本的加载和执行是紧紧挨着的,所以不管你声明的顺序如何,只要它加载完了就会立刻执行
仔细想想,async 对于应用脚本的用处不大,因为它完全不考虑依赖(哪怕是最低级的顺序执行),不过它对于那些可以不依赖任何脚本或不被任何脚本依赖的脚本来说却是非常合适的
CSS 权重优先级的认知
从 CSS 代码存放位置看权重优先级:内嵌样式 > 内部样式表 > 外联样式表。其实这个基本可以忽视之,大部分情况下 CSS 代码都是使用外联样式表。
从样式选择器看权重优先级:important > 内嵌样式 > ID > 类 > 标签 | 伪类 | 属性选择 > 伪对象 > 继承 > 通配符。
CSS 水平垂直居中
1.position
.center {
background: red;
width: 100px;
height: 100px;
position: absolute;
top: 0;
bottom: 0;
left: 0;
right: 0;
margin: auto;
}
/* or */
.center {
background: red;
width: 100px;
height: 100px;
position: absolute;
top: 50%;
left: 50%;
margin: -50px 0 0 -50px;
}
**元素宽高未知 css**
.center {
color: red;
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%,-50%);
}2.flex 布局
<div class="wrap">
<div class="item">test</div>
</div>.wrap {
width: 100%;
height: 100vh;
display: flex;
align-items: center;
justify-content: center;
}
.item {
color: red;
}3.使用伪类
<div class="wrap">
<div class="item">test</div>
</div>.wrap {
width: 100%;
height: 100%;
background-color: #009ef4;
text-align: center;
position: absolute;
top: 0;
left: 0;
}
.wrap:after {
display: inline-block;
content: '';
width: 0;
height: 100%;
vertical-align: middle;
}
.item {
color: red;
display: inline-block;
vertical-align: middle;
}4.使用表格
<div class="wrap">
<div class="item">test</div>
</div>.wrap {
width: 100%;
height: 100vh;
display: table;
}
.item {
color: #F00;
display: table-cell;
vertical-align: middle;
text-align: center;
}css 三角形的实现
三角形实现原理:宽度 width 为 0;height 为 0;
(1)有一条横竖边(上下左右)的设置为 border-方向:长度 solid red,这个画的就是底部的直线。其他边使用 border-方向:长度 solid transparent。
(2)有两个横竖边(上下左右)的设置,若斜边是在三角形的右边,这时候设置 top 或 bottom 的直线,和右边的斜线。若斜边是在三角形的左边,这时候设置 top 或 bottom 的直线,和左边的斜线。
#triangle-up {
width: 0;
height: 0;
border-left: 50px solid transparent;
border-right: 50px solid transparent;
border-bottom: 100px solid red;
}关于CSS Modules全局污染解决
问题:
当我们设置如下样式的时候,整个项目的所有表格的td都会按照下面的样式跟着改动。 也就是说,我们要对元素标签进行设置的时候全局作用域的优点就变成了全局污染这个缺点了。
tbody tr td{
text-align: center!important;
color: #00cc00
}这就是css Modules的全局污染! 按照正常的思维,我们在页面引入哪个css文件,就会只是在当前页面中起作用。(引入:import styles from '../styles.css';)
解决:
我们的解决方案是加上局部作用域:local看一下具体代码如何实现吧。
(1):local(.类名)
:local(.biaoge-duli){
tbody tr td{
text-align: center!important;
color: #00cc00
}
}(2)页面引用
import styles from '../styles.css';//对应的文件名<Table className={styg['biaoge-duli']} />对于这个问题就解决了。 对于此类的问题,需要对标签的元素进行样式操作而又无法直接在对应的标签元素加上class名就这样解决了。
最后,总结一下:local的用法。
:local(.className) { background: red; }
:local .className { color: green; }
:local(.className .subClass) { color: green; }盒模型
CSS 盒模型本质上是一个盒子,封装周围的 HTML 元素,它包括:边距,边框,填充,和实际内容。
内容(content)、内边距(padding)、边框(border)、外边距(margin), CSS 盒子模型都具备这些属性。
标准盒模型和怪异盒模型的区别
css 盒模型本质是一个盒子,它由边距、边框、填充和实际内容组成。盒模型能够让我们在其他元素和周边元素边框之间的空间放置元素。
标准盒与怪异盒的区别在于他们的总宽度的计算公式不一样。标准模式下总宽度=width+margin(左右)+padding(左右)border(左右);怪异模式下总宽度=width+margin(左右)(就是说 width 已经包含了 padding 和 border 值)。标准模式下如果定义的 DOCTYPE 缺失,则在 ie6、ie7、ie8 下汇触发怪异模式。当设置为 box-sizing:content-box 时,将采用标准模式解析计算,也是默认模式;当设置为 box-sizing:border-box 时,将采用怪异模式解析计算;
宽度不定,如何实现三个元素按照 1:1:1 布局
父元素:display: flex;
子集:flex:1;
Navigator.sendBeacon()
navigator.sendBeacon() 方法可用于通过HTTP将少量数据异步传输到Web服务器。
navigator.sendBeacon(url, data);
url
url 参数表明 data 将要被发送到的网络地址。
data
data 参数是将要发送的 ArrayBufferView 或 Blob, DOMString 或者 FormData 类型的数据。
JS 数据类型:JS 的数据类型有几种?
8 种,Number、String、Boolean、Null、undefined、object、symbol、bigInt。
JS 数据类型:Object 中包含了哪几种类型?
其中包含了Date、function、Array等。这三种是常规用的。
JS 数据类型:JS 的基本类型和引用类型有哪些呢?
基本类型(单类型):除Object。 String、Number、boolean、null、undefined。
引用类型:object。里面包含的 function、Array、Date。
JS 实现深浅拷贝
1.浅拷贝 实现
let copy1 = {...{x:1}} bject.assign实现
let copy2=Object.assign({}, {x:1})
2.深拷贝
// 1. JOSN.stringify() //JSON.parse()
let obj={a: 1, b: {x: 3}};
JSON.parse(JSON.stringify(obj))- 递归拷贝
function deepClone(obj) {
let copy = obj instanceof Array ? [] : {}
for (let i in obj) {
if (obj.hasOwnProperty(i)) {
copy[i] = typeof obj[i] === 'object'?deepClone(obj[i]) : obj[i] }
}
return copy
}作用域和作用域链
一、作用域在 Javascript 中,作用域分为 全局作用域 和 函数作用域
全局作用域:
代码在程序的任何地方都能被访问,window 对象的内置属性都拥有全局作用域。
函数作用域:
在固定的代码片段才能被访问
二、作用域链一般情况下,变量取值到 创建 这个变量 的函数的作用域中取值。
但是如果在当前作用域中没有查到值,就会向上级作用域去查,直到查到全局作用域,这么一个查找过程形成的链条就叫做作用域链。
闭包&&原型链
-
闭包
概念:闭包就是能够读取其他函数内部变量的函数。由于在 Javascript 语言中,只有函数内部的子函数才能读取局部变量,因此可以把闭包简单理解成“定义在一个函数内部的函数”。所以,在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁。
例子:函数 b 就是一个闭包函数,用于获取函数 a 内部的变量 i。当函数 a 的内部函数 b,被函数 a 外的一个变量 c 引用的时候,就创建了一个闭包。
作用:闭包可以用在许多地方。它的最大用处有两个
可以读取函数内部的变量 让这些变量的值始终保持在内存中 注意事项:
1)由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在 IE 中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
2)闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
2.原型链
原型:所有的函数都有一个特殊的属性 prototype(原型),prototype 属性是一个指针,指向的是一个对象(原型对象),原型对象中的方法和属性都可以被函数的实例所共享。所谓的函数实例是指以函数作为构造函数创建的对象,这些对象实例都可以共享构造函数的原型的方法。
原型链:原型链是用于查找引用类型(对象)的属性,查找属性会沿着原型链依次进行,如果找到该属性会停止搜索并做相应的操作,否则将会沿着原型链依次查找直到结尾。常见的应用是用在创建对象和继承中。
1、JavaScript 语言是单线程的,同一个时间只能做一件事; 2、遵循事件循环机制,当 JS 解析执行时,会被引擎分为两类任务,同步任务(synchronous) 和 异步任务(asynchronous)。对于同步任务来说,会被推到执行栈按顺序去执行这些任务。对于异步任务来说,当其可以被执行时,会被放到一个 任务队列(task queue) 里等待 JS 引擎去执行。当执行栈中的所有同步任务完成后,JS 引擎才会去任务队列里查看是否有任务存在,并将任务放到执行栈中去执行,执行完了又会去任务队列里查看是否有已经可以执行的任务。这种循环检查的机制,就叫做事件循环(Event Loop)。对于任务队列,其实是有更细的分类。其被分为 微任务(microtask)队列 & 宏任务(macrotask)队列。
同步任务
微任务
process.nextTick
MutationObserver
Promise.then catch finally宏任务
I/O
setTimeout
setInterval
setImmediate
requestAnimationFrame执行完一轮宏任务执行微任务 继续执行宏任务 event loop~
DOMContentLoaded 和 window.onload 的区别
何时触发这两个事件?
1、当 onload 事件触发时,页面上所有的 DOM,样式表,脚本,图片,flash 都已经加载完成了。 2、当 DOMContentLoaded 事件触发时,仅当 DOM 加载完成,不包括样式表,图片,flash。
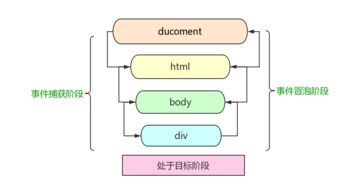
DOM 事件流的顺序
DOM 事件流包括三个阶段: 事件捕获阶段 处于目标阶段 事件冒泡阶段
事件捕获阶段 => 处于目标阶段 => 事件冒泡阶段 在这个过程中可以使用 event.stopPropagation();来阻止这个过程继续执行; 而 addEventListener()的第三个参数为:true 则表示将事件绑定在捕获阶段,false 表示将事件绑定在冒泡阶段;
捕获阶段:从 window 对象传导到目标节点(上层传到底层)称为“捕获阶段”(capture phase),捕获阶段不会响应任何事件; 目标阶段:在目标节点上触发,称为“目标阶段” 冒泡阶段:从目标节点传导回 window 对象(从底层传回上层),称为“冒泡阶段”(bubbling phase)。事件代理即是利用事件冒泡的机制把里层所需要响应的事件绑定到外层;
stopPropagation
event.stopPropagation();阻止事件冒泡。
stopImmediatePropagation
event.stopImmediatePropagation(); 阻止事件冒泡并且阻止该元素上同事件类型的监听器被触发。
事件委托
1、可以大量节省内存占用,减少事件注册,比如在 ul 上代理所有 li 的 click 事件就非常棒 2、可以实现当新增子对象时无需再次对其绑定(动态绑定事件)
setTimeout、Promise、Async、Await 异步原理和执行顺序
ES6 的新增功能
1.Default Parameters(默认参数) in ES6
2.Template Literals(模板对象) in ES6
3.Multi-line Strings (多行字符串)in ES6
4.Destructuring Assignment (解构赋值)in ES6
5.Arrow Functions in(箭头函数) ES6
6.Promises in ES6
7.Block-Scoped Constructs Let and Const(块作用域 let 和 const)
8.Classes (类)in ES6
9.Modules (模块)in ES6import虽然属于声明命令,但它是和export命令配合使用的。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。ES6 为字符串扩展了几个新的 API:
includes():返回布尔值,表示是否找到了参数字符串。
startsWith():返回布尔值,表示参数字符串是否在原字符串的头部。
endsWith():返回布尔值,表示参数字符串是否在原字符串的尾部。1.Set
ES6 提供了新的数据结构 Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
Set本身是一个构造函数,用来生成 Set 数据结构。
成员唯一、无序且不重复;
[value, value],键值与键名是一致的(或者说只有键值,没有键名);
可以遍历,方法有:add、delete、has。
2.WeakSet
WeakSet 结构与 Set 类似,也是不重复的值的集合。但是,它与 Set 有两个区别。
成员都是对象;
成员都是弱引用,可以被垃圾回收机制回收,可以用来保存 DOM 节点,不容易造成内存泄漏;
不能遍历,方法有 add、delete、has。
3.Map
JavaScript 的对象(Object),本质上是键值对的集合(Hash 结构),但是传统上只能用字符串当作键。这给它的使用带来了很大的限制。
可以遍历,方法很多,可以跟各种数据格式转换。
4.WeakMap
WeakMap结构与Map结构类似,也是用于生成键值对的集合。
只接受对象最为键名(null 除外),不接受其他类型的值作为键名;
键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的;
不能遍历,方法有 get、set、has、delete。
ES6中的迭代器(Iterator)和生成器(Generator)
新的数组方法和新的集合类型(如Set集合与Map集合)都依赖迭代器的实现,这个新特性对于高效的数据处理而言是不可或缺的,在语言的其他特性中也都有迭代器的身影:新的for-of循环、展开运算符(...),甚至连异步编程都可以使用迭代器。
下面是一段标准的for循环代码,通过变量i来跟踪colors数组的索引,循环每次执行时,如果i小于数组长度len则加1,并执行下一次循环
迭代器(Iterator)
var colors = ["red", "green", "blue"];
for (var i = 0, len = colors.length; i < len; i++) {
console.log(colors[i]);
}虽然循环语句语法简单,但如果将多个循环嵌套则需要追踪多个变量,代码复杂度会大大增加,一不小心就错误使用了其他for循环的跟踪变量,从而导致程序出错。迭代器的出现旨在消除这种复杂性并减少循环中的错误
ES5 版本迭代器
function createIterator(items) {
var i = 0;
return {
next: function() {
var done = (i >= items.length);
var value = !done ? items[i++] : undefined;
return {
done: done,
value: value
};
}
};
}
var iterator = createIterator([1, 2, 3]);
console.log(iterator.next()); // "{ value: 1, done: false }"
console.log(iterator.next()); // "{ value: 2, done: false }"
console.log(iterator.next()); // "{ value: 3, done: false }"
console.log(iterator.next()); // "{ value: undefined, done: true }"
