From 5b03366de0ab054d646b732a1b9280f2762b06cb Mon Sep 17 00:00:00 2001
From: kaleo <1311766212@qq.com>
Date: Tue, 26 Mar 2024 11:11:08 +0800
Subject: [PATCH 1/2] translated zh-CN chapter 6
---
chapters/zh-CN/_toctree.yml | 39 +-
chapters/zh-CN/chapter6/evaluation.mdx | 18 +
chapters/zh-CN/chapter6/fine-tuning.mdx | 557 ++++++++++++++++++
chapters/zh-CN/chapter6/hands_on.mdx | 15 +
chapters/zh-CN/chapter6/introduction.mdx | 21 +
.../zh-CN/chapter6/pre-trained_models.mdx | 374 ++++++++++++
.../zh-CN/chapter6/supplemental_reading.mdx | 8 +
chapters/zh-CN/chapter6/tts_datasets.mdx | 54 ++
8 files changed, 1063 insertions(+), 23 deletions(-)
create mode 100644 chapters/zh-CN/chapter6/evaluation.mdx
create mode 100644 chapters/zh-CN/chapter6/fine-tuning.mdx
create mode 100644 chapters/zh-CN/chapter6/hands_on.mdx
create mode 100644 chapters/zh-CN/chapter6/introduction.mdx
create mode 100644 chapters/zh-CN/chapter6/pre-trained_models.mdx
create mode 100644 chapters/zh-CN/chapter6/supplemental_reading.mdx
create mode 100644 chapters/zh-CN/chapter6/tts_datasets.mdx
diff --git a/chapters/zh-CN/_toctree.yml b/chapters/zh-CN/_toctree.yml
index fb952a1..9da7016 100644
--- a/chapters/zh-CN/_toctree.yml
+++ b/chapters/zh-CN/_toctree.yml
@@ -84,29 +84,22 @@
- local: chapter5/supplemental_reading
title: 补充阅读
-#- title: 第6单元:由文字合成语音(TTS)
-# sections:
-# - local: chapter6/introduction
-# title: 单元简介
-# - local: chapter6/overview
-# title: 如何从文字合成语音
-# - local: chapter6/choosing_dataset
-# title: 数据集选择
-# - local: chapter6/preprocessing
-# title: 数据加载和预处理
-# - local: chapter6/pre-trained_models
-# title: 文字转语音(TTS)预训练模型
-# - local: chapter6/evaluation
-# title: 文字转语音(TTS)的评价指标
-# - local: chapter6/fine-tuning
-# title: SpeechT5模型的微调
-# - local: chapter6/quiz
-# title: 习题
-# quiz: 6
-# - local: chapter6/hands_on
-# title: 实战练习
-# - local: chapter6/supplemental_reading
-# title: 补充材料
+- title: 第六单元:从文本到语音
+ sections:
+ - local: chapter6/introduction
