+  +
+
+
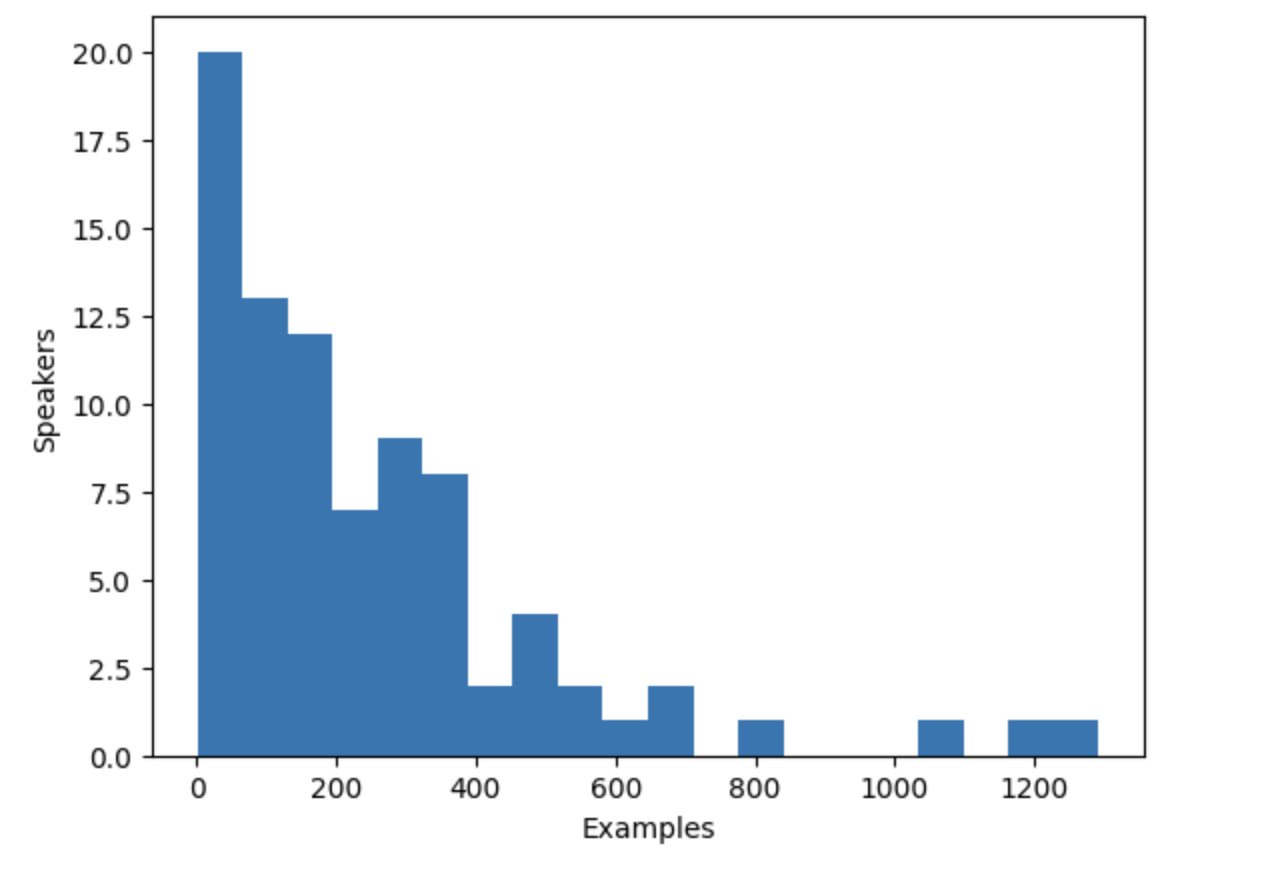
+Гистограмма показывает, что примерно треть дикторов в наборе данных имеет менее 100 примеров, в то время как
+около десяти дикторов имеют более 500 примеров. Чтобы повысить эффективность обучения и сбалансировать набор данных, мы можем ограничить
+данные дикторами, имеющими от 100 до 400 примеров.
+
+```py
+def select_speaker(speaker_id):
+ return 100 <= speaker_counts[speaker_id] <= 400
+
+
+dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
+```
+
+Проверим, сколько осталось дикторов:
+
+```py
+len(set(dataset["speaker_id"]))
+```
+
+**Output:**
+```out
+42
+```
+
+Посмотрим, сколько осталось примеров:
+
+```py
+len(dataset)
+```
+
+**Output:**
+```out
+9973
+```
+
+В результате вы получаете чуть менее 10 000 примеров из примерно 40 уникальных дикторов, что должно быть вполне достаточно.
+
+Отметим, что некоторые дикторы с небольшим количеством примеров могут иметь больше аудиофайлов, если примеры длинные. Однако
+определение общего объема аудиозаписей для каждого диктора требует сканирования всего датасета, что является
+трудоемким процессом, включающим загрузку и декодирование каждого аудиофайла. Поэтому в данном случае мы решили пропустить этот этап.
+
+### Эмбеддинги диктора
+
+Для того чтобы модель TTS могла различать несколько дикторов, необходимо создать эмбеддинги диктора для каждого примера.
+Эмбеддинги дикторов - это дополнительный вход для модели, который фиксирует характеристики голоса конкретного диктора.
+Для создания эмбеддингов диктора используется предварительно обученная модель [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
+от SpeechBrain.
+
+Создадим функцию `create_speaker_embedding()`, которая принимает входную волновую форму звука и выдает 512-элементный вектор,
+содержащий соответствующие эмбеддинги диктора.
+
+```py
+import os
+import torch
+from speechbrain.pretrained import EncoderClassifier
+
+spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+speaker_model = EncoderClassifier.from_hparams(
+ source=spk_model_name,
+ run_opts={"device": device},
+ savedir=os.path.join("/tmp", spk_model_name),
+)
+
+
+def create_speaker_embedding(waveform):
+ with torch.no_grad():
+ speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
+ speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
+ speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
+ return speaker_embeddings
+```
+
+Важно отметить, что модель `speechbrain/spkrec-xvect-voxceleb` была обучена на английской речи из датасета VoxCeleb,
+в то время как учебные примеры в данном руководстве представлены на голландском языке. Хотя мы считаем, что данная модель все равно будет генерировать разумные эмбеддинги диктора
+для нашего голландского датасета, это предположение может быть справедливо не во всех случаях.
+
+Для получения оптимальных результатов необходимо сначала обучить модель X-вектора на целевой речи. Это позволит модели
+лучше улавливать уникальные речевые особенности, присущие голландскому языку. Если вы хотите обучить свою собственную X-векторную модель,
+то в качестве примера можно использовать [этот скрипт](https://huggingface.co/mechanicalsea/speecht5-vc/blob/main/manifest/utils/prep_cmu_arctic_spkemb.py).
+
+### Обработка датасета
+
+Наконец, обработаем данные в тот формат, который ожидает модель. Создадим функцию `prepare_dataset`, которая принимает
+один пример и использует объект `SpeechT5Processor` для токенизации входного текста и загрузки целевого аудио в лог-мел спектрограмму.
+Она также должна добавлять эмбеддинги диктора в качестве дополнительного входного сигнала.
+
+```py
+def prepare_dataset(example):
+ audio = example["audio"]
+
+ example = processor(
+ text=example["normalized_text"],
+ audio_target=audio["array"],
+ sampling_rate=audio["sampling_rate"],
+ return_attention_mask=False,
+ )
+
+ # strip off the batch dimension
+ example["labels"] = example["labels"][0]
+
+ # use SpeechBrain to obtain x-vector
+ example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
+
+ return example
+```
+
+Проверить правильность обработки можно на одном из примеров:
+
+```py
+processed_example = prepare_dataset(dataset[0])
+list(processed_example.keys())
+```
+
+**Output:**
+```out
+['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']
+```
+
+Эмбеддинги диктора должны представлять собой 512-элементный вектор:
+
+```py
+processed_example["speaker_embeddings"].shape
+```
+
+**Output:**
+```out
+(512,)
+```
+
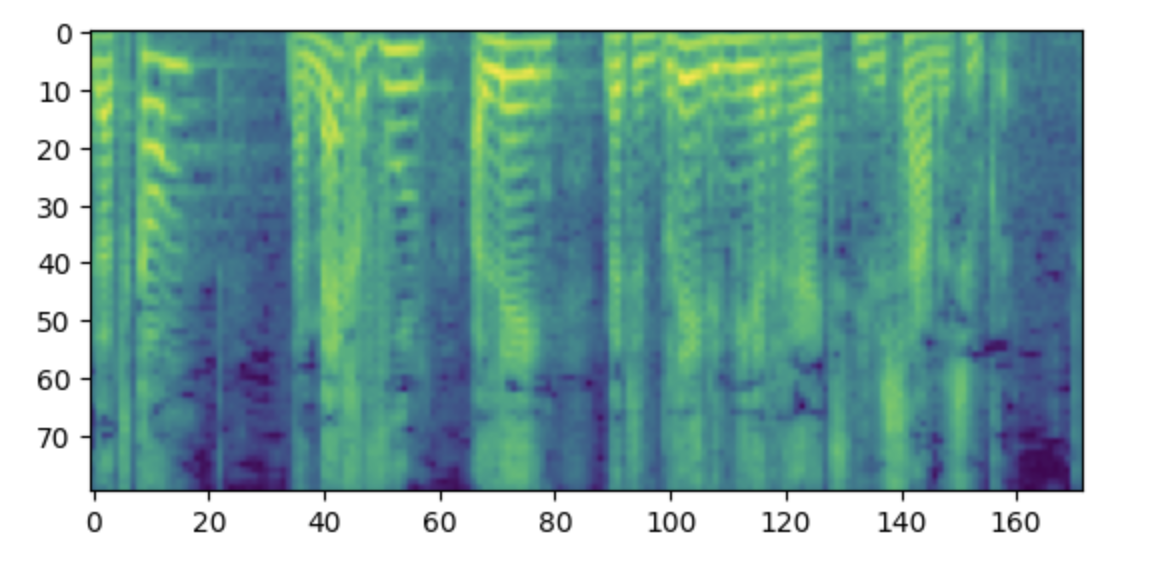
+Метки должны представлять собой лог-мел спектрограмму с 80 мел бинами.
