This repository contains the code for our paper "PanopticNDT: Efficient and Robust Panoptic Mapping" (IEEE Xplore, arXiv (with appendix and some minor fixes - see changelog below)).
(Click on the image to open YouTube video)
The source code is published under Apache 2.0 license, see license file for details.
If you use the source code or the network weights, please cite the following paper:
Seichter, D., Stephan, B., Fischedick, S. B., Müller, S., Rabes, L., Gross, H.-M. PanopticNDT: Efficient and Robust Panoptic Mapping, in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 7233-7240, 2023.
BibTeX
@inproceedings{panopticndt2023iros,
title = {{PanopticNDT: Efficient and Robust Panoptic Mapping}},
author = {Seichter, Daniel and Stephan, Benedict and Fischedick, S{\"o}hnke Benedikt and Mueller, Steffen and Rabes, Leonard and Gross, Horst-Michael},
booktitle = {IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS)},
year = {2023},
pages = {7233-7240},
}
% with appendix and some minor fixes - we recommend working with this version
@article{panopticndt2023arxiv,
title = {{PanopticNDT: Efficient and Robust Panoptic Mapping}},
author = {Seichter, Daniel and Stephan, Benedict and Fischedick, S{\"o}hnke Benedikt and Mueller, Steffen and Rabes, Leonard and Gross, Horst-Michael},
journal = {arXiv preprint arXiv:2309.13635},
year = {2023}
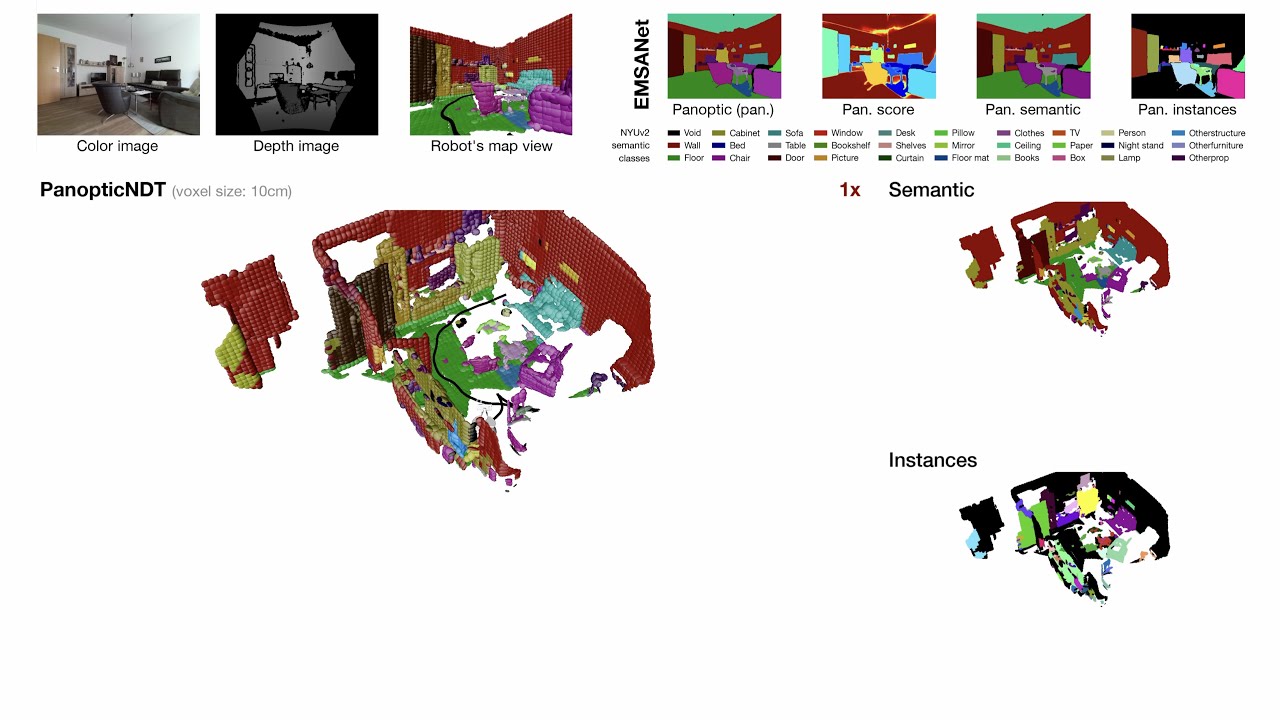
}Given a precise localization in the environment, our panoptic mapping approach comprises two steps. We first apply EMSANet – an efficient RGB-D panoptic segmentation approach – to the current set of input images (color and depth). Unlike other approaches, we decided in favor of an RGB-D approach as depth provides complementary information that helps segmenting cluttered indoor scenes. Afterward, the obtained panoptic segmentation, the depth image, and the current pose are passed to the panoptic mapping stage.
