diff --git a/chapters/en/_toctree.yml b/chapters/en/_toctree.yml
index af5b5c35..2698b1fc 100644
--- a/chapters/en/_toctree.yml
+++ b/chapters/en/_toctree.yml
@@ -103,27 +103,23 @@
- local: chapter6/supplemental_reading
title: Supplemental reading and resources
-#- title: Unit 7. Audio to audio
-# sections:
-# - local: chapter7/introduction
-# title: What you'll learn and what you'll build
-# - local: chapter7/tasks
-# title: Examples of audio-to-audio tasks
-# - local: chapter7/choosing_dataset
-# title: Choosing a dataset
-# - local: chapter7/preprocessing
-# title: Loading and preprocessing data
-# - local: chapter7/evaluation
-# title: Evaluation metrics for audio-to-audio
-# - local: chapter7/fine-tuning
-# title: Fine-tuning the model
+- title: Unit 7. Putting it all together
+ sections:
+ - local: chapter7/introduction
+ title: What you'll learn and what you'll build
+ - local: chapter7/speech-to-speech
+ title: Speech-to-speech translation
+ - local: chapter7/voice-assistant
+ title: Creating a voice assistant
+ - local: chapter7/transcribe-meeting
+ title: Transcribe a meeting
# - local: chapter7/quiz
# title: Quiz
# quiz: 7
-# - local: chapter7/hands_on
-# title: Hands-on exercise
-# - local: chapter7/supplemental_reading
-# title: Supplemental reading and resources
+ - local: chapter7/hands-on
+ title: Hands-on exercise
+ - local: chapter7/supplemental_reading
+ title: Supplemental reading and resources
#
#- title: Unit 8. Finish line
# sections:
diff --git a/chapters/en/chapter7/hands-on.mdx b/chapters/en/chapter7/hands-on.mdx
new file mode 100644
index 00000000..691c0c33
--- /dev/null
+++ b/chapters/en/chapter7/hands-on.mdx
@@ -0,0 +1,47 @@
+# Hands-on exercise
+
+In this Unit, we consolidated the material covered in the previous six units of the course to build three integrated
+audio applications. As you've experienced, building more involved audio tools is fully within reach by using the
+foundational skills you've acquired in this course.
+
+The hands-on exercise takes one of the applications covered in this Unit, and extends it with a few multilingual
+tweaks 🌍 Your objective is to take the [cascaded speech-to-speech translation Gradio demo](https://huggingface.co/spaces/course-demos/speech-to-speech-translation)
+from the first section in this Unit, and update it to translate to any **non-English** language. That is to say, the
+demo should take speech in language X, and translate it to speech in language Y, where the target language Y is not
+English. You should start by [duplicating](https://huggingface.co/spaces/course-demos/speech-to-speech-translation?duplicate=true)
+the template under your Hugging Face namespace. There's no requirement to use a GPU accelerator device - the free CPU
+tier works just fine 🤗 However, you should ensure that the visibility of your demo is set to **public**. This is required
+such that your demo is accessible to us and can thus be checked for correctness.
+
+Tips for updating the speech translation function to perform multilingual speech translation are provided in the
+section on [speech-to-speech translation](speech-to-speech.mdx). By following these instructions, you should be able
+to update the demo to translate from speech in language X to text in language Y, which is half of the task!
+
+To synthesise from text in language Y to speech in language Y, where Y is a multilingual language, you will need
+to use a multilingual TTS checkpoint. For this, you can either use the SpeechT5 TTS checkpoint that you fine-tuned
+in the previous hands-on exercise, or a pre-trained multilingual TTS checkpoint. There are two options for pre-trained
+checkpoints, either the checkpoint [sanchit-gandhi/speecht5_tts_vox_nl](https://huggingface.co/sanchit-gandhi/speecht5_tts_vox_nl),
+which is a SpeechT5 checkpoint fine-tuned on the Dutch split of the [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli)
+dataset, or an MMS TTS checkpoint (see section on [pretrained models for TTS](../chapter6/pre-trained_models.mdx)).
+
+
+ In our experience experimenting with the Dutch language, using an MMS TTS checkpoint results in better performance than a
+ fine-tuned SpeechT5 one, but you might find that your fine-tuned TTS checkpoint is preferable in your language.
+ If you decide to use an MMS TTS checkpoint, you will need to update the requirements.txt
+ file of your demo to install transformers from the PR branch:
+ git+https://github.com/hollance/transformers.git@6900e8ba6532162a8613d2270ec2286c3f58f57b
+
+
+
+Your demo should take as input an audio file, and return as output another audio file, matching the signature of the
+[`speech_to_speech_translation`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/3946ba6705a6632a63de8672ac52a482ab74b3fc/app.py#L35)
+function in the template demo. Therefore, we recommend that you leave the main function `speech_to_speech_translation`
+as is, and only update the [`translate`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L24)
+and [`synthesise`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L29)
+functions as required.
