
You can also find all 50 answers here 👉 Devinterview.io - Hadoop
Apache Hadoop is a robust, open-source platform that facilitates distributed storage and processing of vast datasets across clusters of computers. It provides a cost-effective, powerful, and scalable foundation for Big Data analytics.
- Purpose: Designed for high-speed access to application data and redundantly storing and managing large volumes of data.
- Key Features: Fault tolerance through data replication, high throughput for data access, data integrity, and coherency.
- HDFS Components: NameNode (manages the file system namespace and regulates access to files), DataNodes (store and manage data within the file system), Secondary NameNode (performs periodic checkpoints of the namespace).
- Purpose: Serves as a distributed resource management system for allocating computational resources in Hadoop clusters.
- Key Features: Allows multiple data processing engines like MapReduce, Spark, and others to run on Hadoop in a shared manner.
- YARN Components: ResourceManager (manages and monitors cluster resources), NodeManager (manages resources on individual nodes), ApplicationMaster (coordinates execution of a particular application or job), Containers (virtualized resources where application code runs).
- Purpose: A data processing model that processes large data sets across a Hadoop cluster in a distributed and parallel manner.
- Key Features: Implements data distribution, data processing, and data aggregation phases.
- MapReduce Components: Mapper (processes input data and generates key-value pairs), Reducer (aggregates the key-value pairs generated by the Mappers), Partitioner (distributes the key-value pairs across Reducers), Combiner (performs local aggregation on the Map output before it's shuffled to the Reducers).
Hadoop's rich ecosystem comprises tools and frameworks that extend its functionality to various Big Data tasks:
- Apache Hive: A data warehouse infrastructure that provides data summarization and ad hoc querying using a SQL-like language called HiveQL. It translates queries to MapReduce jobs.
- Apache HBase: A NoSQL database designed to operate on top of HDFS. It's capable of real-time read/write access to Big Data.
- Apache ZooKeeper: A centralized service for distributed systems that enables synchronization and group services, such as configuration management and distributed locks.
- Apache Oozie: A workflow scheduler to manage Apache Hadoop jobs.
- Apache Mahout: A library of scalable machine learning algorithms that can be run on Hadoop. It allows easy implementation of simple Hadoop workflows.
- Apache Pig: A platform for analyzing large datasets. It provides a high-level language, Pig Latin, which automates common data manipulation operations.
Hadoop is highly flexible and compatible with a wide array of hardware vendors and cloud service providers, making it a favorite choice for efficient Big Data management and analysis.
Hadoop Distributed File System (HDFS) is a distributed, fault-tolerant, and scalable file system designed to reside on commodity hardware. It's part of the core Hadoop ecosystem and provides reliable data storage for distributed data processing tasks.
- Rack Awareness: HDFS is aware of machine racks, enabling optimized data replication.
- Write Once, Read Many: It's better suited for applications where files are written once but read multiple times.
- Data Locality: HDFS aims to process data on the same nodes where it is stored to minimize network congestion.
- NameNode: Serves as the master node, keeping track of the file system structure and metadata like permissions and data block locations.
- DataNode: Multiple nodes serve as slaves, storing the actual data blocks and responding to requests from clients.
- Client: Applications that use HDFS. They can be run as a library or a separate utility, interacting with Namenode and Datanodes.
HDFS uses block storage, typically with a default block size of 128 MB (configurable) and a replication mechanism to ensure data redundancy. By default, it makes three copies of each block.
- File Write: The client splits the file into blocks and sends them to DataNodes for storage. The NameNode records the blocks' locations.
- Block Replication: DataNodes replicate blocks for redundancy.
- File Read: The client fetches block locations from the NameNode and reads directly from the DataNodes.
- File Deletion: The client requests file deletion from the NameNode, which updates metadata and expedites block deletion on DataNodes.
HDFS employs both data mirroring across DataNodes and block replication to ensure that each data block is safely stored across the cluster. This approach minimizes data loss due to node failures.
Even if a single node or a few nodes fail, data remains accessible using the available replicas. When a node becomes inaccessible, the NameNode redistributes the blocks stored on that node.
- Latency with Small Files: Not optimized for high-throughput or low-latency requirements, especially with small files.
- Primary Consistency: Ensures only primary consistency, which might not suffice for applications needing strong consistency.