// 之后的所有调用
console.log(iterator.next()); // "{ value: undefined, done: true }"在上面这段代码中,createIterator()方法返回的对象有一个next()方法,每次调用时,items数组的下一个值会作为value返回。当i为3时,done变为true;此时三元表达式会将value的值设置为undefined。最后两次调用的结果与ES6迭代器的最终返回机制类似,当数据集被用尽后会返回最终的内容
上面这个示例很复杂,而在ES6中,迭代器的编写规则也同样复杂,但ES6同时还引入了一个生成器对象,它可以让创建迭代器对象的过程变得更简单
生成器(Generator)
生成器是一种返回迭代器的函数,通过function关键字后的星号(*)来表示,函数中会用到新的关键字yield。星号可以紧挨着function关键字,也可以在中间添加一个空格。
// 生成器
function *createIterator() {
yield 1;
yield 2;
yield 3;
}
// 生成器能像正规函数那样被调用,但会返回一个迭代器
let iterator = createIterator();
console.log(iterator.next().value); // 1
console.log(iterator.next().value); // 2
console.log(iterator.next().value); // 3在这个示例中,createlterator()前的星号表明它是一个生成器;yield关键字也是ES6的新特性,可以通过它来指定调用迭代器的next()方法时的返回值及返回顺序。生成迭代器后,连续3次调用它的next()方法返回3个不同的值,分别是1、2和3。生成器的调用过程与其他函数一样,最终返回的是创建好的迭代器
生成器函数最有趣的部分是,每当执行完一条yield语句后函数就会自动停止执行。举个例子,在上面这段代码中,执行完语句yield 1之后,函数便不再执行其他任何语句,直到再次调用迭代器的next()方法才会继续执行yield 2语句。生成器函数的这种中止函数执行的能力有很多有趣的应用
使用yield关键字可以返回任何值或表达式,所以可以通过生成器函数批量地给迭代器添加元素。例如,可以在循环中使用yield关键字
function *createIterator(items) {
for (let i = 0; i < items.length; i++) {
yield items[i];
}
}
let iterator = createIterator([1, 2, 3]);
console.log(iterator.next()); // "{ value: 1, done: false }"
console.log(iterator.next()); // "{ value: 2, done: false }"
console.log(iterator.next()); // "{ value: 3, done: false }"
console.log(iterator.next()); // "{ value: undefined, done: true }"
// 之后的所有调用
console.log(iterator.next()); // "{ value: undefined, done: true }"在此示例中,给生成器函数createlterator()传入一个items数组,而在函数内部,for循环不断从数组中生成新的元素放入迭代器中,每遇到一个yield语句循环都会停止;每次调用迭代器的next()方法,循环会继续运行并执行下一条yield语句
生成器函数是ES6中的一个重要特性,可以将其用于所有支持函数使用的地方
【使用限制】
yield关键字只可在生成器内部使用,在其他地方使用会导致程序抛出错误
function *createIterator(items) {
items.forEach(function(item) {
// 语法错误
yield item + 1;
});
}从字面上看,yield关键字确实在createlterator()函数内部,但是它与return关键字一样,二者都不能穿透函数边界。嵌套函数中的return语句不能用作外部函数的返回语句,而此处嵌套函数中的yield语句会导致程序抛出语法错误
【生成器函数表达式】
也可以通过函数表达式来创建生成器,只需在function关键字和小括号中间添加一个星号(*)即可
let createIterator = function *(items) {
for (let i = 0; i < items.length; i++) {
yield items[i];
}
};
let iterator = createIterator([1, 2, 3]);
console.log(iterator.next()); // "{ value: 1, done: false }"
console.log(iterator.next()); // "{ value: 2, done: false }"
console.log(iterator.next()); // "{ value: 3, done: false }"
console.log(iterator.next()); // "{ value: undefined, done: true }"
// 之后的所有调用
console.log(iterator.next()); // "{ value: undefined, done: true }"在这段代码中,createlterator()是一个生成器函数表达式,而不是一个函数声明。由于函数表达式是匿名的,因此星号直接放在function关键字和小括号之间。此外,这个示例基本与前例相同,使用的也是for循环
[注意]不能用箭头函数来创建生成器
【生成器对象的方法】
由于生成器本身就是函数,因而可以将它们添加到对象中。例如,在ES5风格的对象字面量中,可以通过函数表达式来创建生成器
var o = {
createIterator: function *(items) {
for (let i = 0; i < items.length; i++) {
yield items[i];
}
}
};
let iterator = o.createIterator([1, 2, 3]);也可以用ES6的函数方法的简写方式来创建生成器,只需在函数名前添加一个星号(*)
var o = {
*createIterator(items) {
for (let i = 0; i < items.length; i++) {
yield items[i];
}
}
};
let iterator = o.createIterator([1, 2, 3]);这些示例使用了不同于之前的语法,但它们的功能实际上是等价的。在简写版本中,由于不使用function关键字来定义createlterator()方法,因此尽管可以在星号和方法名之间留白,但还是将星号紧贴在方法名之前
更多内容请看 https://www.cnblogs.com/xiaohuochai/p/7253466.html
浅谈JS中的装饰器
什么是装饰器?
装饰器模式(Decorator Pattern)是一种结构型设计模式,旨在促进代码复用,可以用于修改现有的系统,希望在系统中为对象添加额外的功能,同时又不需要大量修改原有的代码。JS中的装饰器是ES7中的一个新语法,可以对类、方法、属性进行修饰,从而进行一些相关功能定制, 它的写法与Java的注解(Annotation)类似,但是功能有比较大的区别。
大家可能听说过 组合函数 和 高阶函数 的概念,也可以这么理解。
https://www.jianshu.com/p/c8a5d4f50780
JS 错误监控
1、try-catch
总结: 只能捕获捉到运行时非异步错误,异步错误就显得无能为力,捕捉不到
2、window.onerror
同步错误捕获
3、资源加载错误
object.onerror
如script,image等标签src引用,会返回一个event对象 ,TIPS: object.onerror不会冒泡到window对象,所以window.onerror无法监控资源加载错误
var img = new Image();
img.src = 'http://xxx.com/xxx.jpg';
img.onerror = function(event) {
console.log(event);
}performance.getEntries()
返回已成功加载的资源列表,然后自行做比对差集运算,核实哪些文件没有加载成功
var result = [];
window.performance.getEntries().forEach(function (perf) {
result.push({
'url': perf.name,
'entryType': perf.entryType,
'type': perf.initiatorType,
'duration(ms)': perf.duration
});
});
console.log(result);Error事件捕获 (全局监控静态资源异常)
window.addEventListener('error', (msg, url, row, col, error) => {
console.log('我知道 404 错误了');
console.log(
msg, url, row, col, error
);
return false;
}, true);4、全局去捕获promise error
window.addEventListener("unhandledrejection", function(e) {
e.preventDefault()
console.log('我知道 promise 的错误了');
console.log(e.reason);
return true;
});
Promise.reject('promise error').catch((err)=>{
console.log(err);
})
new Promise((resolve, reject) => {
reject('promise error');
}).catch((err)=>{
console.log(err);
})
new Promise((resolve) => {
resolve();
}).then(() => {
throw 'promise error'
});
new Promise((resolve, reject) => {
reject(123);
})5、跨域错误能捕获吗?可以
(1)客户端:在script标签中加crossorigin属性
<script crossorigin src="http://www.lmj.com/demo/crossoriginAttribute/error.js"></script>(2)服务端:在响应头Access-Control-Allow-Origin:域名或*
6、上报错误的基本原理
(1)采用Ajax通信的方式上报
(2)利用Image对象上报
src 和 href 区别
href 用于建立当前页面与引用资源之间的关系(链接),而 src 则会替换当前标签。遇到 href,页面会并行加载后续内容;而 src 则不同,浏览器需要加载完毕 src 的内容才会继续往下走。
通过解析过程了解 JavaScript
什么是 Javascript 解析引擎? Javascript 解析引擎(简称 Javascript 引擎),是一个程序,是浏览器引擎的一个部分。
每个浏览器的 Javascript 解析引擎都不相同(因为每个浏览器编写 Javascript 解析引擎的语言(C 或者 C++)以及解析原理都不相同)。标准的 Javascript 解析引擎会按照 ECMAScript 文档来实现。虽然每个浏览器的 Javascript 解析引擎不同,但 Javascript 的语言性质决定了 Javascript 关键的渲染原理仍然是动态执行 Javascript 字符串。只是词法分析、语法分析、变量赋值、字符串拼接的实现方式有所不同。
JavaScript 解析引擎到底是干什么的? JavaScript 解析引擎就是根据 ECMAScript 定义的语言标准来动态执行 JavaScript 字符串。虽然之前说现在很多浏览器不全是按照标准来的,解释机制也不尽相同,但动态解析 JS 的过程还是分成两个阶段:语法检查阶段和运行阶段。
语法检查包括词法分析和语法分析,运行阶段又包括预解析和运行阶段(像 V8 引擎会将 JavaScript 字符串编译成二进制代码,此过程应该归到语法检查过程中)。
JavaScript 解析过程 在 JavaScript 解析过程中,如遇错误就直接跳出当前代码块,直接执行下一个 script 代码段。所以在同一个 script 内的代码段有错误的话就不会执行下去,但是不会影响下一个 script 内的代码段。
第一阶段:语法检查 语法检查也是 JavaScript 解析器的工作之一,包括 词法分析 和 语法分析,过程大致如下:
一:词法分析 词法分析:JavaScript 解释器先把 JavaScript 代码(字符串)的字符流按照 ECMAScript 标准转换为记号流。
例如:把字符流:
a = (b - c);
转换为记号流:
NAME "a"
EQUALS
OPEN_PARENTHESIS
NAME "b"
MINUS
NAME "c"
CLOSE_PARENTHESIS
SEMICOLON
二:语法分析
语法分析:JavaScript 语法分析器在经过词法分析后,将记号流按照 ECMAScript 标准把词法分析所产生的记号生成语法树。 通俗地说就是把从程序中收集的信息存储到数据结构中,每取一个词法记号,就送入语法分析器进行分析。
语法分析不做的事:去掉注释,自动生成文档,提供错误位置(可以通过记录行号来提供)。ECMAScript 标准如下:
var,if,else,break,continue 等是 JavaScript 的关键词 abstract,int,long 等是 JavaScript 保留词 怎么样算是数字、怎么样算是字符串等等 定义了操作符(+,-,=)等操作符 定义了 JavaScript 的语法 定义了对表达式,语句等标准的处理算法,比如遇到==该如何处理 …… 当语法检查正确无误之后,就可以进入运行阶段了。
第二阶段:运行阶段
一:预解析 第一步:JavaScript 引擎将语法检查正确后生成的语法树复制到当前执行上下文中。 第二步:JavaScript 引擎会对语法树当中的变量声明、函数声明以及函数的形参进行属性填充。
“预解析”从语法检查阶段复制过来的信息如下:
内部变量表 varDecls:varDecls 保存的用 var 进行显式声明的局部变量。 内嵌函数表 funDecls:在“预解析”阶段,发现有函数定义的时候,除了记录函数的声明外,还会创建一个原型链对象(prototype)。 …其他的信息。 执行上下文(execution context)
(一)预解析阶段创建的执行上下文包括:变量对象、作用域链、this
变量对象(Variable Object):由 var declaration、function declaration(变量声明、函数声明)、arguments(参数)构成。变量对象是以单例形式存在。 作用域链(Scope Chain):variable object + all parent scopes(变量对象以及所有父级作用域)构成。 this 值:(thisValue):content object。this 值在进入上下文阶段就确定了。一旦进入执行代码阶段,this 值就不会变了。 (二)“预解析”阶段创建执行上下文之后,还会对变量对象/活动对象(VO/AO)的一些属性填充数值。
函数的形参:执行上下文的变量对象的一个属性,其属性名就是形参的名字,其值就是实参的值;对于没有传递的参数,其值为 undefined。 函数声明:执行上下文的变量对象的一个属性,属性名和值都是函数对象创建出来的;如果变量对象已经包含了相同名字的属性,则会替换它的值。 变量声明:执行上下文的变量对象的一个属性,其属性名即为变量名,其值为 undefined;如果变量名和已经声明的函数名或者函数的参数名相同,则不会影响已经存在的函数声明的属性,该声明会被忽略掉,但其包含的赋值操作不会忽略。 变量对象/活动对象(VO/AO)填充的顺序也是按照以上顺序:函数的形参->函数声明->变量声明;在变量对象/活动对象(VO/AO)中权重高低也按照函数的形参->函数声明->变量声明顺序来。
如下代码:
var a=1;
function b(a) {
alert(a);
}
var b;
alert(b); // function b(a) { alert(a); }
b(); //undefined
变量对象/活动对象(VO/AO)填充及优先顺序
以上代码在进入执行上下文时,按照函数的形参->函数声明->变量声明顺序来填充,并且优先权永远都是函数的形参>函数声明>变量声明,所以只要 alert(a)中的 a 是函数中的形参,就永远不会被函数和变量声明覆盖。就算没有赋值也是默认填充的 undefined 值。
第二部分:执行代码 经过“预解析”创建执行上下文之后,就进入执行代码阶段,VO/AO 就会重新赋予真实的值,“预解析”阶段赋予的 undefined 值会被覆盖。
此阶段才是程序真正进入执行阶段,Javascript 引擎会一行一行的读取并运行代码。此时那些变量都会重新赋值。
假如变量是定义在函数内的,而函数从头到尾都没被激活(调用)的话,则变量值永远都是 undefined 值。
进入了执行代码阶段,在“预解析”阶段所创建的任何东西可能都会改变,不仅仅是 VO/AO,this 和作用域链也会因为某些语句而改变,后面会讲到。
了解完 Javascript 的解析过程最后我们再来了解下 firebug 的控制台对 Javascript 的报错提示吧。
其实 firebug 的控制台也算是 JavaScript 的解释器,而且他们会提示我们哪行出现了错误或者错误发生在哪个时期,语法检查阶段错误,还是运行期错误。
如下:
alert(var);// SyntaxError: syntax error 语法分析阶段错误 :语法错误
var=1;; // SyntaxError: missing variable name 语法分析阶段错误 :var是保留字符,导致变量名丢失
a=b=v // ReferenceError: v is not defined 运行期错误: v 是未定义的
JavaScript错误信息)
有如此详细的错误提示,是不是就很快就知道代码中到底是哪里错了呢!
