|
| 1 | +@[toc] |
| 2 | +> 我们都知道HashMap是线程不安全的,在多线程的环境下不建议使用它。那么,它到底是哪里线程不安全呢? |
| 3 | +* HashMap根据键的HashCode值存储数据,大多数情况下可以直接定位到它的值,因此具有很快的访问速度,但是遍历顺序确实不确定的。HashMap最多允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMa,可能会导致数据的不一致。下面通过JDK1.7和JDK1.8分别来说一下HashMap的内部结构和底层原理。 |
| 4 | +# JDK1.7的HashMap |
| 5 | +* JDK1.7HashMap的结构:数组+链表 |
| 6 | +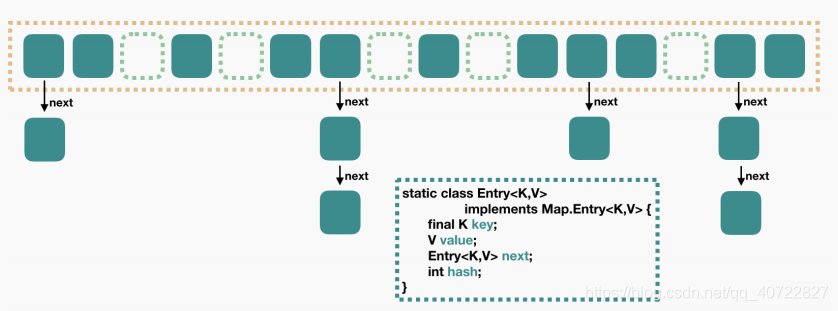 |
| 7 | +* HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色的实体是嵌套类(内部类) Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。 |
| 8 | +> 1. capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。 |
| 9 | +> 2. loadFactor:负载因子,默认为 0.75。 |
| 10 | +> 3. threshold:扩容的阈值,等于 capacity * loadFactor |
| 11 | +## 不安全原因之一:死循环 |
| 12 | +> 死循环发生在HashMap的扩容函数中,根源在transfer函数中,jdk1.7中HashMap的transfer函数如下: |
| 13 | +
|
| 14 | +```java |
| 15 | +void transfer(Entry[] newTable, boolean rehash) { |
| 16 | + //newCapacity 新数组的容量 |
| 17 | + int newCapacity = newTable.length; |
| 18 | + for (Entry<K,V> e : table) { |
| 19 | + while(null != e) { |
| 20 | + Entry<K,V> next = e.next; |
| 21 | + if (rehash) { |
| 22 | + e.hash = null == e.key ? 0 : hash(e.key); |
| 23 | + } |
| 24 | + int i = indexFor(e.hash, newCapacity); |
| 25 | + //头插法 |
| 26 | + e.next = newTable[i]; |
| 27 | + newTable[i] = e; |
| 28 | + e = next; |
| 29 | + } |
| 30 | + } |
| 31 | + } |
| 32 | +``` |
| 33 | +* 该函数主要作用:对table进行扩容到newTable后,需要将原来数据转移到newTable中,可以看出在转移元素的过程中,当发生hash碰撞时,使用的是头插法,也就是链表的顺序会翻转,这里也是形成死循环的关键点。 |
| 34 | +* JDK1.7还存在安全问题,如果有一组相同hash的数存入HashMap,那么HashMap就会退化为一个链表。而且黑客可以利用这个问题,进行DOS注入,造成性能问题。 |
