This repo has been deprecated. Here is the complete codes for training Faster-RCNN on your data and using the pre-trained Faster-RCNN model for new data: ChainerCV
This is an experimental implementation of Faster R-CNN in Chainer based on Ross Girshick's work: py-faster-rcnn codes.
Using anaconda is strongly recommended.
-
Python 2.7.6+, 3.4.3+, 3.5.1+
- Chainer 1.22.0+
- NumPy 1.9, 1.10, 1.11
- Cython 0.25+
- OpenCV 2.9+, 3.1+
pip install numpy
pip install cython
pip install chainer
pip install chainercv
# for python3
conda install -c https://conda.binstar.org/menpo opencv3
# for python2
conda install opencv
There's a known problem in cpu_nms.pyx. But a workaround has been posted here (and see also the issue posted to the original py-faster-rcnn).
python setup.py build_ext -i
if [ ! -d data ]; then mkdir data; fi
curl https://dl.dropboxusercontent.com/u/2498135/faster-rcnn/VGG16_faster_rcnn_final.model?dl=1 -o data/VGG16_faster_rcnn_final.model
NOTE: The model definition in faster_rcnn.py has been changed, so if you already have the older pre-trained model file, please download it again to replace the older one with the new one.
curl -O http://vision.cs.utexas.edu/voc/VOC2007_test/JPEGImages/004545.jpg
python forward.py --img_fn 004545.jpg --gpu 0
--gpu 0 turns on GPU. When you turn off GPU, use --gpu -1 or remove --gpu option.

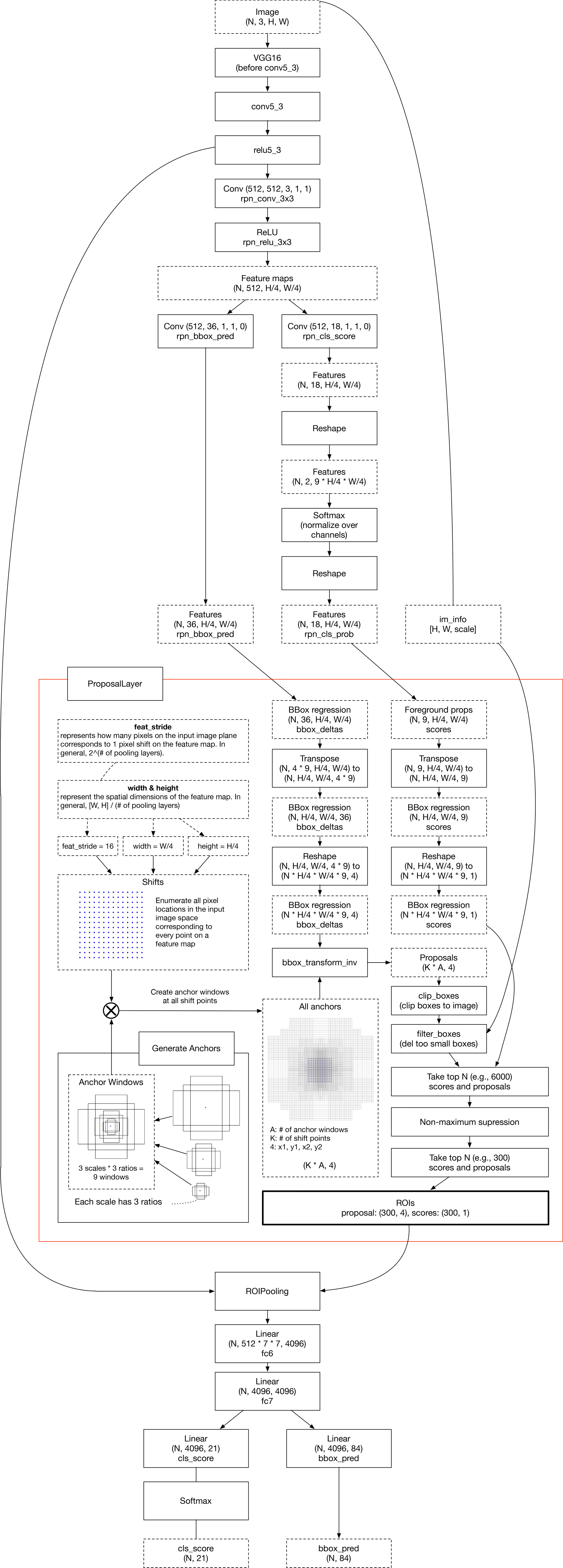
Summarization of Faster R-CNN layers used during inference
The region proposal layer (RPN) is consisted of AnchorTargetLayer and ProposalLayer. RPN takes feature maps from trunk network like VGG-16, and performs 3x3 convolution to it. Then, it applies two independent 1x1 convolutions to the output of the first 3x3 convolution. Resulting outputs are rpn_cls_score and rpn_bbox_pred.
- The shape of
rpn_cls_scoreis(N, 2 * n_anchors, 14, 14)because each pixel on the feature map hasn_anchorsbboxes and each bbox should have 2 values that mean object/background. - The shape of
rpn_bbox_predis(N, 4 * n_anchors, 14, 14)because each pixel on the feature map hasn_anchorsbboxes, and each bbox is represented with 4 values that mean left topxandy,widthandheight.
ChainerCV is a utility library enables Chainer to treat various datasets easily. It also provides some transformation utility for data augmentation, and includes some standard algorithms for some comptuer vision tasks. Check the repo to know details. Here I use (VOCDetectionDataset)[http://chainercv.readthedocs.io/en/latest/reference/datasets.html#vocdetectiondataset] of ChainerCV. Anyway, before starting training of FasterRCNN, please install ChainerCV via pip.
pip install chainercv
python train_rpn.py
Note that it is a visualization of the workflow DURING INFERENCE