接下来我们详细来介绍执行上下文中的一个重要概念——作用域链。
作用域链(Scope Chain)
作用域链是处理标识符时进行变量查询的变量对象列表,每个执行上下文都有自己的变量对象:对于全局上下文而言,其变量对象就是全局对象本身;对于函数而言,其变量对象就是活动对象。
作用域链以及执行上下文的关系
在 Javascript 中只有函数能规定作用域,全局执行上下文中的 Scope 是全局上下文中的属性,也是最外层的作用域链。
函数的属性[[Scope]]是在“预解析”的时候就已经存在的了,它包含了所有上层变量对象,并一直保存在函数中。就算函数永远都没被激活(调用),[[Scope]]也都还是存在函数对象上。
创建执行上下文的 Scope 属性和进入执行上下文的过程如下:
Scope = AO + [[Scope]] //预解析时的 Scope 属性 Scope = [AO].concat([[Scope]]); //执行阶段,将 AO 添加到作用域链的最前端 执行上下文定义的 Scope 属性变化过程
执行上下文中的[AO]是函数的活动对象,而[[Scope]]则是该函数属性作用域。当前函数的 AO 永远是在最前面的,保存在堆栈上,而每当函数激活的时候,这些 AO 都会压栈到该堆栈上,查询变量是先从栈顶开始查找,也就是说作用域链的栈顶永远是当前正在执行的代码所在环境的 VO/AO(当函数调用结束后,则会从栈顶移除)。
通俗点讲就是:JavaScript 解释器通过作用域链将不同执行位置上的变量对象串连成列表,并借助这个列表帮助 JavaScript 解释器检索变量的值。作用域链相当于一个索引表,并通过编号来存储它们的嵌套关系。当 JavaScript 解释器检索变量的值,会按着这个索引编号进行快速查找,直到找到全局对象为止,如果没有找到值,则传递一个特殊的 undefined 值。
是不是又想到了一条 JavaScript 高效准则:为什么说在该函数内定义的变量,能减少函数嵌套能提高 JavaScript 的效率?因为函数定义的变量,此变量永远在栈顶,这样子查询变量的时间变短了。
作用域的特性
保证查询有序的访问所有变量和函数 作用域链感觉就是一个 VO 链表,当访问一个变量时,先在链表的第一个 VO 上查找,如果没有找到则继续在第二个 VO 上查找,直到搜索结束,也就是搜索到全局执行环境的 VO 中。这也就形成了作用域链的概念。
var color="blue";
function changecolor(){
var anothercolor="red";
function swapcolors(){
var tempcolor=anothercolor;
anothercolor=color;
color=tempcolor; // Todo something
}
swapcolors();
}
changecolor();//这里不能访问 tempcolor 和 anocolor;但是可以访问 color;
alert("Color is now "+color);
作用域链保护变量安全
函数的作用域是在函数创建即“预解析”阶段就已经就已经定义了,而在代码执行阶段则是将函数的作用域添加到作用域链上。
原型链查询
在介绍“预解析”阶段时,我们有提到当创建函数时,同时也会创建原型链对象(prototype)函数天生的。原型链对象在作用域链中没有找到变量对象时,那么就会通过原型链来查找。
function Foo() {
function bar() {
alert(x);
}
bar();
}
Object.prototype.x = 10;
Foo(); // 10
上例中在作用域链中遍历查询,到了全局对象了,该对象继承自 Object.prototype,因此,最终变量“x”的值就变成了 10。不过,在原型链上定义变量对象有些浏览器不支持,譬如 IE6,而且这样增加了变量对象的查询时间。所以变量声明尽量在调用函数 AO 里,即在用到该变量的函数内声明变量对象。
作用域是在“预解析”时就已经决定的,所以作用域被叫做静态作用域,而在执行阶段的则被叫做动态链,因为在执行阶段会改变作用域链中填充的值。
手撕 简版 Promise
let myPromise = function (executor) {
let self = this; //缓存一下this
self.status = "pending"; // 状态管理 状态的变化只能由pending变为resolved或者rejected。一件事情不能既成功又失败。所以resolved和rejected不能相互转化。
self.value = undefined; // 成功后的值 传给resolve
self.reason = undefined; //失败原因 传给reject
self.onResolvedCallbacks = []; // 存放then中成功的回调
self.onRejectedCallbacks = []; // 存放then中失败的回调
// 这里说明一下,第三步使用定时器。执行完 new Promise 之后,会执行then方法,此时会把then中的方法缓存起来,并不执行:此时状态还是pending。等到定时器2秒之后,执行
// resolve|reject 时,而是依次执行存放在数组中的方法。 参考发布订阅模式
function resolve(value) {
// pending => resolved
if (self.status === "pending") {
self.value = value;
self.status = "resolved";
// 依次执行缓存的成功的回调
self.onResolvedCallbacks.forEach((fn) => fn(self.value));
}
}
function reject(reason) {
// pending => rejected
if (self.status === "pending") {
self.value = value;
self.status = "rejected";
// 依次执行缓存的失败的回调
self.onRejectedCallbacks.forEach((fn) => fn(self.reason));
}
}
try {
//new Promise 时 executor执行
executor(resolve, reject);
} catch (error) {
reject(error); // 当executor中执行有异常时,直接执行reject
}
};
// 每个Promise实例上都有then方法
Promise.prototype.then = function (onFulfilled, onRejected) {
let self = this;
// 执行了 resolve
if (self.status === "resolved") {
// 执行成功的回调
onFulfilled(self.value);
}
// 执行了 reject
if (self.status === "rejected") {
// 执行失败的回调
onRejected(self.reason);
}
// new Promise中可以支持异步行为 当既不执行resolve又不执行reject时 状态是默认的等待态pending
if (self.status === "pending") {
// 缓存成功的回调
self.onResolvedCallbacks.push(onFulfilled);
// 缓存失败的回调
self.onRejectedCallbacks.push(onRejected);
}
};Performance — 前端性能监控利器
Performance是一个做前端性能监控离不开的API,最好在页面完全加载完成之后再使用,因为很多值必须在页面完全加载之后才能得到。最简单的办法是在window.onload事件中读取各种数据。
属性
timing (PerformanceTiming)
已废弃 该特性已经从 Web 标准中删除,虽然一些浏览器目前仍然支持它,但也许会在未来的某个时间停止支持,请尽量不要使用该特性。
该属性在 Navigation Timing Level 2 specification 中已经被废弃,请使用 Performance.timeOrigin 替代。
timeOrigin
从输入url到用户可以使用页面的全过程时间统计,会返回一个PerformanceTiming对象,单位均为毫秒

按触发顺序排列所有属性:(更详细标准的解释请参看:W3C Editor's Draft)
navigationStart:在同一个浏览器上下文中,前一个网页(与当前页面不一定同域)unload 的时间戳,如果无前一个网页 unload ,则与 fetchStart 值相等
unloadEventStart:前一个网页(与当前页面同域)unload 的时间戳,如果无前一个网页
unload 或者前一个网页与当前页面不同域,则值为 0
unloadEventEnd:和 unloadEventStart 相对应,返回前一个网页 unload 事件绑定的回调函数执行完毕的时间戳
redirectStart:第一个 HTTP 重定向发生时的时间。有跳转且是同域名内的重定向才算,否则值为 0
redirectEnd:最后一个 HTTP 重定向完成时的时间。有跳转且是同域名内的重定向才算,否则值为 0
fetchStart:浏览器准备好使用 HTTP 请求抓取文档的时间,这发生在检查本地缓存之前
domainLookupStart:DNS 域名查询开始的时间,如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等
domainLookupEnd:DNS 域名查询完成的时间,如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等
connectStart:HTTP(TCP) 开始建立连接的时间,如果是持久连接,则与 fetchStart 值相等,如果在传输层发生了错误且重新建立连接,则这里显示的是新建立的连接开始的时间
connectEnd:HTTP(TCP) 完成建立连接的时间(完成握手),如果是持久连接,则与 fetchStart 值相等,如果在传输层发生了错误且重新建立连接,则这里显示的是新建立的连接完成的时间注意:这里握手结束,包括安全连接建立完成、SOCKS 授权通过
secureConnectionStart:HTTPS 连接开始的时间,如果不是安全连接,则值为 0
requestStart:HTTP 请求读取真实文档开始的时间(完成建立连接),包括从本地读取缓存,连接错误重连时,这里显示的也是新建立连接的时间
responseStart:HTTP 开始接收响应的时间(获取到第一个字节),包括从本地读取缓存
responseEnd:HTTP 响应全部接收完成的时间(获取到最后一个字节),包括从本地读取缓存
domLoading:开始解析渲染 DOM 树的时间,此时 Document.readyState 变为 loading,并将抛出 readystatechange 相关事件
domInteractive:完成解析 DOM 树的时间,Document.readyState 变为 interactive,并将抛出 readystatechange 相关事件注意:只是 DOM 树解析完成,这时候并没有开始加载网页内的资源
domContentLoadedEventStart:DOM 解析完成后,网页内资源加载开始的时间,文档发生 DOMContentLoaded事件的时间
domContentLoadedEventEnd:DOM 解析完成后,网页内资源加载完成的时间(如 JS 脚本加载执行完毕),文档的DOMContentLoaded 事件的结束时间
domComplete:DOM 树解析完成,且资源也准备就绪的时间,Document.readyState 变为 complete,并将抛出 readystatechange 相关事件
loadEventStart:load 事件发送给文档,也即 load 回调函数开始执行的时间,如果没有绑定 load 事件,值为 0
loadEventEnd:load 事件的回调函数执行完毕的时间,如果没有绑定 load 事件,值为 0常用计算:
DNS查询耗时 :domainLookupEnd - domainLookupStart
TCP链接耗时 :connectEnd - connectStart
request请求耗时 :responseEnd - responseStart
解析dom树耗时 : domComplete - domInteractive
白屏时间 :responseStart - navigationStart
domready时间(用户可操作时间节点) :domContentLoadedEventEnd - navigationStart
onload时间(总下载时间) :loadEventEnd - navigationStartnavigation
Performance.navigation属性对象提供了浏览器的一些行为信息。
旨在告诉开发者当前页面是通过什么方式导航过来的,只有两个属性:type,redirectCount
Performance.navigation.type //通过整数值表示网页从何加载
//0:网页通过点击链接、地址栏输入、表单提交、脚本操作等方式加载
//1:网页通过“重新加载”按钮或者location.reload()方法加载
//2:网页通过“前进”或“后退”按钮加载
//255:其他来源的加载
Performance.navigation.redirectCount //页面重定向次数Performance.memory属性对象提供了浏览器的内存使用情况。
描述内存多少,是在Chrome中添加的一个非标准属性。
jsHeapSizeLimit: 内存大小限制
totalJSHeapSize: 可使用的内存
usedJSHeapSize: JS对象(包括V8引擎内部对象)占用的内存,不能大于totalJSHeapSize,如果大于,有可能出现了内存泄漏实例代码
// 计算加载时间
function getPerformanceTiming() {
var performance = window.performance;
if (!performance) {
// 当前浏览器不支持
console.log('你的浏览器不支持 performance 接口');
return;
}
var t = performance.timing;
var times = {};
//【重要】页面加载完成的时间
//【原因】这几乎代表了用户等待页面可用的时间
times.loadPage = t.loadEventEnd - t.navigationStart;
//【重要】解析 DOM 树结构的时间
//【原因】反省下你的 DOM 树嵌套是不是太多了!
times.domReady = t.domComplete - t.responseEnd;
//【重要】重定向的时间
//【原因】拒绝重定向!比如,http://example.com/ 就不该写成 http://example.com
times.redirect = t.redirectEnd - t.redirectStart;
//【重要】DNS 查询时间
//【原因】DNS 预加载做了么?页面内是不是使用了太多不同的域名导致域名查询的时间太长?
// 可使用 HTML5 Prefetch 预查询 DNS ,见:[HTML5 prefetch](http://segmentfault.com/a/1190000000633364)
times.lookupDomain = t.domainLookupEnd - t.domainLookupStart;
//【重要】读取页面第一个字节的时间
//【原因】这可以理解为用户拿到你的资源占用的时间,加异地机房了么,加CDN 处理了么?加带宽了么?加 CPU 运算速度了么?
