forked from ChenRocks/UNITER
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
0 parents
commit f2582bc
Showing
35 changed files
with
3,664 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,107 @@ | ||
| # ctags | ||
| tags | ||
|
|
||
| # Byte-compiled / optimized / DLL files | ||
| __pycache__/ | ||
| *.py[cod] | ||
| *$py.class | ||
|
|
||
| # C extensions | ||
| *.so | ||
|
|
||
| # Distribution / packaging | ||
| .Python | ||
| build/ | ||
| develop-eggs/ | ||
| dist/ | ||
| downloads/ | ||
| eggs/ | ||
| .eggs/ | ||
| lib/ | ||
| lib64/ | ||
| parts/ | ||
| sdist/ | ||
| var/ | ||
| wheels/ | ||
| *.egg-info/ | ||
| .installed.cfg | ||
| *.egg | ||
| MANIFEST | ||
|
|
||
| # PyInstaller | ||
| # Usually these files are written by a python script from a template | ||
| # before PyInstaller builds the exe, so as to inject date/other infos into it. | ||
| *.manifest | ||
| *.spec | ||
|
|
||
| # Installer logs | ||
| pip-log.txt | ||
| pip-delete-this-directory.txt | ||
|
|
||
| # Unit test / coverage reports | ||
| htmlcov/ | ||
| .tox/ | ||
| .coverage | ||
| .coverage.* | ||
| .cache | ||
| nosetests.xml | ||
| coverage.xml | ||
| *.cover | ||
| .hypothesis/ | ||
| .pytest_cache/ | ||
|
|
||
| # Translations | ||
| *.mo | ||
| *.pot | ||
|
|
||
| # Django stuff: | ||
| *.log | ||
| local_settings.py | ||
| db.sqlite3 | ||
|
|
||
| # Flask stuff: | ||
| instance/ | ||
| .webassets-cache | ||
|
|
||
| # Scrapy stuff: | ||
| .scrapy | ||
|
|
||
| # Sphinx documentation | ||
| docs/_build/ | ||
|
|
||
| # PyBuilder | ||
| target/ | ||
|
|
||
| # Jupyter Notebook | ||
| .ipynb_checkpoints | ||
|
|
||
| # pyenv | ||
| .python-version | ||
|
|
||
| # celery beat schedule file | ||
| celerybeat-schedule | ||
|
|
||
| # SageMath parsed files | ||
| *.sage.py | ||
|
|
||
| # Environments | ||
| .env | ||
| .venv | ||
| env/ | ||
| venv/ | ||
| ENV/ | ||
| env.bak/ | ||
| venv.bak/ | ||
|
|
||
| # Spyder project settings | ||
| .spyderproject | ||
| .spyproject | ||
|
|
||
| # Rope project settings | ||
| .ropeproject | ||
|
|
||
| # mkdocs documentation | ||
| /site | ||
|
|
||
| # mypy | ||
| .mypy_cache/ |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,38 @@ | ||
| FROM nvcr.io/nvidia/pytorch:19.05-py3 | ||
|
|
||
| # basic python packages | ||
| RUN pip install pytorch-pretrained-bert==0.6.2 \ | ||
| tensorboardX==1.7 ipdb==0.12 lz4==2.1.9 lmdb==0.97 | ||
|
|
||
| ####### horovod for multi-GPU (distributed) training ####### | ||
|
|
||
| # update OpenMPI to avoid horovod bug | ||
| RUN rm -r /usr/local/mpi &&\ | ||
| wget https://download.open-mpi.org/release/open-mpi/v3.1/openmpi-3.1.4.tar.gz &&\ | ||
| gunzip -c openmpi-3.1.4.tar.gz | tar xf - &&\ | ||
| cd openmpi-3.1.4 &&\ | ||
| ./configure --prefix=/usr/local/mpi --enable-orterun-prefix-by-default \ | ||
| --with-verbs --disable-getpwuid &&\ | ||
| make -j$(nproc) all && make install &&\ | ||
| ldconfig &&\ | ||
| cd - && rm -r openmpi-3.1.4 && rm openmpi-3.1.4.tar.gz | ||
|
|
||
| ENV OPENMPI_VERSION=3.1.4 | ||
|
|
||
| # horovod | ||
| RUN HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_NCCL_LINK=SHARED HOROVOD_WITH_PYTORCH=1 \ | ||
| pip install --no-cache-dir horovod==0.16.4 &&\ | ||
| ldconfig | ||
|
|
||
| # ssh | ||
| RUN apt-get update &&\ | ||
