

Worker is a simple HTTP server that accepts FQL (Ferret Query Language) queries, executes them and returns their results.
Ferret is a declarative web scraping query language that allows you to extract data from web pages using a SQL-like syntax. Worker provides a REST API interface to execute FQL queries remotely, making it easy to integrate web scraping capabilities into your applications.
Common use cases:
- Web scraping and data extraction from websites
- Automated testing of web applications
- Monitoring web pages for changes
- Generating PDFs or screenshots from web pages
- Collecting data for analytics and research
OpenAPI v2 schema can be found here.
- Docker (recommended) or Go 1.23+ for local installation
- For local installation without Docker: Google Chrome or Chromium browser
The Worker is shipped with dedicated Docker image that contains headless Google Chrome, so feel free to run queries using cdp driver:
DockerHub:
docker run -d -p 8080:8080 montferret/workerGitHub Container Registry:
docker run -d -p 8080:8080 ghcr.io/montferret/workerAlternatively, if you want to use your own version of Chrome, you can run the Worker locally.
Install from script:
curl https://raw.githubusercontent.com/MontFerret/worker/master/install.sh | sh
workerBuild from source:
git clone https://github.com/MontFerret/worker.git
cd worker
makeOnce the Worker is running, you can send FQL queries via POST requests to http://localhost:8080/:
Simple data extraction:
curl -X POST http://localhost:8080/ \
-H "Content-Type: application/json" \
-d '{
"text": "LET doc = DOCUMENT(\"https://example.com\") RETURN doc.title"
}'Web scraping with browser automation:
curl -X POST http://localhost:8080/ \
-H "Content-Type: application/json" \
-d '{
"text": "LET page = DOCUMENT(\"https://github.com\", { driver: \"cdp\" }) WAIT_ELEMENT(page, \"h1\") RETURN INNER_TEXT(page, \"h1\")"
