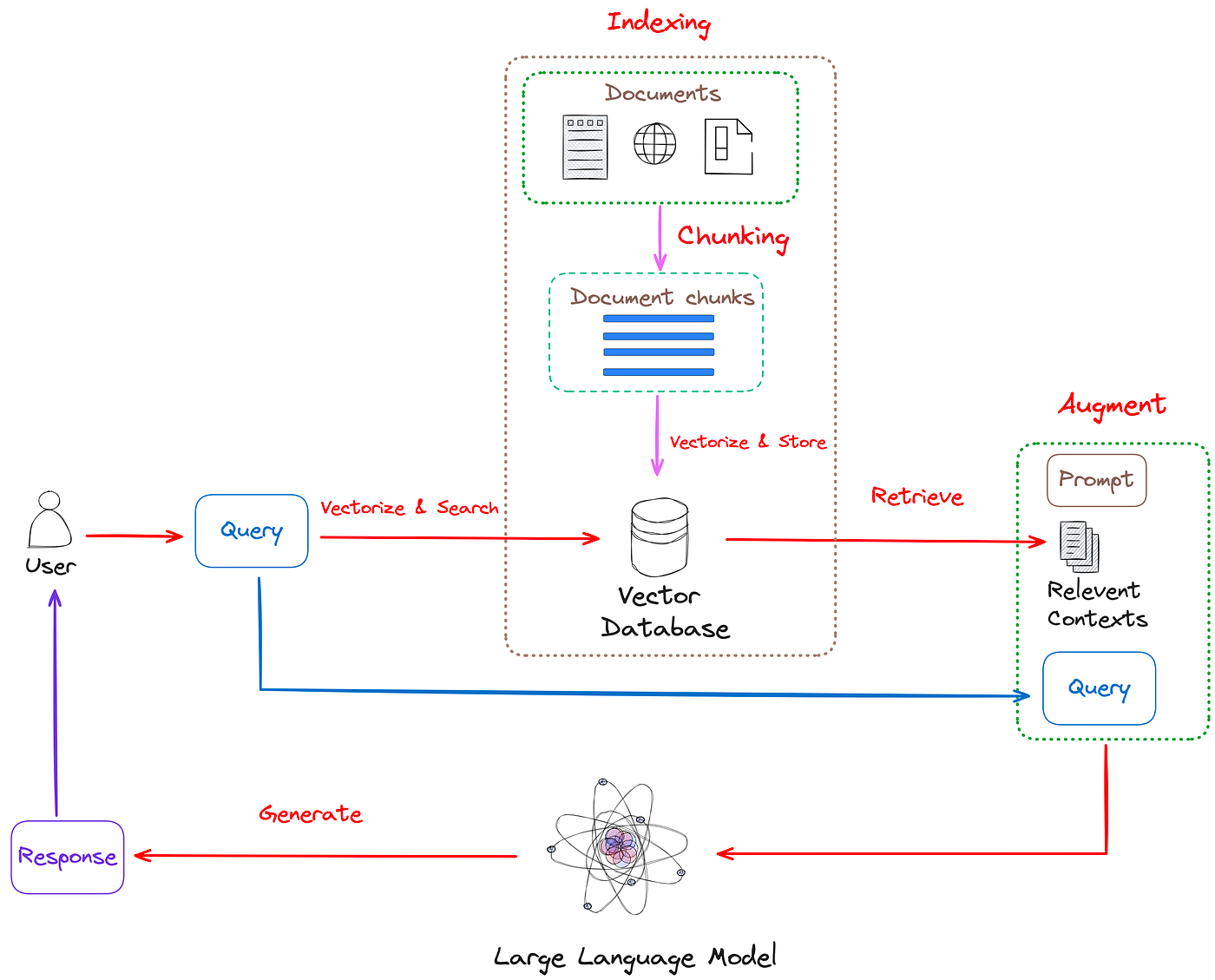
The goal of this project is to create a system for refining Large Language Models (LLMs) using Retrieval-Augmented Generation (RAG). It implements a design assistant that leverages GPT-4 and ElasticSearch to provide contextually relevant design advice.
- OpenAI API key
- ElasticSearch instance
- Kibana
- Python 3.8+
- Clone the repository:
git clone https://github.com/MaxRondelli/Refining-a-LLM-using-RAG.git
cd Refining-a-LLM-using-RAG- Install required dependencies:
pip install -r requirements.txt- Create a
.envfile in the root directory with your credentials:
OPENAI_API_KEY=your_openai_api_key
ELASTIC_HOST=your_elasticsearch_host
CA_CERTS_PATH=ca_certs_path
ELASTIC_USERNAME=your_username
ELASTIC_PWD=your_passwordwebapp.py: Streamlit-based user interface and chat logicmain.py: Core functionality for document retrieval and prompt generationindexer.py: Document processing and embedding generationelastic.py: ElasticSearch database configuration and operations
The system processes PDF documents through the following steps:
- Splits documents into manageable chunks.
- Generates embeddings for each chunk using OpenAI's embedding model.
- Stores the embeddings and text in ElasticSearch.
When a user submits a query:
- The system generates an embedding for the query.
- Searches for the 3 most relevant document chunks using k-NN search.
- Creates a prompt template combining the query and relevant context.
The system:
- Maintains conversation history for context.
- Uses GPT-4 to generate responses based on retrieved documents.
- Presents responses through a user-friendly interface.
- Create the vector database running the
python3 elastic.pyBe sure the docker with elastic and kibare are on.
- Index the new documents with
python3 indexer.py- Start the web application with
streamlit run webapp.pyThe project has been developed between me and Alessandro Borrelli.
Contributions are welcome! Feel free to submit PRs.