Here is the Java code:
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path inFile = new Path("/input/file.txt");
try(FSDataInputStream in = fs.open(inFile)) {
byte[] buffer = new byte[8192];
int bytesRead = in.read(buffer);
// Process the data
} catch(IOException e) {
// Handle exception
}This Java code demonstrates how to read a file from HDFS using the FileSystem and FSDataInputStream classes.
MapReduce is the foundation of Hadoop's parallel data processing system. Its two-step methodology involves mapping data into key-value pairs and then reducing based on those keys.
- Input Data: Gets divided into smaller chunks for processing.
- Mapper: Operates on these data chunks, typically filtering, transforming, and sorting them.
- Shuffle and Sort: Collects and organizes mapped data before passing it to the reducers.
- Reducer: Processes and aggregates the data, finalizing the output.
- Data Splitting: Hadoop splits data files into manageable blocks (default: 128MB).
- Mapper Input: Each block is processed by multiple mappers, creating intermediate key-value pairs.
- Data Shuffling: Key-value pairs are shuffled, sorted, and grouped to ensure data of the same key goes to the same reducer.
- Reducer Input: Reducers handle key groups separately, computing each group's output.
Here is the mapper code:
from mrjob.job import MRJob
class WordCount(MRJob):
def mapper(self, _, line):
words = line.split()
for word in words:
yield word, 1
if __name__ == '__main__':
WordCount.run()And the corresponding reducer:
from mrjob.job import MRJob
class WordCount(MRJob):
def reducer(self, key, values):
yield key, sum(values)
if __name__ == '__main__':
WordCount.run()- Job Tracker: Manages all jobs in the Hadoop cluster.
- Task Tracker: Each node runs a task tracker to execute Map and Reduce tasks.
- Data Locality: Hadoop tries to process data on the same node where it's stored, minimizing data transfer over the network.
YARN, short for "Yet Another Resource Negotiator," is Hadoop's latest resource management platform. YARN represents a crucial advancement over its predecessor, the TaskTracker/JobTracker system, by offering a more flexible, scalable, and precise resource assignment and management.
YARN has a distributed architecture comprising three main components:
-
Resource Manager (RM): The primary master daemon. It oversees resource allocation and job scheduling across the Hadoop cluster. It's composed of two sub-components: the Scheduler and the ApplicationManager.
-
Node Manager (NM): Per-cluster-node slave daemon. This manager is responsible for monitoring resources on individual cluster nodes and for being responsive to Resource Manager requests.
-
Application Master (AM): A per-application framework-specific master. It orchestrates the task execution and resource management for a particular application.
-
Resource Manager (RM): This represents the global resource scheduler. It's in charge of handling job submissions, negotiates resources, and works to avoid over-commitment of resources.
-
Node Manager (NM): This daemon is present on all nodes within the cluster, monitoring resource usage (CPU, memory, etc.) and reporting the same to the Resource Manager.
-
Application Master (AM): A specialized resource manager for a single application. It handles the task of requesting resources from the Resource Manager and processing them from Node Managers.
The typical resource management flow in a YARN setup involves these general steps:
-
Job Submission and Initialization: The client submits the job to the Resource Manager. The Resource Manager deploys the Application Master specific to the application.
-
Resource Acquisition: The Application Master, after initialization, requests the resources it needs from the Resource Manager.
-
Task Execution: The Application Master directs the Node Manager to launch containers, which are the entities where the actual tasks (mappers or reducers, in the case of MapReduce) are run.
-
Client Communication: The Resource Manager and Application Master constantly update the client about the job status.
The main distinguishing feature of YARN is its use of the "container concept" for allocating resources. A container is a unified unit of CPU, memory, storage, and network resources, which is what YARN allocates to an application or a task.
The flexibility of containers sets YARN apart, as it allows systems like MapReduce and other applications to request the specific resources they need (e.g., CPU cores or memory). This is in contrast to the initial approach, where MapReduce tasks were restricted to fixed-size resource slots.
-
Improved Task Scheduling: YARN enhances task scheduling by allowing applications to request specific resources and schedule tasks promptly.
-
Resource Management Flexibility: With containers, applications are no longer restricted to a predetermined number of slots for resources. They can tailor requests based on their unique requirements.