We evaluate our panoptic mapping approach on Hypersim and ScanNet in 3D and 2D. The evaluation protocol builds upon the publicly available ScanNet benchmark pipeline. Unfortunately, the ScanNet pipeline does not feature a panoptic evaluation. Therefore, we extend the existing pipeline with a complementary panoptic evaluation task.
We evaluate the predictions of EMSANet as well as back-projections of our panoptic mapping approach in 2D on three tasks:
- 2D semantic task: the original ScanNet 2D Semantic Label Prediction task with 20 semantic classes (metric: mIoU)
- 2D semantic instance task: the original ScanNet 2D Semantic Instance Prediction task, i.e., evaluation of foreground instances of thing classes with corresponding semantic class and segmentation mask (metric: AP_50)
- 2D panoptic task: the proposed complementary dense panoptic evaluation taking into account both stuff and thing classes (metric: PQ and mIoU)
The data format for our proposed 2D panoptic task follows the same naming convention and data format as the original ScanNet 2D Semantic Label Prediction task. Label encoding is similar to the ground-truth encoding for the ScanNet 2D Semantic Instance Prediction task. However, as Hypersim features much more (small) instances than ScanNet, label encoding cannot be done in grayscale png16 (uint16) with sem*1000+ins. Instead, we encode panoptic labels as RGB png8 with R: semantic class (uint8), G+B: instance id (uint16), i.e., sem*(1<<16)+ins is used. We also adopt the same label encoding for encoding the ground truth for the 2D semantic instance task to support Hypersim.
We describe the 2D ground-truth generation below in section Extract 2D ground truth and EMSANet predictions for evaluation / mapping.
Similar to the 2D evaluation, we evaluate our panoptic mapping approach in 3D on the same three tasks:
- 3D semantic task: the original 3D Semantic Label Prediction task with 20 semantic classes (metric: mIoU)
- 3D semantic instance task: the original ScanNet 3D Semantic Instance Prediction task, i.e., evaluation of foreground instances of thing classes with corresponding semantic class and segmentation mask (metric: AP_50)
- 3D panoptic task: the proposed complementary dense panoptic evaluation taking into account both stuff and thing classes (metric: PQ and mIoU)
The ground truth for all three tasks is given as txt files with each line describing the label of a corresponding point in a point-cloud representation. For the 3D semantic instance task and the 3D panoptic task, similar to 2D, we change the label encoding in the txt files from sem*1000+ins to sem*(1<<16)+ins to support Hypersim as well.
We describe the 3D ground-truth generation below in section Extract 3D ground truth.
To enable other researchers to have a similar setup and to compare to our panoptic mapping approach, we share the pipeline for data preparation and evaluation as well as the training details and weights of all neural networks involved. Follow the steps below to reproduce results or to integrate parts in our pipeline.
- Setup and environment
- Prepare data
- Download pretrained models
- Extract 2D ground truth and EMSANet predictions for evaluation / mapping
- Reproduce reported EMSANet results
- Extract 3D ground truth
- Run mapping experiments
- Evaluate mapping results
- Changelog
The required source code is distributed across multiple existing repositories that have been updated along with this publication. To make it easier to set up the environment, we provide this meta repository that contains all required repositories as submodules.
-
Clone repositories:
# do not forget the '--recursive' argument to clone all submodules git clone --recursive https://github.com/TUI-NICR/panoptic-mapping.git REPO_ROOT="/path/to/this/repository"
-
Set up anaconda environment including most relevant dependencies:
# create conda environment from YAML file # option 1: latest tested version (Python 3.11.0, PyTorch 2.3, Open3D 0.18.0) conda env create -f panoptic_mapping_2024.yml conda activate panoptic_mapping_2024 # option 2: original publication (Python 3.8.16, PyTorch 1.13.0) conda env create -f panoptic_mapping.yml conda activate panoptic_mapping
-
Install remaining packages required for preparing datasets and EMSANet:
# dataset package - required for preparing the datasets and EMSANet python -m pip install -e "${REPO_ROOT}/emsanet/lib/nicr-scene-analysis-datasets[withpreparation,with3d]" # multi-task scene analysis package - required for EMSANet and metric calculation python -m pip install -e "${REPO_ROOT}/emsanet/lib/nicr-multitask-scene-analysis"
-
Patch ScanNet submodule: We have modified the ScanNet benchmark scripts:
- to support Python 3.X
- to support recent NumPy versions (fixes for np.bool vs bool, ...)