+
+```py
+import matplotlib.pyplot as plt
+
+plt.figure()
+plt.imshow(processed_example["labels"].T)
+plt.show()
+```
+
+
+
+  +
+
+
+Примечание: Если данная спектрограмма кажется вам непонятной, то это может быть связано с тем, что вы привыкли располагать низкие частоты
+внизу, а высокие - вверху графика. Однако при построении спектрограмм в виде изображения с помощью библиотеки matplotlib ось y
+переворачивается, и спектрограммы выглядят перевернутыми.
+
+Теперь необходимо применить функцию препроцессинга ко всему набору данных. Это займет от 5 до 10 минут.
+
+```py
+dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
+```
+
+Появится предупреждение о том, что длина некоторых примеров в датасете превышает максимальную длину входных данных, которую может обработать модель (600 лексем).
+Удалите эти примеры из датасета. Здесь мы идем еще дальше и для того, чтобы увеличить размер батча, удаляем все, что превышает 200 токенов.
+
+```py
+def is_not_too_long(input_ids):
+ input_length = len(input_ids)
+ return input_length < 200
+
+
+dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
+len(dataset)
+```
+
+**Output:**
+```out
+8259
+```
+
+Затем создадим базовое разделение на тренировочную и тестовую части:
+
+```py
+dataset = dataset.train_test_split(test_size=0.1)
+```
+
+### Коллатор данных
+
+Для того чтобы объединить несколько примеров в батч, необходимо определить пользовательский коллатор данных. Этот коллатор будет дополнять более короткие последовательности токенами,
+гарантируя, что все примеры будут иметь одинаковую длину. Для меток спектрограммы дополняемая части заменяются на специальное значение `-100`.
+Это специальное значение указывает модели игнорировать эту часть спектрограммы при расчете потерь спектрограммы.
+
+```py
+from dataclasses import dataclass
+from typing import Any, Dict, List, Union
+
+
+@dataclass
+class TTSDataCollatorWithPadding:
+ processor: Any
+
+ def __call__(
+ self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
+ ) -> Dict[str, torch.Tensor]:
+ input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
+ label_features = [{"input_values": feature["labels"]} for feature in features]
+ speaker_features = [feature["speaker_embeddings"] for feature in features]
+
+ # collate the inputs and targets into a batch
+ batch = processor.pad(
+ input_ids=input_ids, labels=label_features, return_tensors="pt"
+ )
+
+ # replace padding with -100 to ignore loss correctly
+ batch["labels"] = batch["labels"].masked_fill(
+ batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100
+ )
+
+ # not used during fine-tuning
+ del batch["decoder_attention_mask"]
+
+ # round down target lengths to multiple of reduction factor
+ if model.config.reduction_factor > 1:
+ target_lengths = torch.tensor(
+ [len(feature["input_values"]) for feature in label_features]
+ )
+ target_lengths = target_lengths.new(
+ [
+ length - length % model.config.reduction_factor
+ for length in target_lengths
+ ]
+ )
+ max_length = max(target_lengths)
+ batch["labels"] = batch["labels"][:, :max_length]
+
+ # also add in the speaker embeddings
+ batch["speaker_embeddings"] = torch.tensor(speaker_features)
+
+ return batch
+```
+
+В SpeechT5 входная информация для декодера уменьшается в 2 раза. Другими словами, отбрасывается каждый второй
+временной шаг из целевой последовательности.Затем декодер предсказывает последовательность, которая в два раза длиннее. Поскольку исходная длина
+целевой последовательности [NL] может быть нечетной, коллатор данных обязательно округляет максимальную длину батча до значения [NL], кратного 2.
+
+```py
+data_collator = TTSDataCollatorWithPadding(processor=processor)
+```
+
+## Обучение модели
+
+Загрузите предварительно обученную модель из той же контрольной точки, которая использовалась для загрузки процессора:
+
+```py
+from transformers import SpeechT5ForTextToSpeech
+
+model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)
+```
+
+Опция `use_cache=True` несовместима с использованием градиентных контрольных точек. Отключите ее для обучения и снова включите кэш для генерации,
+чтобы ускорить инференс:
+
+```py
+from functools import partial
+
+# отключить кэш во время обучения, так как он несовместим с градиентными контрольными точками
+model.config.use_cache = False
+
+# заданим язык и задачу для генерации и снова включим кэш
+model.generate = partial(model.generate, use_cache=True)
+```
+
+Определим аргументы обучения. Здесь мы не вычисляем никаких оценочных метрик в процессе обучения,
+мы поговорим об оценке позже в этой главе. Вместо этого мы будем рассматривать только потери:
+
+```python
+from transformers import Seq2SeqTrainingArguments
+
+training_args = Seq2SeqTrainingArguments(
+ output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=8,
+ learning_rate=1e-5,
+ warmup_steps=500,
+ max_steps=4000,
+ gradient_checkpointing=True,
+ fp16=True,
+ evaluation_strategy="steps",
+ per_device_eval_batch_size=2,
+ save_steps=1000,
+ eval_steps=1000,
+ logging_steps=25,
+ report_to=["tensorboard"],
+ load_best_model_at_end=True,
+ greater_is_better=False,
+ label_names=["labels"],
+ push_to_hub=True,
+)
+```
+
+Инстанцируем объект `Trainer` и передаем ему модель, набор данных и коллатор данных.
+
+```py
+from transformers import Seq2SeqTrainer
+
+trainer = Seq2SeqTrainer(
+ args=training_args,
+ model=model,
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
+ data_collator=data_collator,
+ tokenizer=processor,
+)
+```
+
+И с этим мы готовы приступить к обучению! Обучение займет несколько часов. В зависимости от используемого GPU
+возможно, что при начале обучения возникнет ошибка CUDA "out-of-memory". В этом случае можно уменьшить
+размер `per_device_train_batch_size` постепенно в 2 раза и увеличить `gradient_accumulation_steps` в 2 раза, чтобы компенсировать это.
+
+```py
+trainer.train()
+```
+
+Push the final model to the 🤗 Hub:
+
+```py
+trainer.push_to_hub()
+```
+
+## Инференс
+
+После того как модель дообучена, ее можно использовать для инференса! Загрузите модель из 🤗 Hub (убедитесь, что в
+следующем фрагменте кода используется имя вашей учетной записи):
+
+```py
+model = SpeechT5ForTextToSpeech.from_pretrained(
+ "YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl"
+)
+```
+
+Выберем пример, здесь мы возьмем пример из тестового набора данных. Получаем эмбеддинги диктора.
+
+```py
+example = dataset["test"][304]
+speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
+```
+
+Определим некоторый входной текст и токенизируем его.
+
+```py
+text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
+```
+
+Выполним препроцессинг входного текста:
+
+```py
+inputs = processor(text=text, return_tensors="pt")
+```
+
+Инстанцируем вокодер и сгенерируем речь:
+
+```py
+from transformers import SpeechT5HifiGan
+
+vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
+speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
+```
+
+Готовы послушать результат?
+
+```py
+from IPython.display import Audio
+
+Audio(speech.numpy(), rate=16000)
+```
+
+Получение удовлетворительных результатов с помощью этой модели на новом языке может оказаться непростой задачей. Качество эмбеддингов диктора
+может быть существенным фактором. Поскольку SpeechT5 была предварительно обучена на английских x-векторах, она показывает наилучшие результаты
+при использовании эмбеддингов английских дикторов. Если синтезированная речь звучит плохо, попробуйте использовать другие эмбеддинги диктора.