-
Multi-Tenancy Capability: YARN supports the simultaneous execution of multiple workloads, making it possible for different applications to exist and operate within the same Hadoop cluster.
-
Enhanced Ecosystem Integration: Both new and existing processing frameworks can seamlessly integrate with the YARN infrastructure, adding further functionality to the Hadoop ecosystem.
-
Simplified Cluster Maintenance: Node Manager and Application Master roles permit easy handling of resources and applications at the cluster node level and within applications, respectively.
The Namenode and Datanodes form the backbone of HDFS, managing metadata and data storage, respectively.
The Namenode primarily functions as the metadata repository for the file system. It maintains file-to-block mapping, file permissions, and the hierarchical directory structure.
The Namenode's key responsibilities include:
- Metadata Storage: It stores metadata such as block IDs, permissions, and modification times.
- Namespace Operations: It manages the file system namespace, including directory and file creation, deletion, and renaming. It also handles attribute modifications.
- Access Control: The Namenode enforces access permissions and authenticates clients.
Checkpointing is the process of merging edit logs with the filesystem metadata on disk. Least frequently modified data is checked less often. This ensures that the namenode remains responsive.
Datanodes are responsible for storing and managing the actual data in HDFS. They execute file I/O operations requested by clients and the namenode.
The main functions of Datanodes are:
- Block Operations: They perform read, write, and delete operations on the data blocks, and report block health and integrity to the Namenode.
- Heartbeats: Datanodes send periodic heartbeats to the Namenode, indicating their operational status.
- Block Reports: They periodically report the list of blocks that they are hosting to the Namenode.
In case of block loss or corruption, the Datanode is responsible for replicating or recovering the block.
HDFS employs a client-server model for read and write operations.
- Read: The client requests data from Datanodes, which operate directly on the files and send blocks to the client.
- Write: The client communicates with the Namenode for file metadata and then directly with Datanodes.
In a distributed environment, keeping a single point of failure is not desirable, which is why there is a mechanism for High Availability with multiple active namenodes (machines).
- Active Namenode: Serves read and write requests.
- Standby Namenode: Maintains enough state information to take over in case of active Namenode failure.
This is achieved via a mechanism called Quorum Journal, which ensures that both Namenodes see the same transactions.
HDFS stores multiple copies of data blocks across Datanodes to ensure high data availability and reliability. The system is configurable to determine the replication level. Usually, the default number of replicas is three.
When a modification happens, the client asks the Namenode for a list of Datanodes to store the new data. Once the writing Datanodes confirm, the operation is considered successful.
In Hadoop Distributed File System (HDFS), the concept of Rack Awareness refers to HDFS's ability to understand the network topology and the physical location of its nodes. The primary goal of Rack Awareness is to optimize data storage reliability and data transfer efficiency (reducing inter-rack data traffic).
HDFS leverages a two-level topology consisting of Racks and Nodes:
- Racks: Represent physical groups or locations of nodes, often within the same data center. They serve as a defining structure that organizes and groups nodes.
- Nodes: Indicate individual machines or servers that store data and comprise Hadoop clusters.
By utilizing this generated network, Hadoop actively places blocks of data across different racks to achieve fault tolerance and performance
HDFS nodes optimize data transfer during block movement, particularly during operations such as rebalancing, replication, and block recovery. This results in a reduction in unnecessary and potentially costly inter-rack data traffic.
-
Fault Tolerance:
- Minimizes probability of losing data due to rack-wide failures.
- Guarantees at least one replica of a block exists on an adjacent rack (except in the case of just one rack).
-
Network Efficiency:
- Reduces bottlenecks and network congestion because data can be read closer to the requesting node, from the local rack where possible.
- Lessens the risk of latency and data transfer overhead caused by inter-rack nodes.
-
Inter-Rack Balancing:
- Distributes blocks equitably across racks, ensuring efficient use of storage and resources.
- Facilitates uniform data access and load distribution.
HDFS uses Rack Awareness Algorithms to control how data placement and data transfer operations work across nodes and racks. Latter versions of HDFS come with dynamic rack discovery techniques to handle more complex and evolving data center configurations.
