JSON.parse 是浏览器内置的 API,但如果面试官让你实现一个怎么办?好在有人已经帮忙做了这件事,本周我们一起精读这篇 JSON Parser with Javascript 文章吧,再温习一遍大学时编译原理相关知识。
要解析 JSON 首先要理解语法概念,之前的 精读《手写 SQL 编译器 - 语法分析》 系列也有介绍过,不过本文介绍的更形象,看下面这个语法图:
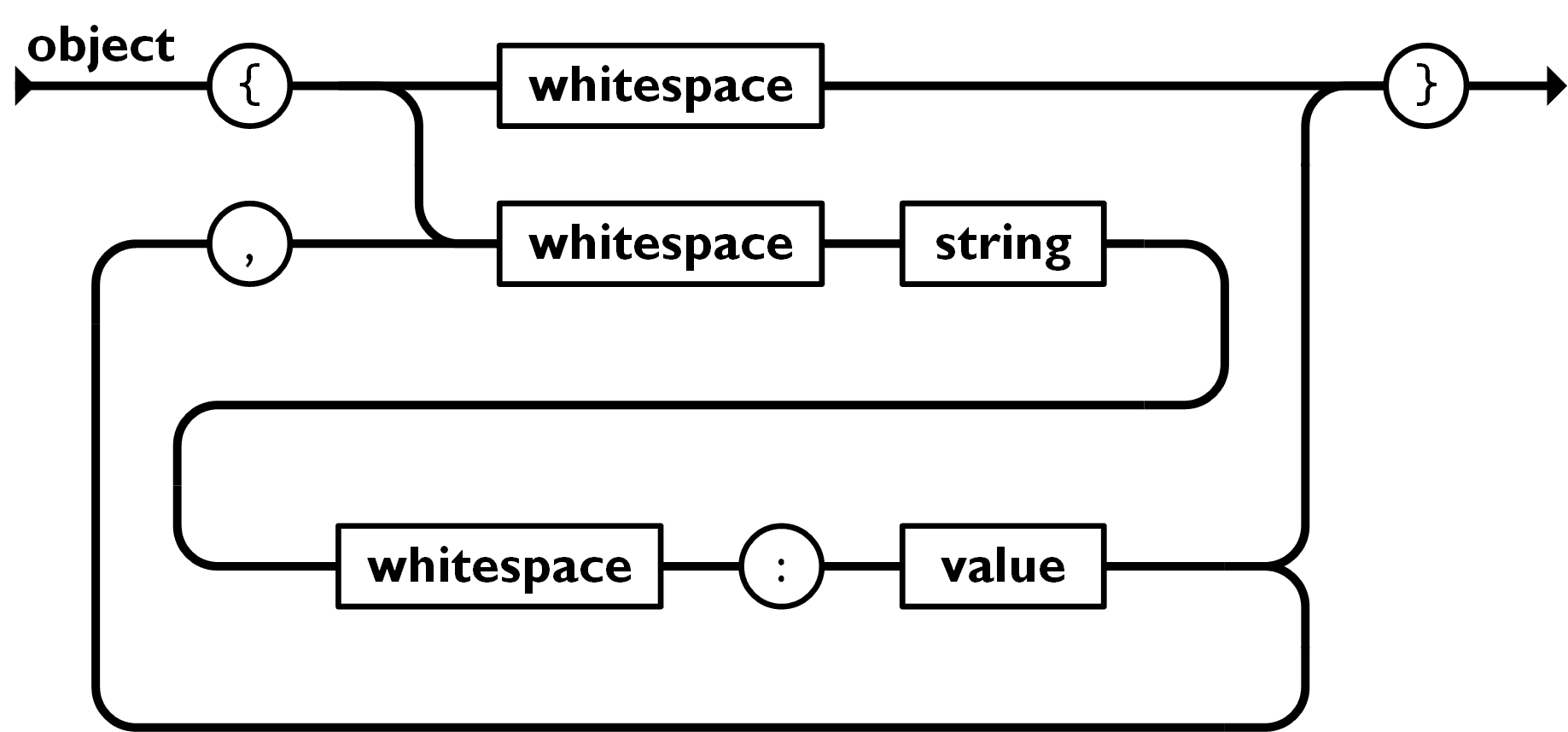
这是关于 Object 类型的语法描述图,从左向右看,根据箭头指向只要能走出这个迷宫就属于正确语法。
比如第一行 { → whitespace → } 表示 { } 属于合法的 JSON 语法。
再比如观察向下的一条最长路线:{ → whitespace → string → whitespace → : → value → } 表示 { string : value } 属于合法的 JSON 语法。
你可能会问,双引号去哪儿了?这就是语法树最核心的概念了,这张图是关于 Object 类型的 产生式,同理还有 string、value 的产生式,产生式中可以嵌套其他产生式,甚至形成环路,以此拥有描述纷繁多变语法的能力。
最后我们再看一个环路,即 { → whitespace → string ... , → whitespace → string ... , ... },我们发现,只要不走回头路,这条路是可以一直 “绕圈” 下去的,因此 Object 类型拥有了任意数量子字段的能力,只是每形成一个子字段,必须经过 , 号分割。
首先实现一个基本结构:
function fakeParseJSON(str) {
let i = 0;
// TODO
}i 表示访问字符的下标,当 i 走到字符串结尾表示遍历结束。
然后是下一步,用几个函数描述解析语法的过程:
function fakeParseJSON(str) {
let i = 0;
function parseObject() {
if (str[i] === '{') {
i++;
skipWhitespace();
// if it is not '}',
// we take the path of string -> whitespace -> ':' -> value -> ...
while (str[i] !== '}') {
const key = parseString();
skipWhitespace();
eatColon();
const value = parseValue();
}
}
}
}其中 skipWhitespace 表示匹配并跳过空格,所谓匹配意味着匹配成功,此时 i 下标可以继续后移,否则匹配失败。下一步则判断如果 i 不是结束标志 },则按照 parseString 匹配字符串 → skipWhitespace 跳过空格 → eatColon 吃掉冒号 → parseValue 匹配值,这个链路循环。其中吃掉冒号表示 “匹配冒号但不会产生任何结果,所以就像吃掉了一样”,吃这个动作还可以用在其他场景,比如吃掉尾分号。
对于看到这儿的小伙伴,笔者要友情提示一下,原文的思路是一种定制语法解析思路,无论是