- to support the Hypersim dataset (requires changing label representation from sem*1000+ins to sem*(1<<16)+ins, as Hypersim has more than 1000 instances in a scene)
- to feature a panoptic evaluation tasks in both 2D and 3D as well
- to write results as *.json files in addition to existing *.txt files (simplifies automatic results parsing)
The patch below applies all the changes required to the original ScanNet benchmark code.
cd ${REPO_ROOT}/evaluation patch -s -p0 < scannet_benchmark_code.patch
Even after the patch is applied, the code quality of the benchmark scripts is still a bit rough. However, it is not up to us to improve on that.
-
Build Cython extension for faster 2D semantic evaluation:
The published original ScanNet benchmark script for the 2D semantic task is very slow and cannot handle the void class. Therefore, we re-added the Cython implementation from cityscapesScripts for faster evaluation. Follow the instructions below to compile the extension to get results in a fraction of the time.
# install cython python -m pip install cython # last tested: 3.0.10 # build extension cd ${REPO_ROOT}/evaluation/ScanNet/BenchmarkScripts/2d_evaluation rm __init__.py # this empty file needs to be removed to avoid compiler errors python setup.py build_ext --inplace
We provide scripts that automate dataset preparation along with our nicr-scene-analysis-datasets python package.
HYPERSIM_DOWNLOAD_PATH=${REPO_ROOT}/datasets/hypersim_preparation
HYPERSIM_PATH=${REPO_ROOT}/datasets/hypersim
# download and extract raw dataset (2x ~1.8TB)
wget https://raw.githubusercontent.com/apple/ml-hypersim/6cbaa80207f44a312654e288cf445016c84658a1/code/python/tools/dataset_download_images.py
python dataset_download_images.py --downloads_dir ${HYPERSIM_DOWNLOAD_PATH}
# prepare dataset (~147 GB):
# - extract required data & convert to our format
# - convert non-standard perspective projection matrices (with tilt-shift photography parameters)
# - blacklist some broken scenes/trajectories
nicr_sa_prepare_dataset hypersim \
${HYPERSIM_PATH} \
${HYPERSIM_DOWNLOAD_PATH} \
--additional-subsamples 2 5 10 20 \
--n-processes 16
# just in case you want to delete the downloaded raw data (2x ~1.8TB)
# rm -rf $HYPERSIM_DOWNLOAD_PATH We refer to the documentation of our nicr-scene-analysis-datasets python package for further details.
To be able to download the dataset fill out the ScanNet Terms of Use and send it to [email protected].
Once your request is approved, you will receive the download_scannet.py script.
SCANNET_DOWNLOAD_PATH=${REPO_ROOT}/datasets/scannet_preparation
SCANNET_PATH=${REPO_ROOT}/datasets/scannet
# download and extract raw dataset (~1.7TB, do not skip .sens files)
python download-scannet.py -o ${SCANNET_DOWNLOAD_PATH}
# prepare dataset (~293 GB):
# - extract required data & convert to our format
# - blacklist some broken images
# - important subsamples: 5 - used for mapping, 50 - used for training, 100 - required for benchmark
nicr_sa_prepare_dataset scannet \
${SCANNET_DOWNLOAD_PATH} \
${SCANNET_PATH} \
--num-processes 16 \
--subsample 5 \
--additional-subsamples 10 50 100 200 500
# just in case you want to delete the downloaded raw data (~1.7TB), however, note
# that the raw data is required later again for extracting 3D ground truth
# rm -rf $SCANNET_DOWNLOAD_PATH We refer to the documentation of our nicr-scene-analysis-datasets python package for further details.
We provide the weights of our EMSANet-R34-NBt1D (enhanced ResNet34-based encoder utilizing the Non-Bottleneck-1D block) used for Hypersim and ScanNet experiments.
