Flagger is a Kubernetes operator that automates the promotion of canary deployments using Istio routing for traffic shifting and Prometheus metrics for canary analysis.
Deploy Flagger in the istio-system namespace using Helm:
# add the Helm repository
helm repo add flagger https://flagger.app
# install or upgrade
helm upgrade -i flagger flagger/flagger \
--namespace=istio-system \
--set metricsServer=http://prometheus.istio-system:9090Flagger is compatible with Kubernetes >1.11.0 and Istio >1.0.0.
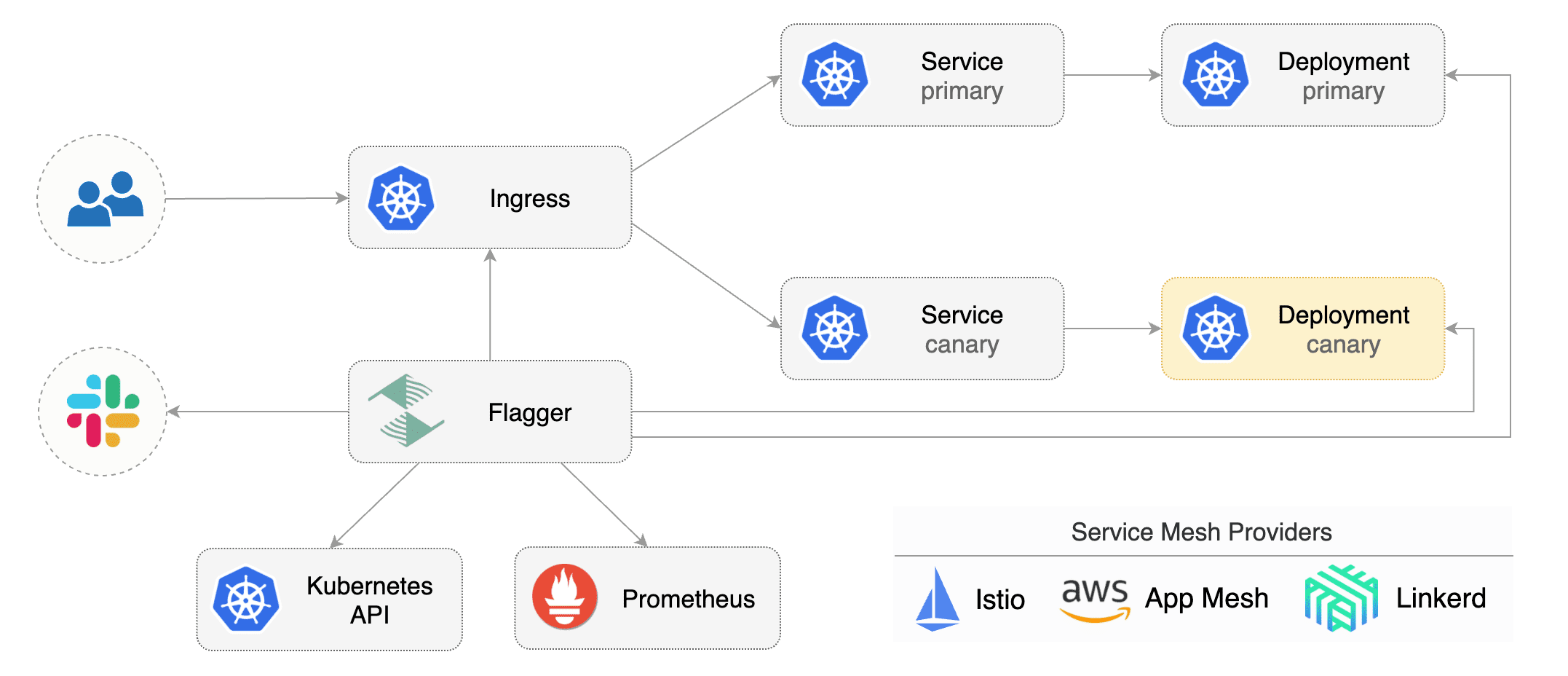
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA) and creates a series of objects (Kubernetes deployments, ClusterIP services and Istio virtual services) to drive the canary analysis and promotion.
