






Documentation | Examples | Tutorials | Contributing | Releases | Developers Board
RecTools is an easy-to-use Python library which makes the process of building recommendation systems easier, faster and more structured than ever before. It includes built-in toolkits for data processing and metrics calculation, a variety of recommender models, some wrappers for already existing implementations of popular algorithms and model selection framework. The aim is to collect ready-to-use solutions and best practices in one place to make processes of creating your first MVP and deploying model to production as fast and easy as possible.
Prepare data with
wget https://files.grouplens.org/datasets/movielens/ml-1m.zip
unzip ml-1m.zipimport pandas as pd
from implicit.nearest_neighbours import TFIDFRecommender
from rectools import Columns
from rectools.dataset import Dataset
from rectools.models import ImplicitItemKNNWrapperModel
# Read the data
ratings = pd.read_csv(
"ml-1m/ratings.dat",
sep="::",
engine="python", # Because of 2-chars separators
header=None,
names=[Columns.User, Columns.Item, Columns.Weight, Columns.Datetime],
)
# Create dataset
dataset = Dataset.construct(ratings)
# Fit model
model = ImplicitItemKNNWrapperModel(TFIDFRecommender(K=10))
model.fit(dataset)
# Make recommendations
recos = model.recommend(
users=ratings[Columns.User].unique(),
dataset=dataset,
k=10,
filter_viewed=True,
)RecTools is on PyPI, so you can use pip to install it.
pip install rectools
The default version doesn't contain all the dependencies, because some of them are needed only for specific functionality. Available user extensions are the following:
lightfm: adds wrapper for LightFM model,torch: adds models based on neural nets,visuals: adds visualization tools,nmslib: adds fast ANN recommenders.
Install extension:
pip install rectools[extension-name]
Install all extensions:
pip install rectools[all]
The table below lists recommender models that are available in RecTools.
See recommender baselines extended tutorial for deep dive into theory & practice of our supported models.
| Model | Type | Description (🎏 for user/item features, 🔆 for warm inference, ❄️ for cold inference support) | Tutorials & Benchmarks |
|---|---|---|---|
| implicit ALS Wrapper | Matrix Factorization | rectools.models.ImplicitALSWrapperModel - Alternating Least Squares Matrix Factorizattion algorithm for implicit feedback. 🎏 |
📙 Theory & Practice 🚀 50% boost to metrics with user & item features |
| implicit ItemKNN Wrapper | Nearest Neighbours | rectools.models.ImplicitItemKNNWrapperModel - Algorithm that calculates item-item similarity matrix using distances between item vectors in user-item interactions matrix |
📙 Theory & Practice |
| LightFM Wrapper | Matrix Factorization | rectools.models.LightFMWrapperModel - Hybrid matrix factorization algorithm which utilises user and item features and supports a variety of losses.🎏 🔆 ❄️ |
📙 Theory & Practice 🚀 10-25 times faster inference with RecTools |
| EASE | Linear Autoencoder | rectools.models.EASEModel - Embarassingly Shallow Autoencoders implementation that explicitly calculates dense item-item similarity matrix |
📙 Theory & Practice |
| PureSVD | Matrix Factorization | rectools.models.PureSVDModel - Truncated Singular Value Decomposition of user-item interactions matrix |
📙 Theory & Practice |
| DSSM | Neural Network | rectools.models.DSSMModel - Two-tower Neural model that learns user and item embeddings utilising their explicit features and learning on triplet loss.🎏 🔆 |
- |
| Popular | Heuristic | rectools.models.PopularModel - Classic baseline which computes popularity of items and also accepts params like time window and type of popularity computation.❄️ |
- |
| Popular in Category | Heuristic | rectools.models.PopularInCategoryModel - Model that computes poularity within category and applies mixing strategy to increase Diversity.❄️ |
- |
| Random | Heuristic | rectools.models.RandomModel - Simple random algorithm useful to benchmark Novelty, Coverage, etc.❄️ |
- |
- All of the models follow the same interface. No exceptions
- No need for manual creation of sparse matrixes or mapping ids. Preparing data for models is as simple as
dataset = Dataset.construct(interactions_df) - Fitting any model is as simple as
model.fit(dataset) - For getting recommendations
filter_viewedanditems_to_recommendoptions are available - For item-to-item recommendations use
recommend_to_itemsmethod - For feeding user/item features to model just specify dataframes when constructing
Dataset. Check our tutorial - For warm / cold inference just provide all required ids in
usersortarget_itemsparameters ofrecommendorrecommend_to_itemsmethods and make sure you have features in the dataset for warm users/items. Nothing else is needed, everything works out of the box.