Download the weights for Hypersim and ScanNet and extract them to ./trained_models or use:
python -m pip install gdown # last tested: 5.2.0
# Hypersim
gdown 1gbu2H9zh7-1kGW8-NI_6eU3mcW_J0j-l --output ${REPO_ROOT}/trained_models/
tar -xvzf ${REPO_ROOT}/trained_models/model_hypersim.tar.gz -C ${REPO_ROOT}/trained_models/
# ScanNet
gdown 1x0Ud6qhqfb5DNjHmhiP9xiau5snKceWb --output ${REPO_ROOT}/trained_models/
tar -xvzf ${REPO_ROOT}/trained_models/model_scannet.tar.gz -C ${REPO_ROOT}/trained_models/We refer to the shipped '*_argv.txt' file next to the weights file for the training command used to obtain the weights.
We further provide the weights for the network used for application and shown in the video above.
The network was trained simultaneously on NYUv2, Hypersim, SUNRGB-D, and ScanNet.
The best epoch was chosen based on the performance on the SUNRGB-D test split.
For more details, we refer to the appendix of our paper (available on arXiv).
Click here to download the weights and extract them to ./trained_models or use:
python -m pip install gdown # last tested: 5.2.0
# Application network
gdown 1oSmEPkHAFVBx7Gut6jojVTjheyQTX4S3 --output ${REPO_ROOT}/trained_models/
tar -xvzf ${REPO_ROOT}/trained_models/model_application.tar.gz -C ${REPO_ROOT}/trained_models/We refer to the shipped '*_argv.txt' file next to the weights file for the training command used to obtain the weights.
We refer to the instructions given in ./trained_models for reproducing the results reported in our paper.
Finally, we also provide the weights of the application network fine-tuned on each of the four datasets above individually.
Download the weights for
NYUv2,
SUNRGB-D (refined instance annotations proposed in this paper),
Hypersim (with camera model correction presented in this paper),
ScanNet (20 classes), and
ScanNet (40 classes)
and extract them to ./trained_models or use:
python -m pip install gdown # last tested: 5.2.0
# Application network fine-tuned on NYUv2
gdown 1yuahzuza5urbb8zVVgKGTqTwla38m6CK --output ${REPO_ROOT}/trained_models/
tar -xvzf ${REPO_ROOT}/trained_models/model_application_nyuv2_finetuned.tar.gz -C ${REPO_ROOT}/trained_models/
# Application network fine-tuned on SUNRGB-D (refined instance annotations proposed in this paper)
gdown 1jIOq29bTwe0vnzsXIldePWd3fpj42BuQ --output ${REPO_ROOT}/trained_models/
tar -xvzf ${REPO_ROOT}/trained_models/model_application_sunrgbd_finetuned.tar.gz -C ${REPO_ROOT}/trained_models/
# Application network fine-tuned on Hypersim (with camera model correction presented in this paper)
gdown 1OSlTk3gbK0Pt3g-yt2fwtzMXoVyE4oOA --output ${REPO_ROOT}/trained_models/
tar -xvzf ${REPO_ROOT}/trained_models/model_application_hypersim_finetuned.tar.gz -C ${REPO_ROOT}/trained_models/
# Application network fine-tuned on ScanNet (20 classes)
gdown 1fhZ5L9mPPeL1_JxxtbhKVPf-i3eWykDo --output ${REPO_ROOT}/trained_models/
tar -xvzf ${REPO_ROOT}/trained_models/model_application_scannet20_finetuned.tar.gz -C ${REPO_ROOT}/trained_models/
# Application network fine-tuned on ScanNet (40 classes)
gdown 1oSWcjcrNDCEB9hHdB0JJBG7NI92cP7ab --output ${REPO_ROOT}/trained_models/
tar -xvzf ${REPO_ROOT}/trained_models/model_application_scannet40_finetuned.tar.gz -C ${REPO_ROOT}/trained_models/We refer to the shipped '*_argv.txt' file next to the weights file for the training command used to obtain the weights.
We refer to the instructions given in ./trained_models for reproducing the results reported in our paper.
We refer to the documentation of our nicr-scene-analysis-datasets python package for preparing the datasets.
To extract the predictions of our EMSANet model for Hypersim and ScanNet, use the inference_dataset.py script provided in the EMSANet submodule in ./emsanet.