// TTFB 即 Time To First Byte 的意思
// 维基百科:https://en.wikipedia.org/wiki/Time_To_First_Byte
times.ttfb = t.responseStart - t.navigationStart;
//【重要】内容加载完成的时间
//【原因】页面内容经过 gzip 压缩了么,静态资源 css/js 等压缩了么?
times.request = t.responseEnd - t.requestStart;
//【重要】执行 onload 回调函数的时间
//【原因】是否太多不必要的操作都放到 onload 回调函数里执行了,考虑过延迟加载、按需加载的策略么?
times.loadEvent = t.loadEventEnd - t.loadEventStart;
// DNS 缓存时间
times.appcache = t.domainLookupStart - t.fetchStart;
// 卸载页面的时间
times.unloadEvent = t.unloadEventEnd - t.unloadEventStart;
// TCP 建立连接完成握手的时间
times.connect = t.connectEnd - t.connectStart;
return times;
}总结
1.对于网页的测速上报需求,可以通过对Performance.timing对象的属性排列组合,计算出业务需要的测速数据。
2.对于网页的性能监测需求,可以通过对Performance.memory对象进行分析,得出内存使用情况等数据。
3.对于页面的其他业务监测需求,可以通过Performance提供的其他方法进行灵活使用,计算出业务所需数据。
JS内存管理机制
像C语言这样的底层语言一般都有底层的内存管理接口,比如 malloc()和free()用于分配内存和释放内存。而对于JavaScript来说,会在创建变量(对象,字符串等)时分配内存,并且在不再使用它们时“自动”释放内存,这个自动释放内存的过程称为垃圾回收。因为自动垃圾回收机制的存在,让大多Javascript开发者感觉他们可以不关心内存管理,所以会在一些情况下导致内存泄漏。
内存生命周期
JS 环境中分配的内存有如下声明周期:
内存分配:当我们申明变量、函数、对象的时候,系统会自动为他们分配内存
内存使用:即读写内存,也就是使用变量、函数等
内存回收:使用完毕,由垃圾回收机制自动回收不再使用的内存JS 的内存分配
为了不让程序员费心分配内存,JavaScript 在定义变量时就完成了内存分配。
var n = 123; // 给数值变量分配内存
var s = "azerty"; // 给字符串分配内存
var o = {
a: 1,
b: null
}; // 给对象及其包含的值分配内存
// 给数组及其包含的值分配内存(就像对象一样)
var a = [1, null, "abra"];
function f(a){
return a + 2;
} // 给函数(可调用的对象)分配内存
// 函数表达式也能分配一个对象
someElement.addEventListener('click', function(){
someElement.style.backgroundColor = 'blue';
}, false);有些函数调用结果是分配对象内存:
var d = new Date(); // 分配一个 Date 对象
var e = document.createElement('div'); // 分配一个 DOM 元素有些方法分配新变量或者新对象:
var s = "azerty";
var s2 = s.substr(0, 3); // s2 是一个新的字符串
// 因为字符串是不变量,
// JavaScript 可能决定不分配内存,
// 只是存储了 [0-3] 的范围。
var a = ["ouais ouais", "nan nan"];
var a2 = ["generation", "nan nan"];
var a3 = a.concat(a2);
// 新数组有四个元素,是 a 连接 a2 的结果JS 的内存使用
使用值的过程实际上是对分配内存进行读取与写入的操作。读取与写入可能是写入一个变量或者一个对象的属性值,甚至传递函数的参数。
var a = 10; // 分配内存
console.log(a); // 对内存的使用JS 的内存回收
引用计数垃圾收集
这是最初级的垃圾回收算法。
引用计数算法定义“内存不再使用”的标准很简单,就是看一个对象是否有指向它的引用。如果没有其他对象指向它了,说明该对象已经不再需了。
标记清除算法
标记清除算法将“不再使用的对象”定义为“无法达到的对象”。简单来说,就是从根部(在JS中就是全局对象)出发定时扫描内存中的对象。凡是能从根部到达的对象,都是还需要使用的。那些无法由根部出发触及到的对象被标记为不再使用,稍后进行回收。
从这个概念可以看出,无法触及的对象包含了没有引用的对象这个概念(没有任何引用的对象也是无法触及的对象)。但反之未必成立。
内存泄漏
什么是内存泄漏
程序的运行需要内存。只要程序提出要求,操作系统或者运行时(runtime)就必须供给内存。
对于持续运行的服务进程(daemon),必须及时释放不再用到的内存。否则,内存占用越来越高,轻则影响系统性能,重则导致进程崩溃。
本质上讲,内存泄漏就是由于疏忽或错误造成程序未能释放那些已经不再使用的内存,造成内存的浪费。
常见的内存泄露案例
- 意外的全局变量
function foo() {
bar1 = 'some text'; // 没有声明变量 实际上是全局变量 => window.bar1
this.bar2 = 'some text' // 全局变量 => window.bar2
}
foo();2. 被遗忘的定时器和回调函数
var serverData = loadData();
setInterval(function() {
var renderer = document.getElementById('renderer');
if(renderer) {
renderer.innerHTML = JSON.stringify(serverData);
}
}, 5000); // 每 5 秒调用一次- 闭包
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing) // 对于 'originalThing'的引用
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log("message");
}
};
};
setInterval(replaceThing, 1000);- DOM 引用
var elements = {
image: document.getElementById('image')
};
function doStuff() {
elements.image.src = 'http://example.com/image_name.png';
}
function removeImage() {
document.body.removeChild(document.getElementById('image'));
// 这个时候我们对于 #image 仍然有一个引用, Image 元素, 仍然无法被内存回收.
}如何避免内存泄漏
记住一个原则:不用的东西,及时归还。
减少不必要的全局变量,使用严格模式避免意外创建全局变量。
在你使用完数据后,及时解除引用(闭包中的变量,dom引用,定时器清除)。
组织好你的逻辑,避免死循环等造成浏览器卡顿,崩溃的问题。
V8 的垃圾回收机制
V8 的垃圾回收策略主要基于分代式垃圾回收机制。主要将内存分为新生代和老生代两代。
新生代空间(Young Generaion) 特点:
管理对象存活时间较短
占用空间比老生代空间小很多
垃圾回特别频繁
新生代空间的垃圾回收采用Scavenge 算法,其工作原理如下:
将新生代空间分为两个空间,称为semispace,处于使用状态的叫做 From 空间,处于闲置的叫 To 空间,当我们分配对象时,先是在 From 空间中进行分配。
开始垃圾回收时,会检查 From 空间中的存活对象,这些存活对象将被复制到 To 空间中,然后释放 From 空间中的内存。
From 空间与 To 空间对换
从上面的过程我们可以看到,Scavenge 算法是典型的牺牲空间换取时间的算法。缺点是只能使用堆内存中的一半,优点是在时间效率上有优异的表现。
老生代空间( OldGeneraion)
在新生代空间中生命周期较长的对象会被复制到老生代空间中,这个过程叫晋升。对象晋升的条件主要有两个:
对象是否经历过一次 Scavenge 回收。 对象从 From 空间复制到 To 空间时,会检查它的内存地址来判断这个对象是否已经经历过一次 Scavenge 回收。如果经历过,就直接复制到老生代空间中,而不是 To 空间。
To 空间的内存使用占比是否超过 To 空间的 25%。 对象从 From 空间复制到 To 空间时,发现 To 空间的内存占比已经超过限制。因为To 空间将会变成 From空间,为了不影响后续的内存分配,会直接晋升到老生代空间中。
对于老生代空间,由于存活对象占比较大,再采用Scavenge的方式会有两个问题:
存活对象比较多,复制存活对象的效率会很低
要拆分两个 semispace 空间,比较浪费
为此,老生代中主要采用标记清除(Mark-Sweep)和标记整理(Mark-Compact)相结合的方式进行垃圾回收,其工作原理如下:
在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象。标记后的示意图如下:
黄色部分为标记活跃的对象,深灰色部分为标记死亡的对象。
标记清除(Mark-Sweep)最大的问题在于,清除标记死亡的对象后,内存不连续,这种碎片空间会对后续的内存分配造成问题。
为了解决内存碎片的问题,标记整理(Mark-Compact)被提出来。它会在标记完成后,将存活的对象移动到一端,然后释放存活对象这一端之外的空间。
增量标记(Incremental Marking)
在进行上面 V8垃圾回收操作的时候,需要将应用逻辑暂停,但是由于老生代空间很大,且存活对象很多,为了避免长时间的停顿,将原本一次性完成的操作改为增量标记,即拆分为许多小“步进”,每做完一次“步进”,让应用逻辑执行一会儿,交替执行,直到垃圾回收执行完成。
提升页面性能的方法有哪些
资源压缩合并,减少HTTP请求.(把资源文件变小)
非核心代码异步加载->异步加载的方式->异步加载的区别
*利用浏览器缓存->缓存的分类->缓存原理
使用CDN(属于网络优化)
预解析DNS
<meta http-equiv="x-dns-prefetch-control" content="on">
<link rel="dns-prefetch" href="//host_name_to_prefetch.com">注:当一次打开时,浏览器缓存起不到任何作用,但是使用CDN可以起到作用。
2)异步加载
异步加载的方式:
动态脚本加载(动态创建结点)
defer
async
异步加载的区别:
defer在HTML解析之后才会执行,如果是多个,按照加载顺序依次执行。
async是在加载完之后立即执行,如果是多个,执行顺序和加载顺序无关。
3)浏览器缓存
缓存
(1)强缓存:直接从缓存中取
(2)304协商缓存:问一下服务器缓存中的能不能用
(3)http请求头:
Cache-Control: no-store // 禁止浏览器缓存
Cache-Control: no-cache // 不允许直接缓存,即协商缓存
Cache-Control: max-age // 秒,缓存的有效时间
pragma: no-cache // 禁止浏览器缓存
expires: 时间 // 格林威治时间,在之前有效
优先级:pragma>Cache-Control>expires(4)响应头
Last-Modified // 通知资源最后修改的时间
ETag // 文章内容修改缓存先expires->Last-Modified->ETag 都没过期,返304响应
4)预解析DNS
<meta http-quiv="x-dns-prefetch-control" content="on"> // 强制打开预解析DNS,http是默认开启的,https是默认关闭的
<link rel="dns-prefetch" href="//local_name.com"> // 将里面的地址预解析防抖(debounce)
首先提出一种思路:在第一次触发事件时,不立即执行函数,而是给出一个期限值比如200ms,然后:
如果在200ms内没有再次触发滚动事件,那么就执行函数
如果在200ms内再次触发滚动事件,那么当前的计时取消,重新开始计时
效果:如果短时间内大量触发同一事件,只会执行一次函数。
实现:既然前面都提到了计时,那实现的关键就在于setTimeout这个函数,由于还需要一个变量来保存计时,考虑维护全局纯净,可以借助闭包来实现:
/*
* fn [function] 需要防抖的函数
* delay [number] 毫秒,防抖期限值
*/
function debounce(fn,delay){
let timer = null //借助闭包
return function() {
if(timer){
clearTimeout(timer)
}
timer = setTimeout(fn,delay)
}
}
function debounce(fn, delay) {
var timeout = null; // 创建一个标记用来存放定时器的返回值
return function(e) {
// 每当用户输入的时候把前一个 setTimeout clear 掉
clearTimeout(timeout);
// 然后又创建一个新的 setTimeout, 这样就能保证interval 间隔内如果时间持续触发,就不会执行 fn 函数
timeout = setTimeout(() => {
fn.apply(this, arguments);
}, delay);
};
}
// 处理函数
function handle() {
console.log('防抖:', Math.random());
}
//滚动事件
window.addEventListener('scroll', debounce(handle, 500));
节流(throttle)
设计一种类似控制阀门一样定期开放的函数,也就是让函数执行一次后,在某个时间段内暂时失效,过了这段时间后再重新激活(类似于技能冷却时间)。
效果:如果短时间内大量触发同一事件,那么在函数执行一次之后,该函数在指定的时间期限内不再工作,直至过了这段时间才重新生效。
实现 这里借助setTimeout来做一个简单的实现,加上一个状态位valid来表示当前函数是否处于工作状态:
function throttle(fn,delay){
let valid = true
return function() {
if(!valid){
//暂时不处理
return false
}
// 工作时间,执行函数并且在间隔期内把状态位设为无效
valid = false
setTimeout(() => {
fn()
valid = true;
}, delay)
}
}
//节流函数
function throttle(fn, delay) {
let timer = null;
let startTime = Date.now();
return function() {
let curTime = Date.now();
let remainning = delay - (curTime - startTime);
let context = this;
let args = arguments;
clearTimeout(timer);
if(remainning <= 0) {
fn.apply(context, args);
startTime = Date.now();
} else {
timer = setTimeout(fn, remainning)
}
}
}
function sayHi(e) {
console.log('节流:');
}
window.addEventListener('resize', throttle(sayHi, 500));
JS 更新 DOM 后页面及时渲染问题
深入研究浏览器内核可以发现,浏览器内核是多线程的,其中一个常驻线程叫 javascript 引擎线程,负责执行 js 代码,还有一个常驻线程叫 GUI 渲染线程,负责页面渲染,dom 重画等操作。javascript 引擎是基于事件驱动单线程执行的,js 线程一直在等待着任务列表中的任务到来,而 js 线程与 gui 渲染线程是互斥的,当 js 线程执行时,渲染线程呈挂起状态,只有当 js 线程空闲时渲染线程才会执行。所以,我们可以理解为什么 dom 更新总是不能被立刻执行。就我们的代码来说,显示提示和隐藏提示的 dom 操作都被浏览器记下来了并放在 gui 渲染线程的任务队列中,但都没有立刻进行渲染,而是在当前函数完成后(js 线程已处于空闲状态),进行最终的 dom 渲染,而我们的用户则基本感受不到这个过程,因为经过 show 和 hide 两个相反的操作,相当于 dom 完全没变。
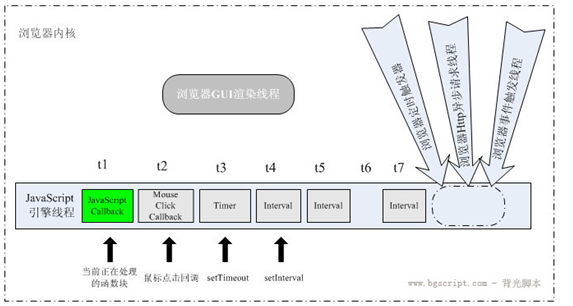
浏览器的行为虽然是合理的,但却给我们带来了麻烦,怎么才能强制浏览器执行 dom 更新的操作以满足我们的业务需要,给用户友好的提示呢,有两种方法:
采用 alert 语句进行提示,alert 语句会 block 住 js 线程,将执行权让给 gui 渲染线程,执行 alert 之后浏览器会把这个语句之前的所有对 dom 的操作都进行体现。这个方法虽然简单有效,但不具有可操作性,首先 alert 是简单粗暴的一种提示方式,反倒降低了用户体验,其次不能适用在各种场景中,不可能在系统中无缘无故地弹出个 alert 框只是为了强制重画更新的 dom。所以,该方法不值得推广。
采用 setTimeout 方法,这是普遍的解决方案。把计算逻辑和隐藏提示的方法放在 setTimeout 里可以解决这个问题,因为 setTimeout 启用了一个定时器,指定在经过一段时间后执行某段逻辑,从而使这段逻辑跳离了当前函数体,使当前函数可以快速地执行完,之后如果 js 引擎线程中没有排队的任务,则 gui 渲染线程得到执行,showTip 相关的 dom 更新得到体现。当定时器到时后,js 线程又得到了新的任务,从而使计算逻辑和隐藏提示的操作得到执行。
前端页面加载阻塞渲染问题,如何解决?