The default rack allocation strategy employs a simple Round-Robin approach to distribute blocks among the data cluster's racks, offering a fundamental yet efficient methodology for data storage and transfer operations. Different strategies, whether static or dynamic, including manual rack planning, might be more fitting for specific scenarios or requirements.
You can set and modify the Rack Awareness policies and configurations in your Hadoop setup using HDFS-specific configuration files, such as hdfs-site.xml.
For instance, you can make use of the following Rack Awareness configurations to:
- Define the number of replicas managed within HDFS.
- Outline the number of racks and their locations within your datacenter.
- Assign nodes to particular racks and guarantee the right configuration of the clusters.
- Allocate nodes fine-tuned to specific racks fitting your rack-based storage or networking needs.
Both Hadoop and relational database management systems (RDBMS) are used for data management. However, they differ in the types of data they handle and their underlying data models.
-
Hadoop: Utilizes a schema-on-read model, allowing for more flexible handling of unstructured or semi-structured data.
-
RDBMS: Implements a schema-on-write model, requiring data to adhere to pre-defined structures before ingestion.
-
Hadoop: Distributes and stores data across clusters in a scalable and fault-tolerant manner. It's suitable for managing large volumes of both structured and unstructured data.
-
RDBMS: Stores data in a structured, tabular format across different tables. While data scaling can be vertical to an extent, horizontal scaling can be complex relative to Hadoop.
-
Hadoop: Primarily employs batch processing with tools such as MapReduce. However, with advancements such as YARN and Spark, it also supports real-time and interactive processing.
-
RDBMS: Designed for transactional processing and predominantly utilizes online transaction processing (OLTP) systems. With the advent of in-memory engines and modern architectures, some RDBMS now support real-time analytics as well.
-
Hadoop: Offers greater flexibility in terms of data analytics workflows. Tools such as Hive, HBase, and Impala allow for various types of data access and query processing.
-
RDBMS: Designed with a specific structure that caters well to certain types of read and write operations. Changes to schema can be challenging, and reporting on unstructured or semi-structured data may be limited.
-
Hadoop: Ideal for processing high volumes of unstructured or semi-structured data, and is often the go-to choice for big data analytics tasks.
-
RDBMS: Suited for handling structured data, is a core component of enterprise systems like customer relationship management (CRM), and is commonly used for traditional point-of-sale (POS) systems.
-
Hadoop: Offers eventual consistency and, in some cases, the concept of "read-your-write" consistency. Duplicating data across nodes enables parallel processing and fault tolerance.
-
RDBMS: Emphasizes immediate consistency to ensure data integrity. While replication and failover can be supported, they often require sophisticated setups and can involve some latency.
Securing a Hadoop cluster involves several measures and mechanisms to safeguard data, control access, and ensure its integrity. Here are some common methods:
- Kerberos: This industry-standard authentication system for Hadoop clusters uses tickets to reduce the risk of unauthorized access.
- LDAP/AD: Hadoop clusters can integrate with LDAP (Lightweight Directory Access Protocol) or Active Directory. This centralizes user authentication and simplifies account management.
- Pluggable Authentication Modules (PAM): These modules enable system nodes to authenticate users and provide mechanisms for password management.
- Hadoop ACLs (Access Control Lists): These lists are associated with Hadoop files and directories to restrict access. Hadoop supports both POSIX-like mechanisms and extended ACLs.
- Hadoop Native Permission model: This mechanism is based on POSIX permissions, consisting of read, write, execute permissions for the owner, the group, and others.
- Data Encryption: HDFS data can be encrypted at rest for additional security. Various tools like OpenSSL, HDFS transparent encryption, and Key Management Servers (HSM/KMS) can be used for encryption.
- Network Encryption: Secure communication between nodes can be established using SSL or SASL mechanisms.
Hadoop clusters can be managed using role-based access control, such as setting up specific roles with defined privileges and then assigning users to these roles.
Hadoop delegates authorization to particular users or system components for certain actions using various mechanisms, including:
- Hive: Through the authorization layer where users are required to possess specific privileges to perform actions on different resources.
- HBase: Using the Apache Ranger plugin or the built-in cell-level permissions feature, which ensures users only have access to specific data clusters based on their permissions.
- Ranger and Sentry: These are centralized authorization tools for Hadoop-based systems that provide a policy engine to define permissions.
