diff --git a/.github/workflows/build_documentation.yml b/.github/workflows/build_documentation.yml
index c2cec95b..8894ae6a 100644
--- a/.github/workflows/build_documentation.yml
+++ b/.github/workflows/build_documentation.yml
@@ -14,7 +14,7 @@ jobs:
package_name: audio-course
path_to_docs: audio-transformers-course/chapters/
additional_args: --not_python_module
- languages: en bn
+ languages: en bn ko
secrets:
token: ${{ secrets.HUGGINGFACE_PUSH }}
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
diff --git a/.github/workflows/build_pr_documentation.yml b/.github/workflows/build_pr_documentation.yml
index d617e385..f036e750 100644
--- a/.github/workflows/build_pr_documentation.yml
+++ b/.github/workflows/build_pr_documentation.yml
@@ -17,4 +17,4 @@ jobs:
package_name: audio-course
path_to_docs: audio-transformers-course/chapters/
additional_args: --not_python_module
- languages: en bn
\ No newline at end of file
+ languages: en bn ko
diff --git a/chapters/ko/_toctree.yml b/chapters/ko/_toctree.yml
new file mode 100644
index 00000000..36c0fc4f
--- /dev/null
+++ b/chapters/ko/_toctree.yml
@@ -0,0 +1,42 @@
+- title: 0단원. 코스에 오신 것을 환영합니다!
+ sections:
+ - local: chapter0/introduction
+ title: 이 코스에서 기대할 수 있는 것들
+ - local: chapter0/get_ready
+ title: 준비하기
+ - local: chapter0/community
+ title: 커뮤니티에 참여하기
+
+- title: 1단원. 오디오 데이터 다루기
+ sections:
+ - local: chapter1/introduction
+ title: 학습할 내용들
+ - local: chapter1/audio_data
+ title: 오디오 데이터에 대하여
+ - local: chapter1/load_and_explore
+ title: 오디오 데이터셋 불러오기 및 탐색하기
+ - local: chapter1/preprocessing
+ title: 오디오 데이터 전처리하기
+ - local: chapter1/streaming
+ title: 오디오 데이터 스트리밍하기
+ - local: chapter1/quiz
+ title: 퀴즈
+ quiz: 1
+ - local: chapter1/supplemental_reading
+ title: 참고자료들
+
+- title: 2단원. 오디오의 응용에 대한 소개
+ sections:
+ - local: chapter2/introduction
+ title: 오디오의 응용 개요
+ - local: chapter2/audio_classification_pipeline
+ title: 파이프라인을 이용한 오디오 분류
+ - local: chapter2/asr_pipeline
+ title: 파이프라인을 이용한 자동 음성 인식
+ - local: chapter2/hands_on
+ title: 실습 과제
+
+- title: 코스 이벤트
+ sections:
+ - local: events/introduction
+ title: 라이브 세션과 워크샵
diff --git a/chapters/ko/chapter0/community.mdx b/chapters/ko/chapter0/community.mdx
new file mode 100644
index 00000000..2603e4bb
--- /dev/null
+++ b/chapters/ko/chapter0/community.mdx
@@ -0,0 +1,26 @@
+# 커뮤니티에 참여해보세요![[join-the-community]]
+
+[활발하고 지원이 풍부한 우리의 디스코드 커뮤니티](http://hf.co/join/discord)에 여러분을 초대합니다. 여러분은 이곳에서 같은 생각을 가진 학습자들을 만나고, 아이디어를 교환하며, 실습 과제에 대한 소중한 피드백을 받으실 수 있습니다. 질문을 하고, 자료를 공유하며 다른 사람들과 협력을 해보세요.
+
+우리 팀도 디스코드에서 활동하고 있으며 여러분께 지원과 안내를 해드립니다. 커뮤니티에 가입하는 것은 참여적이고 동기를 부여받을 수 있게 해주며 소통을 유지할 수 있는 훌륭한 방법입니다. 여러분을 커뮤니티에서 만나 뵙기를 기대합니다!