+ title: 单元简介
+ - local: chapter6/tts_datasets
+ title: 语音合成数据集
+ - local: chapter6/pre-trained_models
+ title: 语音合成的预训练模型
+ - local: chapter6/fine-tuning
+ title: 微调 SpeechT5
+ - local: chapter6/evaluation
+ title: 评估语音合成模型
+ - local: chapter6/hands_on
+ title: 实战练习
+ - local: chapter6/supplemental_reading
+ title: 补充阅读
#
#- title: 第7单元:音频到音频合成(ATA)
# sections:
diff --git a/chapters/zh-CN/chapter6/evaluation.mdx b/chapters/zh-CN/chapter6/evaluation.mdx
new file mode 100644
index 0000000..06306ab
--- /dev/null
+++ b/chapters/zh-CN/chapter6/evaluation.mdx
@@ -0,0 +1,18 @@
+# 评估语音合成模型
+
+在训练期间,语音合成模型旨在优化平均平方误差损失(mean-square error loss,简称 MSE)或平均绝对误差(mean absolute error,简称 MAE),
+这两者衡量的是预测的频谱图和真正的频谱图之间的差异。MSE 和 MAE 都鼓励模型最小化预测和目标频谱图之间的差异。然而,由于 TTS 是一种一对多映射问题,
+即给定文本的输出频谱图有多种可能性,所以评估语音合成模型要比预想的困难得多。
+
+与许多其他可以使用定量指标(如准确率、精确度)客观衡量的计算任务不同,评估 TTS 主要依赖于主观的人类分析。
+
+评估 TTS 系统最常用方法之一是通过平均意见得分(Mean Opinion Scores,简称 MOS)进行定性评估。MOS 是一种主观评分系统,
+允许人类评估者对合成语音的感知质量进行评分,评分范围从 1 到 5。这些得分通常通过听力测试收集,参与者听取并评价合成语音样本。
+
+对于 TTS 评估来说,设置客观指标困难的主要原因之一是语音感知的主观性。不同的人类听众对语音的不同方面,包括发音、语调、自然度和清晰度,
+有着各自的偏好和敏感度。用单一的数值捕捉这些感知细微差别是一项艰巨的任务。同时,人类评估的主观性使得比较和基准测试不同的 TTS 系统变得困难。
+
+此外,这种评估可能会忽视语音合成的某些重要方面,如自然度、表达力和情感影响。这些质量难以客观量化,但在需要合成语音达到类人的品质和引发适当情感反应的应用中至关重要。
+
+总之,由于缺乏一个真正客观的指标,评估语音合成模型是一项复杂的任务。最常用的评估方法,即平均意见得分(MOS),依赖于主观的人类分析。
+尽管 MOS 提供了对合成语音质量的宝贵意见,但它也引入了不确定性和主观性。
diff --git a/chapters/zh-CN/chapter6/fine-tuning.mdx b/chapters/zh-CN/chapter6/fine-tuning.mdx
new file mode 100644
index 0000000..7cf5a8b
--- /dev/null
+++ b/chapters/zh-CN/chapter6/fine-tuning.mdx
@@ -0,0 +1,557 @@
+# 微调 SpeechT5
+
+现在您已经熟悉了语音合成任务和 SpeechT5 模型的内部工作原理,该模型是在英语数据上预训练的,让我们看看如何将其微调到另一种语言。
+
+## 基础准备
+
+如果您想复现这个示例,请确保您有一个 GPU。在笔记本中,您可以使用以下命令检查:
+
+```bash
+nvidia-smi
+```
+
+
+
+在我们的示例中,我们将使用大约 40 小时的训练数据。如果您想使用 Google Colab 免费版的 GPU 复现,需要将训练数据量减少到大约 10-15 小时,并减少训练步骤的数量。
+
+
+
+您还需要一些额外的依赖:
+
+```bash
+pip install transformers datasets soundfile speechbrain accelerate
+```
+