+
+Увеличение продолжительности обучения, вероятно, также повысит качество результатов. Несмотря на это, речь явно голландская, а не английская, и в ней
+передаются особенности голоса говорящего (сравните с оригинальным аудио в примере).
+Еще один момент, с которым можно поэкспериментировать, - это настройка модели. Например, попробуйте использовать `config.reduction_factor = 1`, чтобы
+посмотреть, улучшит ли это результаты.
+
+В следующем разделе мы расскажем о том, как мы оцениваем модели преобразования текста в речь.
diff --git a/chapters/ru/chapter6/hands_on.mdx b/chapters/ru/chapter6/hands_on.mdx
new file mode 100644
index 00000000..59690ef5
--- /dev/null
+++ b/chapters/ru/chapter6/hands_on.mdx
@@ -0,0 +1,21 @@
+# Практическое занятие
+
+В этом разделе мы рассмотрели аудиозадачу преобразования текста в речь, рассказали о существующих наборах данных, предварительно обученных
+моделях и нюансах дообучения SpeechT5 для нового языка.
+
+Как вы убедились, дообучение моделей для задач преобразования текста в речь может быть сложной задачей в условиях ограниченных ресурсов. В то же время
+оценивать модели преобразования текста в речь также нелегко.
+
+По этим причинам данное практическое занятие будет направлено на отработку навыков, а не на достижение определенного значения метрики.
+
+Ваша задача - провести дообучение SpeechT5 на выбранном вами наборе данных. Вы можете выбрать
+другой язык из того же набора данных `voxpopuli`, либо выбрать любой другой набор данных, приведенный в этом разделе.
+
+Помните о размере обучающих данных! Для обучения на GPU бесплатного уровня в Google Colab мы рекомендуем ограничить объем обучающих
+данных примерно до 10-15 часов.
+
+После завершения процесса дообучения поделитесь своей моделью, загрузив ее в Hub. Обязательно пометьте модель
+как модель `text-to-speech` либо соответствующими параметрами kwargs, либо через графический интерфейс Hub.
+
+Помните, что основная цель этого упражнения - предоставить вам обширную практику, которая позволит вам отточить свои навыки и
+получить более глубокое представление об аудиозадачах преобразования текста в речь.
diff --git a/chapters/ru/chapter6/introduction.mdx b/chapters/ru/chapter6/introduction.mdx
new file mode 100644
index 00000000..86806abc
--- /dev/null
+++ b/chapters/ru/chapter6/introduction.mdx
@@ -0,0 +1,29 @@
+# Раздел 6. От текста к речи
+
+В предыдущем разделе вы узнали, как использовать трансформеры для преобразования устной речи в текст. Теперь давайте перевернем сценарий
+и посмотрим, как можно преобразовать заданный входной текст в аудио вывод, звучащий как человеческая речь.
+
+Задача, которую мы будем изучать в этом блоке, называется "Преобразование текста в речь " (Text-to-speech, TTS). Модели, способные преобразовывать текст в слышимую
+человеческую речь, имеют широкий спектр потенциальных применений:
+
+* Вспомогательные приложения: подумайте об инструментах, которые могут использовать эти модели для обеспечения доступа людей с ослабленным зрением к цифровому контенту с помощью звука.
+* Озвучивание аудиокниг: перевод письменных книг в аудиоформат делает литературу более доступной для тех, кто предпочитает слушать или испытывает трудности с чтением.
+* Виртуальные помощники: TTS-модели являются фундаментальным компонентом виртуальных помощников, таких как Siri, Google Assistant или Amazon Alexa. После того как они с помощью классификационной модели поймали слово "пробуждение" и использовали ASR-модель для обработки запроса, они могут использовать TTS-модель для ответа на ваш запрос.
+* Развлечения, игры и изучение языков: озвучивайте персонажей NPC, рассказывайте об игровых событиях или помогайте изучающим язык примерами правильного произношения и интонации слов и фраз.
+
+Это лишь некоторые примеры, и я уверен, что вы можете придумать множество других! Однако с такой мощью приходит и ответственность
+,важно подчеркнуть, что модели TTS потенциально могут быть использованы в злонамеренных целях.
+Например, имея достаточное количество образцов голоса, злоумышленники могут создавать убедительные поддельные аудиозаписи, что приводит к
+несанкционированному использованию голоса человека в мошеннических целях или для манипуляций. Если вы планируете собирать данные для дообучения
+собственных систем, тщательно продумайте вопросы конфиденциальности и информационного согласия. Получение голосовых данных должно осуществляться с явного согласия
+людей, при этом они должны понимать цель, объем и потенциальные риски, связанные с использованием их голоса
+в системе TTS. Пожалуйста, используйте преобразование текста в речь ответственно.
+
+## Чему вы научитесь и что создадите
+
+В этом разделе мы поговорим о:
+
+* [Наборах данных, пригодных для обучения Text-to-speech](tts_datasets)
+* [Предварительно обученных моделях для преобразования текста в речь](pre-trained_models)
+* [Дообучение SpeechT5 на новом языке](fine-tuning)
+* [Оценке моделей TTS](evaluation)
diff --git a/chapters/ru/chapter6/pre-trained_models.mdx b/chapters/ru/chapter6/pre-trained_models.mdx
new file mode 100644
index 00000000..dcf7e10a
--- /dev/null
+++ b/chapters/ru/chapter6/pre-trained_models.mdx
@@ -0,0 +1,258 @@
+# Предварительно обученные модели text-to-speech
+
+По сравнению с задачами ASR (автоматическое распознавание речи) и классификации звука, здесь значительно меньше предварительно обученных
+контрольных точек. На 🤗 Hub вы найдете около 300 подходящих контрольных точек. Среди
+этих предварительно обученных моделей мы остановимся на двух архитектурах, которые легко доступны для вас в библиотеке
+🤗 Transformers - SpeechT5 и Massive Multilingual Speech (MMS).
+В этом разделе мы рассмотрим, как использовать эти предварительно обученные модели в библиотеке Transformers для TTS.
+
+## SpeechT5
+
+[SpeechT5](https://arxiv.org/abs/2110.07205) - это модель, опубликованная Джуньи Ао и другими специалистами компании Microsoft, которая способна
+решать целый ряд речевых задач. Несмотря на то, что в данном разделе мы сосредоточились на аспекте преобразования текста в речь,
+эта модель может быть адаптирована как для задач преобразования речи в текст (автоматическое распознавание речи или идентификация диктора),
+так и для задач преобразования речи в речь (например, улучшение речи или преобразование между различными голосами). Это обусловлено тем, как эта модель
+была спроектирована и предварительно обучена.
+
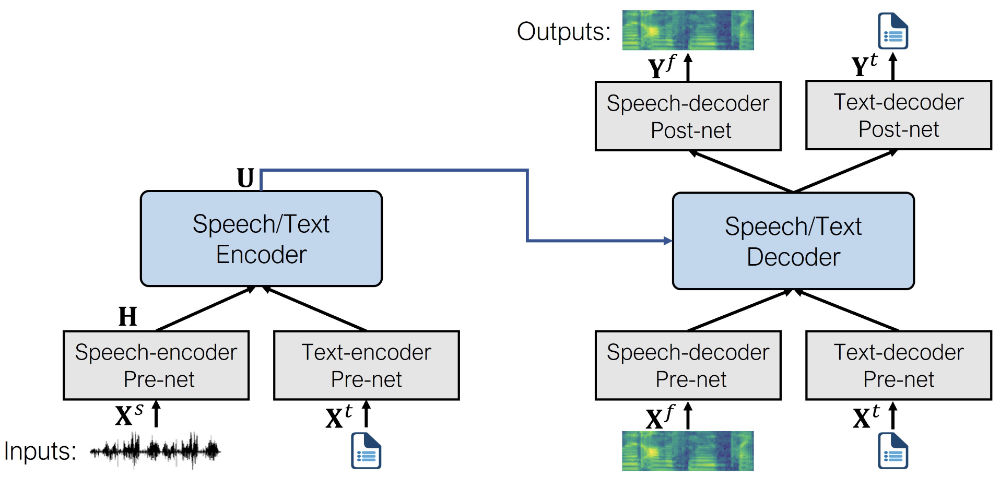
+В основе SpeechT5 лежит обычная модель трансформера энкодер-декодер. Как и любой другой трансформер, модель энкодер-декодер
+осуществляет преобразование последовательности в последовательность с использованием скрытых представлений. Эта основа трансформера
+одинакова для всех задач, поддерживаемых SpeechT5.
+
+Этот трансформер дополнен шестью модально-специфическими (речь/текст) _пред-сетями_ и _пост-сетями_. Входная речь или текст
+(в зависимости от задачи) предварительно обрабатывается через соответствующую предварительную сеть для получения скрытых представлений, которые может использовать трансформер.