+
+## 디스코드가 뭔가요?[[what-is-discord]]
+
+디스코드는 무료 채팅 플랫폼입니다. 슬랙을 써보신적 있으시다면 그것과 비슷하다고 생각하시면 됩니다. 허깅페이스 디스코드 서버는 18,000명의 AI 전문가, 학습자 및 애호가로 구성된 활발한 커뮤니티로, 여러분도 참여하실 수 있습니다.
+
+## 디스코드 탐색하기[[navigating-discord]]
+
+디스코드 서버에 가입하시면 왼쪽의 `#role-assignment`를 클릭하여 관심있는 주제를 선택하셔야 합니다. 주제는 원하시는 만큼 선택하실 수 있으며 다른 학습자들과 같이하기 위해선 반드시 "ML for Audio and Speech"를 클릭하셔야 합니다.
+채널을 살펴보고 `#introduce-yourself`에서 여러분을 소개해보세요.
+
+## 오디오 코스 채널[[audio-course-channels]]
+
+우리의 디스코드 서버에는 다양한 주제의 채널들이 있습니다. 논문에 대한 토론, 이벤트 꾸리기, 프로젝트와 아이디어 공유, 브레인스토밍 등 다양한 활동을 찾아보실 수 있습니다.
+
+다음의 채널들은 오디오 코스 학습을 위해 관련이 있는 채널들입니다:
+
+* `#audio-announcements`: 코스 업데이트, 허깅페이스의 오디오와 관련된 모든 뉴스들, 이벤트 공지 등을 전합니다.
+* `#audio-study-group`: 아이디어를 교환하고 코스에 대한 질문과 토론을 합니다.
+* `#audio-discuss`: 오디오와 관련된 일반적인 토론을 합니다.
+
+`#audio-study-group` 외에도 자유롭게 자신의 학습 그룹을 만들어보세요. 함께 배우면 더 쉽습니다!
diff --git a/chapters/ko/chapter0/get_ready.mdx b/chapters/ko/chapter0/get_ready.mdx
new file mode 100644
index 00000000..ef7a85a5
--- /dev/null
+++ b/chapters/ko/chapter0/get_ready.mdx
@@ -0,0 +1,35 @@
+# 코스 준비하기[[get-ready-to-take-the-course]]
+
+코스에 대한 기대가 크신가요? 이 페이지는 여러분이 바로 시작하실 수 있도록 준비를 도와드립니다.
+
+## 1단계. 등록하기[[step-1-sign-up]]
+
+모든 업데이트와 소셜 이벤트에 대한 최신 소식을 받아보려면 코스에 등록하세요.
+
+[👉 등록하기](http://eepurl.com/insvcI)
+
+## 2단계. Hugging Face 계정 만들기[[step-2-get-a-hugging-face-account]]
+
+아직 허깅페이스 계정이 없다면, 계정을 만드세요(무료입니다). 실습과제 완료, 수료 인증, 사전학습 모델 탐색, 데이터셋에 접근 등을 위해 필요합니다.
+
+[👉 HUGGING FACE 계정 생성](https://huggingface.co/join)
+
+## 3단계. 기초지식 점검하기(필요한 경우)[[step-3-brush-up-on-fundamentals-if-you-need-to]]
+
+우린 여러분이 딥러닝과 트랜스포머에 대해 대략적으로 이해를 하고 있다고 가정합니다. 트랜스포머에 대한 이해가 필요하다면 우리의 [NLP 코스](https://huggingface.co/course/chapter1/1)를 참고하세요.
+
+## 4단계. 설정 확인하기[[step-4-check-your-setup]]
+
+코스 자료를 보기 위해서는 다음이 필요합니다:
+- 인터넷 연결이 가능한 컴퓨터
+- 실습과제를 위한 [Google Colab](https://colab.research.google.com). 무료버전이면 충분합니다.
+
+Google Colab을 사용해본적이 없으시다면, 이 [공식 소개 노트북](https://colab.research.google.com/notebooks/intro.ipynb)을 참고하세요.
+
+## 5단계. 커뮤니티 참여하기[[step-5-join-the-community]]
+
+동료 수강생들과 아이디어를 공유하고 허깅페이스팀과 연락할 수 있는 디스코드 서버에 가입하세요.