Example | Demo | Documentation
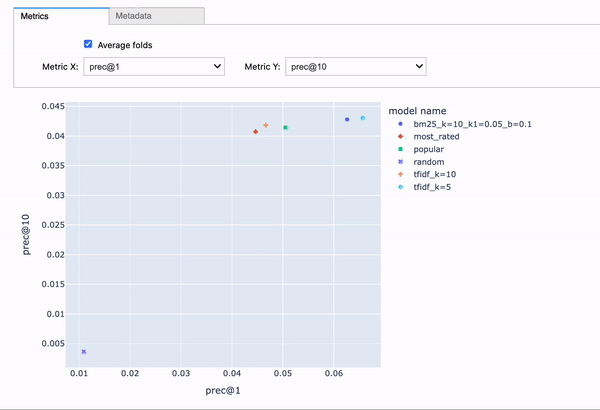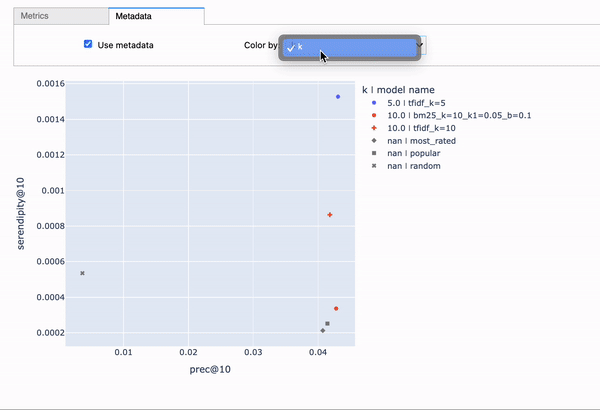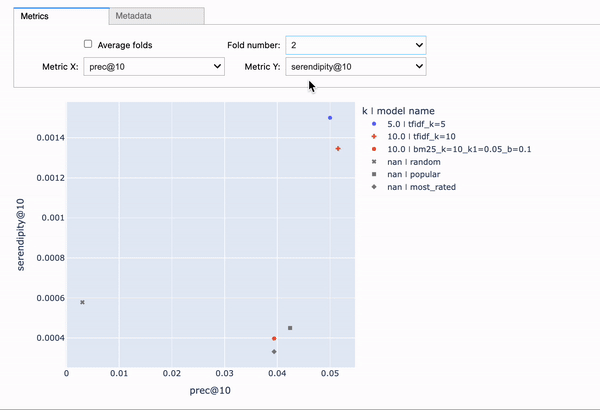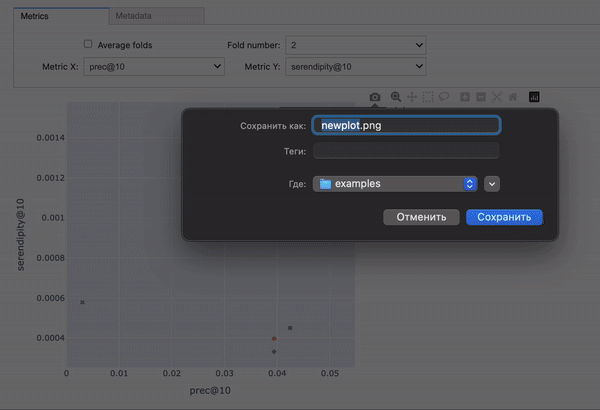
To install all requirements
- you must have
python>=3.8andpoetry>=1.5.0installed - make sure you have no active virtual environments (deactivate conda
baseif applicable) - run
make install
For autoformatting run
make format
For linters check run
make lint
For tests run
make test
For coverage run
make coverage
To remove virtual environment run
make clean
- Emiliy Feldman [Maintainer]
- Daria Tikhonovich [Maintainer]
- Alexander Butenko
- Andrey Semenov
- Mike Sokolov
- Maya Spirina
- Grigoriy Gusarov
Previous contributors: Ildar Safilo [ex-Maintainer], Daniil Potapov [ex-Maintainer], Igor Belkov, Artem Senin, Mikhail Khasykov, Julia Karamnova, Maxim Lukin, Yuri Ulianov, Egor Kratkov, Azat Sibagatulin