The script supports multiple output formats, specified by the --inference-output-format argument:
scannet-semantic: export semantic predictions of EMSANet and corresponding GT for the 2D semantic taskscannet-instance: export instance part of the panoptic predictions of EMSANet and corresponding GT for the 2D semantic instance taskscannet-panoptic: export panoptic predictions of EMSANet and corresponding GT for the proposed 2D panoptic taskmapping: export EMSANet predictions for subsequent mapping
Adjust
--inference-batch-sizeto your GPU memory. The predefined batch size of 2 enables inference on GPUs with at least 8GB VRAM.
cd ${REPO_ROOT}/emsanet
WEIGHTS_FILEPATH=${REPO_ROOT}/trained_models/hypersim/r34_NBt1D.pth
DATASET_PATH=${REPO_ROOT}/datasets/hypersim
# predict all four outputs at once:
# - valid: 0.5GB + 1.3GB + 0.7GB + 23GB
# - test: 0.6GB + 1.4GB + 0.7GB + 23GB
for SPLIT in "valid" "test"
do
python inference_dataset.py \
--dataset hypersim \
--dataset-path ${DATASET_PATH} \
--use-original-scene-labels \
--tasks semantic normal scene instance orientation \
--enable-panoptic \
--no-pretrained-backbone \
--weights-filepath ${WEIGHTS_FILEPATH} \
--input-height 768 \
--input-width 1024 \
--context-module appm-1-2-4-8 \
--instance-center-heatmap-top-k 128 \
--instance-offset-distance-threshold 40 \
--inference-batch-size 2 \
--inference-split ${SPLIT} \
--inference-input-height 768 \
--inference-input-width 1024 \
--inference-output-format scannet-semantic scannet-instance scannet-panoptic mapping \
--inference-output-write-ground-truth \
--inference-output-ground-truth-max-depth 20 \
--inference-output-semantic-instance-shift $((2**16))
doneBy default, the outputs are stored at: ${REPO_ROOT}/trained_models/hypersim/inference_outputs_r34_NBt1D/hypersim/{valid,test}/{inference_output_format}.
To change the output path, pass --inference-output-path to the script.
cd ${REPO_ROOT}/emsanet
WEIGHTS_FILEPATH=${REPO_ROOT}/trained_models/scannet/r34_NBt1D.pth
DATASET_PATH=${REPO_ROOT}/datasets/scannet
# first predict scannet outputs and then mapping outputs:
# - valid: 0.4GB + 0.5GB + 0.4GB + 510GB
# - test: 63MB + 52MB + 39MB + 217GB (no ground truth)
for SPLIT in "valid" "test"
do
for OUTPUT_FORMAT in "scannet-semantic scannet-instance scannet-panoptic" "mapping"
do
if [ "$OUTPUT_FORMAT" = "mapping" ]; then
# we use a subsample of 5 for mapping
SUBSAMPLE=5
SHIFT=$((2**16)) # does not matter for mapping
else
if [ "$SPLIT" = "valid" ]; then
# we use a subsample of 50 for back-projection and evaluation
SUBSAMPLE=50
SHIFT=$((2**16))
else
# ScanNet test split -> use parameters for submission
# -> use default benchmark subsample of 100
SUBSAMPLE=100
# -> use default benchmark semantic-instance shift of 1000
SHIFT=1000
fi
fi
python inference_dataset.py \
--dataset scannet \
--dataset-path ${DATASET_PATH} \
--scannet-semantic-n-classes 20 \
--use-original-scene-labels \
--tasks semantic scene instance orientation \
--enable-panoptic \
--no-pretrained-backbone \
--weights-filepath ${WEIGHTS_FILEPATH} \
--input-height 960 \
--input-width 1280 \
--instance-offset-distance-threshold 120 \
--inference-split ${SPLIT} \
--inference-scannet-subsample ${SUBSAMPLE} \
--inference-input-height 960 \
--inference-input-width 1280 \
--inference-output-format ${OUTPUT_FORMAT} \
--inference-batch-size 2 \
--inference-output-write-ground-truth \
--inference-output-semantic-instance-shift ${SHIFT}
done
doneBy default, the outputs are stored at: ${REPO_ROOT}/trained_models/scannet/inference_outputs_r34_NBt1D/scannet/{valid,test}/{inference_output_format}.
To change the output path, pass --inference-output-path to the script.