- Kafka: This broker requires access controls to work correctly, particularly in multitenant setups.
Cluster nodes can be configured with secure shell (SSH) for encrypted communication between client and server nodes, enhancing overall cluster security.
Using configurations like hadoop.proxyuser.USERNAME.groups, administrators can set up superuser to execute jobs on behalf of other users, thus granting them a subset of their permissions to run said jobs.
HBase is an essential part of the Hadoop Ecosystem. It functions as a scalable NoSQL database that primarily caters to quick and seamless data access.
HBase's unique architecture, which melds real-time access with the enormous storage capacity of the Hadoop Distributed File System (HDFS), makes it ideally suited for a variety of applications.
-
Linear Scalability: HBase can grow to accommodate petabytes of data, and it leverages Hadoop's distributed nature for parallel data operations.
-
Consistency: Users can expect strong consistency through data integrity checks and instantaneous data retrievals.
-
Real-time Access: HBase's architecture supports low-latency data access, efficiently handling rows with billions of columns.
-
Integration with Hadoop: It seamlessly incorporates with Hadoop projects like MapReduce, Apache Hive, and Apache Pig.
-
Automatic Failure Recovery: HBase employs mechanisms like ZooKeeper to ensure system stability in case of node failures.
HBase follows the Availability and Partition Tolerance aspects of the CAP theorem, a natural fit given its real-time use cases.
-
HMaster: Responsible for administrative tasks, such as region assignment and various cluster operations.
-
RegionServer: Manages read and write operations for distinct data regions.
-
ZooKeeper: Acts as a distributed coordination service, crucial for tasks like leader election and synchronization.
HBase's ability to manage data versions efficiently makes it a preferred choice for time-ordered records in industries like finance and telecommunications.
HBase, through its low-latency and column-oriented structure, ably supports analytics with strong consistency.
With high write and read throughput, HBase caters marvelously to IoT devices generating continuous streams of data.
Its flexibility in handling unstructured data is tapestry-like, extending into data cataloging and management.
HBase's blend of real-time capabilities with schema flexibility finds extensive utilization in targeted advertising and customer analytics.
HBase embodies the spirit of Hadoop and seamlessly integrates with its components, thus reinforcing the overall utility and operability of the ecosystem.
Apache Hive is a versatile data warehousing tool that provides SQL interface to query and manage structured data in distributed storage like Hadoop.
With many of its core functionalities similar to relational databases, Hive brings hierarchical data processing and scalability to the table. It's ideal for analytical queries over large datasets, forming a vital part of the Hadoop ecosystem.
HiveQL, a SQL-like scripting language, allows users to perform SQL queries on distributed datasets, abstracting the underlying MapReduce jobs.
Hive stores metadata such as schema details, table info, and partition statistics in a centralized metadata repository called the Hive Metastore. This separation of metadata from data enables better data management and accessibility.
HiveServer is a service that works as an interface to Hive, allowing external clients to interact with Hive through JDBC, ODBC, or Thrift.
Hive Analyzer optimizes queries using techniques such as cost-based optimization, join reordering, predicate pushdown, and more to enhance query performance.
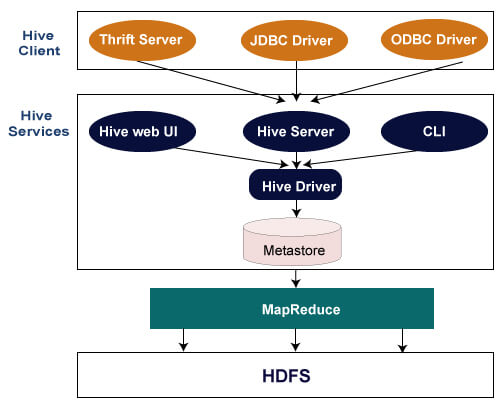
When you execute a Hive query, several components work together to process the tasks:
-
User Interface: Initially, the user submits a SQL-like query through the Hive command line or a GUI tool such as Hue.
-
Driver: The Driver consists of multiple components: Compiler, Query Planner, and Optimizer. The query goes through these elements, generating an execution plan.
-
Metastore: Hive's Metastore contains schemas, partitions, information about serialized objects, and the location of Data in the Hadoop Distributed File System (HDFS).