| apt-get install -y --no-install-recommends openssh-client openssh-server &&\ | ||
| mkdir -p /var/run/sshd | ||
|
|
||
| # Allow OpenSSH to talk to containers without asking for confirmation | ||
| RUN cat /etc/ssh/ssh_config | grep -v StrictHostKeyChecking > /etc/ssh/ssh_config.new && \ | ||
| echo " StrictHostKeyChecking no" >> /etc/ssh/ssh_config.new && \ | ||
| mv /etc/ssh/ssh_config.new /etc/ssh/ssh_config | ||
|
|
||
|
|
||
| WORKDIR /src |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,21 @@ | ||
| MIT License | ||
|
|
||
| Copyright (c) 2019 Microsoft Corporation | ||
|
|
||
| Permission is hereby granted, free of charge, to any person obtaining a copy | ||
| of this software and associated documentation files (the "Software"), to deal | ||
| in the Software without restriction, including without limitation the rights | ||
| to use, copy, modify, merge, publish, distribute, sublicense, and/or sell | ||
| copies of the Software, and to permit persons to whom the Software is | ||
| furnished to do so, subject to the following conditions: | ||
|
|
||
| The above copyright notice and this permission notice shall be included in all | ||
| copies or substantial portions of the Software. | ||
|
|
||
| THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR | ||
| IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, | ||
| FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE | ||
| AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER | ||
| LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, | ||
| OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE | ||
| SOFTWARE. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,137 @@ | ||
| # UNITER: Learning UNiversal Image-TExt Representations | ||
| This is the official repository of [UNITER](https://arxiv.org/abs/1909.11740). | ||
| It is currently an alpha release, which supports finetuning UNITER-base on the | ||
| [NLVR2](http://lil.nlp.cornell.edu/nlvr/) task. | ||
| We plan to release the large model and more downstream tasks but do not have a | ||
| time table as of now. | ||
|
|
||
| 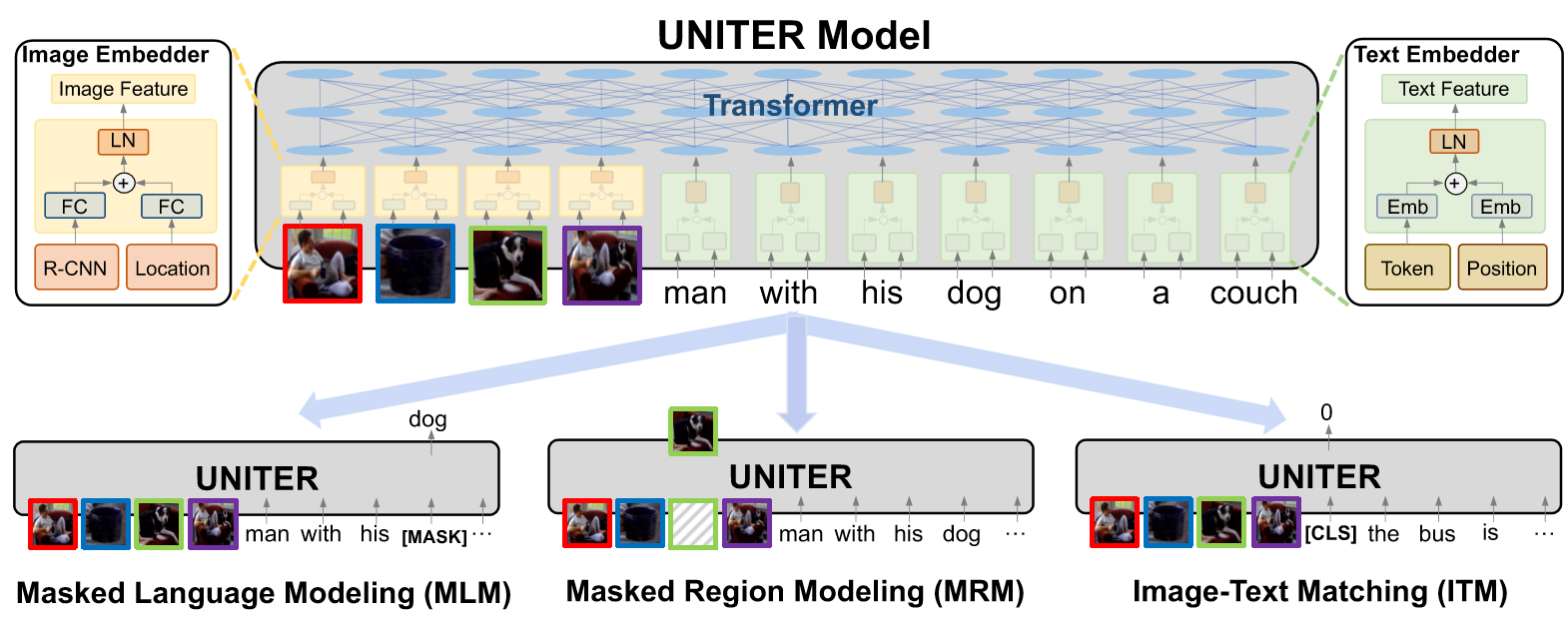 | ||
|
|
||
| Some code in this repo are copied/modified from opensource implementations made available by | ||
| [PyTorch](https://github.com/pytorch/pytorch), | ||
| [HuggingFace](https://github.com/huggingface/transformers), | ||
| [OpenNMT](https://github.com/OpenNMT/OpenNMT-py), | ||
| and [Nvidia](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch). | ||
| The image features are extracted using [BUTD](https://github.com/peteanderson80/bottom-up-attention). | ||
|
|
||
|
|
||
| ## Requirements | ||
| We provide Docker image for easier reproduction. Please install the following: | ||
| - [nvidia driver](https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#package-manager-installation) (418+), | ||
| - [Docker](https://docs.docker.com/install/linux/docker-ce/ubuntu/) (19.03+), | ||
| - [nvidia-container-toolkit](https://github.com/NVIDIA/nvidia-docker#quickstart). | ||
|
|
||
| Our scripts require the user to have the [docker group membership](https://docs.docker.com/install/linux/linux-postinstall/) | ||
| so that docker commands can be run without sudo. | ||
| We only support Linux with NVIDIA GPUs. We test on Ubuntu 18.04 and V100 cards. | ||