+Выходные данные трансформера передаются в пост-сеть, которая использует их для генерации вывода в целевой модальности.
+
+Вот как выглядит архитектура (изображение из оригинальной статьи):
+
+
+
+  +
+
+
+SpeechT5 сначала проходит предварительное обучение на больших объемах немаркированных речевых и текстовых данных, чтобы получить единое представление
+различных модальностей. На этапе предварительного обучения все предварительные и последующие сети используются одновременно.
+
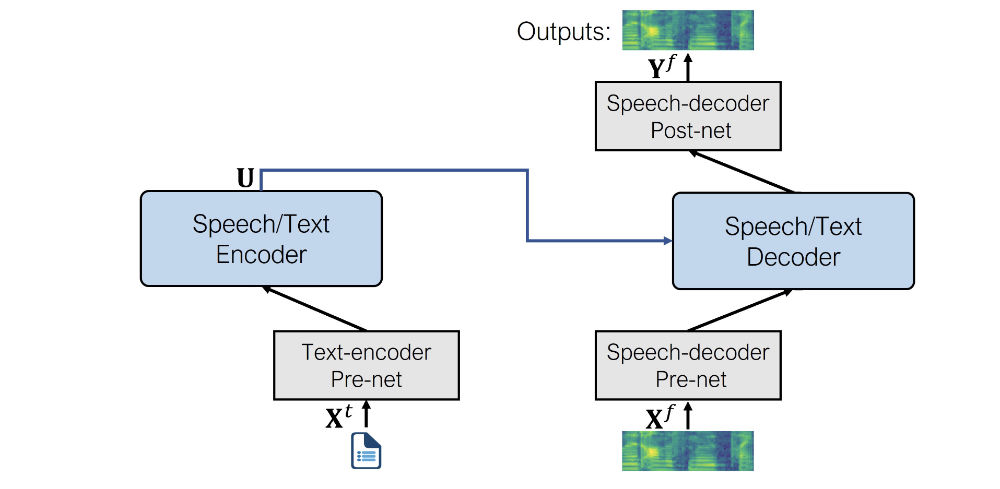
+После предварительного обучения вся структура энкодера-декодера настраивается для каждой конкретной задачи. На этом этапе используются только те
+пред-сети и пост-сети, которые имеют отношение к конкретной задаче. Например, чтобы использовать SpeechT5 для преобразования текста в речь, необходимо
+использовать предварительную сеть энкодера текста для текстовых входов и предварительную и пост-сети декодера речи для речевых выходов.
+
+Такой подход позволяет получить несколько моделей, дообученных для различных речевых задач, все они выигрывают от первоначального
+предварительного обучения на немаркированных данных.
+
+
+
+  +
+
+
+Как видите, на выходе получается лог-мел спектрограмма, а не конечная форма волны. Если вы помните, мы вкратце касались
+этой темы в [Разделе 3](../chapter3/introduction#spectrogram-output). Обычно модели, генерирующие звук, выдают
+лог мел спектограмму, которой необходимо преобразовать в форму волны с помощью дополнительной нейронной сети, называемой вокодером.
+
+Давайте посмотрим, как это можно сделать.
+
+Сначала загрузим из 🤗 Hub настроенную TTS-модель SpeechT5, а также объект процессора, используемый для токенизации
+и извлечения признаков:
+
+```python
+from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
+
+processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
+model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
+```
+
+Далее необходимо выполнить токенизацию входного текста.
+
+```python
+inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")
+```
+
+Модель SpeechT5 TTS не ограничивается созданием речи для одного диктора. Вместо этого она использует так называемые эмбединги диктора,
+которые фиксируют голосовые характеристики конкретного диктора.
+
+
+transformers из ветки PR:
+ git+https://github.com/hollance/transformers.git@6900e8ba6532162a8613d2270ec2286c3f58f57b
+  +
+
+
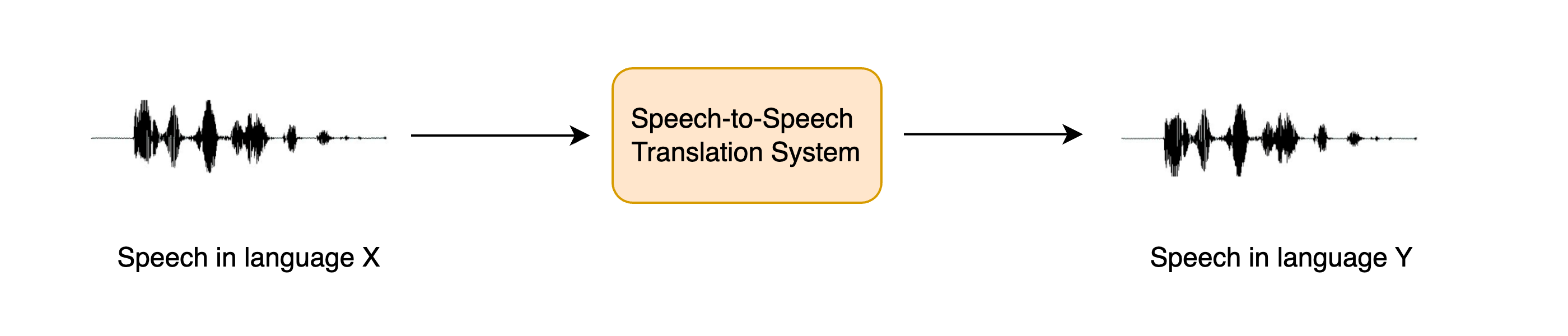
+STST можно рассматривать как расширение традиционной задачи машинного перевода (МТ): вместо перевода **текста** с одного языка
+на другой мы переводим **речь** с одного языка на другой. STST находит применение в области многоязыковой коммуникации,
+позволяя носителям разных языков общаться друг с другом посредством речи.
+
+Предположим, вы хотите общаться с другим человеком, преодолевая языковой барьер. Вместо того чтобы писать информацию, которую вы хотите
+передать, а затем переводить ее в текст на целевом языке, вы можете говорить напрямую, а система STST преобразует вашу устную речь
+в целевой язык. Получатель может ответить, обратившись к системе STST, а вы можете прослушать его ответ. Это более естественный
+способ общения по сравнению с машинным переводом текста.
+
+В этом разделе мы рассмотрим *каскадный* подход к STST, объединив знания, полученные в разделах 5 и 6 курса. Мы будем использовать
+систему *перевода речи (ST)* для транскрибирования исходной речи в текст на целевом языке, а затем *перевода текста в речь (TTS)*
+для генерации речи на целевом языке из переведенного текста:
+
+
+
+  +
+
+
+Можно было бы использовать и трехэтапный подход, когда сначала с помощью системы автоматического распознавания речи (ASR) исходная речь транскрибируется в текст на том же
+языке, затем с помощью машинного перевода транскрибированный текст переводится на целевой язык, и, наконец, с помощью преобразования текста в речь формируется речь
+на целевом языке. Однако добавление большего числа компонентов в конвейер приводит к *распространению ошибок*, когда ошибки, вносимые в одну систему, усугубляются
+при прохождении через остальные системы, а также к увеличению задержки, поскольку инференс приходится проводить для большего числа моделей.
+
+Несмотря на то, что такой каскадный подход к STST достаточно прост, он позволяет создавать очень эффективные системы STST. Трехступенчатая каскадная система ASR + MT + TTS
+ранее использовалась для работы многих коммерческих продуктов STST, в том числе [Google Translate](https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html).
+
+Это также очень эффективный способ разработки STST-системы, поскольку существующие системы распознавания речи и преобразования текста в речь могут быть объединены
+для получения новой STST-модели без дополнительного обучения.
+
+В оставшейся части этого раздела мы сосредоточимся на создании системы STST, которая переводит речь с любого языка X в речь на английском языке.
+Рассмотренные методы могут быть распространены на системы STST, переводящие с любого языка X на любой язык Y, но мы оставляем это на усмотрение читателя и
+указываем, где это возможно.Далее мы разделяем задачу STST на две составные части: ST и TTS. В завершение мы соединим их вместе и создадин демо с помощью Gradio
+для демонстрации нашей системы.
+
+## Перевод речи
+
+Мы будем использовать модель Whisper для нашей системы перевода речи, поскольку эта модель способна переводить с более чем 96 языков на английский.