A canary deployment is triggered by changes in any of the following objects:
- Deployment PodSpec (container image, command, ports, env, resources, etc)
- ConfigMaps mounted as volumes or mapped to environment variables
- Secrets mounted as volumes or mapped to environment variables
Gated canary promotion stages:
- scan for canary deployments
- check Istio virtual service routes are mapped to primary and canary ClusterIP services
- check primary and canary deployments status
- halt advancement if a rolling update is underway
- halt advancement if pods are unhealthy
- increase canary traffic weight percentage from 0% to 5% (step weight)
- call webhooks and check results
- check canary HTTP request success rate and latency
- halt advancement if any metric is under the specified threshold
- increment the failed checks counter
- check if the number of failed checks reached the threshold
- route all traffic to primary
- scale to zero the canary deployment and mark it as failed
- wait for the canary deployment to be updated and start over
- increase canary traffic weight by 5% (step weight) till it reaches 50% (max weight)
- halt advancement while canary request success rate is under the threshold
- halt advancement while canary request duration P99 is over the threshold
- halt advancement if the primary or canary deployment becomes unhealthy
- halt advancement while canary deployment is being scaled up/down by HPA
- promote canary to primary
- copy ConfigMaps and Secrets from canary to primary
- copy canary deployment spec template over primary
- wait for primary rolling update to finish
- halt advancement if pods are unhealthy
- route all traffic to primary
- scale to zero the canary deployment
- mark rollout as finished
- wait for the canary deployment to be updated and start over
You can change the canary analysis max weight and the step weight percentage in the Flagger's custom resource.
Create a test namespace with Istio sidecar injection enabled:
export REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
kubectl apply -f ${REPO}/artifacts/namespaces/test.yamlCreate a deployment and a horizontal pod autoscaler:
kubectl apply -f ${REPO}/artifacts/canaries/deployment.yaml
kubectl apply -f ${REPO}/artifacts/canaries/hpa.yamlDeploy the load testing service to generate traffic during the canary analysis:
kubectl -n test apply -f ${REPO}/artifacts/loadtester/deployment.yaml
kubectl -n test apply -f ${REPO}/artifacts/loadtester/service.yamlCreate a canary custom resource (replace example.com with your own domain):
apiVersion: flagger.app/v1alpha3
kind: Canary
metadata:
name: podinfo
namespace: test
spec:
# deployment reference
targetRef:
apiVersion: apps/v1
kind: Deployment
name: podinfo
# the maximum time in seconds for the canary deployment
# to make progress before it is rollback (default 600s)
progressDeadlineSeconds: 60
# HPA reference (optional)
autoscalerRef:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
name: podinfo
service:
# container port
port: 9898
trafficPolicy:
tls:
# use ISTIO_MUTUAL when mTLS is enabled
mode: DISABLE
# Istio gateways (optional)
gateways:
- public-gateway.istio-system.svc.cluster.local
- mesh
# Istio virtual service host names (optional)
hosts:
- app.example.com
canaryAnalysis:
# schedule interval (default 60s)
interval: 1m
# max number of failed metric checks before rollback
threshold: 5
# max traffic percentage routed to canary
# percentage (0-100)
maxWeight: 50
# canary increment step
# percentage (0-100)
stepWeight: 10
metrics:
- name: request-success-rate
# minimum req success rate (non 5xx responses)
# percentage (0-100)
threshold: 99
interval: 1m
- name: request-duration
# maximum req duration P99
# milliseconds
threshold: 500
interval: 30s
# generate traffic during analysis
webhooks:
- name: load-test
url: http://flagger-loadtester.test/
timeout: 5s
metadata:
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"Save the above resource as podinfo-canary.yaml and then apply it:
kubectl apply -f ./podinfo-canary.yamlAfter a couple of seconds Flagger will create the canary objects:
# applied
deployment.apps/podinfo
horizontalpodautoscaler.autoscaling/podinfo
canary.flagger.app/podinfo
# generated
deployment.apps/podinfo-primary
horizontalpodautoscaler.autoscaling/podinfo-primary
service/podinfo
service/podinfo-canary
service/podinfo-primary
virtualservice.networking.istio.io/podinfo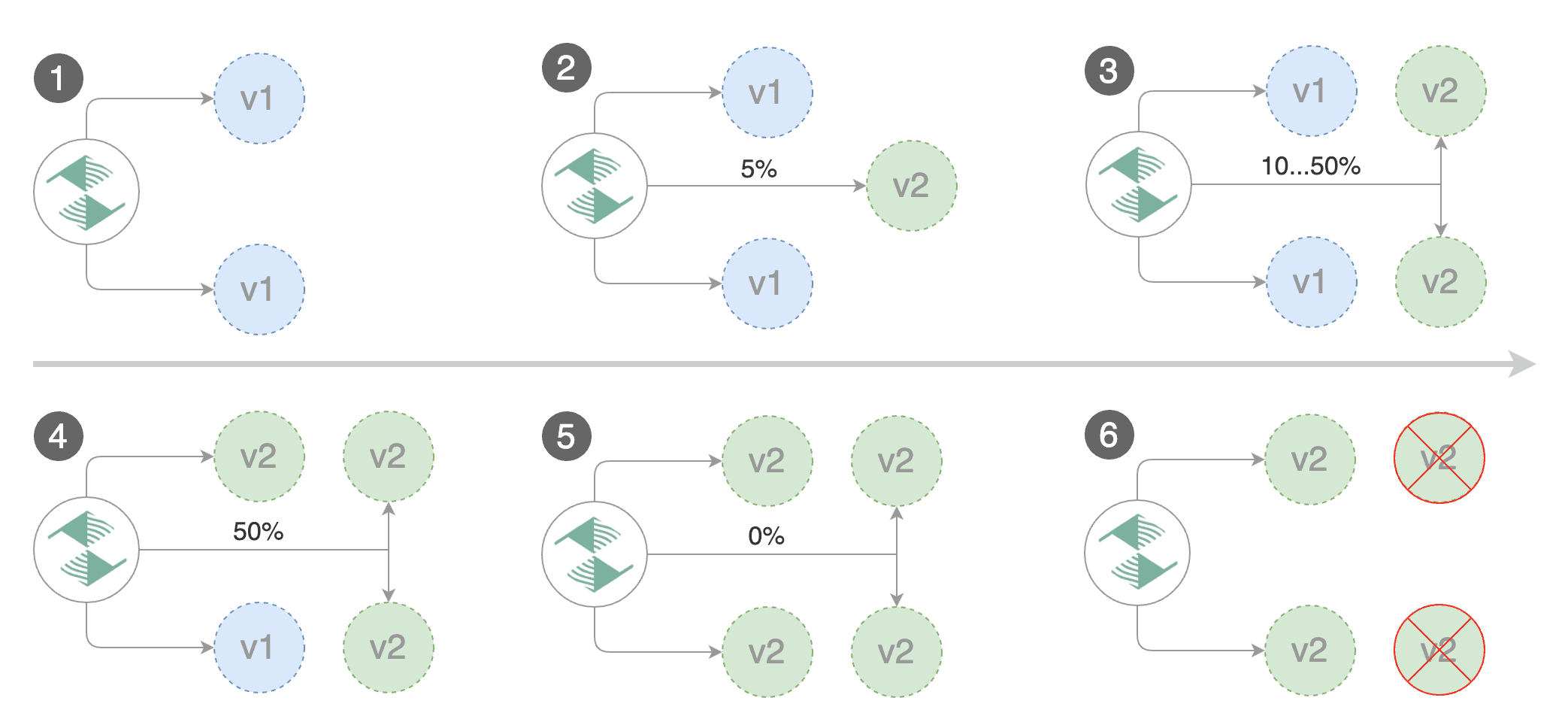
Trigger a canary deployment by updating the container image:
kubectl -n test set image deployment/podinfo \
podinfod=quay.io/stefanprodan/podinfo:1.4.1Flagger detects that the deployment revision changed and starts a new rollout:
kubectl -n test describe canary/podinfo
Status:
Canary Revision: 19871136
Failed Checks: 0
State: finished
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Synced 3m flagger New revision detected podinfo.test
Normal Synced 3m flagger Scaling up podinfo.test
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
Normal Synced 3m flagger Advance podinfo.test canary weight 5
Normal Synced 3m flagger Advance podinfo.test canary weight 10
Normal Synced 3m flagger Advance podinfo.test canary weight 15
Normal Synced 2m flagger Advance podinfo.test canary weight 20
Normal Synced 2m flagger Advance podinfo.test canary weight 25
Normal Synced 1m flagger Advance podinfo.test canary weight 30
Normal Synced 1m flagger Advance podinfo.test canary weight 35
Normal Synced 55s flagger Advance podinfo.test canary weight 40
Normal Synced 45s flagger Advance podinfo.test canary weight 45
Normal Synced 35s flagger Advance podinfo.test canary weight 50
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
Note that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
You can monitor all canaries with:
watch kubectl get canaries --all-namespaces
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
test podinfo Progressing 15 2019-01-16T14:05:07Z
prod frontend Succeeded 0 2019-01-15T16:15:07Z
prod backend Failed 0 2019-01-14T17:05:07ZDuring the canary analysis you can generate HTTP 500 errors and high latency to test if Flagger pauses the rollout.