}'Query with parameters:
curl -X POST http://localhost:8080/ \
-H "Content-Type: application/json" \
-d '{
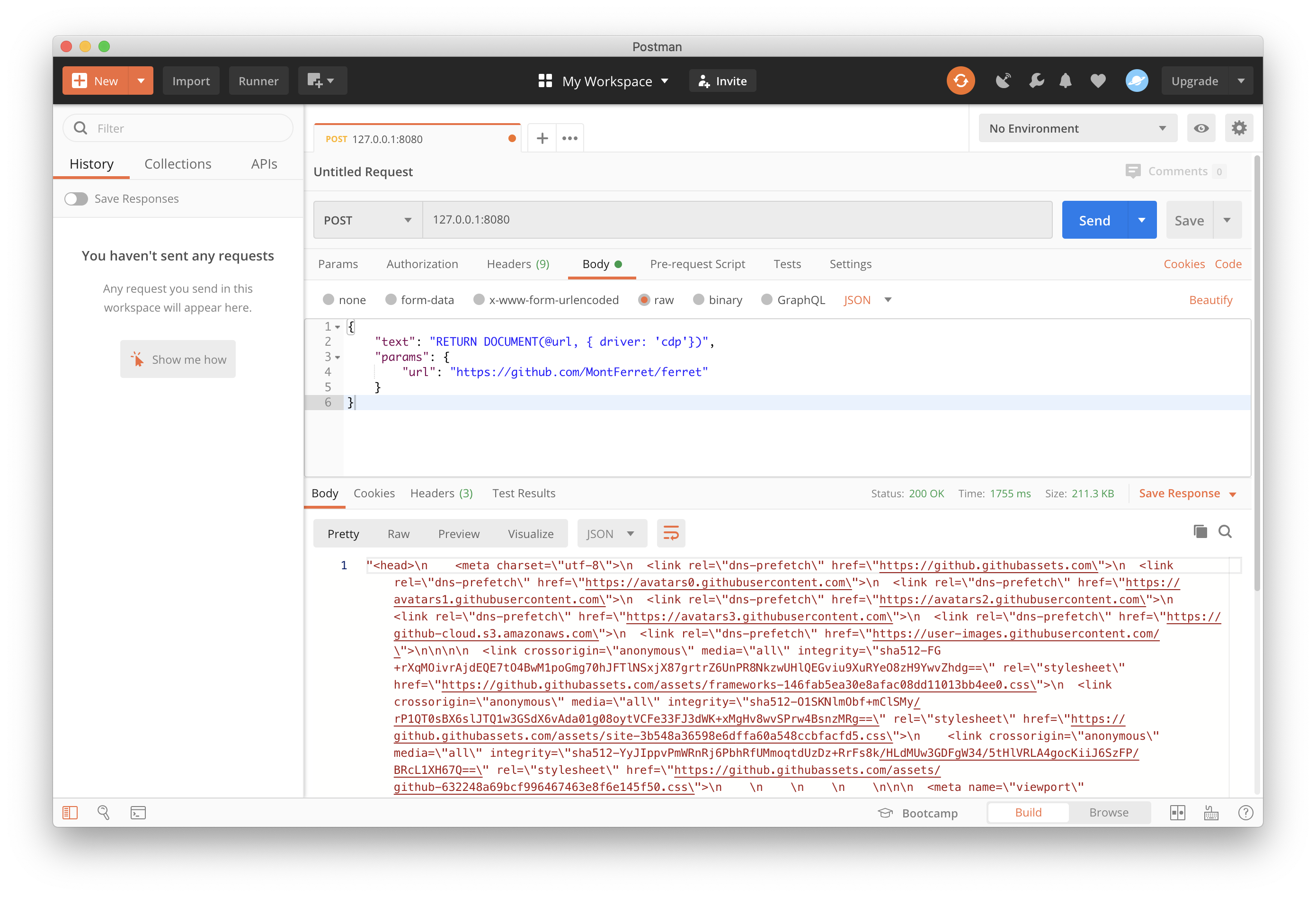
"text": "LET doc = DOCUMENT(@url) RETURN doc.title",
"params": {
"url": "https://example.com"
}
}'
- 2 CPU
- 2 Gb of RAM
Executes a given FQL query. The payload must have the following shape:
{
"text": "LET doc = DOCUMENT('https://example.com') RETURN doc.title",
"params": {
"optional_param": "value"
}
}Request body:
text(string, required): The FQL query to executeparams(object, optional): Parameters to pass to the query (accessible via@param_name)
Response:
{
"data": "Example Domain",
"stats": {
"execution_time": "1.234s"
}
}Example with complex data extraction:
curl -X POST http://localhost:8080/ \
-H "Content-Type: application/json" \
-d '{
"text": "LET page = DOCUMENT(@url, { driver: \"cdp\" }) LET links = ELEMENTS(page, \"a\") RETURN links[* LIMIT 5].href",
"params": {
"url": "https://news.ycombinator.com"
}
}'Returns worker information including Chrome, Ferret and worker versions:
{
"ip": "127.0.0.1",
"version": {
"worker": "1.18.0",
"chrome": {
"browser": "125.0.6422.141",
"protocol": "1.3",
"v8": "12.5.227.39",
"webkit": "537.36"
},
"ferret": "0.18.1"
}
}Health check endpoint that returns HTTP 200 when the service is healthy and all dependencies (like Chrome) are accessible. Returns HTTP 424 when dependencies are unavailable.
Healthy response:
HTTP/1.1 200 OK
Unhealthy response:
HTTP/1.1 424 Failed Dependency
-log-level="debug"
log level (trace, debug, info, warn, error, fatal, panic)
-port=8080
port to listen
-body-limit=1000
maximum size of request body in kb. 0 means no limit.
-request-limit=0
amount of requests per second for each IP. 0 means no limit.
-request-limit-time-window=180
amount of seconds for request rate limit time window.
-cache-size=100
amount of cached queries. 0 means no caching.