+В частности, мы загрузим контрольную точку [Whisper Base](https://huggingface.co/openai/whisper-base), которая имеет 74М параметров. Это далеко не самая производительная
+модель Whisper, поскольку [наибольшая контрольная точка Whisper](https://huggingface.co/openai/whisper-large-v2) более чем в 20 раз больше, но поскольку мы объединяем две
+авторегрессивные системы (ST + TTS), мы хотим, чтобы каждая модель могла работать относительно быстро, чтобы мы получили приемлемую скорость инференса:
+
+```python
+import torch
+from transformers import pipeline
+
+device = "cuda:0" if torch.cuda.is_available() else "cpu"
+pipe = pipeline(
+ "automatic-speech-recognition", model="openai/whisper-base", device=device
+)
+```
+
+Отлично! Для проверки нашей системы STST загрузим аудиопример на неанглийском языке. Загрузим первый пример из итальянской (`it`) части
+датасета [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli):
+
+```python
+from datasets import load_dataset
+
+dataset = load_dataset("facebook/voxpopuli", "it", split="validation", streaming=True)
+sample = next(iter(dataset))
+```
+
+Чтобы прослушать этот пример, мы можем либо воспроизвести его с помощью средства просмотра набора данных на Hub: [facebook/voxpopuli/viewer](https://huggingface.co/datasets/facebook/voxpopuli/viewer/it/validation?row=0)
+
+Или воспроизведение с помощью функции ipynb audio:
+
+```python
+from IPython.display import Audio
+
+Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
+```
+
+Теперь определим функцию, которая принимает этот аудиовход и возвращает переведенный текст. Вы помните, что мы должны передать ключевое слово генерации аргументу `"task"`,
+установив его в значение `"translate"`, чтобы убедиться, что Whisper выполняет перевод речи, а не ее распознавание:
+
+```python
+def translate(audio):
+ outputs = pipe(audio, max_new_tokens=256, generate_kwargs={"task": "translate"})
+ return outputs["text"]
+```
+
+
+
+  +
+
+
+## Диаризация диктора
+
+Диаризация диктора (или диаризация) - это задача получения немаркированных аудиоданных и прогнозирования того, "кто когда говорил". При этом мы можем
+прогнозировать временные метки начала/окончания каждой очереди дикторов, соответствующие моменту начала речи и моменту ее окончания.
+
+🤗 В настоящее время в библиотеке Transformers нет модели для диаризации диктора, но на Hub есть контрольные точки, которые можно использовать
+с относительной легкостью. В этом примере мы будем использовать предварительно обученную модель диаризации диктора из [pyannote.audio](https://github.com/pyannote/pyannote-audio).
+Давайте приступим к работе и установим пакет с помощью pip:
+
+```bash
+pip install --upgrade pyannote.audio
+```
+
+Отлично! Веса для этой модели размещены на Hugging Face Hub. Чтобы получить к ним доступ, сначала нужно согласиться с условиями использования модели диаризации
+диктора: [pyannote/speaker-diarization](https://huggingface.co/pyannote/speaker-diarization). А затем - с условиями использования модели
+сегментации: [pyannote/segmentation](https://huggingface.co/pyannote/segmentation).
+
+После завершения работы мы можем загрузить предварительно обученный конвейер диаризации дикторов локально на наше устройство:
+
+```python
+from pyannote.audio import Pipeline
+
+diarization_pipeline = Pipeline.from_pretrained(
+ "pyannote/speaker-diarization@2.1", use_auth_token=True
+)
+```
+
+Давайте опробуем его на примере аудиофайла! Для этого мы загрузим образец из датасета [LibriSpeech ASR](https://huggingface.co/datasets/librispeech_asr), содержащий речь
+двух разных дикторов, который мы объединили в один аудиофайл:
+
+```python
+from datasets import load_dataset
+
+concatenated_librispeech = load_dataset(
+ "sanchit-gandhi/concatenated_librispeech", split="train", streaming=True
+)
+sample = next(iter(concatenated_librispeech))
+```
+
+Мы можем прослушать аудиозапись, чтобы понять, как она звучит:
+
+```python
+from IPython.display import Audio
+
+Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
+```
+
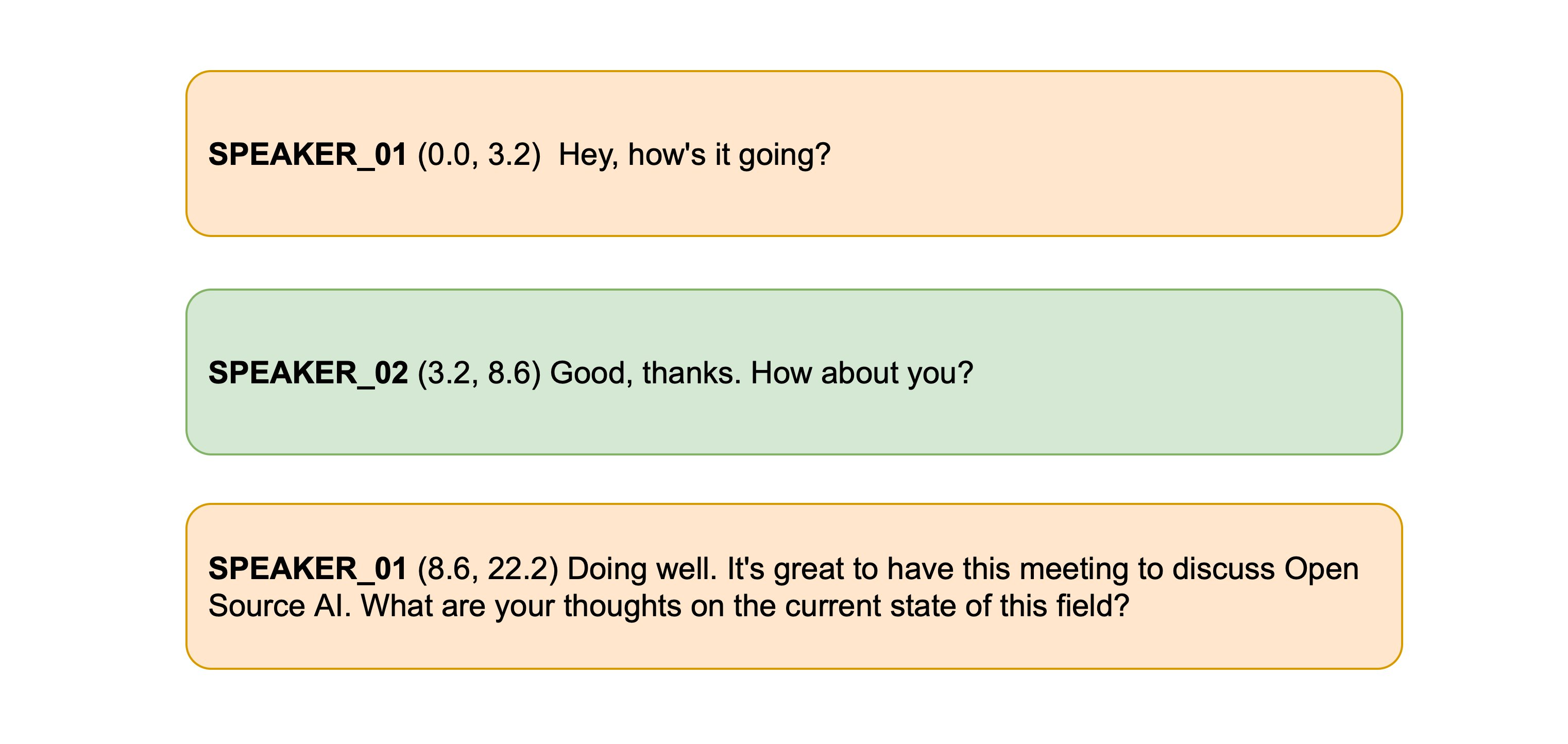
+Класс! Мы отчетливо слышим двух разных дикторов с переходом примерно на 15 секунде звучания. Давайте передадим этот аудиофайл в модель диаризации, чтобы получить
+время начала и окончания разговора. Заметим, что pyannote.audio ожидает, что входной аудиофайл будет представлять собой тензор PyTorch формы `(channels, seq_len)`,
+поэтому перед запуском модели нам необходимо выполнить это преобразование:
+
+```python
+import torch
+
+input_tensor = torch.from_numpy(sample["audio"]["array"][None, :]).float()
+outputs = diarization_pipeline(
+ {"waveform": input_tensor, "sample_rate": sample["audio"]["sampling_rate"]}
+)
+
+outputs.for_json()["content"]
+```
+
+```text
+[{'segment': {'start': 0.4978125, 'end': 14.520937500000002},
+ 'track': 'B',
+ 'label': 'SPEAKER_01'},
+ {'segment': {'start': 15.364687500000002, 'end': 21.3721875},
+ 'track': 'A',
+ 'label': 'SPEAKER_00'}]
+```
+
+Выглядит это довольно неплохо! Видно, что первый диктор говорит до отметки 14,5 секунды, а второй - с 15,4 секунды.
+Теперь нам нужно получить транскрипцию!