Note that the ground truth in the correct format was extracted along with the EMSANet predictions in the previous section.
cd ${REPO_ROOT}/evaluation/ScanNet/BenchmarkScripts/2d_evaluation
SPLIT="valid" # valid / test
PRED_BASEPATH=${REPO_ROOT}/trained_models/hypersim/inference_outputs_r34_NBt1D/hypersim/${SPLIT}
# 2D semantic task
python evalPixelLevelSemanticLabeling.py \
--dataset hypersim \
--gt_path ${PRED_BASEPATH}/scannet_semantic/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_semantic/pred_path_semantic \
--output_file ${PRED_BASEPATH}/scannet_semantic/evaluation.txt
# 2D semantic-instance task (instance)
rm ./gtInstances.json # remove cached instances if dataset or split changes
python evalInstanceLevelSemanticLabeling.py \
--dataset hypersim \
--shift $((2**16)) \
--gt_path ${PRED_BASEPATH}/scannet_instance/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_instance/pred_path_panoptic_instance \
--output_file ${PRED_BASEPATH}/scannet_instance/evaluation.txt
# 2D panoptic task
python evalPanopticLevelSemanticLabeling.py \
--dataset hypersim \
--shift $((2**16)) \
--gt_path ${PRED_BASEPATH}/scannet_panoptic/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_panoptic/pred_path \
--output_file ${PRED_BASEPATH}/scannet_panoptic/evaluation.jsonNote, we also use a semantic-instance shift of 2^16 for the ScanNet validation split in our pipeline. Only for the hidden test split, the default shift of 1000 is used.
cd ${REPO_ROOT}/evaluation/ScanNet/BenchmarkScripts/2d_evaluation
SPLIT="valid" # ground-truth annotations for test are not available (use official evaluation sever)
PRED_BASEPATH=${REPO_ROOT}/trained_models/scannet/inference_outputs_r34_NBt1D/scannet/${SPLIT}
# 2D semantic task
python evalPixelLevelSemanticLabeling.py \
--dataset scannet \
--gt_path ${PRED_BASEPATH}/scannet_semantic/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_semantic/pred_path_semantic \
--output_file ${PRED_BASEPATH}/scannet_semantic/evaluation.txt
# 2D semantic-instance task (instance)
rm ./gtInstances.json # remove cached instances if dataset or split changes
python evalInstanceLevelSemanticLabeling.py \
--dataset scannet \
--shift $((2**16)) \
--gt_path ${PRED_BASEPATH}/scannet_instance/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_instance/pred_path_panoptic_instance \
--output_file ${PRED_BASEPATH}/scannet_instance/evaluation.txt
# 2D panoptic task
python evalPanopticLevelSemanticLabeling.py \
--dataset scannet \
--shift $((2**16)) \
--gt_path ${PRED_BASEPATH}/scannet_panoptic/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_panoptic/pred_path \
--output_file ${PRED_BASEPATH}/scannet_panoptic/evaluation.jsonIn the ScanNet benchmark, evaluation in 3D is done by mapping created representations to annotated ground-truth representations. While ScanNet provides annotated meshes as ground truth, such ground-truth representations are missing for Hypersim. Therefore, we generated them ourselves for Hypersim.
Ground-truth point clouds for Hypersim are created by applying a voxel-grid filter with a voxel size of 1cm to the point cloud of each camera trajectory. The most frequent annotation is used to assign a ground-truth annotation to each voxel. We further limit the maximum distance to a reasonable value of 20m.
Use the nicr_sa_prepare_labeled_point_clouds entry point provided in our nicr-scene-analysis-datasets python package to create the 3D ground truth.
DATASET_PATH=${REPO_ROOT}/datasets/hypersim
OUTPUT_PATH=${REPO_ROOT}/datasets/hypersim_3d
# valid: 15GB, test: 15GB
for SPLIT in "valid" "test"
do
nicr_sa_prepare_labeled_point_clouds \
hypersim \
${DATASET_PATH} \
${OUTPUT_PATH} \
--split ${SPLIT} \
--voxel-size 0.01 \
--max-depth 20 \
--write-scannet-benchmark-ground-truth
doneYou can use the nicr_sa_labeled_pc_viewer entry point in our
nicr-scene-analysis-datasets python package to browse the generated ground-truth data.
Note that the point clouds already contain RGB and label information.
However, the viewer can also be used to visualize mapped predictions.
See the --semantic-label-filepath and --panoptic-label-filepath arguments in the example below. Replace the given ground-truth files with our predicted files to visualize results.