-
Hadoop: The Hadoop component is responsible for the actual storage and processing of data.
-
Execution Engine: The Execution Engine carries out the TaskDeployment on Hadoop
-
Data Warehousing: Suitable for warehouse needs, providing relational database features with distributed data handling.
-
ETL (Extract, Transform, Load): Performs ETL functions using familiar SQL constructs, enhancing usability for data engineers.
-
Ad-Hoc Queries: Allows on-the-go data analysis, common in multi-department business environments.
-
Metric Calculations: Ideal for tasks like KPI monitoring and report generation.
HiveQL abstracts the underlying MapReduce jobs and introduces a more user-friendly SQL-like methodology. When you run a Hive query, it is translated into a series of map/reduce tasks that get applied to the distributed data.
Apache Pig is a platform that allows for the creation of complex data pipelines within the Hadoop ecosystem. By using Apache Pig Latin, a domain-specific language, users can describe the way data should be transformed and analyzed.
-
Data Types and Operators: Pig Latin provides high-level abstractions for common data operations and supports both structured and semi-structured data.
-
Eager Evaluation: Most Pig Latin operations are executed immediately, enabling rapid data debugging.
-
Hadoop Integration: Pig scripts translate into MapReduce jobs, simplifying multi-step data processes.
-
Extensibility: Pig UDFs (User Defined Functions) allow users to implement custom data operations using Java, Python, or other languages.
-
Descriptor Metadata: Pig supports data type detection and schema inference, providing metadata alongside data, which can be useful for certain analytics functions.
-
Optimization: The query compiler optimizes scripts for efficiency.
-
Multi-Language Support: Pig Latin can be written in various languages beyond English.
- Abstraction Level: Pig abstracts many MapReduce details, simplifying development.
- Language Complexity: Pig Latin is SQL-like, often easier for non-programmer analysts.
- Join Optimizations: Pig can optimize join operations, relieving the developer from manually doing so in MapReduce.
- Pig Latin Script: Programmers write scripts in Pig Latin.
- Pig Latin-to-MapReduce: The Pig Latin script is parsed and transformed into a sequence of MapReduce jobs.
- MapReduce Execution: The generated MapReduce jobs are executed on the Hadoop cluster.
- Data Loading:
LOAD,STORE,DUMPare used to read and write data. - Data Transformation:
FILTER,JOIN,GROUP, and more refine data. - User-Defined Functions: Developers can implement custom functions in Java and use them in Pig scripts via the
DEFINEkeyword. - Data Export:
FOREACHandGENERATEprepare data for output.
Here is a Pig Latin script that processes log data:
-- Load the data
A = LOAD 'hdfs://example.com/data/access.log' USING PigStorage() AS (date:chararray, time:chararray, user:chararray, url:chararray);
-- Filter for specific events
B = FILTER A BY date == '20220501' AND hour >= '06' AND hour <= '12';
-- Extract required fields and write to output
C = FOREACH B GENERATE date, time, user, url;
DUMP C;Apache Flume serves as a distributed, reliable, and available system designed to efficiently collect, aggregate, and move large volumes of log and event data from diverse sources to centralized data stores such as HDFS (Hadoop Distributed File System).
- Agent: A lightweight JVM service where data flows in through sources, moves across channels, and exits via sinks.
- Event: Basic data unit, representing a byte array.
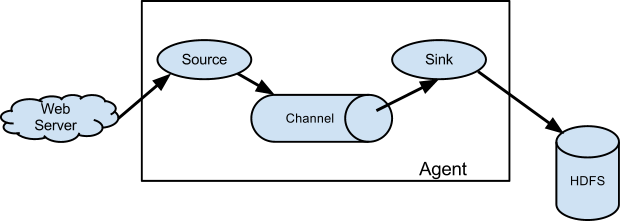
Flume is often deployed in a multi-tier architecture, which provides both flexibility and management benefits. It works especially well for varied and far-reaching data collection requirements.
- Data Ingestion (Source): Often employs Flume's lightweight, high-throughput agents that can be efficiently distributed to the machines generating the data. Agents serve as initial collection points where data originates.
- Data Collection & Movement (Sink): Resides in a central location and is typically a Hadoop cluster. It ingests data from various agents and delivers it to the final destination (e.g., HDFS).