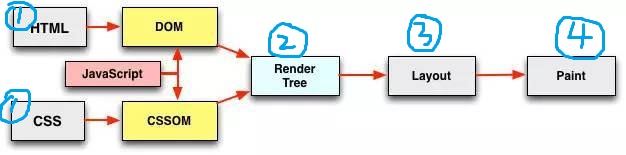
一、解析 DOM 树和 CSSOM
1.HTML 标签进行 Dom 树解析
解析遇到 link、script、img 标签时,浏览器会向服务器发送请求资源。
script 的加载或者执行都会阻塞 html 解析、其他下载线程以及渲染线程。
link 加载完 css 后会解析为 CSSOM(层叠样式表对象模型,一棵仅含有样式信息的树)。css 的加载和解析不会阻塞 html 的解析,但会阻塞渲染。
img 的加载不会阻塞 html 的解析,但 img 加载后并不渲染,它需要等待 Render Tree 生成完后才和 Render Tree 一起渲染出来。未下载完的图片需等下载完后才渲染。
2.CSS 语法进行 CSS 树解析
CSS 解释器将 CSS 进行解释然后解析
划重点!!!Dom 树和 CSSOM 两者不是解析完再渲染的,而是边解析边进行渲染的!
DOM 树和 CSSOM 渲染完成后合并生成 Render 树
布局(reflow 重排发生在这个阶段)
布局(reflow 重排发生在这个阶段)
这个阶段是通过递归调用进行布局的,引擎计算各元素的尺寸大小,进行布局树绘制
触发重排:
页面首次渲染
浏览器窗口大小变化
元素尺寸、位置、内容、字体大小发生变化
添加或删除可见的元素
激活伪类时
绘制(repainting 重绘发生在这个阶段) 触发重绘:改变元素颜色、背景、visibility、outline 等属性
重排一定会触发重绘,重绘不一定会触发重排 。
阻塞问题总结
阻塞发生的情况:
遇到 script 标签加载 js 的时候会加载 js 并且执行完毕才开始渲染
遇到 alert 会阻塞
css 也会阻塞
css 是由单独的下载线程异步下载的。
总结: 1、css 加载不会阻塞 DOM 树的解析
2、css 加载会阻塞 DOM 树(render 树)的渲染
3、css 加载会阻塞后面 js 语句的执行
为了避免让用户看到长时间的白屏时间,我们应该尽可能的提高 css 加载速度,比如可以使用以下几种方法:
使用 CDN(因为 CDN 会根据你的网络状况,替你挑选最近的一个具有缓存内容的节点为你提供资源,因此可以减少加载时间)
对 css 进行压缩(可以用很多打包工具,比如 webpack,gulp 等,也可以通过开启 gzip 压缩) 合理的使用缓存(设置 cache-control,expires,以及 E-tag 都是不错的,不过要注意一个问题,就是文件更新后,你要避免缓存而带来的影响。其中一个解决防范是在文件名字后面加一个版本号) 减少 http 请求数,将多个 css 文件合并,或者是干脆直接写成内联样式(内联样式的一个缺点就是不能缓存)
性能分析 chrome devtool lighthouse
浏览器渲染过程与性能优化
https://juejin.cn/post/6844904040346681358#heading-27
查找字符最多字符
var str = '23weqreqwelkawemrmnqweowerewmrwes';
var obj = {};
for(var i = 0; i < str.length; i++) {
var s = str.charAt(i);
obj[s] ? obj[s]++ : obj[s] = 1;
}
console.log(obj);
var max = [];
var name = '';
for(var c in obj) {
if(obj[c] > max) {
max = obj[c];
name = c;
}
}
console.log('name=' + name + "&max=" + max)求 1-100 的和
function sum(n) {
if(n == 1) return n;
var m = n + sum(n - 1)
// console.log(m)
return m;
}
console.log(sum(100));经典案例 : 斐波拉契数列
1,1,2,3,5,8,13,21,34,55,89...求第 n 项
function fib(n) {
if(n === 1 || n === 2) return 1;
return fib(n - 1) + fib(n - 2)
}
console.log(fib(10))**经典案例 3: 爬楼梯**
JS 递归 假如楼梯有 n 个台阶,每次可以走 1 个或 2 个台阶,请问走完这 n 个台阶有几种z法
function climbStairs(n) {
if(n === 1) return 1;
if(n === 2) return 2;
return climbStairs(n - 1) + climbStairs(n - 2)
}
console.log(climbStairs(6))经典案例 : 深拷贝
**原理: clone(o) = new Object; 返回一个对象 **
var obj = {
a: 1,
b: 2,
c: {
e: 1,
f: 2
},
d: [1, 2, 3],
e: function() {}
};
function clone(o) {
var temp = {};
for(var i in o) {
if(typeof o[i] == 'object') {
temp[i] = clone(o[i])
} else {
temp[i] = o[i]
}
}
return temp;
}
console.log(obj)
for(var i in obj) {
console.log(i)
}接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5] 输出:9
解题思路
最短木桶原理:
每根柱子上方的雨水深度取决于该根柱子左右两边最高的两根柱子中较短那根的高度。
左右两边最高柱子高度都大于该根柱子的情况下,雨水的深度为其左右两边较小柱子高度减去该根柱子高度。
1.循环遍历整个数组,获取每个柱子i的高度
2.循环遍历指点元素i左边的数组元素,并求最大值leftMax
3.循环遍历指定元素i右边的数组元素,并且其最大值rightMax
4.求leftMax和rightMax中的较小值,较小值减去当前元素i的高度就为当前柱子雨水的深度。
var trap = function(height) {
var sum = 0
for(var i=0;i<height.length;i++){
var leftMax = 0
var rightMax = 0
for(var j=i-1;j>=0;j--){ // 求leftMax的值
leftMax = (height[j] >= leftMax) ? height[j] : leftMax
}
for(var k=i+1;k<height.length;k++){ //求rightMax的值
rightMax = (height[k] >= rightMax) ? height[k] : rightMax
}
var min = Math.min(leftMax,rightMax) //求leftMax、rightMax中的较小值
if(min > height[i]){
sum += min - height[i]
}
}
return sum
};
经典的斐波那契数列:1,1,2,3,5,8,13……即从第三项起,每一项的值是前两项值的和。现在求第 n 项的值
function fibonacci(n) {
var n1 = 1, n2 = 1, sum;
for (let i = 2; i < n; i++) {
console.log(n1);
sum = n1 + n2
n1 = n2
n2 = sum
}
return sum
}
fibonacci(30)
var fibona = function (n) {
// 如果求第一项或者第二项,则直接返回1
if (n === 1 || n === 2) return 1;
// 否则的话,返回前两项的和
return fibona(n - 1) + fibona(n - 2);
}
console.log(fibona(5)) // 3复制代
根据递归的思想,首先设置递归的终止条件,就是 n=1 或者 n=2 的时候返回 1。否则的话就重复调用自身,即第 n 项的值是第 n-1 和第 n-2 项的和,那么同理,第 n-1 项的值是第 n-1-2 和 n-1-1 项的值,依次类推,通过递归,最终都转化成了 f(1)或 f(2)的值相加。
Tip:像斐波契数列这类的求值函数,计算量还是有些大的,所以我们完全可以做个缓存,在多次求相同的值的时候,我们可以直接从缓存取值。
尾递归的原理:
当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
以尾递归方式实现阶乘函数的实现:
int facttail(int n, int res)
{
if (n < 0)
return 0;
else if(n == 0)
return 1;
else if(n == 1)
return res;
else
return facttail(n - 1, n *res);
}
合并两个有序数组
1、concat js的Array对象提供了一个叫concat()方法,连接两个或更多的数组,并返回结果。
var c = a.concat(b); //c=[1,2,3,4,5,6];
2、for循环
for( var i in b)
{
a.push(b[i]);
}
3、apply 函数的apply方法有一个特性,那就是func.apply(obj,argv),argv是一个数组。所以我们可以利用这点,直上代码:
a.push.apply(a,b);
调用a.push这个函数实例的apply方法,同时把,b当作参数传入,这样a.push这个方法就会遍历b数组的所有元素,达到合并的效果。
这里可能有点绕,我们可以把b看成[4,5,6],变成这样:
a.push.apply(a,[4,5,6]);
然后上面的操作就等同于:
a.push(4,5,6);
Cookie 安全性
一、对保存到 cookie 里面的敏感信息必须加密
二、设置 HttpOnly 为 true
1、该属性值的作用就是防止 Cookie 值被页面脚本读取。 2、但是设置 HttpOnly 属性,HttpOnly 属性只是增加了攻击者的难度,Cookie 盗窃的威胁并没有彻底消除,因为 cookie 还是有可能传递的过程中被监听捕获后信息泄漏。
三、设置 Secure 为 true
1、给 Cookie 设置该属性时,只有在 https 协议下访问的时候,浏览器才会发送该 Cookie。
2、把 cookie 设置为 secure,只保证 cookie 与 WEB 服务器之间的数据传输过程加密,而保存在本地的 cookie 文件并不加密。如果想让本地 cookie 也加密,得自己加密数据。
四、给 Cookie 设置有效期
1、如果不设置有效期,万一用户获取到用户的 Cookie 后,就可以一直使用用户身份登录。
2、在设置 Cookie 认证的时候,需要加入两个时间,一个是“即使一直在活动,也要失效”的时间,一个是“长时间不活动的失效时间”,并在 Web 应用中,首先判断两个时间是否已超时,再执行其他操作。
CSRF | XSRF 跨站请求伪造攻击
原理:
(1) 用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
(2)在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A; (3)用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
(4)网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
(5)浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
防御:
(1)验证 HTTP Referer 字段,判断页面来源
(2)在请求地址中添加 token 并验证;
(3)在 HTTP 头中自定义属性并验证
**XSS 跨站脚本攻击 **
原理:向页面注入脚本,(如:评论区)
1、可以合理利用现有成熟框架、开启自带的 HTML 转义功能,过滤特殊字符。
2、校验用户输入的特殊字符
3、前端和服务端合作,阻止未转义特殊字符输出。
4、尽量避免内联事件,尽量不要使用 onLoad="onload('{{data}}')"、onClick="go('{{action}}')" 这种拼接内联事件的写法。在 JavaScript 中通过 .addEventlistener() 事件绑定会更安全。
5、避免拼接 HTML前端采用拼接 HTML 的方法比较危险,如果框架允许,使用 createElement、setAttribute 之类的方法实现。或者采用比较成熟的渲染框架,如 Vue/React 等。
浏览器多线程
1.JS引擎线程(js引擎有多个线程,一个主线程,其它的后台配合主线程)
作用:执行js任务(执行js代码,用户输入,网络请求)
2.UI渲染线程(GUI)
作用:渲染页面(js可以操作dom,影响渲染,所以js引擎线程和UI线程是互斥的。js执行时会阻塞页面的渲染。)
3.浏览器事件触发线程
作用:控制交互,响应用户
4.HTTP请求线程
作用:ajax请求等
5.定时触发器线程
作用:setTimeout和setInteval
6.事件轮询处理线程
作用:轮询消息队列,event loop
一、TCP 与 UDP 差异
1.TCP 是面向连接的可靠传输,UDP 是面向无连接的不可靠传输
面向连接表现在3次握手,4次挥手;可靠传输表现在未进行4次挥手时的差错重传,超时重传;
TCP 、UDP 传输时都会建立虚拟信道,区别是 TCP 要进行握手确认,直到挥手才注销信道, UDP 则传输完成就注销信道并不在意接收方收到消息与否。
2.TCP 是面向流的传输,UDP 是基于数据报的传输
流传输可进行流量控制传输,可进行分组传输,可进行拥塞控制传输;基于报文的传输不拆分不合并,无论多大一次性发送。
3.TCP 面向系统资源要求较多,UDP 相对较少
TCP 需要握手挥手,TCP 头部 20 字节,UDP 头部 8 字节
4.TCP 与 UDP 的应用场景不同
TCP 效率要求相对较低,对传输的准确性要求较高,例如:HTTP 请求、文件传输、远程登录 UDP 效率要求相对较高,对传输的准确性要求相对较低,例如:视频通话、语音通话、偶尔断续也不会影响,不会有流量控制、拥塞控制,偶尔丢帧影响不大
5.UDP 的优势
简单 传输快 支持一对一、一对多、多对多,而 TCP 是基于点对点的
二、三次握手与四次挥手
1.三次握手
A 向 B 发起请求
B 向 A 返回确认消息
A 向 B 发起确认包并分配资源
第三次握手是为了防止失效的连接到达服务器,让服务器打开错误的连接,失效的请求是指滞留在网络中的请求,有了第三次握手,滞留在网络中的请求到达服务器时就会拒绝创建连接
2.四次挥手
C 向 D 发起挥手请求
D 向 C 返回确认消息(此时并不会立即断开,等待一定的时间)
D 向 C 传递剩余的数据
C 向 D 发送确认挥手的消息,此时才断开
三、HTTP 协议概述
3.1 Cookie 与 Session
3.1.1 Cookie
Http 协议是无状态的短连接,因此引入 Cookie 保存状态信息;Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,会在下次请求时携带在请求头发送到服务器,判别两次两次请求是否来自同一浏览器,例如登录状态。
cookie 作用:记录会话状态、浏览器行为跟踪。
cookie 创建过程:服务器发送响应报文时,通过 set-cookie 置于响应头中。
cookie 安全性:较差,可通过标记 cookie 为 secure 来提高安全性。 --设置请求类型为 Https
3.1.2 Session
session 将会话信息存储到服务器,本地通过 cookie 只存储 sessionId,使用 session 维护登录状态相对于 cookie 较安全。
3.1.3 二者区别
cookie 只能存 ASCII 字符串,session 可存取任何类型数据,cookie 存在浏览器本地易被恶意查看
3.2缓存 缓解服务器响应压力。 降低客户端获取资源的延迟,缓存比服务器离客户端近。
3.3短链接与长链接 短连接:每发起一次请求获取资源后就断开。
长连接:发起请求获取资源后不断开。每次发起新的请求都需要进行三次握手协议,当浏览器访问包含多张图片资源的页面时,除进行页面资源的请求外,还需要图片资源的请求,如果每次都进行 TCP 连接,开销很大,长连接的出现就是为建立一次 TCP 连接可进行多次 HTTP 通信。
3.4流水线 默认情况下 HTTP 请求是按顺序发出的,下一个请求只有在上一个请求收到应答后才会发出,由于网络延迟和带宽限制可能造成长时间的等待。流水线是同一条长连接上发出的连续的请求,而不用等带响应返回,可避免连接延迟。
3.5 HTTPS
HTTP 先与 SSL 通信,再由 SSL 与 TCP 通信
认证:第三方机构授予服务器、客户端的证书,包含公钥。
混合加密:使用非对称加密进行传输,使用对称加密进行通信。
对称加密和非对称加密的区别
简介:
对称加密: 加密和解密的秘钥使用的是同一个.