+
+Once you have built your demo as a Gradio demo on the Hugging Face Hub, you can submit it for assessment. Head to the
+Space [audio-course-u7-assessment](https://huggingface.co/spaces/huggingface-course/audio-course-u7-assessment) and
+provide the repository id of your demo when prompted. This Space will check that your demo has been built correctly by
+sending a sample audio file to your demo and checking that the returned audio file is indeed non-English. If your demo
+works correctly, you'll get a green tick next to your name on the overall [progress space](https://huggingface.co/spaces/MariaK/Check-my-progress-Audio-Course) ✅
diff --git a/chapters/en/chapter7/introduction.mdx b/chapters/en/chapter7/introduction.mdx
new file mode 100644
index 00000000..3e0de22d
--- /dev/null
+++ b/chapters/en/chapter7/introduction.mdx
@@ -0,0 +1,16 @@
+# Unit 7. Putting it all together 🪢
+
+Well done on making it to Unit 7 🥳 You're just a few steps away from completing the course and acquiring the final few
+skills you need to navigate the field of Audio ML. In terms of understanding, you already know everything there is to know!
+Together, we've comprehensively covered the main topics that constitute the audio domain and their accompanying theory
+(audio data, audio classification, speech recognition and text-to-speech). What this Unit aims to deliver is a framework
+for **putting it all together**: now that you know how each of these tasks work in isolation, we're going to explore how
+you can combine them together to build some real-world applications.
+
+## What you'll learn and what you'll build
+
+In this Unit, we'll cover the following three topics:
+
+* [Speech-to-speech translation](speech-to-speech): translate speech from one language into speech in a different language
+* [Creating a voice assistant](voice-assistant): build your own voice assistant that works in a similar way to Alexa or Siri
+* [Transcribing meetings](transcribe-meeting): transcribe a meeting and label the transcript with who spoke when
diff --git a/chapters/en/chapter7/speech-to-speech.mdx b/chapters/en/chapter7/speech-to-speech.mdx
new file mode 100644
index 00000000..05049fde
