

Context-Based Question Answering is an easy-to-use Extractive QA search engine, which extracts answers to the question based on the provided context.

- Introduction
- Motivation
- Technologies
- Languages
- Installation
- Demo
- Features
- Status
- License
- Credits
- Citations
- Community Contribution
- Contact
Question answering (QA) is a computer science discipline within the fields of information retrieval and natural language processing (NLP), which is concerned with building systems that automatically answer questions posed by humans in a natural language.
Source: Wikipedia
Extractive QA is a popular task for natural language processing (NLP) research, where models must extract a short snippet from a document in order to answer a natural language question.
Source: Facebook AI
Context-Based Question Answering (CBQA) is an inference web-based Extractive QA search engine, mainly dependent on Haystack and Transformers library.
The CBQA application allows the user to add context and perform Question Answering(QA) in that context.
The main components in this application use Haystack's core components,
- FileConverter: Extracts pure text from files (pdf, docx, pptx, html and many more).
- PreProcessor: Cleans and splits texts into smaller chunks.
- DocumentStore: Database storing the documents, metadata and vectors for our search. We recommend Elasticsearch or FAISS, but have also more light-weight options for fast prototyping (SQL or In-Memory).
- Retriever: Fast algorithms that identify candidate documents for a given query from a large collection of documents. Retrievers narrow down the search space significantly and are therefore key for scalable QA. Haystack supports sparse methods (TF-IDF, BM25, custom Elasticsearch queries) and state of the art dense methods (e.g. sentence-transformers and Dense Passage Retrieval)
- Reader: Neural network (e.g. BERT or RoBERTA) that reads through texts in detail to find an answer. The Reader takes multiple passages of text as input and returns top-n answers. Models are trained via FARM or Transformers on SQuAD like tasks. You can just load a pretrained model from Hugging Face's model hub or fine-tune it on your own domain data.
Source: Haystack's Key Components docs
In CBQA the allowed formats for adding the context are,
- Textual Context (Using the TextBox field)
- File Uploads (.pdf, .txt, and .docx)
These contexts are uploaded to a temporary directory for each user for pre-processing and deletes after uploading them to Elasticsearch, which is the only DocumentStore type used in this system.
Each user has a separate Elasticsearch index to store the context documents. Using the PreProcessor and the FileConverter modules from Haystack, the pre-processing and the extraction of text from context files is done.
Elasticsearcher Retriever is used in CBQA to retrieve relevant documents based on the search query.
Transformers-based Readers are used to extracting answers from the retrieved documents. The Readers used in CBQA are the pre-trained Transformers models hosted on the Hugging Face's model hub .
Currently, CBQA provides the interface to perform QA in English and French, using four Transformers based models,
- BERT
- RoBERTa
- DistilBERT
- CamemBERT
The interface provides an option to choose the inference device between CPU and GPU.
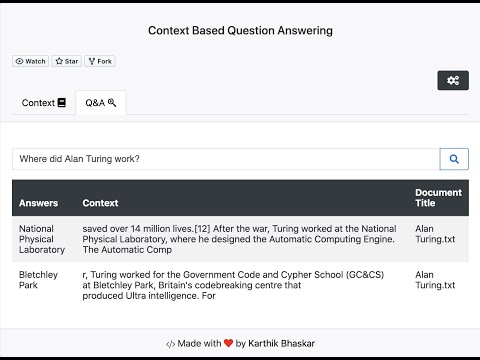
The output is in a tabular form containing the following headers,
- Answers (Extracted answers based on the question and context)
- Context (Specifies the context window, related to the answer)
- Document Title (Specifies the title of context file, related to the answer)
The motivation to implement the CBQA project is to make an easy-to-use interface to perform Question Answering (QA) in multiple languages, with the option for using different pre-trained models. Also, to enable organizations to use this project locally with minimal modifications or none.
- Python (version 3.7)
- Haystack (version 0.7.0)
- Transformers (version 4.3.1)
- Elasticsearch (version 7.10)
- Flask (version 1.1.2)
- Gunicorn (version 20.0.4)
- Bootstrap (version 4.5.3)
- jQuery (version 3.5.1)
- HTML, CSS, and JavaScript
- Docker
en: English
fr: French
Before starting the installation, clone this repository using the following commands in the terminal.
$ git clone https://github.com/Karthik-Bhaskar/Context-Based-Question-Answering.git$ cd Context-Based-Question-Answering/You can get started using one of the two options,
The main dependencies required to run the CBQA application is in the requirements.txt
To install the dependencies,
- Create a Python virtual environment with Python version 3.7 and activate it
- Install dependency libraries using the following command in the terminal.
$ pip install -r requirements.txtBefore executing the CBQA application, please start the Elasticsearch server. Elasticsearch is the DocumentStore type used in this application. To download and install the Elasticsearch, please check here.
In case you are using the docker environment, run Elasticsearch on docker using the following commands in the terminal. If you want to install the docker engine on your machine, please check here.
$ docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.0$ docker run -p 9200:9200 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.0Make sure the Elasticsearch server is running using the following command in the new terminal.
$ curl http://localhost:9200You should get a response like the one below.
{
"name" : "facddac422e8",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "a4A3-yBhQdKBlpSDkpRelg",
"version" : {
"number" : "7.10.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "51e9d6f22758d0374a0f3f5c6e8f3a7997850f96",
"build_date" : "2020-11-09T21:30:33.964949Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}After installing the dependency libraries and starting the Elasticsearch server, you are good to go.
-
To run the application using a WSGI server like Gunicorn. Use the following command in the new terminal.