+
+## Транскрибирование речи
+
+В третий раз в этом блоке мы будем использовать модель Whisper для нашей системы транскрипции речи. В частности, мы загрузим контрольную точку [Whisper Base](https://huggingface.co/openai/whisper-base),
+поскольку она достаточно мала, чтобы обеспечить хорошую скорость инференса при приемлемой точности транскрипции. Как и прежде, вы можете использовать любую контрольную точку распознавания речи с
+[Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=transformers&sort=trending), включая Wav2Vec2, MMS ASR или другие контрольные точки Whisper:
+
+```python
+from transformers import pipeline
+
+asr_pipeline = pipeline(
+ "automatic-speech-recognition",
+ model="openai/whisper-base",
+)
+```
+
+Давайте получим транскрипцию для нашего образца аудиозаписи, возвращая также временные метки на уровне сегментов, чтобы знать время начала и окончания каждого сегмента.
+Из раздела 5 вы помните, что для активации задачи прогнозирования временных меток в Whisper нам необходимо передать аргумент `return_timestamps=True`:
+
+```python
+asr_pipeline(
+ sample["audio"].copy(),
+ generate_kwargs={"max_new_tokens": 256},
+ return_timestamps=True,
+)
+```
+
+```text
+{
+ "text": " The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight. He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
+ "chunks": [
+ {"timestamp": (0.0, 3.56), "text": " The second and importance is as follows."},
+ {
+ "timestamp": (3.56, 7.84),
+ "text": " Sovereignty may be defined to be the right of making laws.",
+ },
+ {
+ "timestamp": (7.84, 13.88),
+ "text": " In France, the king really exercises a portion of the sovereign power, since the laws have",
+ },
+ {"timestamp": (13.88, 15.48), "text": " no weight."},
+ {
+ "timestamp": (15.48, 19.44),
+ "text": " He was in a favored state of mind, owing to the blight his wife's action threatened to",
+ },
+ {"timestamp": (19.44, 21.28), "text": " cast upon his entire future."},
+ ],
+}
+```
+
+Отлично! Мы видим, что каждый сегмент транскрипции имеет начальное и конечное время, причем смена дикторов происходит на отметке 15,48 секунды. Теперь мы можем сопоставить
+эту транскрипцию с временными метками дикторов, полученными с помощью модели диаризации, и получить окончательную транскрипцию.
+
+## Speechbox
+
+Чтобы получить окончательную транскрипцию, совместим временные метки, полученные с помощью модели диаризации, с временными метками, полученными с помощью модели Whisper.
+Модель диаризации предсказала окончание речи первого диктора на 14,5 с, а второго - на 15,4 с, в то время как Whisper предсказал границы сегментов на 13,88, 15,48 и 19,44 с соответственно.
+Поскольку временные метки, полученные с помощью Whisper, не полностью совпадают с данными модели диаризации, нам необходимо найти, какие из этих границ ближе всего к 14,5 и 15,4 с, и
+соответствующим образом сегментировать транскрипцию по дикторам. В частности, мы найдем наиболее близкое совпадение между временными метками диаризации и транскрипции,
+минимизировав абсолютное расстояние между ними.
+
+К счастью для нас, мы можем использовать пакет 🤗 Speechbox для выполнения этого выравнивания. Сначала давайте установим пакет `speechbox` из main:
+
+```bash
+pip install git+https://github.com/huggingface/speechbox
+```
+
+Теперь мы можем инстанцировать наш комбинированный конвейер диаризации и транскрипции, передав модель диаризации и
+модель ASR в класс [`ASRDiarizationPipeline`](https://github.com/huggingface/speechbox/tree/main#asr-with-speaker-diarization):
+
+```python
+from speechbox import ASRDiarizationPipeline
+
+pipeline = ASRDiarizationPipeline(
+ asr_pipeline=asr_pipeline, diarization_pipeline=diarization_pipeline
+)
+```
+
+ASRDiarizationPipeline directly непосредственно из предварительно обученных моделей, указав идентификатор
+ модели ASR на Hub:
+ pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-base")
+  +
+
+
+### 1. Обнаружение слова активации
+
+Голосовые помощники постоянно прослушивают аудиосигналы, поступающие через микрофон вашего устройства, но включаются
+в работу только после произнесения определенного 'слова активации' или 'триггерного слова'.
+
+Задачу обнаружения слов активации решает небольшая модель классификации звука на устройстве, которая значительно меньше и легче модели
+распознавания речи - часто всего несколько миллионов параметров по сравнению с несколькими сотнями миллионов для распознавания речи. Таким
+образом, она может постоянно работать на устройстве, не разряжая аккумулятор. Только при обнаружении "слова активации" запускается более
+крупная модель распознавания речи, после чего она снова отключается.
+
+### 2. Транскрибирование речи
+
+Следующий этап - транскрибация произнесенного запроса в текст. На практике передача аудиофайлов с локального устройства в облако происходит
+медленно из-за большого размера аудиофайлов, поэтому эффективнее транскрибировать их напрямую с помощью модели автоматического распознавания речи (ASR)
+на устройстве, а не использовать модель в облаке. Модель на устройстве может быть меньше и, следовательно, менее точной, чем модель, размещенная в облаке,
+но более высокая скорость инференса оправдывает себя, поскольку мы можем работать с распознаванием речи практически в реальном времени, транскрибируя
+произнесенные нами фразы по мере их произнесения.
+
+Мы уже хорошо знакомы с процессом распознавания речи, так что это должно быть проще простого!
+
+### 3. Запрос к языковой модели
+
+Теперь, когда мы знаем, что спросил пользователь, нам нужно сгенерировать ответ! Лучшими моделями-кандидатами для решения этой задачи являются
+*большие языковые модели (Large Language Models, LLM)*, поскольку они способны эффективно понять семантику текстового запроса
+и сгенерировать подходящий ответ.
+
+Поскольку наш текстовый запрос невелик (всего несколько текстовых токенов), а языковые модели велики (многие миллиарды параметров), наиболее эффективным
+способом проведения инференса LLM является отправка текстового запроса с устройства на LLM, запущенную в облаке, генерация текстового ответа и возврат
+ответа обратно на устройство.
+
+### 4. Синтез речи
+
+Наконец, мы используем модель преобразования текста в речь (TTS) для синтеза текстового ответа в устную речь. Это делается на устройстве, но можно запустить
+модель TTS в облаке, генерируя аудио вывод и передавая его обратно на устройство.
+
+Опять же, мы делали это уже несколько раз, так что процесс будет очень знакомым!
+
+## Обнаружение слова активации
+
+Первым этапом работы голосового помощника является определение того, было ли произнесено слово активации, для решения этой задачи нам необходимо найти подходящую
+предварительно обученную модель! Из раздела [Предварительно обученные модели классификации звука](../chapter4/classification_models) вы помните, что
+[Speech Commands](https://huggingface.co/datasets/speech_commands) - это набор устных слов, предназначенный для оценки моделей классификации звука на 15+ простых
+командных словах, таких как `"вверх"`, `"вниз"`, `"да"` и `"нет"`, а также метка `"тишина"` для классификации отсутствия речи. Уделите минутку прослушиванию
+образцов в программе просмотра наборов данных на Hub и заново познакомиться с набором данных Speech Commands: [datasets viewer](https://huggingface.co/datasets/speech_commands/viewer/v0.01/train).
+
+Мы можем взять модель классификации звука, предварительно обученную на наборе данных Speech Commands, и выбрать одно из этих простых командных слов
+в качестве слова активации. Если из 15 с лишним возможных командных слов модель предсказывает выбранное нами слово активации с наибольшей
+вероятностью, мы можем быть уверены, что оно было произнесено".
+
+Давайте зайдем в Hugging Face Hub и перейдем на вкладку "Models": https://huggingface.co/models.
+
+В результате будут отображены все модели на Hugging Face Hub, отсортированные по количеству загрузок за последние 30 дней:
+
+
+
+  +
+
+
+С левой стороны вы заметите, что у нас есть ряд вкладок, которые мы можем выбрать для фильтрации моделей по задачам, библиотекам, набору данных и т.д.