-chrome-ip="127.0.0.1"
Google Chrome remote IP address
-chrome-port=9222
Google Chrome remote debugging port
-no-chrome=false
disable Chrome driver
-version=false
show version
-help=false
show this listProduction deployment with rate limiting:
worker \
-port=8080 \
-log-level=info \
-request-limit=10 \
-request-limit-time-window=60 \
-body-limit=2000 \
-cache-size=500Development with debugging:
worker \
-port=3000 \
-log-level=debug \
-cache-size=0Using external Chrome instance:
# Start Chrome with remote debugging
google-chrome --headless --remote-debugging-port=9222 &
# Start worker pointing to external Chrome
worker -chrome-ip=localhost -chrome-port=9222Without Chrome (HTTP driver only):
worker -no-chrome=trueCustom port and configuration:
docker run -d \
-p 3000:3000 \
-e PORT=3000 \
montferret/worker \
worker -port=3000 -log-level=infoWith volume for persistent cache:
docker run -d \
-p 8080:8080 \
-v /host/cache:/app/cache \
montferret/worker- Rate Limiting: Always enable rate limiting in production (
-request-limit) - Body Size Limits: Set appropriate body size limits (
-body-limit) to prevent abuse - Network Security: Worker should not be exposed directly to the internet without proper authentication
- Query Validation: Consider implementing query validation/filtering for untrusted input
- Resource Monitoring: Monitor CPU and memory usage as complex queries can be resource-intensive
- Chrome Security: The bundled Chrome runs in sandboxed mode, but avoid running as root in production
Recommended production configuration:
worker \
-port=8080 \
-log-level=warn \
-request-limit=5 \
-request-limit-time-window=60 \
-body-limit=1000 \
-cache-size=200Chrome connection failed:
Error: failed to connect to Chrome
- Ensure Chrome is running with
--remote-debugging-port=9222 - Check if Chrome is accessible at the configured IP/port
- For Docker: make sure Chrome service is healthy
Query timeout:
Error: query execution timeout
- Complex pages may take longer to load
- Consider adding explicit waits in your FQL query
- Check network connectivity to target websites
Memory issues:
Error: out of memory
- Reduce cache size (
-cache-size) - Limit concurrent requests (
-request-limit) - Monitor Chrome memory usage
Permission denied:
Error: permission denied accessing Chrome
- Ensure proper user permissions for Chrome binary
- In Docker, avoid running as root when possible
Enable debug logging to troubleshoot issues:
worker -log-level=debugMonitor worker health:
curl http://localhost:8080/health
curl http://localhost:8080/info// Extract page title
LET doc = DOCUMENT("https://example.com")
RETURN doc.title
// Get all links
LET doc = DOCUMENT("https://example.com")
LET links = ELEMENTS(doc, "a")
RETURN links[*].href
// Extract structured data
LET doc = DOCUMENT("https://news.ycombinator.com")
LET stories = ELEMENTS(doc, ".titleline > a")
RETURN stories[* LIMIT 10].{
title: INNER_TEXT(@),
url: @.href
}// Navigate and interact with page
LET page = DOCUMENT("https://github.com", { driver: "cdp" })
WAIT_ELEMENT(page, "input[name='q']")
INPUT(page, "input[name='q']", "ferret")
CLICK(page, "button[type='submit']")
WAIT_ELEMENT(page, ".repo-list-item")
RETURN ELEMENTS(page, ".repo-list-item h3 a")[*].{
name: INNER_TEXT(@),
url: @.href
}
// Take screenshot
LET page = DOCUMENT("https://example.com", { driver: "cdp" })
RETURN PDF(page)// Query with parameters (pass via "params" in POST body)
LET page = DOCUMENT(@url, { driver: "cdp" })
LET selector = @css_selector
RETURN ELEMENTS(page, selector)[*].{
text: INNER_TEXT(@),
href: @.href
}# Clone repository
git clone https://github.com/MontFerret/worker.git
cd worker
# Install dependencies
make install
# Build
make build
# Run tests
make test
# Start development server
make start- Fork the repository
- Create a feature branch:
git checkout -b my-feature - Make your changes
- Run tests:
make test - Run linter:
make lint - Commit changes:
git commit -am 'Add some feature' - Push to the branch:
git push origin my-feature - Submit a pull request
├── cmd/ # Command-line interface
├── internal/ # Internal application code
│ ├── controllers/ # HTTP request handlers
│ ├── server/ # HTTP server configuration
│ └── storage/ # Caching layer
├── pkg/ # Public packages
│ ├── caching/ # Cache implementation
│ └── worker/ # Core worker logic
├── reference/ # OpenAPI specification
└── assets/ # Documentation assets