# e.g., valid/ai_003_010/cam_00
nicr_sa_labeled_pc_viewer \
${OUTPUT_PATH}/valid/ply/ai_003_010/cam_00/voxel_0_01_maxdepth_20_0.ply \
--semantic-colormap nyuv2_40 \
--instance-colormap visual_distinct \
--semantic-label-filepath ${OUTPUT_PATH}/valid/scannet_benchmark_gt/semantic/ai_003_010_cam_00.txt \
--panoptic-label-filepath ${OUTPUT_PATH}/valid/scannet_benchmark_gt/semantic_instance/ai_003_010_cam_00.txt \
--use-panoptic-labels-as-instance-labels \
--enumerate-instancesFor ScanNet, we provide a script that automates 3D ground-truth generation and copies the existing ply files to the same folder structure as for Hypersim.
cd ${REPO_ROOT}/evaluation/ScanNet/BenchmarkScripts/3d_helpers
DATASET_PATH=${REPO_ROOT}/datasets/scannet
OUTPUT_PATH=${REPO_ROOT}/datasets/scannet_3d
SPLIT_FILES_PATH=`python -c 'import os; from nicr_scene_analysis_datasets.datasets import scannet; print(os.path.dirname(scannet.__file__))'`
# valid: 2.3GB, test: 0.7GB (no ground truth)
for SPLIT in "valid" "test"
do
python extract_scannet_ground_truth.py \
${SCANNET_DOWNLOAD_PATH} \
${SPLIT_FILES_PATH} \
${SCANNET_DOWNLOAD_PATH}/scannetv2-labels.combined.tsv \
${OUTPUT_PATH} \
--split ${SPLIT} \
--shift $((2**16))
doneYou can use the nicr_sa_labeled_pc_viewer entry point in our
nicr-scene-analysis-datasets python package to browse the generated ground-truth data.
Note that the original ScanNet point clouds only contain RGB information.
The viewer can be used to further visualize labels and mapped predictions.
See the --semantic-label-filepath and --panoptic-label-filepath arguments in the example below. Replace the given ground-truth files with our predicted files to visualize results.
# e.g., valid/scene0019_00
nicr_sa_labeled_pc_viewer \
${OUTPUT_PATH}/valid/ply/scene0019_00/scene0019_00_vh_clean_2.ply \
--semantic-colormap nyuv2_40 \
--instance-colormap visual_distinct \
--semantic-label-filepath ${OUTPUT_PATH}/valid/scannet_benchmark_gt/semantic/scene0019_00.txt \
--panoptic-label-filepath ${OUTPUT_PATH}/valid/scannet_benchmark_gt/semantic_instance/scene0019_00.txt \
--use-panoptic-labels-as-instance-labels \
--enumerate-instancesOur panoptic mapping approach is implemented using the middleware for robotic applications (MIRA). However, integrating our pipeline for data processing in ROS workflows is straightforward. We refer to the dataset reader classes in our nicr-scene-analysis-datasets python package.
Once mapping is done, store the results in the following format and folder structure:
2D (i.e., for back-projections):
- 2D semantic task: create prediction files similar to EMSANet predictions in
${REPO_ROOT}/trained_models/{hypersim,scannet}/inference_outputs_r34_NBt1D/{hypersim,scannet}/{valid,test}/scannet_semantic/pred_path_semantic(see section Extract 2D ground truth and EMSANet predictions for evaluation / mapping) - 2D semantic instance task: create prediction files similar to EMSANet predictions in
${REPO_ROOT}/trained_models/{hypersim,scannet}/inference_outputs_r34_NBt1D/{hypersim,scannet}/{valid,test}/scannet_instance/pred_path_panoptic_instance(see section Extract 2D ground truth and EMSANet predictions for evaluation / mapping) - 2D panoptic task: create prediction files similar to EMSANet predictions in
${REPO_ROOT}/trained_models/{hypersim,scannet}/inference_outputs_r34_NBt1D/{hypersim,scannet}/{valid,test}/scannet_panoptic/pred_path(see section Extract 2D ground truth and EMSANet predictions for evaluation / mapping)
3D:
- 3D semantic task: create prediction files similar to the ground-truth files in
${REPO_ROOT}/datasets/{hypersim_3d,scannet_3d}/{valid,test}/scannet_benchmark_gt/semanticfolder (see section Extract 3D ground truth) - 3D semantic instance task: create prediction files as described for the original ScanNet 3D Semantic Instance Prediction task
- 3D panoptic task: create prediction files similar to the ground-truth files in
${REPO_ROOT}/datasets/{hypersim_3d,scannet_3d}/{valid,test}/scannet_benchmark_gt/semantic_instancefolder (see section Extract 3D ground truth)
Note that the ground truth in the correct format was extracted along with the EMSANet predictions in section Extract 2D ground truth and EMSANet predictions for evaluation / mapping.