Create a tester pod and exec into it:
kubectl -n test run tester --image=quay.io/stefanprodan/podinfo:1.2.1 -- ./podinfo --port=9898
kubectl -n test exec -it tester-xx-xx shGenerate HTTP 500 errors:
watch curl http://podinfo-canary:9898/status/500Generate latency:
watch curl http://podinfo-canary:9898/delay/1When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
kubectl -n test describe canary/podinfo
Status:
Canary Revision: 16695041
Failed Checks: 10
State: failed
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Synced 3m flagger Starting canary deployment for podinfo.test
Normal Synced 3m flagger Advance podinfo.test canary weight 5
Normal Synced 3m flagger Advance podinfo.test canary weight 10
Normal Synced 3m flagger Advance podinfo.test canary weight 15
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
Normal Synced 2m flagger Halt podinfo.test advancement success rate 55.06% < 99%
Normal Synced 2m flagger Halt podinfo.test advancement success rate 47.00% < 99%
Normal Synced 2m flagger (combined from similar events): Halt podinfo.test advancement success rate 38.08% < 99%
Warning Synced 1m flagger Rolling back podinfo.test failed checks threshold reached 10
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
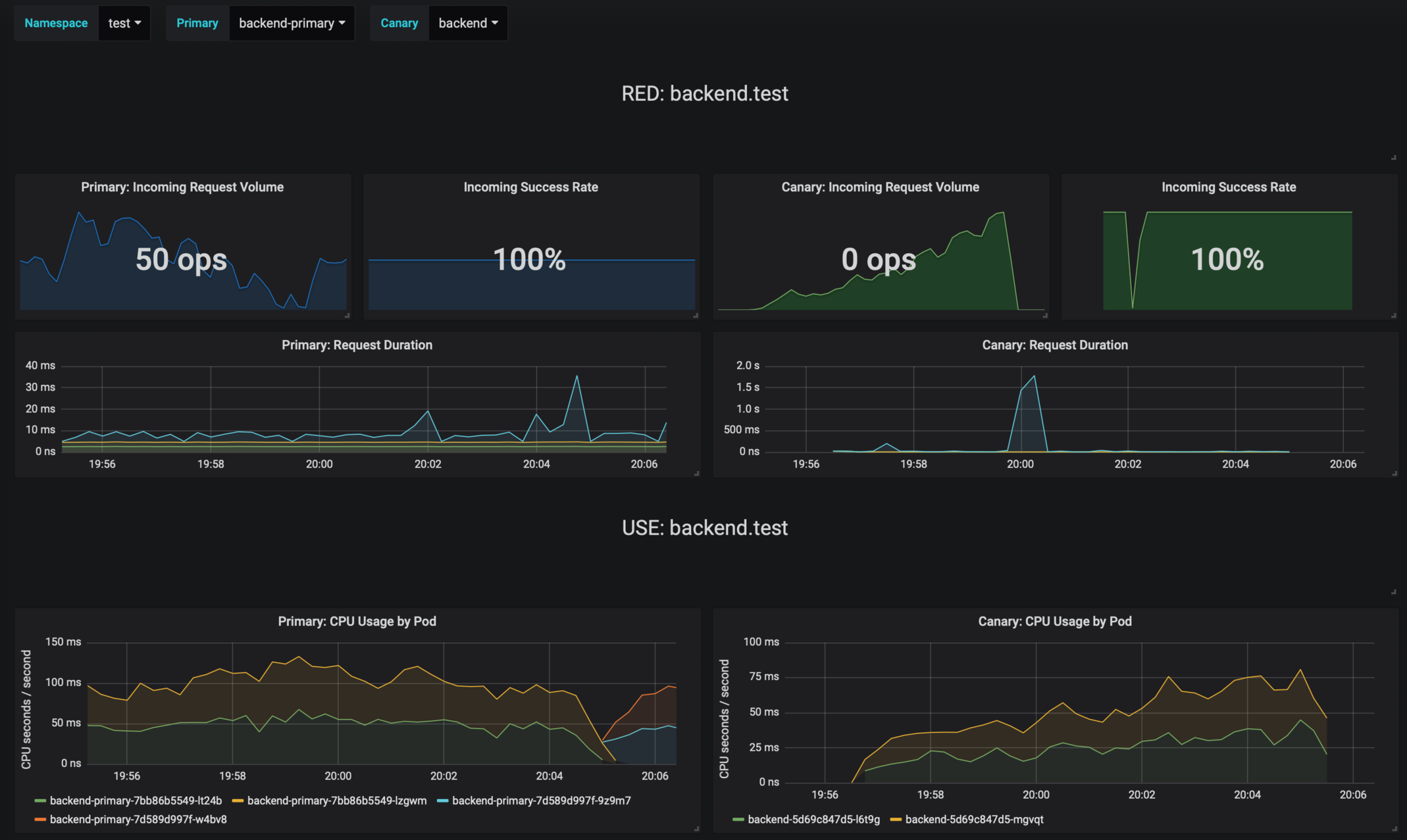
Flagger comes with a Grafana dashboard made for canary analysis.