+最后,不要忘记登录您的 Hugging Face 账户,以便您能够上传并与社区共享您的模型:
+
+```py
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+## 数据集
+
+在这个示例中,我们将使用 [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) 数据集的荷兰语(`nl`)子集。
+[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) 是一个大规模的多语言语音语料库,包含了 2009-2020 年欧洲议会事件的录音数据。
+它包含 15 种欧洲语言的带标签的音频-转写数据。虽然我们将使用荷兰语子集,但您可以自由选择其他子集。
+
+这是一个语音识别(ASR)数据集,所以,如前所述,它不是训练 TTS 模型的最佳选择。然而,对于这个练习来说,它已经足够好了。
+
+让我们加载数据:
+
+```python
+from datasets import load_dataset, Audio
+
+dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
+len(dataset)
+```
+
+**输出:**
+
+```out
+20968
+```
+
+20968 条数据应该足以进行微调。输入 SpeechT5 的音频数据应具有 16 kHz 的采样率,所以要确保我们的数据集满足这一要求:
+
+```python
+dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
+```
+
+## 数据预处理
+
+处理器包含了分词器和特征提取器,我们需要用它们来预处理训练数据。所以我们先定义要使用的模型检查点,并加载对应的处理器:
+
+```py
+from transformers import SpeechT5Processor
+
+checkpoint = "microsoft/speecht5_tts"
+processor = SpeechT5Processor.from_pretrained(checkpoint)
+```
+
+### 为 SpeechT5 分词进行文本清理
+
+首先,为了处理文本,我们需要处理器的分词器部分,所以让我们来获取它:
+
+```py
+tokenizer = processor.tokenizer
+```
+
+让我们看一个示例:
+
+```python
+dataset[0]
+```
+
+**输出:**
+
+```out
+{'audio_id': '20100210-0900-PLENARY-3-nl_20100210-09:06:43_4',
+ 'language': 9,
+ 'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/02ec6a19d5b97c03e1379250378454dbf3fa2972943504a91c7da5045aa26a89/train_part_0/20100210-0900-PLENARY-3-nl_20100210-09:06:43_4.wav',
+ 'array': array([ 4.27246094e-04, 1.31225586e-03, 1.03759766e-03, ...,
+ -9.15527344e-05, 7.62939453e-04, -2.44140625e-04]),
+ 'sampling_rate': 16000},
+ 'raw_text': 'Dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
+ 'normalized_text': 'dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
+ 'gender': 'female',
+ 'speaker_id': '1122',
+ 'is_gold_transcript': True,
+ 'accent': 'None'}
+```
+
+您可能会注意到数据包含 `raw_text` 和 `normalized_text` 特征。在决定使用哪个特征作为文本输入时,需要注意的是 SpeechT5 分词器没有任何数字的词元。
+在 `normalized_text` 中,数字被写成文本。因此,它更合适,我们应该使用 `normalized_text` 作为输入文本。