非对称加密: 与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey)。
对称加密算法: 密钥较短,破译困难,除了数据加密标准(DES),另一个对称密钥加密系统是国际数据加密算法(IDEA),它比 DES 的加密性好,且对计算机性能要求也没有那么高.
优点:
算法公开、计算量小、加密速度快、加密效率高
缺点:
在数据传送前,发送方和接收方必须商定好秘钥,然后 使双方都能保存好秘钥。其次如果一方的秘钥被泄露,那么加密信息也就不安全了。另外,每对用户每次使用对称加密算法时,都需要使用其他人不知道的唯一秘钥,这会使得收、发双方所拥有的钥匙数量巨大,密钥管理成为双方的负担。
常见的对称加密算法有: DES、3DES、Blowfish、IDEA、RC4、RC5、RC6 和 AES
非对称加密算法: 公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
非对称加密算法实现机密信息交换的基本过程是:甲方生成一对密钥并将其中的一把作为公用密钥向其它方公开;得到该公用密钥的乙方使用该密钥对机密信息进行加密后再发送给甲方;甲方再用自己保存的另一把专用密钥对加密后的信息进行解密。甲方只能用其专用密钥解密由其公用密钥加密后的任何信息。
优点:
安全
缺点:
速度较慢
常见的非对称加密算法有: RSA、ECC(移动设备用)、Diffie-Hellman、El Gamal、DSA(数字签名用)
Hash 算法(摘要算法)
Hash 算法特别的地方在于它是一种单向算法,用户可以通过 hash 算法对目标信息生成一段特定长度的唯一 hash 值,却不能通过这个 hash 值重新获得目标信息。因此 Hash 算法常用在不可还原的密码存储、信息完整性校验等。
常见的摘要算法有: MD2、MD4、MD5、HAVAL、SHA
HTTP 1.0 和 HTTP2.0 的区别
HTTP/2 没有改变 HTTP 的基本语义和操作,各种操作方法(如 GET/POST/HEAD 等)、请求头和请求体机制都没有改变,不同的只是传输的方式改变了。HTTP/1.x 协议以换行符作为纯文本的分隔符,而 HTTP/2 将所有传输的信息分割为更小的消息和帧,并采用二进制格式对它们编码。
HTTP/2 的主要功能特性
将 HTTP 协议中的纯文本传输修改成了二进制帧传输,分为头部帧和数据帧。
使用 HPCAK 对头部数据压缩,添加头部索引减少重复头部数据传输。
添加数据优先级,针对不同的数据源建立不同的优先级树,确保优先级高的数据不会被阻塞。
请求响应的复用,同一个数据流中可以同时以不同的顺序发送多个不同的帧,每个数据源只产生一个连接。
流控制,阻止发送方向接收方发送的大量数据,通过请求窗口限制请求速率。
服务端推送,打破严格的请求-响应机制,服务端也可以主动推送数据到客户端。
HTTP/2 数据传输的基本元素
新的 HTTP/2 协议通过二进制帧来传输数据,改变了客户端与服务器之间交换数据的方式,主要涉及了三个概念:
帧:HTTP/2 数据传输的基本单位,通过把原始的文本数据处理成二进制帧来发送。
消息:逻辑请求和响应构成的统一整体就是消息。
数据流:建立的 TCP 连接,承载发送一条和多条消息。
帧和消息
和 HTTP/1 一样,HTTP/2 依旧还是保留了请求头、请求体以及响应体的部分。只不过在传输的时候被处理成了二进制的内容格式,同时把请求帧和响应帧区分开来了,两者可以单独发送。
HTTP CODE 状态码
100 Continue 继续,一般在发送post请求时,已发送了http
header之后服务端将返回此信息,表示确认,之后发送具体参数信息
200 OK 正常返回信息
201 Created 请求成功并且服务器创建了新的资源
202 Accepted服务器已接受请求,但尚未处理
301 Moved Permanently请求的网页已永久移动到新位置.
302 Found 临时性重定向
303 See Other 临时性重定向,且总是使用 GET 请求新的 URI.
304 Not Modified自从上次请求后,请求的网页未修改过
400 BadRequest服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求
401Unauthorized 请求未授权
403 Forbidden 禁止访问
404 Not Found 找不到如何与URI相匹配的资源
500 Internal Server Error 最常见的服务器端错误
503 ServiceUnavailable 服务器端暂时无法处理请求(可能是过载或维护)从输入 url 到页面加载发生了什么
这是一道经典的面试题,这道题没有一个标准的答案,它涉及很多的知识点,面试官会通过这道题了解你对哪一方面的知识比较擅长,然后继续追问看看你的掌握程度。当然我写的这些也只是我的一些简单的理解,从前端的角度出发,我觉得首先回答必须包括几个基本的点,然后在根据你的理解深入回答。
1、浏览器的地址栏输入 URL 并按下回车。
2、浏览器查找当前 URL 是否存在缓存,并比较缓存是否过期。
3、DNS 解析 URL 对应的 IP。
4、根据 IP 建立 TCP 连接(三次握手)。
5、HTTP 发起请求。
6、服务器处理请求,浏览器接收 HTTP 响应。
7、渲染页面,构建 DOM 树。
8、关闭 TCP 连接(四次挥手)。
说完整个过程的几个关键点后我们再来展开的说一下。
一、URL
二、缓存
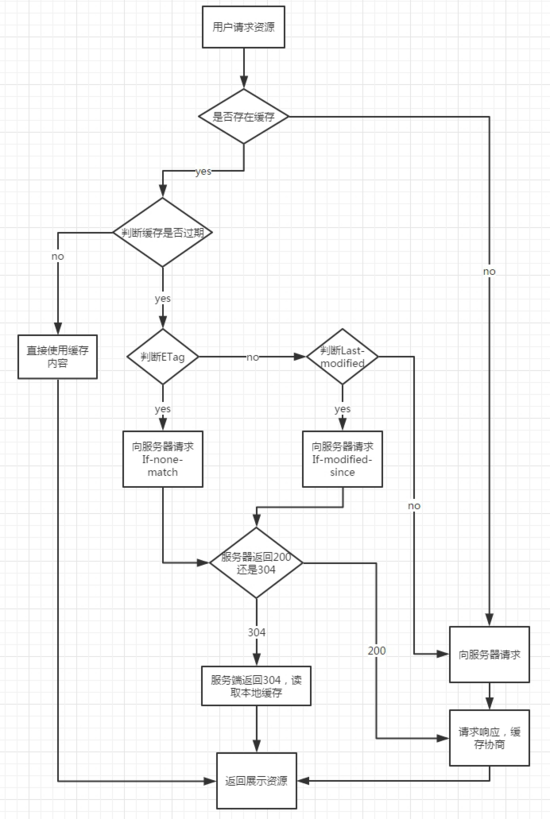
说完 URL 我们说说浏览器缓存,HTTP 缓存有多种规则,根据是否需要重新向服务器发起请求来分类,我将其分为强制缓存,对比缓存。
强制缓存判断 HTTP 首部字段:cache-control,Expires。
Expires 是一个绝对时间,即服务器时间。浏览器检查当前时间,如果还没到失效时间就直接使用缓存文件。但是该方法存在一个问题:服务器时间与客户端时间可能不一致。因此该字段已经很少使用。
cache-control 中的 max-age 保存一个相对时间。例如 Cache-Control: max-age = 484200,表示浏览器收到文件后,缓存在 484200s 内均有效。 如果同时存在 cache-control 和 Expires,浏览器总是优先使用 cache-control。
对比缓存通过 HTTP 的 last-modified,Etag 字段进行判断。
last-modified 是第一次请求资源时,服务器返回的字段,表示最后一次更新的时间。下一次浏览器请求资源时就发送 if-modified-since 字段。服务器用本地 Last-modified 时间与 if-modified-since 时间比较,如果不一致则认为缓存已过期并返回新资源给浏览器;如果时间一致则发送 304 状态码,让浏览器继续使用缓存。
Etag:资源的实体标识(哈希字符串),当资源内容更新时,Etag 会改变。服务器会判断 Etag 是否发生变化,如果变化则返回新资源,否则返回 304。
三、DNS 域名解析
我们知道在地址栏输入的域名并不是最后资源所在的真实位置,域名只是与 IP 地址的一个映射。网络服务器的 IP 地址那么多,我们不可能去记一串串的数字,因此域名就产生了,域名解析的过程实际是将域名还原为 IP 地址的过程。
首先浏览器先检查本地 hosts 文件是否有这个网址映射关系,如果有就调用这个 IP 地址映射,完成域名解析。
如果没找到则会查找本地 DNS 解析器缓存,如果查找到则返回。
如果还是没有找到则会查找本地 DNS 服务器,如果查找到则返回。
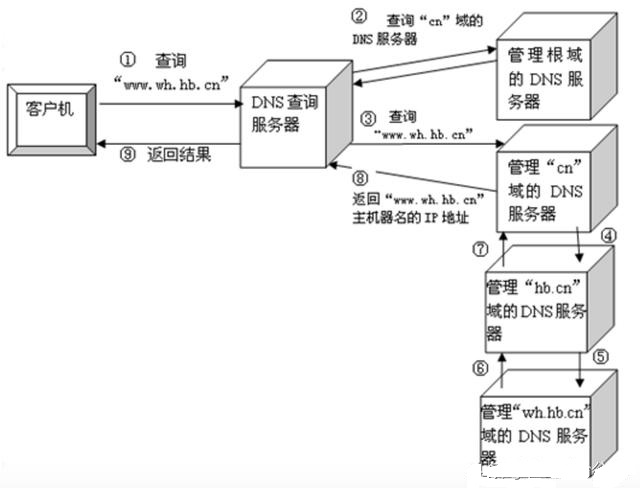
最后迭代查询,按根域服务器 ->顶级域,.cn->第二层域,hb.cn ->子域,www.hb.cn的顺序找到IP地址。
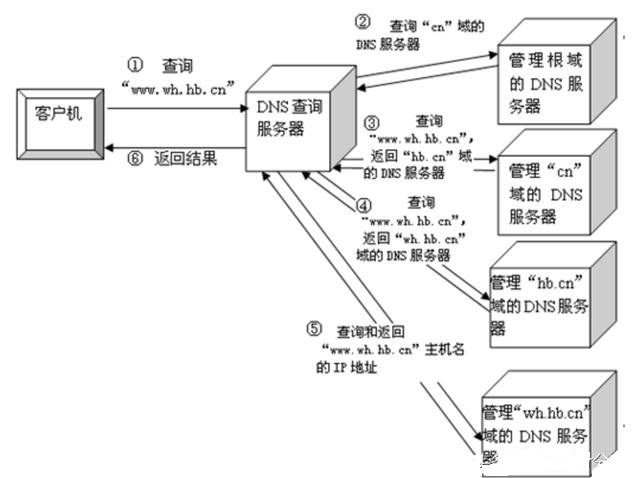
递归查询,按上一级 DNS 服务器->上上级->....逐级向上查询找到 IP 地址。
四、TCP 连接
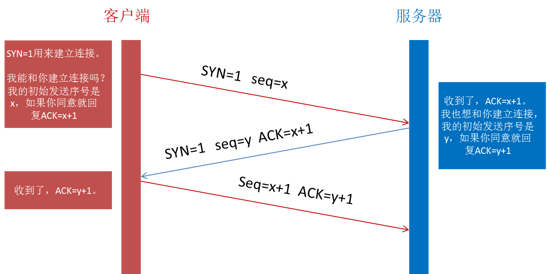
在通过第一步的 DNS 域名解析后,获取到了服务器的 IP 地址,在获取到 IP 地址后,便会开始建立一次连接,这是由 TCP 协议完成的,主要通过三次握手进行连接。
第一次握手: 建立连接时,客户端发送 syn 包(syn=j)到服务器,并进入 SYN_SENT 状态,等待服务器确认;
第二次握手: 服务器收到 syn 包,必须确认客户的 SYN(ack=j+1),同时自己也发送一个 SYN 包(syn=k),即 SYN+ACK 包,此时服务器进入 SYN_RECV 状态;
第三次握手: 客户端收到服务器的 SYN+ACK 包,向服务器发送确认包 ACK(ack=k+1),此包发送完毕,客户端和服务器进入 ESTABLISHED(TCP 连接成功)状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据。
五、浏览器向服务器发送 HTTP 请求
完整的 HTTP 请求包含请求起始行、请求头部、请求主体三部分。
六、浏览器接收响应
服务器在收到浏览器发送的 HTTP 请求之后,会将收到的 HTTP 报文封装成 HTTP 的 Request 对象,并通过不同的 Web 服务器进行处理,处理完的结果以 HTTP 的 Response 对象返回,主要包括状态码,响应头,响应报文三个部分。
状态码主要包括以下部分
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求。
响应头主要由 Cache-Control、 Connection、Date、Pragma 等组成。
响应体为服务器返回给浏览器的信息,主要由 HTML,css,js,图片文件组成。
七、页面渲染
如果说响应的内容是 HTML 文档的话,就需要浏览器进行解析渲染呈现给用户。整个过程涉及两个方面:解析和渲染。在渲染页面之前,需要构建 DOM 树和 CSSOM 树。
在浏览器还没接收到完整的 HTML 文件时,它就开始渲染页面了,在遇到外部链入的脚本标签或样式标签或图片时,会再次发送 HTTP 请求重复上述的步骤。在收到 CSS 文件后会对已经渲染的页面重新渲染,加入它们应有的样式,图片文件加载完立刻显示在相应位置。在这一过程中可能会触发页面的重绘或重排。这里就涉及了两个重要概念:Reflow 和 Repaint。
Reflow,也称作 Layout,中文叫回流,一般意味着元素的内容、结构、位置或尺寸发生了变化,需要重新计算样式和渲染树,这个过程称为 Reflow。
Repaint,中文重绘,意味着元素发生的改变只是影响了元素的一些外观之类的时候(例如,背景色,边框颜色,文字颜色等),此时只需要应用新样式绘制这个元素就 OK 了,这个过程称为 Repaint。
所以说 Reflow 的成本比 Repaint 的成本高得多的多。DOM 树里的每个结点都会有 reflow 方法,一个结点的 reflow 很有可能导致子结点,甚至父点以及同级结点的 reflow。
下面这些动作有很大可能会是成本比较高的:
增加、删除、修改 DOM 结点时,会导致 Reflow 或 Repaint
移动 DOM 的位置,或是搞个动画的时候
内容发生变化
修改 CSS 样式的时候
Resize 窗口的时候(移动端没有这个问题),或是滚动的时候
修改网页的默认字体时
基本上来说,reflow 有如下的几个原因:
Initial,网页初始化的时候
Incremental,一些 js 在操作 DOM 树时
Resize,其些元件的尺寸变了
StyleChange,如果 CSS 的属性发生变化了
Dirty,几个 Incremental 的 reflow 发生在同一个 frame 的子树上