+
+[👉 디스코드 참여](http://hf.co/join/discord)
+
+이 디스코드 커뮤니티에 대해 더 알아보고 싶으시다면 [다음 페이지](community)를 참고하세요.
diff --git a/chapters/ko/chapter0/introduction.mdx b/chapters/ko/chapter0/introduction.mdx
new file mode 100644
index 00000000..0abd29ff
--- /dev/null
+++ b/chapters/ko/chapter0/introduction.mdx
@@ -0,0 +1,89 @@
+# 허깅페이스 오디오 코스에 오신것을 환영합니다![[welcome-to-the-hugging-face-audio-course]]
+
+학습자 여러분,
+
+트랜스포머 모델의 오디오 분야 적용에 대한 코스에 오신것을 환영합니다. 트랜스포머는 자연어 처리, 컴퓨터 비전, 최근에는 오디오 처리에 이르기까지 다양한 작업에서 최고의 성능을 달성하는 가장 강력하고 다재다능한 딥러닝 아키텍처 중 하나입니다.
+
+이 코스에서는 트랜스포머를 오디오 데이터에 적용하는 방법을 살펴볼 것입니다. 여러분은 이를 사용하여 다양한 오디오 작업을 처리하는 방법을 배우게 됩니다. 음성 인식, 오디오 분류, 텍스트에서 음성 생성 같은 문제에 관심이 있다면 트랜스포머와 이 코스를 통해 해결할 수 있을것입니다.
+
+이 모델로 어떤 작업이 가능한지 보여주기 위해 아래 데모를 준비했습니다. 데모에서 짧게 말한 후 실시간으로 받아쓰는 것을 확인해보세요!
+
+
+
+코스를 진행하면서 여러분은 오디오 데이터작업의 세부사항들과 다양한 트랜스포머 아키텍처에 대해 배우고, 사전학습된 모델을 활용하여 여러분만의 오디오 트랜스포머를 훈련시킬 것입니다.
+
+이 코스는 딥러닝에 대한 배경지식이 있고 트랜스포머에 대해 어느 정도 친숙한 학습자를 대상으로 설계되었습니다. 오디오 데이터 처리에 대한 전문지식은 필요하지 않습니다. 트랜스포머에 대한 이해가 필요하다면, 트랜스포머의 기초에 대한 저희의 [NLP 코스](https://huggingface.co/course/chapter1/1)를 참고하세요.
+
+## 코스 팀 소개[[meet-the-course-team]]
+
+**Sanchit Gandhi, Machine Learning Research Engineer at Hugging Face**
+
+안녕하세요! 저는 Sanchit이고, 허깅페이스🤗의 오픈 소스 팀에서 오디오 분야의 기계 학습 리서치 엔지니어로 일하고 있습니다.
+저의 주요 연구 분야는 자동 음성 인식과 번역으로, 음성 모델을 더 빠르고, 가볍고, 사용하기 쉽게 만드는 것을 목표로 하고 있습니다.
+
+**Matthijs Hollemans, Machine Learning Engineer at Hugging Face**
+
+안녕하세요, 저는 Matthijs입니다. 저는 허깅페이스의 오픈 소스 팀에서 오디오 분야의 기계 학습 엔지니어로 일하고 있습니다. 또한 사운드 신디사이저를 작성하는 방법에 대한 책의 저자이며, 여가 시간에 오디오 플러그인을 만듭니다.
+
+**Maria Khalusova, Documentation & Courses at Hugging Face**
+
+저는 Maria입니다. 트랜스포머와 기타 오픈 소스 도구를 더욱 접근하기 쉽게 만들기 위해 교육 콘텐츠와 문서를 만듭니다. 복잡한 기술 개념을 세분화하여 사람들이 최첨단 기술을 시작하는데 도움을 줍니다.
+
+**Vaibhav Srivastav, ML Developer Advocate Engineer at Hugging Face**
+
+저는 Vaibhav(VB)이고, 허깅페이스의 오픈 소스 팀에서 오디오 분야의 Developer Advocate 엔지니어로 일하고 있습니다. 저자원으로 텍스트를 음성으로 변환하는 연구를 하고 있으며, 최첨단 음성 연구를 대중에게 전달하는데 도움을 주고 있습니다.