+Прокрутите страницу вниз и выберите задачу " Audio Classification " из списка задач аудио:
+
+
+
+  +
+
+
+Теперь нам представлено подмножество из 500+ моделей классификации звука на Hub. Для дальнейшего уточнения этой выборки мы можем
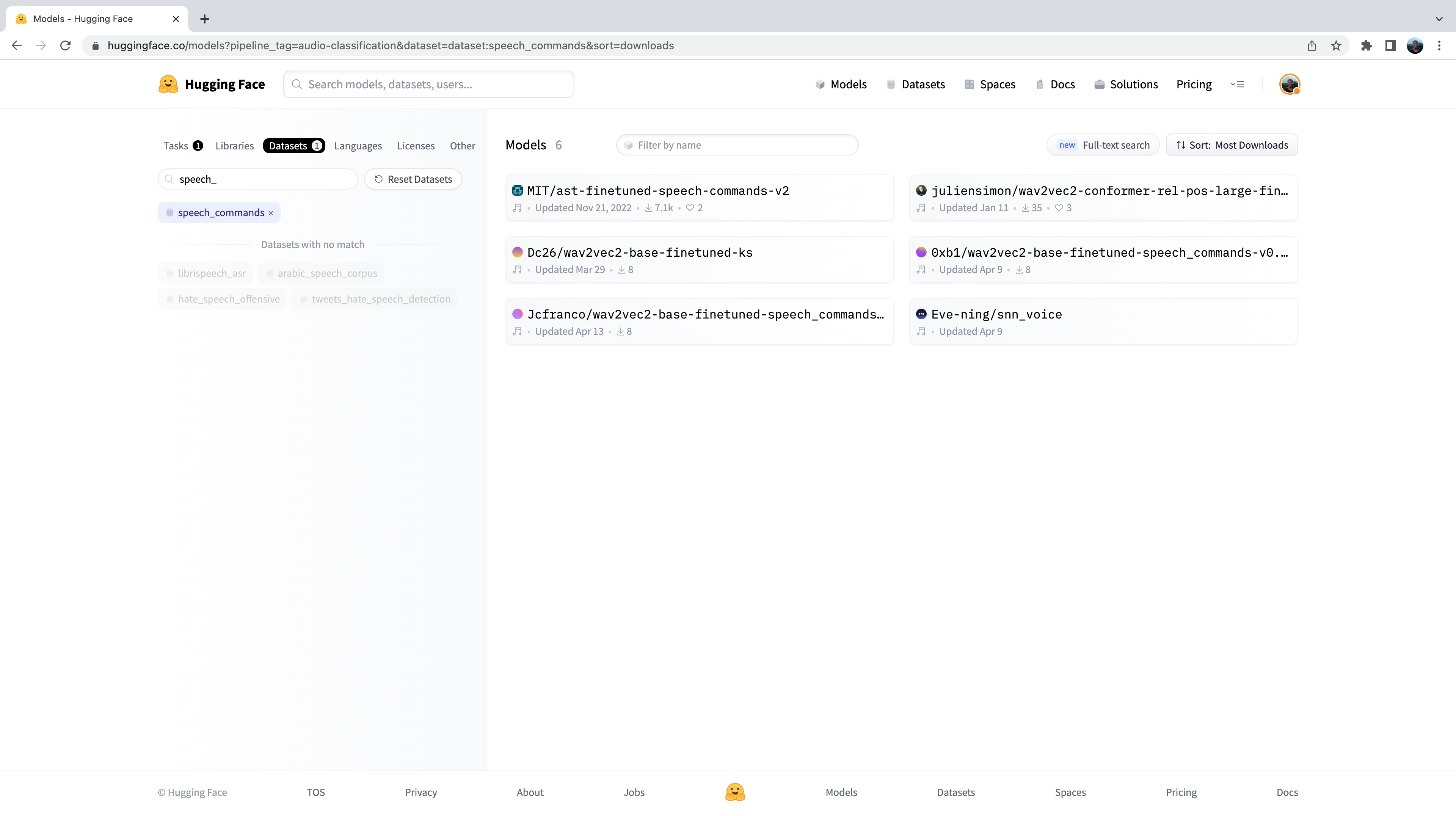
+отфильтровать модели по датасету. Перейдите на вкладку "Datasets" и в строке поиска введите "speech_commands". При вводе текста
+под вкладкой поиска появится выделение `speech_commands. Нажав на эту кнопку, можно отфильтровать все модели классификации звука на те,
+которые были дообучены на датасете Speech Commands:
+
+
+
+  +
+
+
+Отлично! Мы видим, что для данного датасета и задачи нам доступны шесть предварительно обученных моделей (хотя, если вы
+читаете этот материал позднее, могут быть добавлены новые модели!) Первую из этих моделей вы узнаете как [Audio Spectrogram Transformer checkpoint](https://huggingface.co/MIT/ast-finetuned-speech-commands-v2)
+которую мы использовали в примере 4-го раздела. Мы снова будем использовать эту контрольную точку для задачи определения слова активации.
+
+Перейдем к загрузке контрольной точки с помощью класса `pipeline`:
+
+```python
+from transformers import pipeline
+import torch
+
+device = "cuda:0" if torch.cuda.is_available() else "cpu"
+
+classifier = pipeline(
+ "audio-classification", model="MIT/ast-finetuned-speech-commands-v2", device=device
+)
+```
+
+Мы можем проверить, на каких метках обучалась модель, проверив атрибут `id2label` в конфигурации модели:
+
+```python
+classifier.model.config.id2label
+```
+
+Отлично! Мы видим, что модель была обучена на 35 метках классов, включая некоторые простые командные слова, которые мы описали выше, а
+также некоторые конкретные объекты, такие как `"bed"`, `"house"` и `"cat"`. Мы видим, что в этих метках класса есть одно имя:
+id 27 соответствует метке **"marvin "**:
+
+```python
+classifier.model.config.id2label[27]
+```
+
+```
+'marvin'
+```
+
+Отлично! Мы можем использовать это имя в качестве слова активации для нашего голосового помощника, подобно тому, как используется
+"Alexa" для Amazon Alexa или "Hey Siri" для Apple Siri. Если из всех возможных меток модель с наибольшей вероятностью предсказывает
+`"marvin"`, мы можем быть уверены, что выбранное нами слово активации было произнесено.
+
+Теперь нам необходимо определить функцию, которая будет постоянно прослушивать микрофонный вход нашего устройства и непрерывно передавать
+звук в модель классификации для проведения инференса. Для этого мы воспользуемся удобной вспомогательной функцией, входящей
+в состав 🤗 Transformers, под названием [`ffmpeg_microphone_live`](https://github.com/huggingface/transformers/blob/fb78769b9c053876ed7ae152ee995b0439a4462a/src/transformers/pipelines/audio_utils.py#L98).
+
+Эта функция направляет в модель для классификации небольшие фрагменты звука заданной длины `chunk_length_s`. Для обеспечения плавных
+границ между фрагментами звука мы используем скользящее окно с шагом `chunk_length_s / 6`. Чтобы не ждать, пока запишется весь первый фрагмент,
+прежде чем приступить к инференсу, мы также определяем минимальную продолжительность по времени аудио входа `stream_chunk_s`,
+который передается в модель до достижения времени `chunk_length_s`.
+
+Функция `ffmpeg_microphone_live` возвращает объект *generator*, создающий последовательность аудиофрагментов, каждый из которых может быть
+передан модели классификации для предсказания. Мы можем передать этот генератор непосредственно в `pipeline`, который, в свою очередь,
+возвращает на выходе последовательность прогнозов, по одному для каждого фрагмента входного аудиосигнала. Мы можем просмотреть вероятности
+меток классов для каждого фрагмента и остановить цикл обнаружения слов активации, когда обнаружим, что слово активации было произнесено.
+
+Для классификации произнесения слова активации мы будем использовать очень простой критерий: если метка класса с наибольшей вероятностью является
+словом активации и эта вероятность превышает порог `prob_threshold`, то мы объявляем, что слово активации было произнесено. Использование порога
+вероятности для управления классификатором таким образом гарантирует, что слово активации не будет ошибочно предсказано, если аудиосигнал является
+шумом, что обычно происходит, когда модель очень неопределенна и все вероятности меток классов низки. Возможно, вы захотите настроить этот порог
+вероятности или использовать более сложные средства для принятия решения о слове активации с помощью метрики [*entropy*](https://en.wikipedia.org/wiki/Entropy_(information_theory))
+(или метрики, основанной на неопределенности).
+
+```python
+from transformers.pipelines.audio_utils import ffmpeg_microphone_live
+
+
+def launch_fn(
+ wake_word="marvin",
+ prob_threshold=0.5,
+ chunk_length_s=2.0,
+ stream_chunk_s=0.25,
+ debug=False,
+):
+ if wake_word not in classifier.model.config.label2id.keys():
+ raise ValueError(
+ f"Wake word {wake_word} not in set of valid class labels, pick a wake word in the set {classifier.model.config.label2id.keys()}."
+ )
+
+ sampling_rate = classifier.feature_extractor.sampling_rate
+
+ mic = ffmpeg_microphone_live(
+ sampling_rate=sampling_rate,
+ chunk_length_s=chunk_length_s,
+ stream_chunk_s=stream_chunk_s,
+ )
+
+ print("Listening for wake word...")
+ for prediction in classifier(mic):
+ prediction = prediction[0]
+ if debug:
+ print(prediction)
+ if prediction["label"] == wake_word:
+ if prediction["score"] > prob_threshold:
+ return True
+```
+
+Давайте опробуем эту функцию и посмотрим, как она работает! Установим флаг `debug=True`, чтобы выводить прогнозы для каждого фрагмента звука. Пусть модель
+поработает несколько секунд, чтобы увидеть, какие предсказания она делает при отсутствии речевого ввода, затем четко произнесем слово активации `"marvin"`
+и увидим, как предсказание метки класса для `"marvin"` подскочит почти до 1:
+
+```python
+launch_fn(debug=True)
+```
+
+```text
+Listening for wake word...