八、关闭 TCP 连接或继续保持连接
通过四次挥手关闭连接(FIN ACK, ACK, FIN ACK, ACK)。
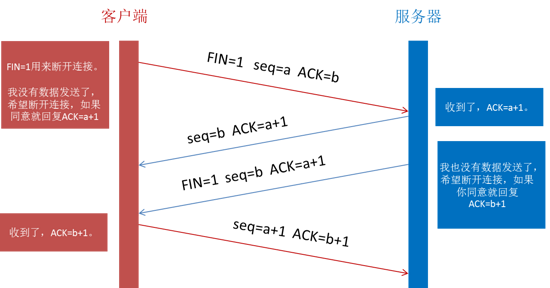
第一次挥手是浏览器发完数据后,发送 FIN 请求断开连接。
第二次挥手是服务器发送 ACK 表示同意,如果在这一次服务器也发送 FIN 请求断开连接似乎也没有不妥,但考虑到服务器可能还有数据要发送,所以服务器发送 FIN 应该放在第三次挥手中。
这样浏览器需要返回 ACK 表示同意,也就是第四次挥手。
至此从浏览器地址栏输入 URL 到页面呈现到你面前的整个过程就分析完了。
一 强制缓存
强制缓存整体流程比较简单,就是在第一次访问服务器取到数据之后,在过期时间之内不会再去重复请求。实现这个流程的核心就是如何知道当前时间是否超过了过期时间。
强制缓存的过期时间通过第一次访问服务器时返回的响应头获取。在 http 1.0 和 http 1.1 版本中通过不同的响应头字段实现。
http 1.0
在 http 1.0 版本中,强制缓存通过 Expires 响应头来实现。 expires 表示未来资源会过期的时间。也就是说,当发起请求的时间超过了 expires 设定的时间,即表示资源缓存时间到期,会发送请求到服务器重新获取资源。而如果发起请求的时间在 expires 限定的时间之内,浏览器会直接读取本地缓存数据库中的信息(from memory or from disk),两种方式根据浏览器的策略随机获取。
http 1.1
在 http 1.1 版本中,强制缓存通过 Cache-Control 响应头来实现。Cache-Control 拥有多个值:
private:客户端可以缓存
public:客户端和代理服务器均可缓存;
max-age=xxx:缓存的资源将在 xxx 秒后过期;
no-cache:需要使用协商缓存来验证是否过期;
no-store:不可缓存
最常用的字段就是 max-age=xxx ,表示缓存的资源将在 xxx 秒后过期。一般来说,为了兼容,两个版本的强制缓存都会被实现。
总结
强制缓存只有首次请求才会跟服务器通信,读取缓存资源时不会发出任何请求,资源的 Status 状态码为 200,资源的 Size 为 from memory 或者 from disk ,http 1.1 版本的实现优先级会高于 http 1.0 版本的实现。
二 协商缓存
协商缓存与强制缓存的不同之处在于,协商缓存每次读取数据时都需要跟服务器通信,并且会增加缓存标识。在第一次请求服务器时,服务器会返回资源,并且返回一个资源的缓存标识,一起存到浏览器的缓存数据库。当第二次请求资源时,浏览器会首先将缓存标识发送给服务器,服务器拿到标识后判断标识是否匹配,如果不匹配,表示资源有更新,服务器会将新数据和新的缓存标识一起返回到浏览器;如果缓存标识匹配,表示资源没有更新,并且返回 304 状态码,浏览器就读取本地缓存服务器中的数据。
在 http 协议的 1.0 和 1.1 版本中也有不同的实现方式。
http 1.0
在 http 1.0 版本中,第一次请求资源时服务器通过 Last-Modified 来设置响应头的缓存标识,并且把资源最后修改的时间作为值填入,然后将资源返回给浏览器。在第二次请求时,浏览器会首先带上 If-Modified-Since 请求头去访问服务器,服务器会将 If-Modified-Since 中携带的时间与资源修改的时间匹配,如果时间不一致,服务器会返回新的资源,并且将 Last-Modified 值更新,作为响应头返回给浏览器。如果时间一致,表示资源没有更新,服务器返回 304 状态码,浏览器拿到响应状态码后从本地缓存数据库中读取缓存资源。
这种方式有一个弊端,就是当服务器中的资源增加了一个字符,后来又把这个字符删掉,本身资源文件并没有发生变化,但修改时间发生了变化。当下次请求过来时,服务器也会把这个本来没有变化的资源重新返回给浏览器。
http 1.1
在 http 1.1 版本中,服务器通过 Etag 来设置响应头缓存标识。Etag 的值由服务端生成。在第一次请求时,服务器会将资源和 Etag 一并返回给浏览器,浏览器将两者缓存到本地缓存数据库。在第二次请求时,浏览器会将 Etag 信息放到 If-None-Match 请求头去访问服务器,服务器收到请求后,会将服务器中的文件标识与浏览器发来的标识进行对比,如果不相同,服务器返回更新的资源和新的 Etag ,如果相同,服务器返回 304 状态码,浏览器读取缓存。
总结
协商缓存每次请求都会与服务器交互,第一次是拿数据和标识的过程,第二次开始,就是浏览器询问服务器资源是否有更新的过程。每次请求都会传输数据,如果命中缓存,则资源的 Status 状态码为 304 而不是 200 。同样的,一般来讲为了兼容,两个版本的协商缓存都会被实现,http 1.1 版本的实现优先级会高于 http 1.0 版本的实现。
强制缓存优先于协商缓存进行,若强制缓存(Expires 和 Cache-Control)生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since 和 Etag / If-None-Match),协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,重新获取请求结果,再存入浏览器缓存中;生效则返回 304,继续使用缓存,主要过程如下:


1、GET在浏览器回退时是无害的,而POST会再次提交请求。
2、GET产生的URL地址可以被Bookmark,而POST不可以
3、GET请求会被浏览器主动cache,而POST不会,除非手动设置。
4、GET请求只能进行url编码,而POST支持多种编码方式。
5、GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
6、GET请求在URL中传送的参数是有长度限制的(浏览器限制),而POST没有。
7、对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
8、GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
9、GET参数通过URL传递,POST放在Request body中。
GET和POST还有一个重大区别,简单的说:
GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)
重载
函数名相同,函数的参数列表不同(包括参数个数和参数类型),根据参数的不同去执行不同的操作。在JavaScript中,同一个作用域,出现两个名字一样的函数,后面的会覆盖前面的,所以 JavaScript 没有真正意义的重载。
// 可以跟据arguments个数实现重载
function fn(){
switch(arguments.length){
case 0:
addFn(arguments.length)
break
case 1:
deleteFn(arguments.length)
}
}
function addFn(n){
console.log(`fn函数参数个数为${n+1}个`)
}
function deleteFn(n){
console.log(`fn函数参数个数为${n-1}个`)
}
fn() // fn函数参数个数为1个
fn(1) // fn函数参数个数为0个
重写
“实例中的指针仅指向原型,而不是指向构造函数”。 “重写原型对象切断了现有原型与任何之前已经存在的对象实例之间的关系;它们引用的仍然是最初的原型”。
var parent = function(name,age){
this.name = name;
this.age = age;
}
parent.prototype.showProper = function(){
console.log(this.name+":"+this.age);
}
var child = function(name,age){
parent.call(this,name,age);
}
// inheritance
child.prototype = Object.create(parent.prototype);
// child.prototype = new parent();
child.prototype.constructor = child;
// rewrite function
child.prototype.showProper = function(){
console.log('I am '+this.name+":"+this.age);
}
var obj = new child('wozien','22');
obj.showProper();上面这段代码通过使用寄生组合继承,实现子类私有继承父类私有,子类公有继承父类公有,达到重写父类的showProper
React Fiber 原理介绍
在 React Fiber 架构面世一年多后,最近 React 又发布了最新版 16.8.0,又一激动人心的特性:React Hooks 正式上线,让我升级 React 的意愿越来越强烈了。在升级之前,不妨回到原点,了解下人才济济的 React 团队为什么要大费周章,重写 React 架构,而 Fiber 又是个什么概念。
这是React 核心算法的一次大的更新,重写了 React 的 reconciliation 算法。reconciliation 算法是用来更新并且渲染DOM树的算法。以前React 15.x的版本使用的算法称为“stack reconciliation”,现在称为“fiber reconciler”。
fiber reconciler主要的特点是可以把更新流程拆分成一个一个的小的单元进行更新,并且可以中断,转而去执行高优先级的任务或者浏览器的动画渲染等,等主线程空闲了再继续执行更新。
React 15 的问题
在页面元素很多,且需要频繁刷新的场景下,React 15 会出现掉帧的现象。
其根本原因,是大量的同步计算任务阻塞了浏览器的 UI 渲染。默认情况下,JS 运算、页面布局和页面绘制都是运行在浏览器的主线程当中,他们之间是互斥的关系。如果 JS 运算持续占用主线程,页面就没法得到及时的更新。当我们调用setState更新页面的时候,React 会遍历应用的所有节点,计算出差异,然后再更新 UI。整个过程是一气呵成,不能被打断的。如果页面元素很多,整个过程占用的时机就可能超过 16 毫秒,就容易出现掉帧的现象。
解题思路
解决主线程长时间被 JS 运算占用这一问题的基本思路,是将运算切割为多个步骤,分批完成。也就是说在完成一部分任务之后,将控制权交回给浏览器,让浏览器有时间进行页面的渲染。等浏览器忙完之后,再继续之前未完成的任务。
旧版 React 通过递归的方式进行渲染,使用的是 JS 引擎自身的函数调用栈,它会一直执行到栈空为止。而Fiber实现了自己的组件调用栈,它以链表的形式遍历组件树,可以灵活的暂停、继续和丢弃执行的任务。实现方式是使用了浏览器的requestIdleCallback这一 API。官方的解释是这样的:
window.requestIdleCallback()会在浏览器空闲时期依次调用函数,这就可以让开发者在主事件循环中执行后台或低优先级的任务,而且不会对像动画和用户交互这些延迟触发但关键的事件产生影响。函数一般会按先进先调用的顺序执行,除非函数在浏览器调用它之前就到了它的超时时间。
本文从 React 15 存在的问题出发,介绍 React Fiber 解决问题的思路,并介绍了 Fiber Reconciler 的工作流程。从Stack Reconciler到Fiber Reconciler,源码层面其实就是干了一件递归改循环的事情.