- Data Storage (Channels): Acts as an intermediate, fault-tolerant storage for data in transit between agents and the centralized collection point.
- Reliability: Guarantees data delivery, even under hardware or network failures.
- Horizontal Scalability: Easily expands to handle higher data volumes and a broader range of sources.
- Data Partitioning: Ability to partition data for load balancing and fault tolerance.
- Data Aggregation: Efficiently groups data to limit overheads in downstream processing.
- Extensible: Since it's open-source, it supports third-party plugins.
Configure a Flume agent to ingest data from a Twitter stream and write it directly to an HDFS sink. Name this agent "TwitterAgent". Inside the "twitter.conf" file, you'd add the following configuration:
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = XXXXX
TwitterAgent.sources.Twitter.consumerSecret = XXXXX
TwitterAgent.sources.Twitter.accessToken = XXXXX
TwitterAgent.sources.Twitter.accessTokenSecret = XXXXX
TwitterAgent.sources.Twitter.keywords = hadoop, bigdata, apache
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://namenode/path/to/hadoop/storage
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
TwitterAgent.sinks.HDFS.hdfs.idleTimeout = 20
TwitterAgent.sinks.HDFS.hdfs.filePrefix = twitter_stream- Kafka: Emphasizes general-purpose data streaming with higher throughput and less focus on data transformation.
- NiFi: Offers interactive and visual data flow management with real-time data movement and transformation capabilities.
- Sqoop: Specializes in bulk data transfer between Hadoop and structured datastores such as RDBMS.
- Chukwa: Primarily aims at monitoring and managing large distributed systems, consolidating and providing a detailed view of the cluster state.
Apache Sqoop acts as a data ingestion tool that enables the transfer of data between Hadoop (HDFS) and relational databases. This back-and-forth flow of data is bidirectional, adhering to the different storage formats and offering a range of configuration parameters that ensure adherence to Hadoop and the database.
-
RDBMS: Sqoop serves as a bridge between Hadoop and a variety of relational databases including MySQL, Oracle, Apache, Derby, and PostgreSQL.
-
HDFS: Sqoop can interface with the Hadoop Distributed File System for importing data into Hadoop and exporting data from it.
-
Connectors: These connectors facilitate linking Sqoop with different RDBMS. Users can develop custom connectors for databases without native support.
-
Import & Export Workflows: Sqoop affords distinct workflows for importing data from RDBMS to Hadoop and for exporting data from Hadoop to RDBMS.
-
Job Scheduling: Sqoop has provisions for task scheduling, allowing regular jobs to automate data flows.
-
MapReduce Integration: Sqoop utilizes Hadoop's MapReduce framework for tasks such as data partitioning and transferring data in parallel to optimize performance.
-
Cluster Coordination: Sqoop leverages resources from Hadoop's YARN or MapReduce to manage large-scale data transfers efficiently.
-
Parallel Data Transfer: Provides for concurrent data transfer for increased speed.
-
Automated Code Generation: Generates Java code that can be executed directly to process the data.
-
Data Validation: Offers options to ensure data integrity during transfer.
-
Monitoring and Insights: Offers detailed logs and progress updates during the transfer process.
Here is the Java code:
import org.apache.sqoop.Sqoop;
import org.apache.sqoop.tool.ImportTool;
public class RDBMStoHDFS {
public static void main(String[] args) {
String[] sqoopArgs = {
"--connect", "jdbc:mysql://localhost/mydb",
"--username", "user",
"--password", "pwd",
"--table", "my_table",
"--target-dir", "/user/hadoop/my_table"
};
int status = Sqoop.runTool(sqoopArgs, new ImportTool());
}
}Oozie, a workflow scheduler system specifically designed for Hadoop, coordinates and manages data processing jobs on a Hadoop cluster.
-
Actions: Represent a specific task or job in the workflow. This can be a MapReduce, Pig, Hive, Sqoop, or Shell action and more.
-
Workflows: Graphical representations of a set of actions and their dependencies.
-
Coordinators: Time or data-driven scheduling systems that manage workflows and trigger their execution based on specified parameters such as specific time slots or the availability of data.
-
Bundles: Used to group multiple coordinators, simplifying the management of multiple related workflows.