Install Grafana with Helm:
helm upgrade -i flagger-grafana flagger/grafana \
--namespace=istio-system \
--set url=http://prometheus.istio-system:9090The dashboard shows the RED and USE metrics for the primary and canary workloads:
The canary errors and latency spikes have been recorded as Kubernetes events and logged by Flagger in json format:
kubectl -n istio-system logs deployment/flagger --tail=100 | jq .msg
Starting canary deployment for podinfo.test
Advance podinfo.test canary weight 5
Advance podinfo.test canary weight 10
Advance podinfo.test canary weight 15
Advance podinfo.test canary weight 20
Advance podinfo.test canary weight 25
Advance podinfo.test canary weight 30
Advance podinfo.test canary weight 35
Halt podinfo.test advancement success rate 98.69% < 99%
Advance podinfo.test canary weight 40
Halt podinfo.test advancement request duration 1.515s > 500ms
Advance podinfo.test canary weight 45
Advance podinfo.test canary weight 50
Copying podinfo.test template spec to podinfo-primary.test
Halt podinfo-primary.test advancement waiting for rollout to finish: 1 old replicas are pending termination
Scaling down podinfo.test
Promotion completed! podinfo.test
Flagger can be configured to send Slack notifications:
helm upgrade -i flagger flagger/flagger \
--namespace=istio-system \
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
--set slack.channel=general \
--set slack.user=flaggerOnce configured with a Slack incoming webhook, Flagger will post messages when a canary deployment has been initialized, when a new revision has been detected and if the canary analysis failed or succeeded.

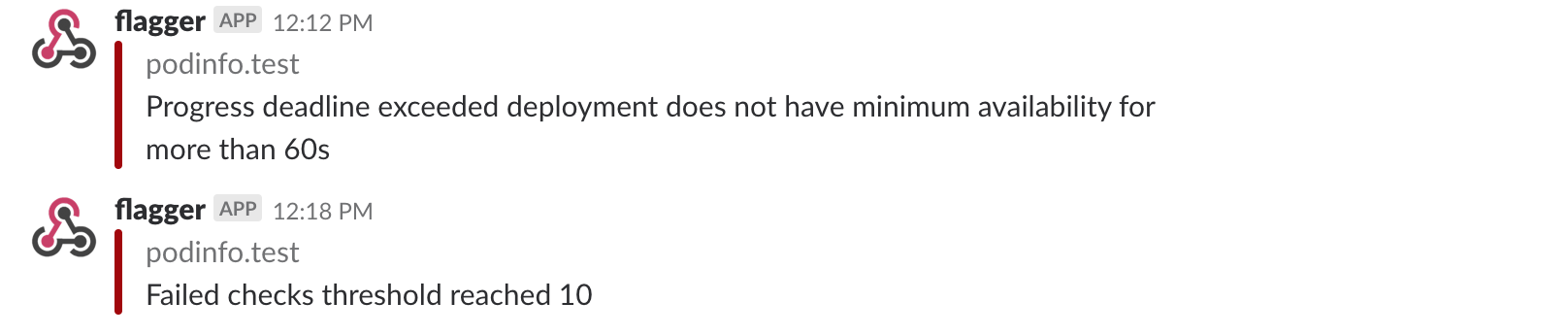
A canary deployment will be rolled back if the progress deadline exceeded or if the analysis reached the maximum number of failed checks:
Besides Slack, you can use Alertmanager to trigger alerts when a canary deployment failed:
- alert: canary_rollback
expr: flagger_canary_status > 1
for: 1m
labels:
severity: warning
annotations:
summary: "Canary failed"
description: "Workload {{ $labels.name }} namespace {{ $labels.namespace }}"Next: A/B Testing with Helm