Maksim Kuprashevich, Grigorii Alekseenko, Irina Tolstykh, Georgii Fedorov, Bulat Suleimanov, Vladimir Dokholyan, Aleksandr Gordeev
Recent advances in generative modeling enable image editing assistants that follow natural language instructions without additional user input. Their supervised training requires millions of triplets <original image, instruction, edited image>, yet mining pixel-accurate examples is hard. Each edit must affect only prompt-specified regions, preserve stylistic coherence, respect physical plausibility, and retain visual appeal. The lack of robust automated edit-quality metrics hinders reliable automation at scale. We present an automated, modular pipeline that mines high-fidelity triplets across domains, resolutions, instruction complexities, and styles. Built on public generative models and running without human intervention, our system uses a task-tuned Gemini validator to score instruction adherence and aesthetics directly, removing any need for segmentation or grounding models. Inversion and compositional bootstrapping enlarge the mined set by
$\approx 2.2\times$ , enabling large-scale high-fidelity training data. By automating the most repetitive annotation steps, the approach allows a new scale of training without human labeling effort. To democratize research in this resource-intensive area, we release NHR-Edit, an open dataset of$358k$ high-quality triplets. In the largest cross-dataset evaluation, it surpasses all public alternatives. We also release Bagel-NHR-Edit, an open-source fine-tuned Bagel model, which achieves state-of-the-art metrics in our experiments.
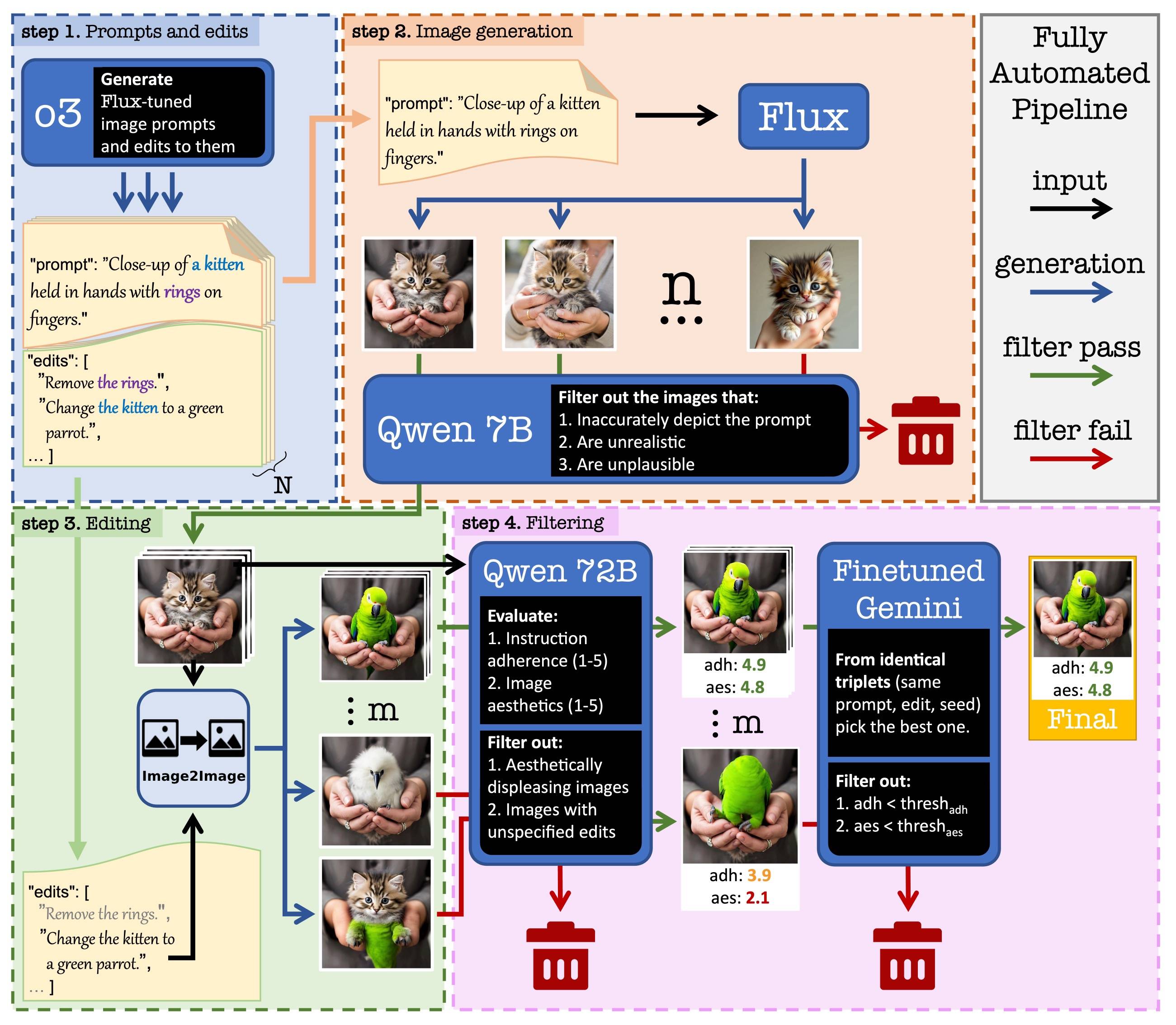
Autonomous Dataset Generation Pipeline. A fully automated system for creating high-quality image-editing datasets: prompts and edit instructions are generated by an LLM, initial images are produced using Flux, edits are applied via Image2Image models, and Qwen models evaluate instruction adherence and aesthetics, with the best triplets selected by a finetuned Gemini model, ensuring scalable and visually appealing data generation.