Oozie coordinates the execution of actions in two types of workflows:
-
Direct Acyclic Graphs (DAGs): Actions are executed in a topological order based on their dependencies (as defined in the workflow XML).
-
Data-Driven Workflows: Actions are executed in response to changes in data. This is especially useful for data ingestion, ETL processes, and other data-centric workflows.
-
Actions: Each action has a defined execution lifecycle, which includes transitioning states like READY, RUNNING, SUSPENDED, and SUCCEEDED. Actions communicate their status to Oozie via callback.
-
Control Nodes: Oozie workflows include control nodes that can set state transitions based on specific criteria (e.g.,
decisionfor conditional execution,fork-jointo execute multiple actions in parallel, orstart-endfor workflow execution boundaries).
Coordinators manage job scheduling based on different strategies:
-
Frequency: Jobs execute with regular time intervals (minute, hourly, daily, etc.).
-
Data Availability: Jobs trigger when necessary data becomes available.
-
Mix Mode: A combination of frequency and data availability.
Coordinators also handle common scheduling scenarios:
-
Initial Job: Execute a job once at the start of a dataset's availability.
-
Timeout: Define a period after which the job will time out if the dataset is not available.
Oozie utilizes an XML-based workflow definition and a properties file to capture the configuration settings.
-
Workflow XML: Describes the workflow graph and its actions.
-
Action Configurations: Specify settings for individual actions.
-
Global Configurations: Define settings applicable to the entire workflow.
These artifacts are typically packaged into a Workflow Application, typically a ZIP file, and submitted to Oozie for execution.
Oozie provides mechanisms for actions and workflows to handle failures:
-
Action Retry: Configurable automatic retries for failing actions.
-
Action-to-Action Transition: Define specific transition paths based on the outcome of previous actions.
-
Kill Node: Allows for conditional ending of workflows based on specific criteria, like the status of certain actions.
Oozie offers web consoles and command-line interfaces for workflow management, monitoring, and reporting. These tools are essential for gaining insights into job execution and troubleshooting any potential issues.
Here is the XML config:
<workflow-app xmlns="uri:oozie:workflow:0.5" name="my_workflow">
<start to="first_action" />
<action name="first_action">
<ssh>
<host>example.com</host>
<command>echo "First action executed"</command>
</ssh>
<ok to="second_action" />
<error to="fail" />
</action>
<action name="second_action">
<java>
<!-- Java configuration settings -->
</java>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<message>Workflow failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end" />
</workflow-app>This workflow contains two actions: an SSH action and a Java action. The workflow starts with the first_action and transitions to the second_action upon successful completion of the first action. If any action fails, the workflow transitions to the fail node, displaying an error message that includes the error of the last failing node.
Apache ZooKeeper is a powerful coordination service essential for distributed systems like Hadoop, ensuring that tasks are carried out efficiently and consistently across multiple nodes.
-
Configuration Management: Simplifies configuration updates in distributed systems, ensuring each node consistently applies any changes.
-
Naming Services: Utilizes the hierarchical namespace to register and locate resources (often data nodes in Hadoop clusters).
-
Synchronization: Offers different kinds of locks, allowing for fine-grained control over access to resources in distributed environments.
-
HDFS Federation: Utilizes ZooKeeper for Active NameNode selection in federated HDFS clusters.
-
HBase: The data store uses ZooKeeper to keep track of active and standby Master servers, providing high availability.
-
Distributed Coordination Service: Multiple Apache distributed applications use it as a standard coordination mechanism.
-
Ordering and Atomicity: It offers strong consistency, ensuring that operations are applied in the same order across all nodes.
-
Reliable Delivery: Every change notification is sent to clients, making sure they are aware of the system's current state.
-
Fault Tolerance: In the event of node failures, tasks and services are redistributed to ensure continued functioning.
-
High Availability: Redundant services and nodes are managed, and active ones are identified to provide consistent services.
-
Synchronization: Ensures data consistency and avoids race conditions, making aggregate computations and shared data processing more reliable.
-
Reliable Deployment: ZooKeeper takes care of tasks that are otherwise complex in distributed systems, like leader election and distributed locking, making the deployment and management of Hadoop services easier.
Explore all 50 answers here 👉 Devinterview.io - Hadoop