+
+## 코스 구성[[course-structure]]
+
+이 코스는 다양한 주제를 심도 있게 다루는 여러 단원으로 구성되어 있습니다:
+
+* 1단원: 오디오 처리 및 데이터 준비 등 오디오 데이터를 다루는 방법을 배웁니다.
+* 2단원: 오디오의 응용방법을 알아보고, 오디오 분류 및 음성 인식과 같은 다양한 작업을 위해 🤗 트랜스포머 파이프라인을 사용하는 방법을 배웁니다.
+* 3단원: 오디오 트랜스포머 아키텍처를 탐구하고, 그 차이를 배우며, 어떤 작업에 가장 적합한지 알아봅니다.
+* 4단원: 여러분만의 음악 장르 분류기를 만듭니다.
+* 5단원: 음성 인식에 대해 더 자세히 알아보고, 회의 녹음을 위한 모델을 만듭니다.
+* 6단원: 텍스트에서 음성을 생성하는 방법을 배웁니다.
+* 7단원: 트랜스포머를 이용하여 오디오에서 다른 오디오로 바꾸는 법을 배웁니다.
+
+각 단원에는 기본 개념과 기술에 대해 깊이 있는 이해를 얻을 수 있는 이론적인 구성 요소가 포함되어 있습니다. 코스 전반에 걸쳐 여러분의 지식을 테스트하고 학습을 도와줄 퀴즈를 제공하며, 일부 장에는 배운 내용을 적용해 볼 수 있는 실습과제들(hands-on exercises)도 포함되어 있습니다.
+
+이 코스를 마치면 여러분은 트랜스포머를 활용한 오디오 데이터 처리에 대한 탄탄한 기초를 갖추게 되며, 다양한 오디오 관련 작업에 이 기술을 적용할 수 있게될 것입니다.
+
+코스의 단원들은 다음과 같은 게시일정에 따라 순차적으로 공개될 예정입니다:
+
+| 단원 | 출시일 |
+|---|-----------------|
+| 0단원, 1단원, 2단원 | 2023년 6월 14일 |
+| 3단원, 4단원 | 2023년 6월 21일 |
+| 5단원 | 2023년 6월 28일 |
+| 6단원 | 2023년 7월 5일 |
+| 7단원, 8단원 | 2023년 7월 12일 |
+
+[//]: # (| Bonus Unit | TBD |)
+
+## 학습 경로 및 인증[[learning-paths-and-certification]]
+
+이 코스를 수강하는 데 옳거나 그른 방법은 없습니다. 이 코스의 모든 자료는 100% 무료로 공개되며 오픈 소스입니다.
+여러분은 자유롭게 진도를 나갈 수 있지만, 단원 순서대로 진행하는 것을 권장합니다.
+
+코스 완료 시 인증을 받고 싶다면, 두 가지 옵션이 있습니다:
+
+| 인증 유형 | 요구 사항 |
+|---|-------------------------------------------------------------------------------------|
+| Certificate of completion | 2023년 7월 말까지 지침에 따라 실습과제의 80%를 완료하세요. |
+| Certificate of honors | 2023년 7월 말까지 지침에 따라 실습과제의 100%를 완료하세요. |
+
+각각의 실습과제들에 완료 기준이 써있습니다. 인증을 받을 수 있을정도로 실습과제들을 충분히 풀었다면, 코스의 마지막 단원을 참조하여 인증서를 취득하는 방법을 알아보세요. 행운을 빕니다!
+
+## 코스 등록하기[[sign-up-to-the-course]]
+
+이 코스의 단원들은 몇 주에 걸쳐 점진적으로 공개될 예정입니다. 새로운 단원이 출시될때 놓치지 않도록 코스 업데이트에 등록하시는 것을 권유드립니다. 코스 업데이트에 등록한 사용자는 저희가 주최예정인 특별한 소셜 이벤트에 대해서도 가장 먼저 알게 됩니다.