--- /dev/null
+++ b/chapters/en/chapter7/speech-to-speech.mdx
@@ -0,0 +1,262 @@
+# Speech-to-speech translation
+
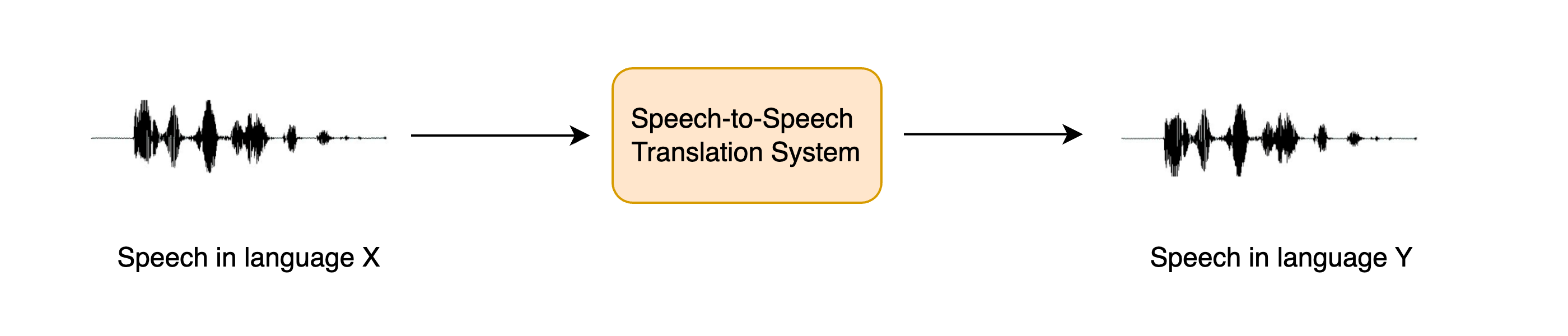
+Speech-to-speech translation (STST or S2ST) is a relatively new spoken language processing task. It involves translating
+speech from one langauge into speech in a **different** language:
+
+
+
+
+

+
+
+
ASRDiarizationPipeline directly from pre-trained by specifying the model id
+ of an ASR model on the Hub:
+ pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-base")
+
+
+Let's pass the audio file to the composite pipeline and see what we get out:
+
+```python
+pipeline(sample["audio"].copy())
+```
+
+```text
+[{'speaker': 'SPEAKER_01',
+ 'text': ' The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight.',
+ 'timestamp': (0.0, 15.48)},
+ {'speaker': 'SPEAKER_00',
+ 'text': " He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
+ 'timestamp': (15.48, 21.28)}]
+```
+
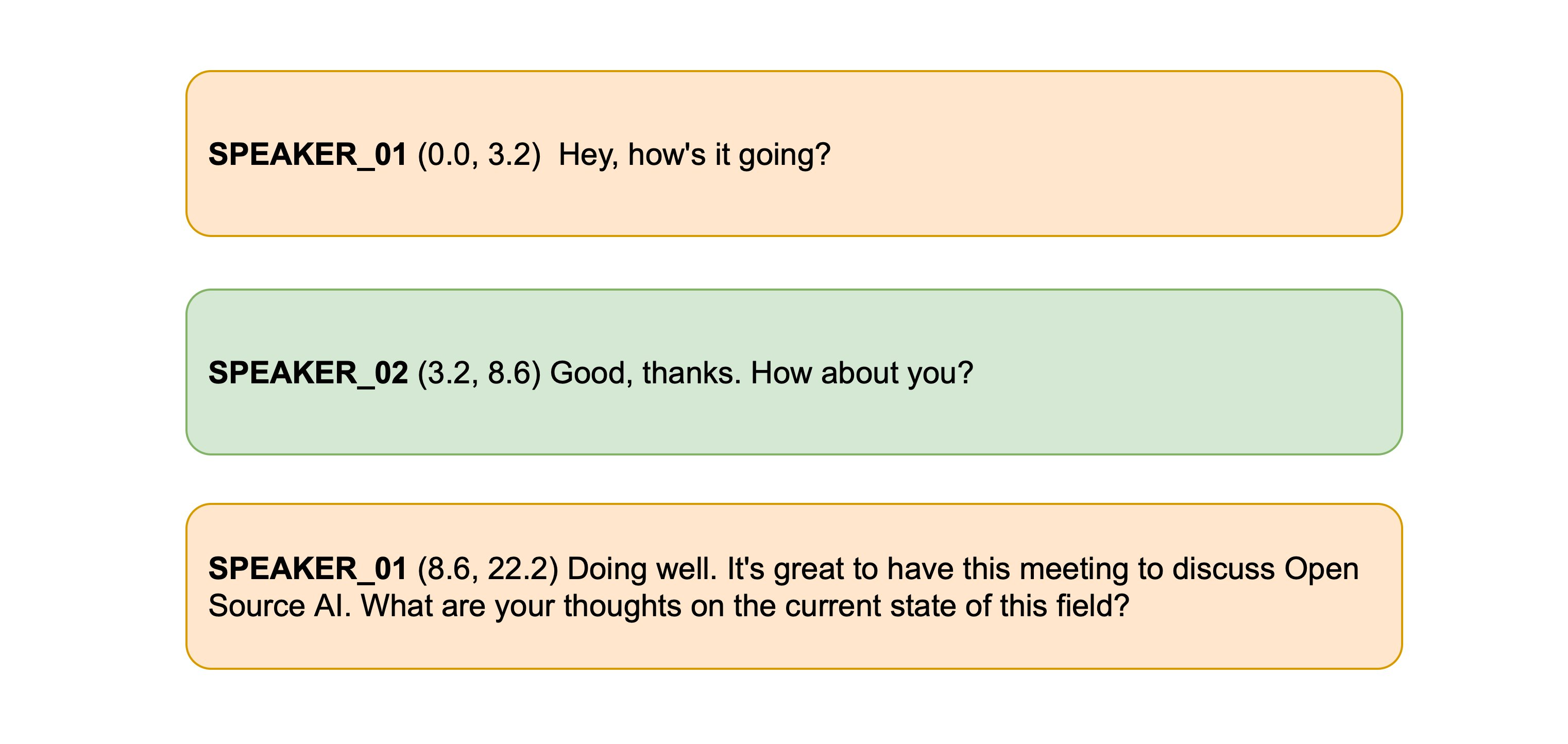
+Excellent! The first speaker is segmented as speaking from 0 to 15.48 seconds, and the second speaker from 15.48 to 21.28 seconds,
+with the corresponding transcriptions for each.
+
+We can format the timestamps a little more nicely by defining two helper functions. The first converts a tuple of
+timestamps to a string, rounded to a set number of decimal places. The second combines the speaker id, timestamp and text
+information onto one line, and splits each speaker onto their own line for ease of reading:
+
+```python
+def tuple_to_string(start_end_tuple, ndigits=1):
+ return str((round(start_end_tuple[0], ndigits), round(start_end_tuple[1], ndigits)))
+
+
+def format_as_transcription(raw_segments):
+ return "\n\n".join(
+ [
+ chunk["speaker"] + " " + tuple_to_string(chunk["timestamp"]) + chunk["text"]
+ for chunk in raw_segments
+ ]
+ )
+```
+
+Let's re-run the pipeline, this time formatting the transcription according to the function we've just defined:
+```python
+outputs = pipeline(sample["audio"].copy())
+
+format_as_transcription(outputs)
+```
+
+```text
+SPEAKER_01 (0.0, 15.5) The second and importance is as follows. Sovereignty may be defined to be the right of making laws.
