
SQL — это язык структурированных запросов (Structured Query Language), позволяющий хранить, манипулировать и извлекать данные из реляционных баз данных (далее — РБД, БД).
SQL позволяет:
- получать доступ к данным в системах управления РБД
- описывать данные (их структуру)
- определять данные в БД и управлять ими
- взаимодействовать с другими языками через модули SQL, библиотеки и предваритальные компиляторы
- создавать и удалять БД и таблицы
- создавать представления, хранимые процедуры (stored procedures) и функции в БД
- устанавливать разрешения на доступ к таблицам, процедурам и представлениям
А что из себя представляют реляционные БД?
Реляционная база данных — это система хранения и организации информации, имеющей установленные отношения.
- данные упорядочиваются с использованием табличных форм, содержащих сведения об их сущности
- строки и столбцы в таких таблицах представляют заранее установленные категории данных
А самое главное - термин "реляционный" указывает на наличие связей в информационных базах!
Что это всё-таки означает?
При создании базы данных здравый смысл подсказывает, что для разных типов сущностей мы будем использовать отдельные таблицы. Например: клиенты, заказы, предметы, сообщения и т.д. Но нам также нужно иметь между этими таблицами связи. Например, клиенты делают заказы, а заказы содержат предметы. Эти отношения должны быть представлены в базе данных.
В качестве примера рассмотрим онлайн-магазин.
🔶 В нашей базе данных находится таблица с информацией о клиентах. В столбцах указываются имена клиентов и адреса, а в строках – данные по каждому клиенту.
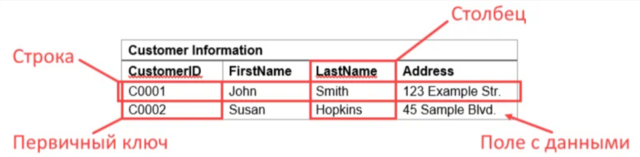
🔶 Допустим, у нас есть таблица с заказами товаров. В одном столбце этой таблицы находится информация о клиенте.
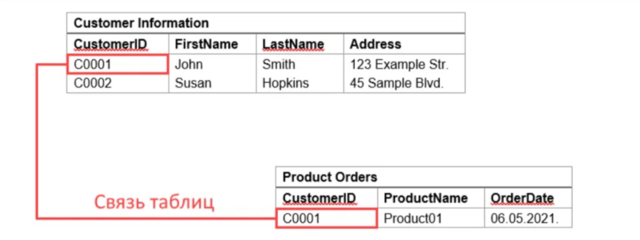
Эти две таблицы можно связать с помощью определенных команд (об этом в следующих темах более подробно). Зачем вообще нужны связи? А может вообще всё сделать в одну таблицу и не мучиться?
Как раз-таки мучиться будем, если так и сделаем. Разбив данные на разные таблицы и построив связи между ними в базе данных мы сможем нормализировать БД, настроить отношение между данными таблиц и сделать эффективные выборки данных.
🔶 Связь между таблицами является важным аспектом хорошей реляционной базы данных.
-
Она устанавливает соединение между парой таблиц, которые логически связаны друг с другом.
-
Это помогает усовершенствовать структуры таблиц и свести к минимуму избыточные данные.
-
Это механизм, который позволяет вам извлекать данные из нескольких таблиц одновременно.
-
Отношения необходимы также для поддержания вашей базы данных в форме нормализации, которая является частью правила реляционной базы данных.
-
А также для поддержания ссылочной целостности, которая является составной частью концепции отношений.
Как и во всех моделях баз данных, здесь есть свои плюсы и минусы.
➕ Плюсы
- Реляционные БД используют таблицы столбцов и строк, поэтому они отображают данные проще, чем другие типы, и работать с ними удобнее.
- Такая табличная структура создана специально для обработки данных, что повышает производительность и позволяет использовать сложные, высокоуровневые запросы.
- И, наконец, в реляционных БД легко масштабировать данные, добавляя строки, столбцы или целые таблицы, не нарушая при этом общей структуры базы.
➖ Минусы
- Реляционные БД могут масштабироваться только до определенного предела. Если говорить о размере базы, то в некоторых БД есть строгое ограничение по длине столбцов. Если вы создаете базу на отдельном сервере, то при ее разрастании придется покупать дополнительное место, то есть в долгосрочной перспективе ее поддержание обходится не дешево.
- Кроме того, постоянное добавление новых элементов может усложнить базу и затруднить установление связей между новыми частями. Сложные отношения между данными замедляют запросы и негативно сказываются на производительности.
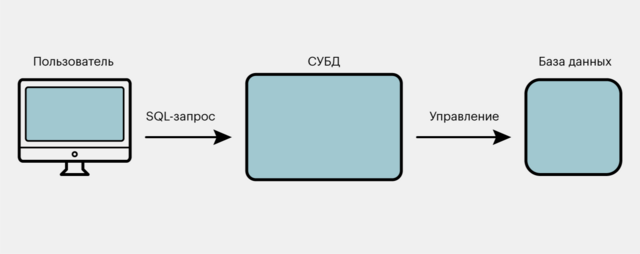
🔶 SQL обращается к базам данных не напрямую, а через системы управления базами данных, или СУБД. СУБД — это посредник, который получает от пользователя команды, что сделать с базой данных, и выполняет их. Эти-то команды и написаны на языке SQL.
🔆 И ещё один нюанс: SQL — декларативный язык. Это значит, что при написании кода мы говорим, что хотим получить от программы. Логика того, как именно СУБД будет выполнять поставленную задачу, скрыта от нас.
Запросы в SQL похожи на естественный английский язык и выглядят как полноценные предложения.