+
+因为 SpeechT5 是在英语上训练的,它可能无法识别荷兰语数据集中的某些字符。如果保持原样,这些字符将被转换为 `` 词元。
+然而,在荷兰语中,某些字符如 `à` 用于强调音节。为了保留文本的含义,我们可以将此字符替换为普通的 `a`。
+
+要识别不支持的词元,使用 `SpeechT5Tokenizer` 提取数据集中所有独特字符,该分词器将字符视为词元。为此,我们将编写 `extract_all_chars` 映射函数,
+该函数将所有数据样例的转写连接成一个字符串,然后转换为字符集。确保在 `dataset.map()` 中设置 `batched=True` 和 `batch_size=-1`,以便一次性获取所有转写并输入映射函数。
+
+```py
+def extract_all_chars(batch):
+ all_text = " ".join(batch["normalized_text"])
+ vocab = list(set(all_text))
+ return {"vocab": [vocab], "all_text": [all_text]}
+
+
+vocabs = dataset.map(
+ extract_all_chars,
+ batched=True,
+ batch_size=-1,
+ keep_in_memory=True,
+ remove_columns=dataset.column_names,
+)
+
+dataset_vocab = set(vocabs["vocab"][0])
+tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
+```
+
+现在您有两组字符:一个来自数据集,另一个来自分词器。要识别数据集中任何不支持的字符,您可以取这两组的差集,结果将包含在数据集中而不在分词器中的字符。
+
+```py
+dataset_vocab - tokenizer_vocab
+```
+
+**输出:**
+
+```out
+{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
+```
+
+为了处理上一步骤中识别的不支持字符,我们可以定义一个将这些字符映射到有效词元的函数。注意,分词器中的空格已经被替换为 `▁`,因此不需要单独处理。
+
+```py
+replacements = [
+ ("à", "a"),
+ ("ç", "c"),
+ ("è", "e"),
+ ("ë", "e"),
+ ("í", "i"),
+ ("ï", "i"),
+ ("ö", "o"),
+ ("ü", "u"),
+]
+
+
+def cleanup_text(inputs):
+ for src, dst in replacements:
+ inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
+ return inputs
+
+
+dataset = dataset.map(cleanup_text)
+```
+
+现在我们处理好了文本中的特殊字符,是时候将注意力转移到音频数据上了。
+
+### 说话人
+
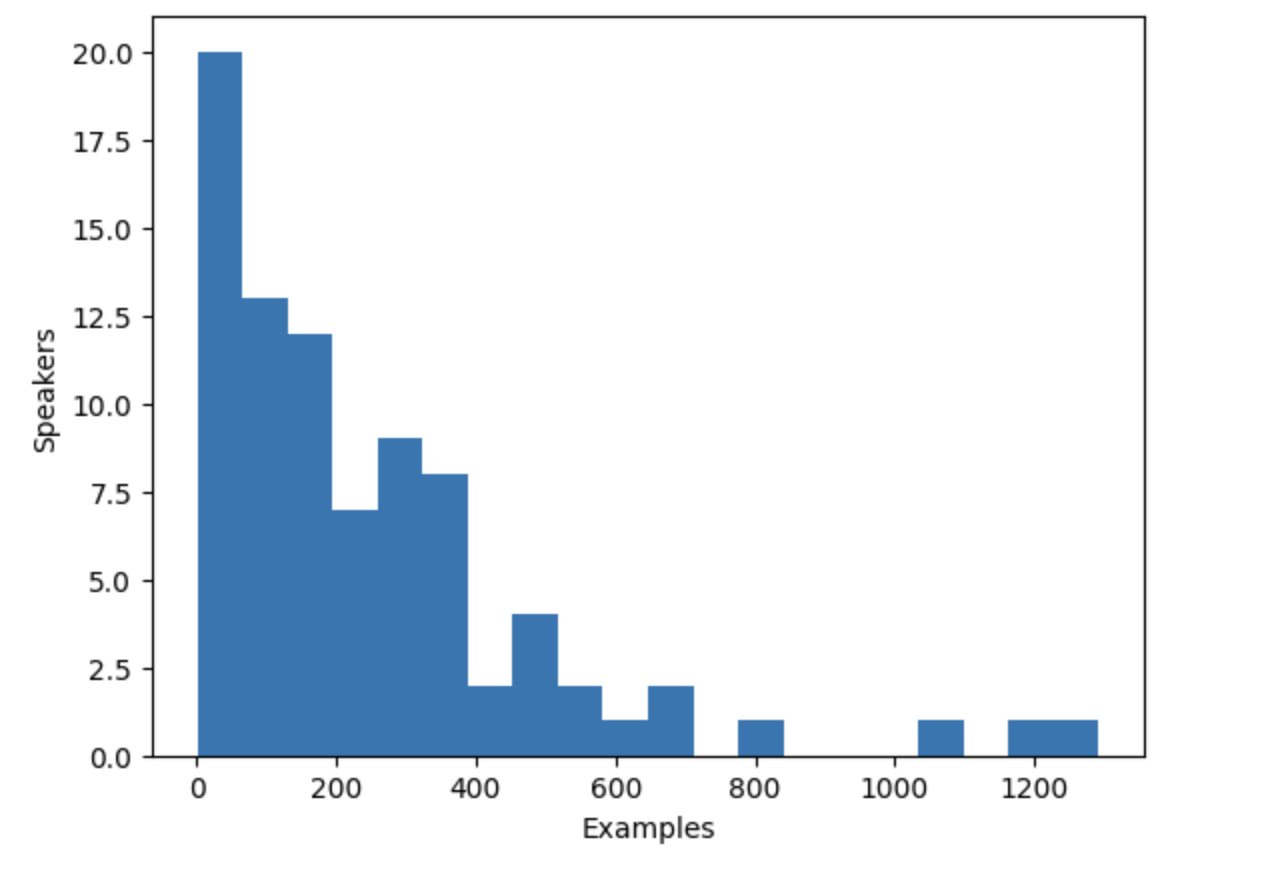
+VoxPopuli 数据集包含多个说话人的语音,但到底有多少呢?我们可以计算一下数据集中说话人的数量以及每个说话人贡献的数据量。
+数据集总共有 20,968 条数据,这些信息将帮助我们更好地了解数据中的说话人和数据样例的分布。
+
+```py
+from collections import defaultdict
+
+speaker_counts = defaultdict(int)
+
+for speaker_id in dataset["speaker_id"]:
+ speaker_counts[speaker_id] += 1
+```
+
+通过绘制直方图,您可以了解每个说话人的数据量。
+
+```py
+import matplotlib.pyplot as plt
+
+plt.figure()
+plt.hist(speaker_counts.values(), bins=20)
+plt.ylabel("Speakers")
+plt.xlabel("Examples")
+plt.show()
+```
+
+
+
+
+
+
+
+
+
+