| 35 | +# JDK1.8的HashMap |
| 36 | +> 在 Java8 中,当链表中的元素超过了 8 个以后,并且数组的长度超过64时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。 |
| 37 | +
|
| 38 | +* JDK1.8HashMap的结构:数组+链表+红黑树 |
| 39 | +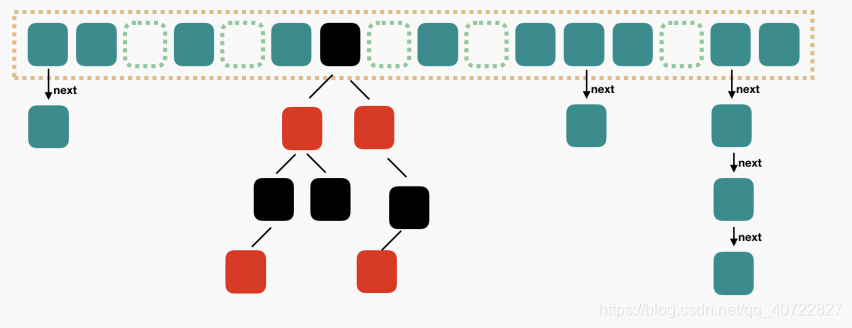 |
| 40 | +* JDK1.7 节点名字由Entry改为了Node,但是属性没改变。 |
| 41 | + |
| 42 | +## 不安全原因之一:数据覆盖 |
| 43 | +* 在jdk1.8中对HashMap进行了优化,在发生hash碰撞,不再采用头插法方式,而是直接插入链表尾部(尾插法),因此不会出现环形链表的情况,但是在多线程的情况下仍然不安全。 |
| 44 | +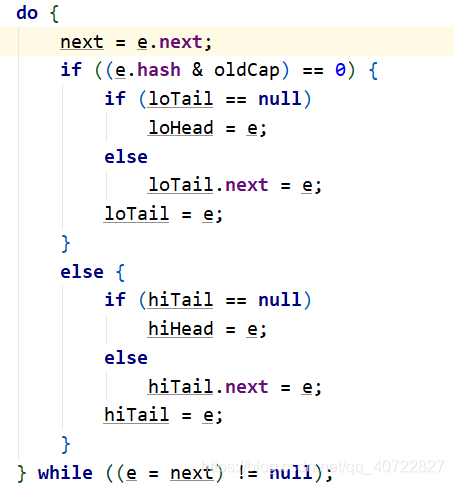 |
| 45 | +* putVal中的两行代码: |
| 46 | +```java |
| 47 | +if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有hash碰撞则直接插入元素 |
| 48 | + tab[i] = newNode(hash, key, value, null); |
| 49 | +``` |
| 50 | +* 如果线程A和线程B同时进行put操作,刚好这两条不同的数据hash值一样,并且该位置数据为null,所以这线程A、B都会进入上述的代码中。假设一种情况,线程A进入后还未进行数据插入时挂起,而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,问题出现:线程A会把线程B插入的数据给覆盖,发生线程不安全。 |
| 51 | +# 总结 |
| 52 | +* HashMap在JDK1.7中会出现死循环的问题,线程不安全 |
| 53 | +* HashMap在JDK1.8中会出现值覆盖问题,线程同样不安全 |
| 54 | +* HashMap的数字大小只能为2^n^ ,当初始化时赋的值不是 2^n^,则HashMap内部帮你调整为最接近初始值的下一个2^n^的数。 |
| 55 | +* HashMap默认初始容量为16,负载因子为0.75. |
| 56 | +* HashMap发生hash碰撞时,JDK1.7采用头插法插入数据,JDK1.8改为了尾插法。 |
| 57 | +* HashMap最多允许一条记录的键为null,允许多条记录的值为null。 |
| 58 | + |
| 59 | +如果需要线程满足安全,可以使用`HashTable`或者`Collections的synchronizedMap`方法使HashMap具有线程安全能力,也可以使用`ConcurrentHashMap` 。更多时候,为了并发性能,我们选择使用`ConcurrentHashMap`。 |
| 60 | + |
| 61 | +**你知道的越多,你不知道的越多。 |
| 62 | +有道无术,术尚可求,有术无道,止于术。 |
| 63 | +如有其它问题,欢迎大家留言,我们一起讨论,一起学习,一起进步** |
| 64 | + |
| 65 | + |
0 commit comments