| We use mixed-precision training hence GPUs with Tensor Cores are recommended. | ||
|
|
||
| ## Quick Start | ||
| 1. Download processed data and pretrained models with the following command. | ||
| ```bash | ||
| bash scripts/download.sh $PATH_TO_STORAGE | ||
| ``` | ||
| After downloading you should see the following folder structure: | ||
| ``` | ||
| ├── ann | ||
| │ ├── dev.json | ||
| │ └── test1.json | ||
| ├── finetune | ||
| │ ├── nlvr-base | ||
| │ └── nlvr-base.tar | ||
| ├── img_db | ||
| │ ├── nlvr2_dev | ||
| │ ├── nlvr2_dev.tar | ||
| │ ├── nlvr2_test | ||
| │ ├── nlvr2_test.tar | ||
| │ ├── nlvr2_train | ||
| │ └── nlvr2_train.tar | ||
| ├── pretrained | ||
| │ └── uniter-base.pt | ||
| └── txt_db | ||
| ├── nlvr2_dev.db | ||
| ├── nlvr2_dev.db.tar | ||
| ├── nlvr2_test1.db | ||
| ├── nlvr2_test1.db.tar | ||
| ├── nlvr2_train.db | ||
| └── nlvr2_train.db.tar | ||
| ``` | ||
|
|
||
| 2. Launch the Docker container for running the experiments. | ||
| ```bash | ||
| # docker image should be automatically pulled | ||
| source launch_container.sh $PATH_TO_STORAGE/txt_db $PATH_TO_STORAGE/img_db \ | ||
| $PATH_TO_STORAGE/finetune $PATH_TO_STORAGE/pretrained | ||
| ``` | ||
| The launch script respects $CUDA_VISIBLE_DEVICES environment variable. | ||
| Note that the source code is mounted into the container under `/src` instead | ||
| of built into the image so that user modification will be reflected without | ||
| re-building the image. (Data folders are mounted into the container separately | ||
| for flexibility on folder structures.) | ||
|
|
||
|
|
||
| 3. Run finetuning for the NLVR2 task. | ||
| ```bash | ||
| # inside the container | ||
| python train_nlvr2.py --config config/train-nlvr2-base-1gpu.json | ||
|
|
||
| # for more customization | ||
| horovodrun -np $N_GPU python train_nlvr2.py --config $YOUR_CONFIG_JSON | ||
| ``` | ||
|
|
||
| 4. Run inference for the NLVR2 task and then evaluate. | ||
| ```bash | ||
| # inference | ||
| python inf_nlvr2.py --txt_db /txt/nlvr2_test1.db/ --img_db /img/nlvr2_test/ \ | ||
| --train_dir /storage/nlvr-base/ --ckpt 6500 --output_dir . --fp16 | ||
|
|
||
| # evaluation | ||
| # run this command outside docker (tested with python 3.6) | ||
| # or copy the annotation json into mounted folder | ||
| python scripts/eval_nlvr2.py ./results.csv $PATH_TO_STORAGE/ann/test1.json | ||
| ``` | ||
| The above command runs inference on the model we trained. Feel free to replace | ||
| `--train_dir` and `--ckpt` with your own model trained in step 3. | ||
| Currently we only support single GPU inference. | ||
|
|
||
|
|
||
| 5. Customization | ||
| ```bash | ||
| # training options | ||
| python train_nlvr2.py --help | ||
| ``` | ||
| - command-line argument overwrites JSON config files | ||
| - JSON config overwrites `argparse` default value. | ||
| - use horovodrun to run multi-GPU training | ||
| - `--gradient_accumulation_steps` emulates multi-gpu training | ||
|
|
||
|
|
||
| 6. Misc. | ||
| ```bash | ||
| # text annotation preprocessing | ||
| bash scripts/create_txtdb.sh $PATH_TO_STORAGE/txt_db $PATH_TO_STORAGE/ann | ||
|
|
||
| # image feature extraction (Tested on Titan-Xp; may not run on latest GPUs) | ||
| bash scripts/extract_imgfeat.sh $PATH_TO_IMG_FOLDER $PATH_TO_IMG_NPY | ||
