David HURTADO & Zijie NING
-
Basic concepts of recurrent networks
A recurrent neural network (RNN) is a neural network that is specialized for processing a sequence of values
$\boldsymbol{x}^{(1)}, \ldots, \boldsymbol{x}^{(\tau)}$ .E.g. Given list of word vectors:
$x_{1}, \ldots, x_{t-1}, x_{t}, x_{t+1}, \ldots, x_{T}$ At a single time step, the output depends on the previous state ($h_{t-1}$ ) and the current input ($h_t$ ): $$ \begin{aligned} h_{t} &=\sigma\left(W^{(h h)} h_{t-1}+W^{(h x)} x_{[t]}\right) \ \hat{y}{t} &=\operatorname{softmax}\left(W^{(S)} h{t}\right) \end{aligned} $$$$ \hat{P}\left(x_{t+1}=v_{j} \mid x_{t}, \ldots, x_{1}\right)=\hat{y}_{t, j} $$

The core idea is that the state of the previous moment also affects the output of the current moment.
Problem: Vanishing or exploding gradient
-
Why?
The difficulty with long-term dependencies arises from the exponentially smaller weights given to long-term interactions (involving the multiplication of many Jacobians) compared to short-term ones.
Because each derivative is either bigger or lesser than 1, when we take the furthest words into account, due to a huge amount of multiplications during the backpropagation, the gradient will tend to zero or infinity.
-
How to solve
-
Identity matrix initialization (Vanishing)
Instead of randomly initializing the weight matrix, we use the identity matrix to learn long-range dependencies or a scaled one to forget long range effects. A Simple Way to Initialize Recurrent Networks of Rectified Linear Units, Quoc V. Le, Navdeep Jaitly, Geoffrey E. Hinton
-
Clipping Gradient (Exploding)
-
LSTM & GRU (Both)
-
-
-
Link with the Markov assumption
Although the forecast should base on every word before, we assume that a small window of previous words is enough. $$ P\left(w_{1}, \ldots, w_{m}\right)=\prod_{i=1}^{m} P\left(w_{i} \mid w_{1}, \ldots, w_{i-1}\right) \approx \prod_{i=1}^{m} P\left(w_{i} \mid w_{i-(n-1)}, \ldots, w_{i-1}\right) $$
-
Different RNN architectures (GRU, LSTM) and interests
-
LSTM Invented on 1997
Interest: Solve the problem of vanishing or exploding gradient
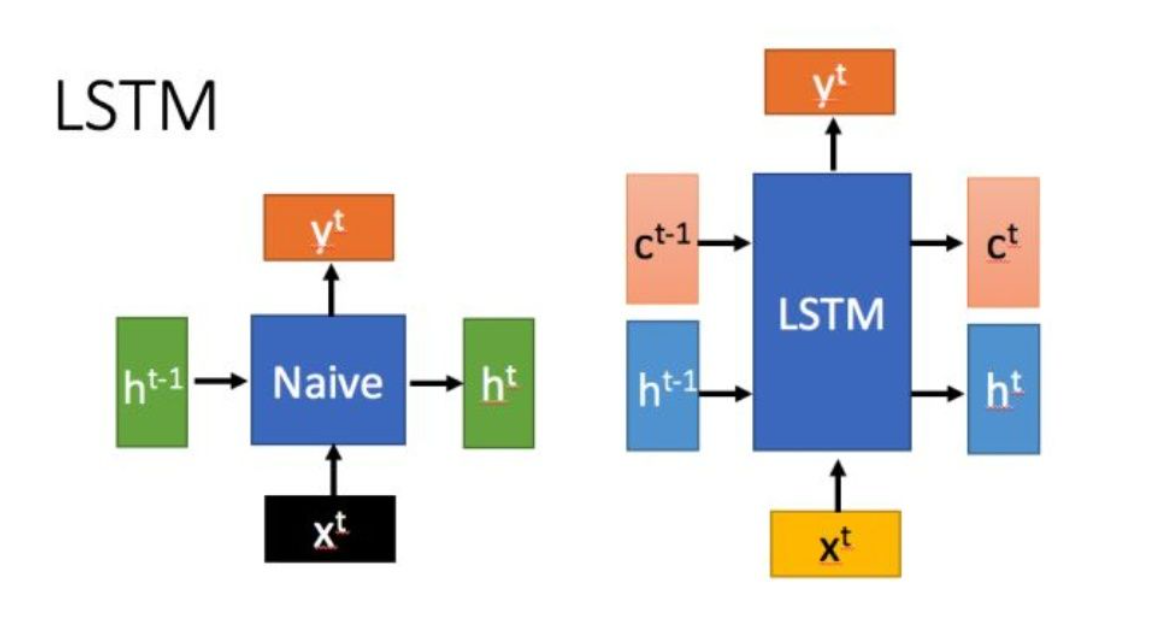
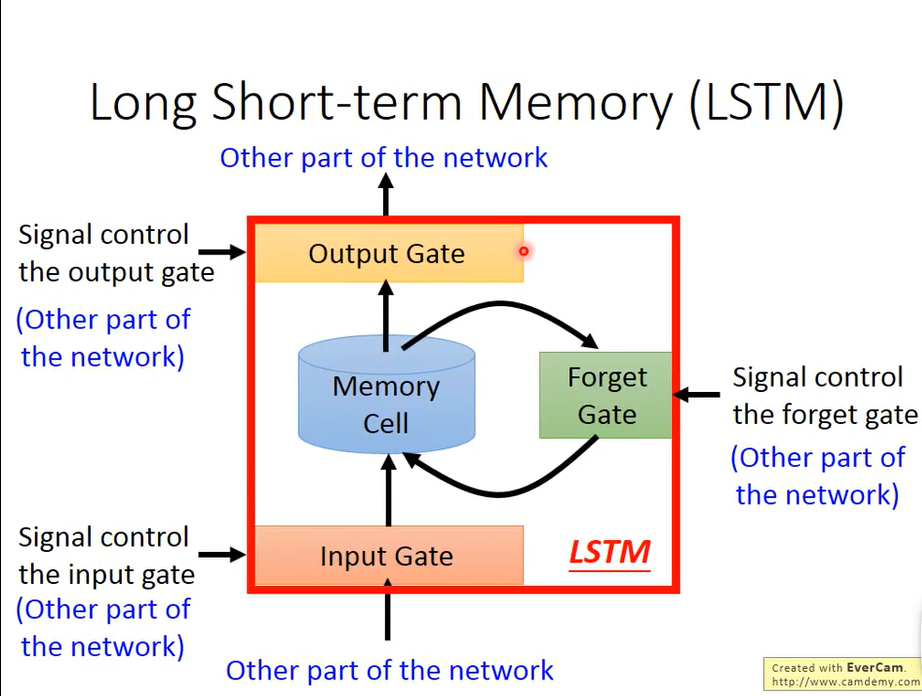
-
GRU: Gated Recurrent Units
Invented on 2014
The main difference with the LSTM is that a single gating unit simultaneously controls the forgetting factor and the decision to update the state unit.
We choose to use Gated Recurrent Unit (GRU) (Cho et al., 2014) in our experiment since it performs similarly to LSTM (Hochreiter & Schmidhuber, 1997) but is computationally cheaper.
--- Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling(Chung et al., 2014)
-
-
Case studies (language, time series forecasting)
-
Nature language processing
Word prediction, machine translation, speech recognition.
-
Time series forecasting
Time series forecasting occurs when you make scientific predictions based on historical time stamped data.
-
-
Chapter 10 Goodfellow et al.: https://www.deeplearningbook.org/contents/rnn.html