cd ${REPO_ROOT}/evaluation/ScanNet/BenchmarkScripts/2d_evaluation
DATASET="hypersim" # hypersim / scannet
SPLIT="valid" # valid / test for hypersim, test for scannet
GT_BASEPATH=${REPO_ROOT}/trained_models/${DATASET}/inference_outputs_r34_NBt1D/${DATASET}/${SPLIT}
PRED_BASEPATH="/path/to/your/2d_results"
# 2D semantic task
python evalPixelLevelSemanticLabeling.py \
--dataset ${DATASET} \
--gt_path ${GT_BASEPATH}/scannet_semantic/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_semantic/pred_path \
--output_file ${PRED_BASEPATH}/scannet_semantic/evaluation.txt
# 2D semantic-instance task (instance)
rm ./gtInstances.json # remove cached instances if dataset or split changes
python evalInstanceLevelSemanticLabeling.py \
--dataset ${DATASET} \
--shift $((2**16)) \
--gt_path ${GT_BASEPATH}/scannet_instance/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_instance/pred_path \
--output_file ${PREDICTION_PATH}/scannet_instance/evaluation.txt
# 2D panoptic task
python evalPanopticLevelSemanticLabeling.py \
--dataset ${DATASET} \
--shift $((2**16)) \
--gt_path ${GT_BASEPATH}/scannet_panoptic/gt_path \
--pred_path ${PRED_BASEPATH}/scannet_panoptic/pred_path \
--output_file ${PRED_BASEPATH}/scannet_panoptic/evaluation.jsonNote that 3D evaluation in the ScanNet benchmark is done by comparing *.txt files containing the labels assigned to each point of the ground-truth representation.
Therefore, it is important that prediction and ground truth are aligned.
An easy way to double-check this is to visualize the prediction over the ground-truth representation using our nicr_sa_labeled_pc_viewer entry point (see instructions in section Extract 3D ground truth).
cd ${REPO_ROOT}/evaluation/ScanNet/BenchmarkScripts/3d_evaluation
DATASET="hypersim" # hypersim / scannet
SPLIT="valid" # valid / test for hypersim, test for scannet
GT_BASEPATH=${REPO_ROOT}/datasets/${DATASET}_3d/${SPLIT}/scannet_benchmark_gt
PRED_BASEPATH="/path/to/your/3d_results"
# 3D semantic task - might be quite slow for hypersim
python evaluate_semantic_label.py \
--dataset ${DATASET} \
--pred_path ${PRED_BASEPATH}/semantic \
--gt_path ${GT_BASEPATH}/semantic \
--output_file ${PRED_BASEPATH}/evaluation_semantic.txt
# 3D semantic-instance task (instance) - might be quite slow for hypersim
python evaluate_semantic_instance.py \
--dataset ${DATASET} \
--shift $((2**16)) \
--pred_path ${PRED_BASEPATH}/semantic_instance \
--gt_path ${GT_BASEPATH}/semantic_instance \
--output_file ${PRED_BASEPATH}/evaluation_semantic_instance.txt
# 3D panoptic task - much faster than the other two benchmarks
python evaluate_panoptic.py \
--dataset ${DATASET} \
--shift $((2**16)) \
--pred_path ${PRED_BASEPATH}/panoptic \
--gt_path ${GT_BASEPATH}/semantic_instance \
--output_file ${PRED_BASEPATH}/evaluation_panoptic.jsonJun 29, 2024
- update EMSANet submodule to latest version:
- with
lib/nicr-scene-analysis-datasetsv0.7.0 - with
lib/nicr-multitask-scene-analysisv0.2.3 - there is no need anymore to use a specific branch in EMSANet repository
- with
- add more recent environment file (Python 3.11.0, PyTorch 2.3, Open3D 0.18.0)
- small fix in proposed
ScanNet/BenchmarkScripts/2d_evaluation/evalPanopticLevelSemanticLabeling.py - update ScanNet patch file to fix some NumPy issues in the original evaluation
script:
ScanNet/BenchmarkScripts/2d_evaluation/evalInstanceLevelSemanticLabeling.py - some other minor fixes
- update paper on arXiv:
- fixed small issue in Eq. 5: order was not respected
- fixed small issue in Eq. 10: second branch was limted to stuff classes only
- fixed noted CPU name in tables: Intel i7-1165G7 to Intel i7-1165G7
- some other minor fixes (appendix only)
Sep 26, 2023
- initial public release