Например, если мы хотим выбрать из таблицы book названия (title) всех книг, которые написал Достоевский Ф.М. (author), то нам нужно написать такую команду:
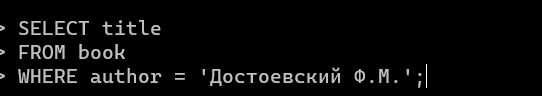
Перевести на русский её можно так: «Выбери значения из столбца title в таблице book, где значение столбца author равно "Достоевский Ф.М.". Символ ; означает конец команды.
CREATE DATABASE — создаёт БД.
DROP DATABASE — удаляет БД.
USE — указывает СУБД, в какой БД работать в дальнейшем.
CREATE TABLE — создаёт новую таблицу внутри БД.
DROP TABLE — удаляет таблицу.
INSERT — добавляет данные в таблицу. Используется вместе с операторами INTO (указывает на таблицу) и VALUES (ему передают значения, которые нужно добавить).
UPDATE — обновляет данные в таблице. UPDATE указывает на саму таблицу, а потом используется оператор SET, после которого и прописываются новые значения для атрибутов. Чтобы указать на конкретную запись, используют оператор WHERE.
DELETE — удаляет данные из таблицы. Используется перед оператором FROM.
SELECT — выбирает данные. Ему передают название атрибута или атрибутов. Если нужно выбрать все атрибуты, то пишут SELECT *. Находится перед оператором FROM.
FROM — указывает на таблицу, к которой обращена команда.
WHERE — указывает на условие или условия, которым должна удовлетворять строка. Пишется после оператора FROM. Необязательный элемент инструкции. Если его не указывать, то команда применяется ко всем записям в таблице.
ORDER BY — сортирует результаты запроса. По умолчанию — в порядке возрастания. Для сортировки по убыванию можно использовать слово DESC.
JOIN — объединяет значения нескольких колонок. Бывает нескольких видов: внутренний (INNER), внешний (OUTER), левый (LEFT) и правый (RIGHT).
🔶 Порядок выполнения SQL запроса — это фактическая последовательность, в которой механизм базы данных обрабатывает различные компоненты SQL запроса. Это не то же самое, что порядок, в котором мы пишем запрос. Следуя определённому порядку выполнения, ядро базы данных может свести к минимуму дисковый ввод/вывод, эффективно использовать индексы и избежать ненужных операций. Это приводит к более быстрому выполнению запросов и меньшему потреблению ресурсов.
Возьмём пример SQL запроса и посмотрим, как он выполняется:
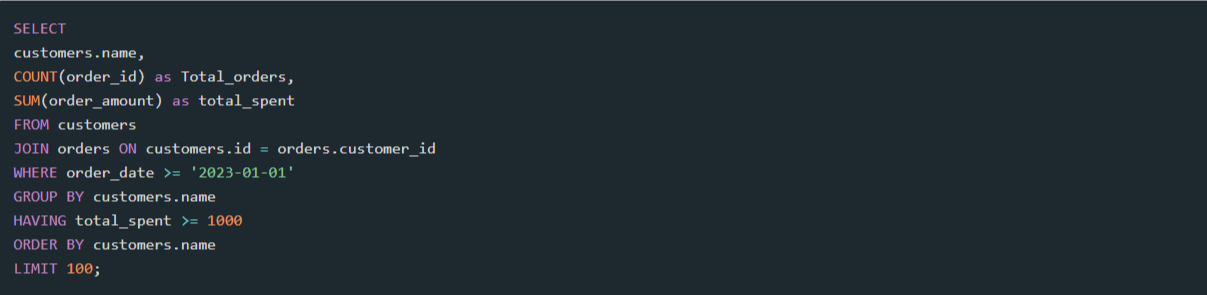
Порядок выполнения этого запроса следующий:
-
Предложение FROM: Первым шагом является определение таблиц, задействованных в запросе. В данном случае это customers и orders.
-
Предложение JOIN: Следующим шагом является выполнение операции объединения на основе условия объединения. В данном случае это customers.id = orders.customer_id, которое связывает две таблицы, сопоставляя id клиентов.
-
Предложение WHERE: Третий шаг — применить условие фильтрации к объединённой таблице. В данном случае это order_date >= '2023-01-01', который выбирает только заказы, сделанные 1 января 2023 года и позже. Теперь важно написать запрос SARGABLE, чтобы эффективно использовать индексы. SARGABLE означает Searched ARGUment ABLE и относится к запросам, которые могут использовать индексы для более быстрого выполнения. Мы углубимся в SARGABLE запросы позже.
-
Предложение GROUP BY: Четвёртый шаг — сгруппировать строки по указанным столбцам. В данном случае это customers.name, которое создаёт группы на основе имени клиента.
-
Предложение HAVING: Пятый шаг — фильтрация групп по условию. В данном случае это total_spent >= 1000, при котором выбираются группы с общей потраченной суммой 1000 и более.
-
Предложение SELECT: Шестой шаг — выбор столбцов и агрегатных функций из каждой группы. В данном случае это customers.name, COUNT(order_id) as Total_orders и SUM(order_amount) as total_spent.
-
Предложение ORDER: Седьмой шаг — сортировка строк по указанным столбцам. В данном случае это customers.name, которое сортирует строки в алфавитном порядке по именам клиентов.
-
Предложение LIMIT: Последний шаг — пропустить несколько строк из отсортированного набора результатов. В данном случае результат ограничивается максимум 100 строками.
Материал о порядке выполнения SQL-запроса взят с сайта dev-notes.ru
⬆️ Решения практических задач с моими пояснениями (подбробный разбор по косточкам) на курсе Stepik Интерактивный тренажёр по SQL
Теоретический материал добавлен мною также из других источников
Информация, размещённая в статье, собрана с различных интернет-ресурсов.