|
|
||
| # image preprocessing | ||
| bash scripts/create_imgdb.sh $PATH_TO_IMG_NPY $PATH_TO_STORAGE/img_db | ||
| ``` | ||
| In case you would like to reproduce the whole preprocessing pipeline. | ||
|
|
||
|
|
||
| ## Citation | ||
|
|
||
| If you find this code useful for your research, please consider citing: | ||
| ``` | ||
| @article{chen2019uniter, | ||
| title={Uniter: Learning universal image-text representations}, | ||
| author={Chen, Yen-Chun and Li, Linjie and Yu, Licheng and Kholy, Ahmed El and Ahmed, Faisal and Gan, Zhe and Cheng, Yu and Liu, Jingjing}, | ||
| journal={arXiv preprint arXiv:1909.11740}, | ||
| year={2019} | ||
| } | ||
| ``` | ||
|
|
||
| ## License | ||
|
|
||
| MIT |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,37 @@ | ||
| { | ||
| "train_txt_db": "/txt/nlvr2_train.db", | ||
| "train_img_db": "/img/nlvr2_train/", | ||
| "val_txt_db": "/txt/nlvr2_dev.db", | ||
| "val_img_db": "/img/nlvr2_dev/", | ||
| "test_txt_db": "/txt/nlvr2_test1.db", | ||
| "test_img_db": "/img/nlvr2_test/", | ||
| "checkpoint": "/pretrain/uniter-base.pt", | ||
| "model_config": "/src/config/uniter-base.json", | ||
| "model": "paired-attn", | ||
| "use_img_type": true, | ||
| "output_dir": "/storage/nlvr2/default", | ||
| "max_txt_len": 60, | ||
| "conf_th": 0.2, | ||
| "max_bb": 100, | ||
| "min_bb": 10, | ||
| "num_bb": 36, | ||
| "train_batch_size": 10240, | ||
| "val_batch_size": 10240, | ||
| "gradient_accumulation_steps": 1, | ||
| "learning_rate": 3e-05, | ||
| "valid_steps": 500, | ||
| "num_train_steps": 8000, | ||
| "optim": "adamw", | ||
| "betas": [ | ||
| 0.9, | ||
| 0.98 | ||
| ], | ||
| "dropout": 0.1, | ||
| "weight_decay": 0.01, | ||
| "grad_norm": 2.0, | ||
| "warmup_steps": 800, | ||
| "seed": 77, | ||
| "fp16": true, | ||
| "n_workers": 4, | ||
| "pin_mem": true | ||
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,13 @@ | ||
| { | ||
| "attention_probs_dropout_prob": 0.1, | ||
| "hidden_act": "gelu", | ||
| "hidden_dropout_prob": 0.1, | ||
| "hidden_size": 768, | ||
| "initializer_range": 0.02, | ||
| "intermediate_size": 3072, | ||
| "max_position_embeddings": 512, | ||
| "num_attention_heads": 12, | ||
| "num_hidden_layers": 12, | ||
| "type_vocab_size": 2, | ||
| "vocab_size": 28996 | ||
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,13 @@ | ||
| import sys | ||
| from collections import OrderedDict | ||
|
|
||
| import torch | ||
|
|
||
| bert_ckpt, output_ckpt = sys.argv[1:] | ||
|
|
||
| bert = torch.load(bert_ckpt) | ||
| uniter = OrderedDict() | ||
| for k, v in bert.items(): | ||
| uniter[k.replace('bert', 'uniter')] = v | ||
|
|
||
| torch.save(uniter, output_ckpt) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,12 @@ | ||
| """ | ||
| Copyright (c) Microsoft Corporation. | ||
| Licensed under the MIT license. | ||
| """ | ||
| from .data import TxtTokLmdb, DetectFeatLmdb | ||
| from .sampler import TokenBucketSampler, DistributedTokenBucketSampler | ||
| from .loader import PrefetchLoader | ||
| from .nlvr2 import (Nlvr2PairedDataset, Nlvr2PairedEvalDataset, | ||
| Nlvr2TripletDataset, Nlvr2TripletEvalDataset, | ||
| nlvr2_paired_collate, nlvr2_paired_eval_collate, | ||
| nlvr2_triplet_collate, nlvr2_triplet_eval_collate) |
Oops, something went wrong.