+{'score': 0.055326107889413834, 'label': 'one'}
+{'score': 0.05999856814742088, 'label': 'off'}
+{'score': 0.1282748430967331, 'label': 'five'}
+{'score': 0.07310110330581665, 'label': 'follow'}
+{'score': 0.06634809821844101, 'label': 'follow'}
+{'score': 0.05992642417550087, 'label': 'tree'}
+{'score': 0.05992642417550087, 'label': 'tree'}
+{'score': 0.999913215637207, 'label': 'marvin'}
+```
+
+Потрясающе! Как мы и ожидали, в течение первых нескольких секунд модель генерирует "мусорные" предсказания. Речевой ввод отсутствует, поэтому модель
+делает прогнозы, близкие к случайным, но с очень низкой вероятностью. Как только мы произносим слово активации, модель прогнозирует `"marvin"`
+с вероятностью, близкой к 1, и завершает цикл, сигнализируя о том, что слово активации обнаружено и система ASR должна быть активирована!
+
+## Транскрибирование речи
+
+И снова мы будем использовать модель Whisper для нашей системы транскрипции речи. В частности, мы загрузим контрольную точку
+[Whisper Base English](https://huggingface.co/openai/whisper-base.en), поскольку она достаточно мала, чтобы обеспечить хорошую скорость инференса при приемлемой
+точности транскрипции. Мы будем использовать трюк, позволяющий получить транскрипцию практически в реальном времени за счет умного подхода к передаче аудиосигнала
+в модель. Как и прежде, можно использовать любую контрольную точку распознавания речи на [Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=transformers&sort=trending),
+включая Wav2Vec2, MMS ASR или другие контрольные точки Whisper:
+
+```python
+transcriber = pipeline(
+ "automatic-speech-recognition", model="openai/whisper-base.en", device=device
+)
+```
+
+
+ "openai/whisper-small.en".
+
+  +
+
+
+Мы будем использовать контрольную точку [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) от [TII](https://www.tii.ae/) - LM с декодером только на 7B параметров,
+которая дообучена на смеси датасетов чатов и инструкций. Вы можете использовать любую LLM на Hugging Face Hub, у которой активирован параметр "Hosted inference API",
+просто обратите внимание на виджет в правой части карточки модели:
+
+
+
+  +
+
+
+Inference API позволяет отправить HTTP-запрос с локальной машины на LLM, размещенную на Hub, и возвращает ответ в виде файла `json`.
+Все, что нам нужно, - это указать наш токен Hugging Face Hub (который мы получаем непосредственно из нашей папки Hugging Face Hub)
+и идентификатор модели LLM, которой мы хотим передать запрос:
+
+```python
+from huggingface_hub import HfFolder
+import requests
+
+
+def query(text, model_id="tiiuae/falcon-7b-instruct"):
+ api_url = f"https://api-inference.huggingface.co/models/{model_id}"
+ headers = {"Authorization": f"Bearer {HfFolder().get_token()}"}
+ payload = {"inputs": text}
+
+ print(f"Querying...: {text}")
+ response = requests.post(api_url, headers=headers, json=payload)
+ return response.json()[0]["generated_text"][len(text) + 1 :]
+```
+
+Давайте попробуем это сделать с помощью тестового ввода!
+
+```python
+query("What does Hugging Face do?")
+```
+
+```
+'Hugging Face is a company that provides natural language processing and machine learning tools for developers. They'
+```
+
+Вы можете заметить, насколько быстро выполняется инференс с помощью Inference API - нам нужно отправить лишь небольшое количество текстовых токенов
+с нашей локальной машины на размещенную на сервере модель, поэтому затраты на связь очень малы. LLM размещается на GPU-ускорителях, поэтому инференс
+выполняется очень быстро. Наконец, сгенерированный ответ передается обратно от модели на нашу локальную машину,
+что также не требует больших коммуникационных затрат.
+
+## Синтез речи
+
+Теперь мы готовы к получению окончательного речевого вывода! В очередной раз мы будем использовать модель Microsoft [SpeechT5 TTS](https://huggingface.co/microsoft/speecht5_tts)
+для TTS на английском языке, но вы можете использовать любую модель TTS по своему усмотрению. Давайте загрузим процессор и модель:
+
+```python
+from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
+
+processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
+
+model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(device)
+vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(device)
+```
+
+А также эбеддинги диктора:
+
+```python
+from datasets import load_dataset
+
+embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
+speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
+```
+
+Мы повторно используем функцию `synthesise`, которую мы определили в предыдущей главе [Перевод речи в речь] (speech-to-speech):
+
+```python
+def synthesise(text):
+ inputs = processor(text=text, return_tensors="pt")
+ speech = model.generate_speech(
+ inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
+ )
+ return speech.cpu()
+```
+
+Давайте быстро проверим, что все работает так, как и ожидается:
+
+```python
+from IPython.display import Audio
+
+audio = synthesise(
+ "Hugging Face is a company that provides natural language processing and machine learning tools for developers."
+)
+
+Audio(audio, rate=16000)
+```
+
+Отличная работа 👍
+
+## Марвин 🤖
+
+Теперь, когда мы определили функцию для каждого из четырех этапов конвейера голосового помощника, осталось только собрать их вместе,
+чтобы получить готовый голосовой помощник. Мы просто объединим все четыре этапа, начиная с обнаружения слов активации (`launch_fn`),
+транскрипции речи, передачи запроса LLM и заканчивая синтезом речи.
+
+```python
+launch_fn()
+transcription = transcribe()
+response = query(transcription)
+audio = synthesise(response)
+
+Audio(audio, rate=16000, autoplay=True)
+```
+
+Попробуйте сделать это с помощью нескольких запросов! Вот несколько примеров для начала:
+* Какая самая жаркая страна в мире?
+* Как работают модели-трансформеры?
+* Знаешь ли ты испанский язык?
+
+Вот и все, у нас есть готовый голосовой помощник, созданный с использованием 🤗 аудио инструментов, которые вы изучили в этом курсе, с добавлением в конце волшебства LLM.
+Есть несколько расширений, которые мы могли бы сделать для улучшения голосового помощника. Во-первых, модель классификации звука классифицирует 35 различных меток.
+Мы могли бы использовать более компактную и легкую модель бинарной классификации, которая прогнозирует только то, было ли произнесено слово активации или нет.
+Во-вторых, мы заранее загружаем все модели и держим их запущенными на нашем устройстве. Если бы мы хотели сэкономить электроэнергию, то загружали бы каждую модель
+только в тот момент, когда она необходима, а затем выгружали бы ее. В-третьих, в нашей функции транскрибации отсутствует модель определения активности голоса,
+транскрибация осуществляется в течение фиксированного времени, которое в одних случаях слишком длинное, а в других - слишком короткое.
+
+## Обобщаем всё 🪄
+
+До сих пор мы видели, как можно генерировать речевой вывод с помощью нашего голосового помощника Marvin.
+В заключение мы продемонстрируем, как можно обобщить этот речевой вывод на текст, аудио и изображение.
+
+Для построения нашего помощника мы будем использовать [Transformers Agents](https://huggingface.co/docs/transformers/transformers_agents). Transformers Agents
+предоставляет API для работы с естественным языком поверх библиотек 🤗 Transformers и Diffusers, интерпретирует входной сигнал на естественном языке с помощью LLM
+с тщательно продуманными подсказками и использует набор курируемых инструментов для обеспечения мультимодального вывода.
+
+Давайте перейдем к инстанцированию агента. Для агентов-трансформеров существует [три LLM](https://huggingface.co/docs/transformers/transformers_agents#quickstart), две из которых с открытым исходным кодом
+и бесплатно доступны на Hugging Face Hub. Третья - модель от OpenAI, требующая ключа OpenAI API. В данном примере мы будем использовать бесплатную модель [Bigcode Starcoder](https://huggingface.co/bigcode/starcoder),
+но вы также можете попробовать любую из других доступных LLM:
+
+```python
+from transformers import HfAgent
+
+agent = HfAgent(
+ url_endpoint="https://api-inference.huggingface.co/models/bigcode/starcoder"
+)
+```
+
+Чтобы воспользоваться агентом, достаточно вызвать `agent.run` с нашим текстовым приглашением. В качестве примера мы попросим
+его сгенерировать изображение кота 🐈 (которое, надеюсь, выглядит немного лучше, чем этот эмоджи):
+
+```python
+agent.run("Generate an image of a cat")
+```
+
+
+
+  +
+
+
+
+