diff --git a/chapters/ko/_toctree.yml b/chapters/ko/_toctree.yml
index 36c0fc4f..ab3a6105 100644
--- a/chapters/ko/_toctree.yml
+++ b/chapters/ko/_toctree.yml
@@ -36,7 +36,23 @@
- local: chapter2/hands_on
title: 실습 과제
+- title: 3단원. 오디오용 트랜스포머 아키텍처
+ sections:
+ - local: chapter3/introduction
+ title: 트랜스퍼모델 돌아보기
+ - local: chapter3/ctc
+ title: CTC 아키텍처
+ - local: chapter3/seq2seq
+ title: Seq2Seq 아키텍처
+ - local: chapter3/classification
+ title: 오디오 분류 아키텍처
+ - local: chapter3/quiz
+ title: 퀴즈
+ quiz: 3
+ - local: chapter3/supplemental_reading
+ title: 보충자료 및 리소스
+
- title: 코스 이벤트
sections:
- local: events/introduction
- title: 라이브 세션과 워크샵
+ title: 라이브 세션과 워크샵
\ No newline at end of file
diff --git a/chapters/ko/chapter3/classification.mdx b/chapters/ko/chapter3/classification.mdx
new file mode 100644
index 00000000..38f39e5f
--- /dev/null
+++ b/chapters/ko/chapter3/classification.mdx
@@ -0,0 +1,35 @@
+# 오디오 분류 아키텍처[[audio-classification-architectures]]
+
+오디오 분류의 목표는 오디오 입력에 대한 클래스 레이블을 예측하는 것입니다. 모델은 전체 입력 시퀀스를 포괄하는 단일 클래스 레이블을 예측하거나 모든 오디오 프레임(일반적으로 입력 오디오의 20밀리초마다)에 대한 레이블을 예측할 수 있으며, 이 경우 모델의 출력은 클래스 레이블 확률의 시퀀스입니다. 전자의 예로는 어떤 새가 특정 소리를 내는지 감지하는 것을 들 수 있고, 후자의 예로는 특정 순간에 어떤 화자가 말하는지 예측하는 화자 구분(speaker diarization)을 들 수 있습니다.
+
+## 스펙트로그램을 사용한 분류[[classification-using-spectrograms]]
+
+오디오 분류를 수행하는 가장 쉬운 방법 중 하나는 이미지 분류 문제인 것처럼 가정하는 것입니다!
+
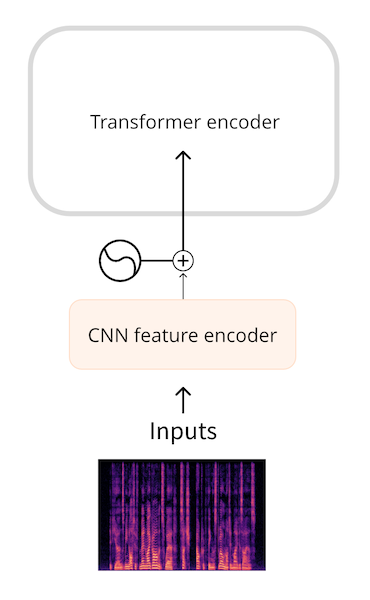
+스펙트로그램은 `(주파수, 시퀀스 길이)` 모양의 2차원 텐서라는 것을 기억하세요. [오디오 데이터 챕터](../chapter1/audio_data)에서 이러한 스펙트로그램을 이미지로 그려보았습니다. 여러분 아시나요? 말 그대로 스펙트로그램을 이미지로 취급하고 ResNet과 같은 일반 CNN 분류기 모델에 전달하면 매우 좋은 예측 결과를 얻을 수 있습니다. 더 좋은 방법은 ViT와 같은 이미지 트랜스포머 모델을 사용하는 것입니다.
+
+이것이 바로 **오디오 스펙트로그램 트랜스포머**가 하는 일입니다. 이 모델은 ViT 또는 비전 트랜스포머 모델을 사용하며, 일반 이미지 대신 스펙트로그램을 입력으로 전달합니다. 트랜스포머의 셀프 어텐션 레이어 덕분에 이 모델은 CNN보다 글로벌 컨텍스트를 더 잘 포착할 수 있습니다.
+
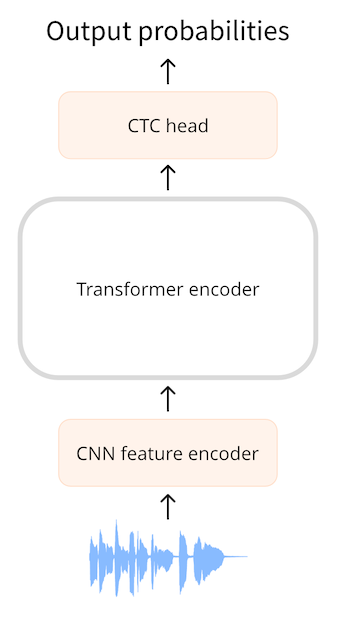
+ViT와 마찬가지로 AST(Audio Spectrogram Transformer) 모델은 오디오 스펙트로그램을 16×16픽셀의 부분적으로 겹치는 이미지 패치 시퀀스로 분할합니다. 그런 다음 이 패치 시퀀스는 일련의 임베딩으로 투영되고, 이 임베딩은 평소와 같이 트랜스포머 인코더에 입력으로 제공됩니다. AST는 인코더 전용 트랜스포머 모델이므로 출력은 16×16 입력 패치마다 하나씩 숨겨진 상태 시퀀스입니다. 여기에는 은닉 상태를 분류 확률에 매핑하기 위해 시그모이드 활성화가 포함된 간단한 분류 계층이 있습니다.
+
+
+

+
+
+
+

+
+

+
+
+
+
+
+
+
+
+
+

+
+

+