+In France, the king really exercises a portion of the sovereign power, since the laws have no weight.
+
+SPEAKER_00 (15.5, 21.3) He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon
+his entire future.
+```
+
+There we go! With that, we've both diarized and transcribe our input audio and returned speaker-segmented transcriptions.
+While the minimum distance algoirthm to align the diarized timestamps and transcribed timestamps is simple, it
+works well in practice. If you want to explore more advanced methods for combining the timestamps, the
+source code for the `ASRDiarizationPipeline` is a good place to start: [speechbox/diarize.py](https://github.com/huggingface/speechbox/blob/96d2d1a180252d92263f862a1cd25a48860f1aed/src/speechbox/diarize.py#L12)
diff --git a/chapters/en/chapter7/voice-assistant.mdx b/chapters/en/chapter7/voice-assistant.mdx
new file mode 100644
index 00000000..287743b2
--- /dev/null
+++ b/chapters/en/chapter7/voice-assistant.mdx
@@ -0,0 +1,466 @@
+# Creating a voice assistant
+
+In this section, we'll piece together three models that we've already had hands-on experience with to build an end-to-end
+voice assistant called **Marvin** 🤖. Like Amazon's Alexa or Apple's Siri, Marvin is a virtual voice assistant who
+responds to a particular 'wake word', then listens out for a spoken query, and finally responds with a spoken answer.
+
+We can break down the voice assistant pipeline into four stages, each of which requires a standalone model:
+
+
+

+
+
+
+
+
+
+
"openai/whisper-small.en".
+
+
+We can now define a function to record our microphone input and transcribe the corresponding text. With the `ffmpeg_microphone_live`
+helper function, we can control how 'real-time' our speech recognition model is. Using a smaller `stream_chunk_s` lends
+itself to more real-time speech recognition, since we divide our input audio into smaller chunks and transcribe them on
+the fly. However, this comes at the expense of poorer accuracy, since there's less context for the model to infer from.
+
+As we're transcribing the speech, we also need to have an idea of when the user **stops** speaking, so that we can terminate
+the recording. For simplicity, we'll terminate our microphone recording after the first `chunk_length_s` (which is set to
+5 seconds by default), but you can experiment with using a [voice activity detection (VAD)](https://huggingface.co/models?pipeline_tag=voice-activity-detection&sort=trending)
+model to predict when the user has stopped speaking.
+
+```python
+import sys
+
+
+def transcribe(chunk_length_s=5.0, stream_chunk_s=1.0):
+ sampling_rate = transcriber.feature_extractor.sampling_rate
+
+ mic = ffmpeg_microphone_live(
+ sampling_rate=sampling_rate,
+ chunk_length_s=chunk_length_s,
+ stream_chunk_s=stream_chunk_s,
+ )
+
+ print("Start speaking...")
+ for item in transcriber(mic, generate_kwargs={"max_new_tokens": 128}):
+ sys.stdout.write("\033[K")
+ print(item["text"], end="\r")
+ if not item["partial"][0]:
+ break
+
+ return item["text"]
+```
+
+Let's give this a go and see how we get on! Once the microphone is live, start speaking and watch your transcription
+appear in semi real-time:
+```python
+transcribe()
+```
+
+```text
+Start speaking...
+ Hey, this is a test with the whisper model.
+```
+
+Nice! You can adjust the maximum audio length `chunk_length_s` based on how fast or slow you speak (increase it if you
+felt like you didn't have enough time to speak, decrease it if you were left waiting at the end), and the
+`stream_chunk_s` for the real-time factor. Just pass these as arguments to the `transcribe` function.
+
+## Language model query
+
+Now that we have our spoken query transcribed, we want to generate a meaningful response. To do this, we'll use an LLM
+hosted on the Cloud. Specifically, we'll pick an LLM on the Hugging Face Hub and use the [Inference API](https://huggingface.co/inference-api)
+to easily query the model.
+
+First, let's head over to the Hugging Face Hub. To find our LLM, we'll use the [🤗 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard),
+a Space that ranks LLM models by performance over four generation tasks. We'll search by "instruct" to filter out models
+that have been instruction fine-tuned, since these should work better for our querying task:
+
+
+

+
+

+
+

+