$ gunicorn -w 1 --threads 4 app:appThis runs the application in Gunicorn server on http://localhost:8000 with a single worker and 4 threads.
-
To run the application in the flask development server (Not recommended using this in production). Use the following command in the new terminal.
$ python app.pyNow the application will be running in the flask development server on http://localhost/5000.
In the application execution cases above, you should see the below statement (date and time will be different) in the terminal after the application has started.
User tracker thread started @ 2021-03-04 18:25:20.803277The above statement means that the thread handling the user connection has started, and the application is ready to accept users.
Note: When performing QA using pre-trained models, at first use, the selected model gets downloaded from the Hugging Face's model hub this may take a while depending on your internet speed. If you are re-starting the application while you are testing, make sure to remove the auto-created temporary user directories in the project and the user index on Elasticsearch (Will be fixed soon)
To install the docker engine on your machine, please check here.
This project includes the docker-compose.yml file describing the services to get started quickly. The specified services in the file are Elasticsearch, Kibana, and the CBQA application.
Note: Make sure to increase the resources (Memory) in your docker engine in case you are facing 137 exit code (out of memory).
The docker image for the CBQA application has already been built and hosted on the docker hub.
To start the complete package that includes Elasticsearch, Kibana, and CBQA application as a docker container.
Use the following command in the terminal from the root of this project directory to start the container.
$ docker-compose up
Please wait until all the services have started after pulling the images.
Make sure the Elasticsearch server is running using the following command in the new terminal.
$ curl http://localhost:9200You should get a response like the one below.
{
"name" : "facddac422e8",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "a4A3-yBhQdKBlpSDkpRelg",
"version" : {
"number" : "7.10.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "51e9d6f22758d0374a0f3f5c6e8f3a7997850f96",
"build_date" : "2020-11-09T21:30:33.964949Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}The CBQA application service in the docker container runs on http://localhost:5000, the container name of the application will be web-app.
Elasticsearch service will be running on http://localhost:9200, and Kibana service will be running on http://localhost:5601.
Note: When performing QA using pre-trained models, at first use, the selected model gets downloaded from the Hugging Face's model hub this may take a while depending on your internet speed. If you are re-starting the application while you are testing, make sure to remove the auto-created temporary user directories in the project and the user index on Elasticsearch (Will be fixed soon)
To stop the container, use the following command in the new terminal.
$ docker-compose downFull demo video on YouTube.
Ready:
- Easy to use UI to perform QA
- Pre-trained models selection
- QA Language support (English and French)
- Simultaneous user handling support (While using WSGI server)
Future development:
- Ability to plugin large scale document corpus for the QA engine
- Generative QA support
- Additional QA Language support
- Improvising UI
- Haystack (deepset)
- Transformers (Hugging Face)
- Pre-trained Transformers Models on Hugging Face's model hub
- roberta-base-squad2 (deepset)
- bert-large-uncased-whole-word-masking-squad2(deepset)
- distilbert-base-cased-distilled-squad
- camembert-base-fquad (illuin)
- Elasticsearch and Kibana
- Flask
- Gunicorn
- Bootstrap
- DropzoneJS
- Docker
- Sanjay R Kamath, PhD (Research Scientist, NLP)
- Open-Source Community ❤️
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-1907-11692,
author = {Yinhan Liu and
Myle Ott and
Naman Goyal and
Jingfei Du and
Mandar Joshi and
Danqi Chen and
Omer Levy and
Mike Lewis and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {RoBERTa: {A} Robustly Optimized {BERT} Pretraining Approach},
journal = {CoRR},
volume = {abs/1907.11692},
year = {2019},
url = {http://arxiv.org/abs/1907.11692},
archivePrefix = {arXiv},
eprint = {1907.11692},
timestamp = {Thu, 01 Aug 2019 08:59:33 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1907-11692.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}@article{DBLP:journals/corr/abs-1910-01108,
author = {Victor Sanh and
Lysandre Debut and
Julien Chaumond and
Thomas Wolf},
title = {DistilBERT, a distilled version of {BERT:} smaller, faster, cheaper
and lighter},
journal = {CoRR},
volume = {abs/1910.01108},
year = {2019},
url = {http://arxiv.org/abs/1910.01108},
archivePrefix = {arXiv},
eprint = {1910.01108},
timestamp = {Tue, 02 Jun 2020 12:48:59 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1910-01108.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}@article{DBLP:journals/corr/abs-1911-03894,
author = {Louis Martin and
Benjamin M{\"{u}}ller and
Pedro Javier Ortiz Su{\'{a}}rez and
Yoann Dupont and
Laurent Romary and
{\'{E}}ric Villemonte de la Clergerie and
Djam{\'{e}} Seddah and
Beno{\^{\i}}t Sagot},
title = {CamemBERT: a Tasty French Language Model},
journal = {CoRR},
volume = {abs/1911.03894},
year = {2019},
url = {http://arxiv.org/abs/1911.03894},
archivePrefix = {arXiv},
eprint = {1911.03894},
timestamp = {Sun, 01 Dec 2019 20:31:34 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1911-03894.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}@article{dHoffschmidt2020FQuADFQ,
title={FQuAD: French Question Answering Dataset},
author={Martin d'Hoffschmidt and Maxime Vidal and Wacim Belblidia and Tom Brendl'e and Quentin Heinrich},
journal={ArXiv},
year={2020},
volume={abs/2002.06071}
}You are most welcome to contribute to this project. Be it a small typo correction or a feature enhancement. Currently, there is no structure to follow for contribution, but you can open an Issue under "Community contribution" or contact me to discuss it before getting started 🙂
Karthik Bhaskar - Feel free to contact me.