[17/07/2025] NHR-Edit Dataset and Bagel-NHR-Edit has been published on HuggingFace.
[18/07/2025] 🔥🔥🔥 Paper has been published on Arxiv.
[21/07/2025] Bagel-NHR-Edit Demo has been published on HuggingFace 🤗.
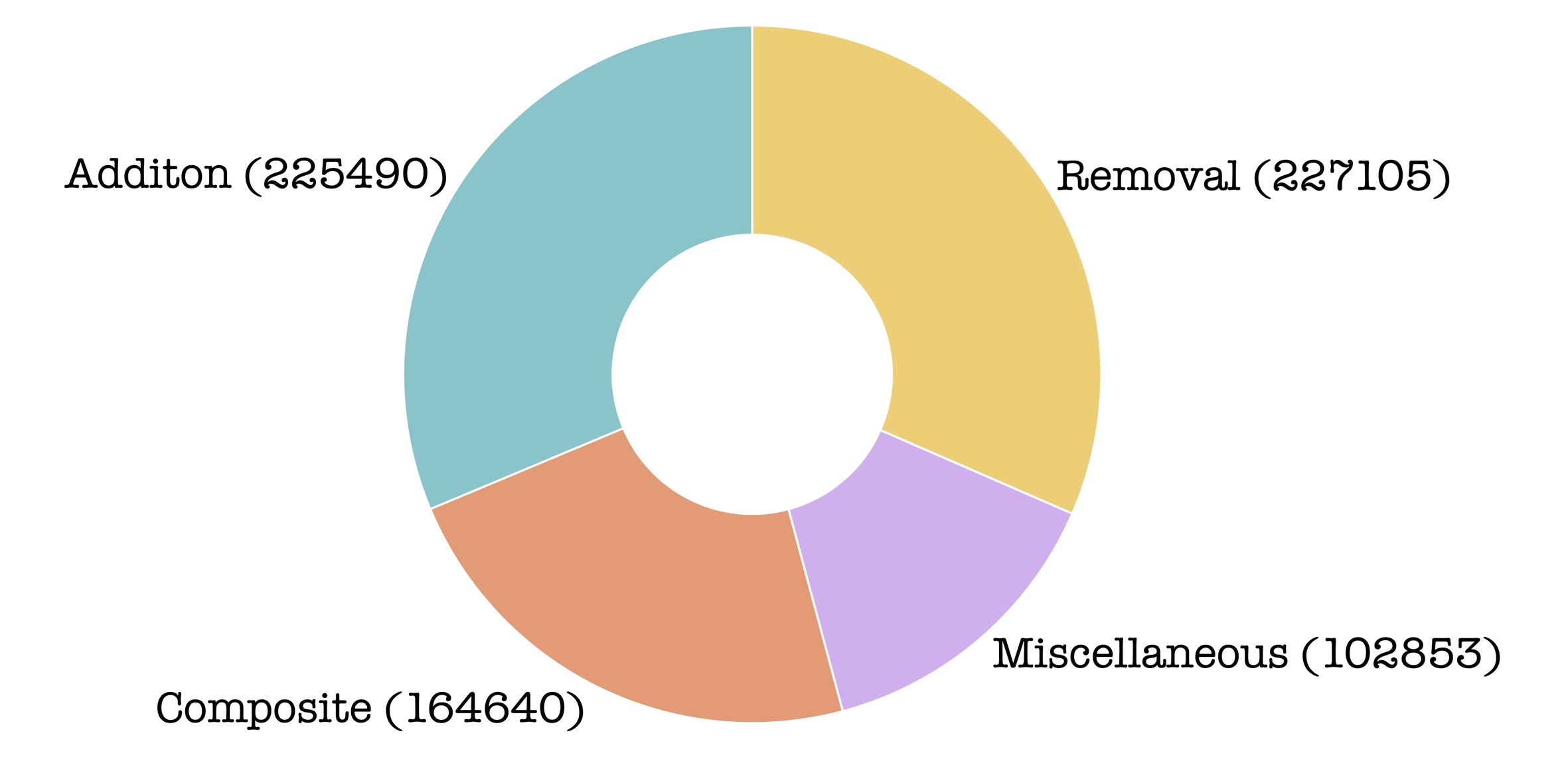
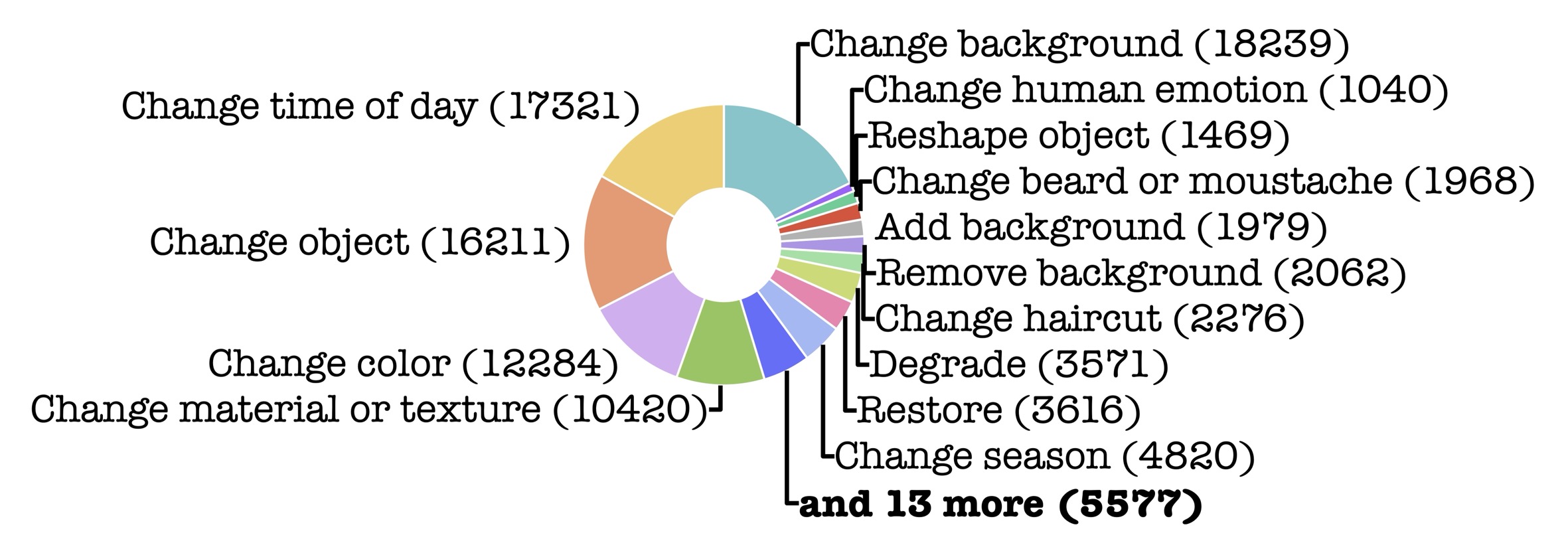
- Unique source images: 286,608
- Instruction-image pairs (triplets): 358,463
- Image resolution: variable (metadata includes exact width/height)
Bagel-NHR-Edit is a model fine-tuned on the NHR-Edit dataset using parameter-efficient LoRA adaptation on the generation expert’s attention and FFN projection layers.
PWC Leaderboards: ImgEdit, GEdit-Bench-EN
| Model | GEdit-Bench-EN (SC) ↑ | GEdit-Bench-EN (PQ) ↑ | GEdit-Bench-EN (O) ↑ |
|---|---|---|---|
| BAGEL-7B-MoT | 7.983 | 6.570 | 6.921 |
| BAGEL-NHR-Edit | 8.067 | 6.881 | 7.115 |
Scoring model:
gpt-4.1-2025-04-14(with default temperature)
| Model | Style | Extract | Remove | Background | Action | Adjust | Add | Replace | Compose | Overall ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| BAGEL-7B-MoT | 4.22 | 1.53 | 3.04 | 3.3 | 4.07 | 3.67 | 3.98 | 3.5 | 3.0 | 3.3 |
| BAGEL-NHR-Edit | 4.3 | 1.62 | 3.18 | 3.42 | 3.95 | 3.55 | 4.19 | 3.77 | 2.94 | 3.39 |
Scoring model:
gpt-4o-2024-11-20(with temperature = 0.0)
Results comparison between original Bagel-7B-MoT and BAGEL-NHR-EDIT on samples from ImgEdit and GEdit benches:

@article{Layer2025NoHumansRequired,
arxivId = {2507.14119},
author = {Maksim Kuprashevich and Grigorii Alekseenko and Irina Tolstykh and Georgii Fedorov and Bulat Suleimanov and Vladimir Dokholyan and Aleksandr Gordeev},
title = {{NoHumansRequired: Autonomous High-Quality Image Editing Triplet Mining}},
year = {2025},
eprint = {2507.14119},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2507.14119},
journal={arXiv preprint arXiv:2507.14119}
}