+
+[등록하기](http://eepurl.com/insvcI)
+
+즐거운 학습 되세요!
diff --git a/chapters/ko/chapter1/audio_data.mdx b/chapters/ko/chapter1/audio_data.mdx
new file mode 100644
index 00000000..22a14bd5
--- /dev/null
+++ b/chapters/ko/chapter1/audio_data.mdx
@@ -0,0 +1,211 @@
+# 오디오 데이터에 대하여[[introduction-to-audio-data]]
+
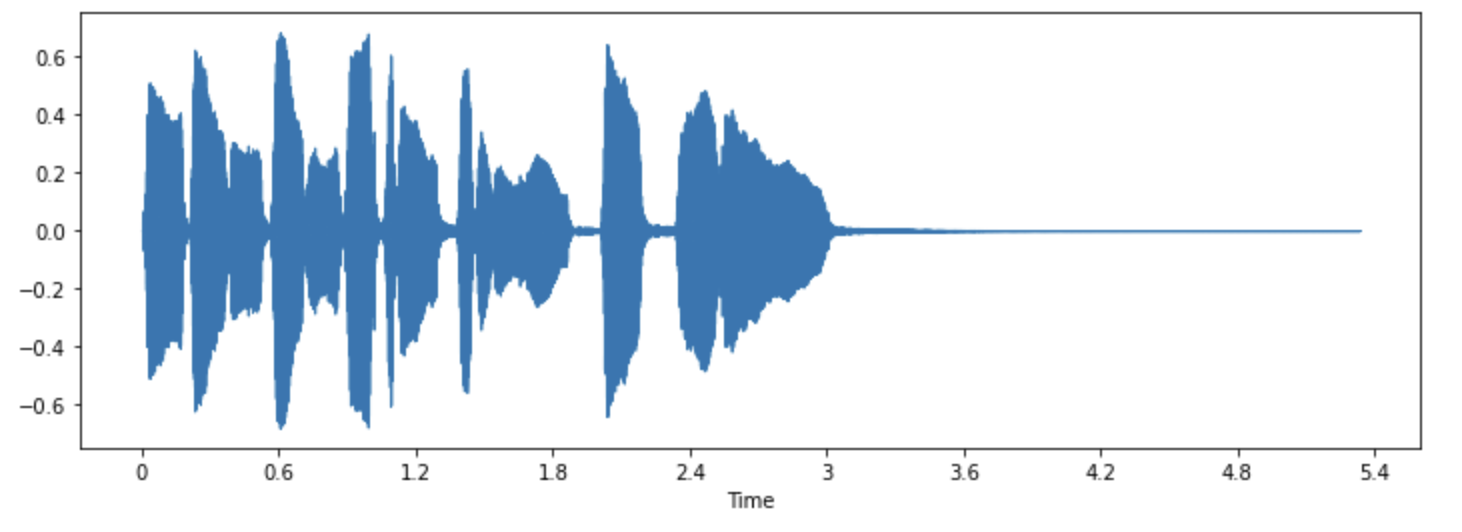
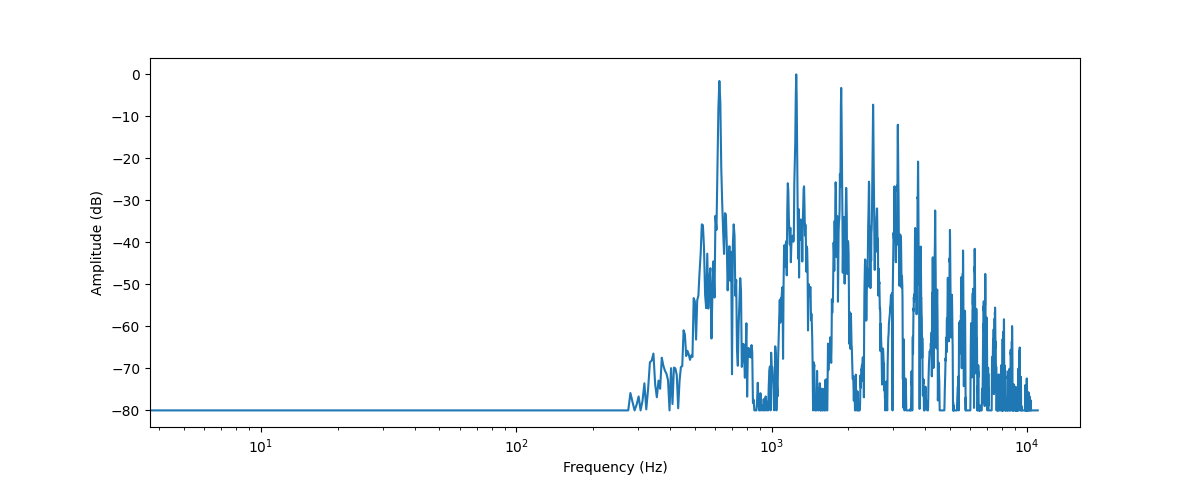
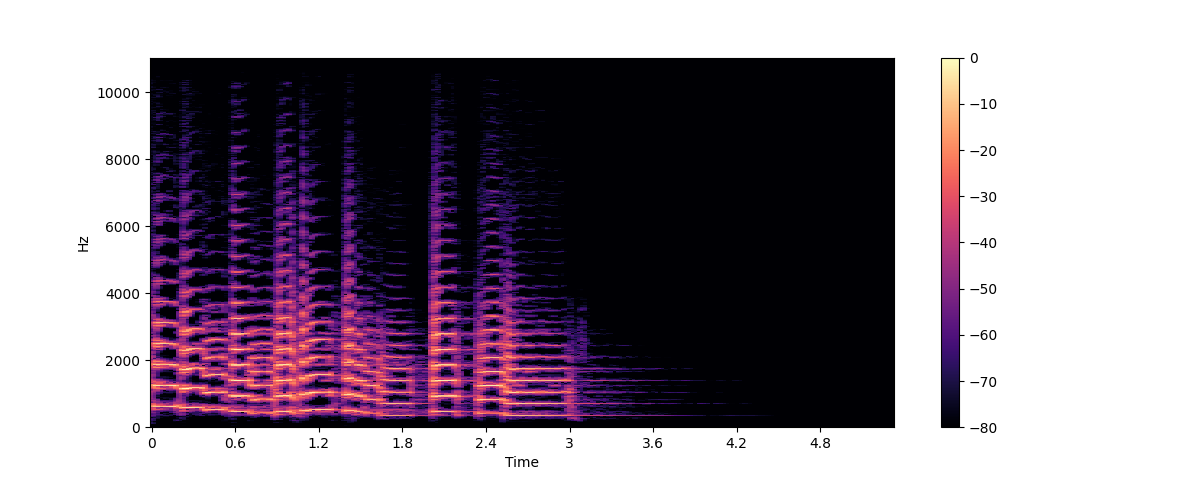
+본질적으로 음파(sound wave)는 연속적인 신호입니다. 이는 어떤 주어진 시간에 대해 무한개의 신호 값을 가진다는 뜻입니다.
+그런데 디지털 기기들은 유한개의 값들을 요구하기에 문제가 됩니다. 이런 디지털 기기에서의 처리, 저장, 전송을 위해 연속적인 음파들은 일련의 이산적인(discrete) 값, 즉 디지털 표현(digital representation)으로 변환되어야 합니다.
+
+어떤 오디오 데이터셋에서건 텍스트 나레이션이나 음악같은 디지털 음향 파일들을 볼 수 있습니다. 이는 `.wav` (Waveform Audio File), `.flac` (Free Lossless Audio Codec), 그리고 `.mp3` (MPEG-1 Audio Layer 3)같이 다양한 포맷으로 접할 수 있습니다. 이 포맷들은 주로 오디오 신호의 디지털 표현을 압축하는 방식에서 차이가 있습니다.
+
+연속적인 신호로부터 이러한 표현을 얻는 방법에 대해 알아봅시다. 아날로그 신호는 먼저 마이크에 의해 포착되어 음파에서 전기 신호로 변환됩니다. 이 전기 신호는 아날로그-디지털 컨버터(Analog-to-Dogital Converter)를 거치며 샘플링(sampling)을 통해 디지털 표현으로 디지털화됩니다.