React(组件中的onClick)
JSX的onClick事件处理方式和HTML的onclick有很大不同。 在HTML中直接使用onclick很不专业,原因如下
onclick添加的事件处理函数是在全局环境下执行的,这污染了全局环境,很容易产生意料不到的后果;
给很多DOM元素添加onclick事件,可能会影响网页的性能,毕竟,网页需要的事件处理函数越多,性能就会越低;
对于使用onclick的DOM元素,如果要动态地从DOM树中删掉的话,需要把对应的时间处理器注销,假如忘了注销,就可能造成内存泄露,这样的bug很难被发现。
上面说的这些问题,在JSX中都不存在。
onClick挂载的每个函数,都可以控制在组件范围内,不会污染全局空间。
我们在JSX中看到一个组件使用了onClick,但并没有产生直接使用onclick(注意是onclick不是onClick)的HTML,而是使用了事件委托(eventdelegation)的方式处理点击事件,无论有多少个onClick出现,其实最后都只在DOM树上添加了一个事件处理函数,挂在最顶层的DOM节点上。所有的点击事件都被这个事件处理函数捕获,然后根据具体组件分配给特定函数,使用事件委托的性能当然要比为每个onClick都挂载一个事件处理函数要高。
React Hooks的常见应用及一些原理
类组件(class)类组件的缺点:
大型组件很难拆分和重构,也很难测试
业务逻辑分散在组件的各个方法中,导致重复逻辑或关联逻辑
组件类引入复杂的编程模式,比如render、props
import React, { Component } from "react";
export default class Button extends Component {
constructor() {
super();
this.state = { buttonText: "Click me, please" };
this.handleClick = this.handleClick.bind(this);
}
handleClick() {
this.setState(() => {
return { buttonText: "Thanks, been clicked!" };
});
}
render() {
const { buttonText } = this.state;
return <button onClick={this.handleClick}>{buttonText}</button>;
}
}函数组件 目的:React团队希望,组件不要变成复杂的容器,最好只是数据流的管道,开发者可以根据需要组合管道。完全不使用类就能写出一个全功能组件
function Welcome(props) {
return <h1>Hello, {props.name}</h1>;
}这种写法有重大限制,必须是纯函数,不能包含状态,也不支持生命周期方法,因此无法取代类。
Hooks
React核心思想是将页面拆成一堆独立的、可复用的组件,并且用自上而下的数据流串联起来。但是在实际项目中很多组件冗长且难以复用。
React Hooks要解决的问题是状态逻辑复用。
React Hooks 的意思是,组件尽量写成纯函数,如果需要外部功能和副作用,就用钩子把外部代码"钩"进来。
React默认提供了一些常用函数,同时也允许封装自己的钩子,React约定,所有钩子函数一律用use前缀命名,意思是为函数引入外部功能。
4种常见函数:
useState()
useContext()
useReducer()
useEffect()useState(状态钩子) 纯函数不能有状态,useState用于为函数组件引入状态。
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}useEffect(副作用钩子)
可将useEffect视为componentDidMount,componentDidUpdate 和 componentWillUnmount 的组合。
hooks 更多详细内容 https://www.jianshu.com/p/e6265f3f2a81
React网络请求到底该放在哪个生命周期中?
总的来说,对于异步请求,最好放在componentDidMount中去操作,对于同步的状态改变,可以放在componentWillMount中,一般用的比较少。
如果认为在componentWillMount里发起请求能提早获得结果,这种想法其实是错误的,通常componentWillMount比componentDidMount早不了多少微秒,网络上任何一点延迟,这一点差异都可忽略不计。
看看react的生命周期:
**constructor() ----> componentWillMount() ----> render() ----> componentDidMount()**上面这些方法的调用是有次序的,由上而下依次调用。
constructor被调用是在组件准备要挂载的最开始,此时组件尚未挂载到网页上。
componentWillMount方法的调用在constructor之后,在render之前,在这方法里的代码调用setState方法不会触发重新render,所以它一般不会用来作加载数据之用。
componentDidMount方法中的代码,是在组件已经完全挂载到网页上才会调用被执行,所以可以保证数据的加载。此外,在这方法中调用setState方法,会触发重新渲染。所以,官方设计这个方法就是用来加载外部数据用的,或处理其他的副作用代码。与组件上的数据无关的加载,也可以在constructor里做,但constructor是做组件state初绐化工作,并不是做加载数据这工作的,constructor里也不能setState,还有加载的时间太长或者出错,页面就无法加载出来。所以有副作用的代码都会集中在componentDidMount方法里。
总结:
1.跟服务器端渲染(同构)有关系,如果在componentWillMount里面获取数据,fetch data会执行两次,一次在服务器端一次在客户端。在componentDidMount中可以解决这个问题,componentWillMount同样也会render两次。
2.在componentWillMount中fetch data,数据一定在render后才能到达,如果你忘记了设置初始状态,用户体验不好。
3.react16.0以后,componentWillMount可能会被执行多次。
React setState是同步还是异步的
setTimeout和原生事件中,可以立即拿到更新结果。也就是同步。
在合成事件和生命周期中,不能立即拿到更新结果。也就是所谓的“异步”。
在合成事件和生命周期中,如果对同一个值进行多次setState,setState的批量更新策略会对其进行覆盖,取最后一次的执行。
1、关于埋点或者无账号登录状态下如何确定用户标识信息 | 指纹ID
UV和PV埋点的方式相同,唯一不同的地方就是UV需要在PV的基础上通过唯一标示进行筛选。统计有多少个唯一标示而得UV的数量,一般我们常见的唯一标示如下:
手机号:用户登录页面后依据他绑定的手机号来进行统计,但是如果用户未登录将无法统计;
cookie:通过用户浏览器上的cookie作为唯一标示,但因为cookie是存在用户浏览器中容易被修改;
localStorage:通过在浏览器在本地存储一个长期唯一标示,但是可以手动清理;
IP:通过访问页面ip地址进行区分,如果ip变更将另行计算;
seesionStorae:通过存在服务器的信息进行表示,有实效性。
这5个就是我们常用作为UV唯一标示的,他们推荐使用的优先级手机>ip>local>cookie>seesion。
其实在以上(除账号体系登录的情况下)几种无状态用户的情况下,都不是最佳方案!
今天给大家介绍一种 murmurhash3 算法 ,fingerprintjs生成用户指纹id库,通过几十种信息组合,降低id 重复率。
https://github.com/pid/murmurHash3js
1、User Agent
2、语言
3、颜色深度
4、屏幕分辨率
5、时区
6、是否具有会话存储
7、是否具有本地存储
8、是否具有索引DB
9、IE是否指定AddBehavior
10、是否有打开的DB
11、CPU类
12、平台
13、是否DoNotTrack
14、已安装的Flash字体列表
15、使用JS/CSS检测到的字体列表(最多可检测到Flash之外的500种字体)
16、Canvas指纹
17、WebGL指纹
18、浏览器的插件信息
19、是否安装AdBlock
20、用户是否篡改了语言
21、用户是否篡改了屏幕分辨率
22、用户是否篡改了操作系统
23、用户是否篡改了浏览器
24、触摸屏检测和能力一般情况下,JS字体检测最多可检测65种已安装的字体。用户可通过使用extendedFontList: true选项提升字体检测能力,可提升到500种。
更多指纹资源
1、多显示器检测
2、Silverlight集成
3、Flash linux内核版本
4、内部哈希表执行检测
5、WebRTC指纹
6、Math常数
7、可访问性指纹
8、相机信息
9、DRM支持
10、加速器支持
11、虚拟键盘
12、手势列表(触摸设备)
13、像素密度
14、视频和音频编解码器的可用性这里有个小的hack 需要处理,下面是我测试的安卓和苹果的微信浏览器用fingerprintjs2.js生成的系统浏览器UA,只有网络这里需要更改。安卓其他浏览器测试倒是没发现有NetType/WIFI字段。
安卓4G微信浏览器生成的userAgent
Mozilla/5.0 (Linux; Android 10; GM1910 Build/QKQ1.190716.003; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/66.0.3359.126 MQQBrowser/6.2 TBS/045008 Mobile Safari/537.36 MMWEBID/6063 MicroMessenger/7.0.8.1540(0x27000834) Process/tools NetType/4G Language/zh_CN ABI/arm64安卓wifi微信浏览器生成的userAgent
Mozilla/5.0 (Linux; Android 10; GM1910 Build/QKQ1.190716.003; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/66.0.3359.126 MQQBrowser/6.2 TBS/045008 Mobile Safari/537.36 MMWEBID/6063 MicroMessenger/7.0.8.1540(0x27000834) Process/tools NetType/WIFI Language/zh_CN ABI/arm64"苹果wifi微信浏览器生成的userAgent
Mozilla/5.0 (iPhone; CPU iPhone OS 12_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.8(0x17000820) NetType/WIFI Language/zh_CN苹果4G微信浏览器生成的userAgent
Mozilla/5.0 (iPhone; CPU iPhone OS 12_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.8(0x17000820) NetType/4G Language/zh_CN官方给的演示代码生成的指纹ID在大部分浏览器都没问题,就是在微信浏览器里因为UA多了网络字段,所以导致生成的ID不一样。把NetType/**网络部分替换成空,就能确保微信浏览器里切换4G或者WIFI网络后,指纹ID也能保持一致了。
Fingerprint2.get(function(components) {
const values = components.map(function(component,index) {
if (index === 0) { //把微信浏览器里UA的wifi或4G等网络替换成空,不然切换网络会ID不一样
return component.value.replace(/\bNetType\/\w+\b/, '')
}
return component.value
})
// 生成最终id murmur
const murmur = Fingerprint2.x64hash128(values.join(''), 31)
})部分来自:https://www.xiedandan.com/post-11.html
未完待续~
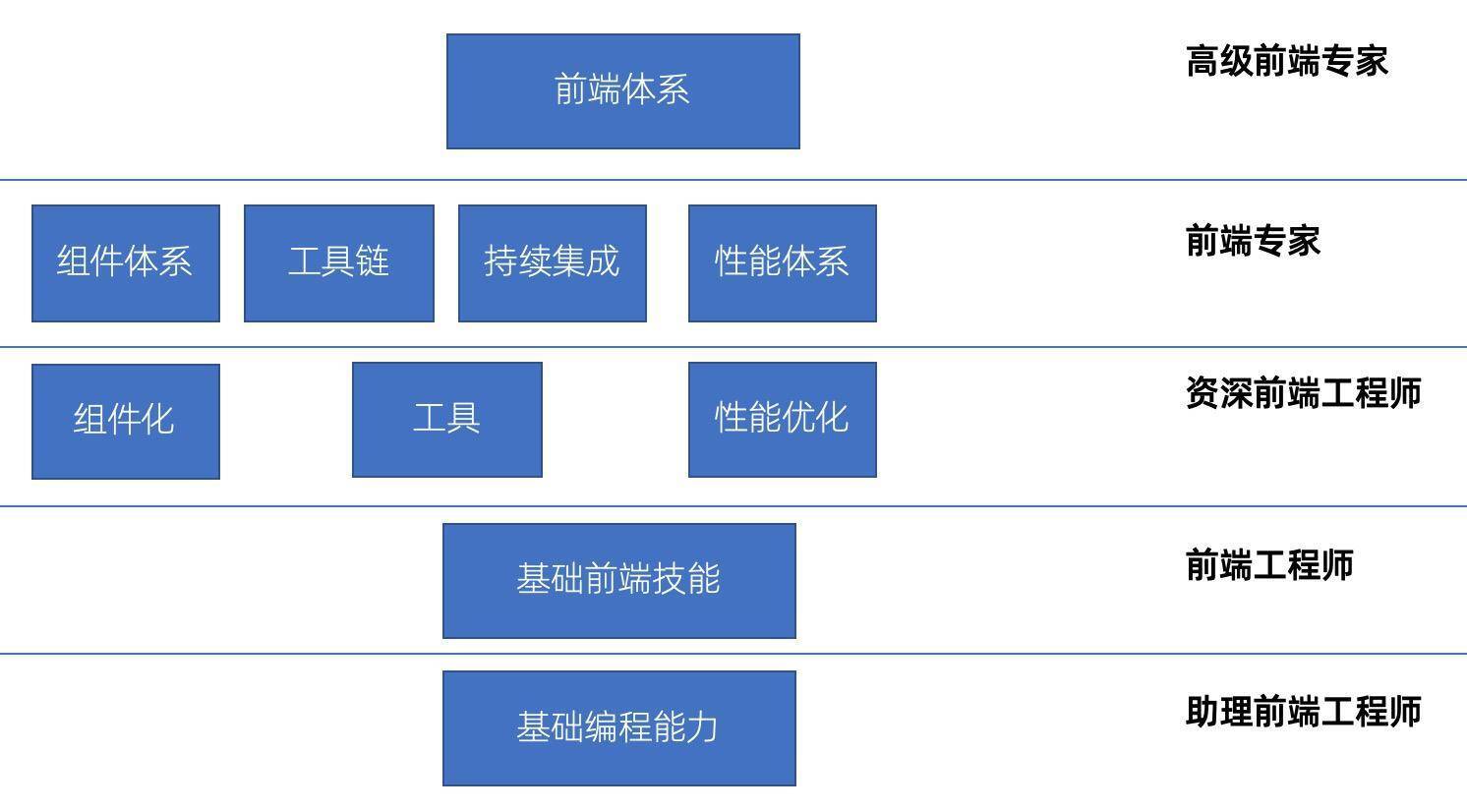
前端技术专家
对标阿里 P7 级别。到了这个级别,我们从图上可以看到,要求又不一样了,比如组件变成了组件体系,工具变成了工具链和持续集成体系,性能优化变成了性能体系。这些东西变得不仅仅是称呼,还有工作的内容,这个级别跟资深工程师的主要区别是,从解决单点问题变成系统性方法,从服务自己变成服务团队,从一次性发挥变成持续性输出。比如,资深工程师可能做一些组件,然后在项目里面用,自己的代码可维护性提升了,复用也做得更好了。但是前端专家要考虑制定组件规范推广到团队,还要做培训,考虑组件如何开发、管理和下线。资深工程师做性能,把自己的页面优化好了就可以了,但是前端专家就需要考虑采集数据、做报表和监控、总结 checklist、跟工具结合、定性能指标等等。由于这个级别对架构能力、工程和软技能要求很高,所以算是比较难以跨越的。