+
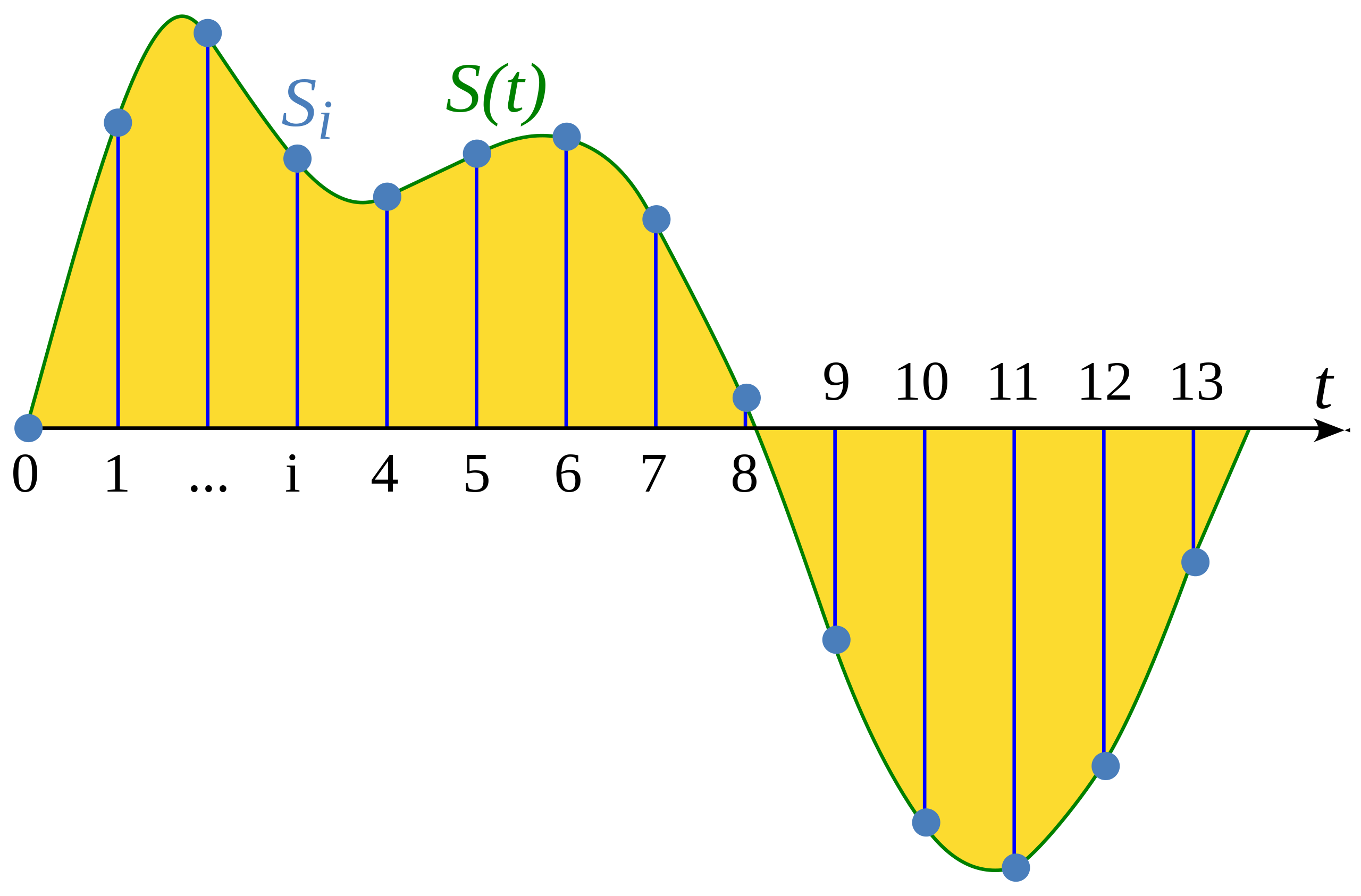
+## 샘플링과 샘플링 속도(sampling rate)[[sampling-and-sampling-rate]]
+
+샘플링이란 연속적인 신호를 고정된 시간 간격으로 측정하는 과정입니다. 샘플링된 파형(waveform)은 균일한 간격으로 유한개의 신호 값을 가지므로 이산적입니다.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+