eatColon还是parseValue都仅具备解析 JSON 的通用性,但不具备解析任意语法的通用性。如果你想做一个具备解析任何通用语法的解析器,读入的内容应该是语法描述,处理方式必须更加通用,如果感兴趣可以阅读 精读《手写 SQL 编译器 - 语法分析》 系列文章了解更多。
由于 Object 第一个元素前面不允许加逗号,因此可以利用 initial 做一个初始化判定,在初始时机不会吃掉逗号:
function fakeParseJSON(str) {
let i = 0;
function parseObject() {
if (str[i] === '{') {
i++;
skipWhitespace();
let initial = true;
// if it is not '}',
// we take the path of string -> whitespace -> ':' -> value -> ...
while (str[i] !== '}') {
if (!initial) {
eatComma();
skipWhitespace();
}
const key = parseString();
skipWhitespace();
eatColon();
const value = parseValue();
initial = false;
}
// move to the next character of '}'
i++;
}
}
}那么当第一个子元素前面存在逗号时,由于没有 “吃掉逗号” 这个功能,所以读到逗号会报错,语法解析提前结束。
吃逗号和吃冒号的代码都非常简单,即判断当前字符串必须是 “要吃的那个元素”,并且在吃掉后将 i 下标自增 1:
function fakeParseJSON(str) {
// ...
function eatComma() {
if (str[i] !== ',') {
throw new Error('Expected ",".');
}
i++;
}
function eatColon() {
if (str[i] !== ':') {
throw new Error('Expected ":".');
}
i++;
}
}在有了基本判定功能后,fakeParseJSON 需要返回 Object,因此我们只需在每个循环中对 Object 赋值,最后一并 return 即可:
function fakeParseJSON(str) {
let i = 0;
function parseObject() {
if (str[i] === '{') {
i++;
skipWhitespace();
const result = {};
let initial = true;
// if it is not '}',
// we take the path of string -> whitespace -> ':' -> value -> ...
while (str[i] !== '}') {
if (!initial) {
eatComma();
skipWhitespace();
}
const key = parseString();
skipWhitespace();
eatColon();
const value = parseValue();
result[key] = value;
initial = false;
}
// move to the next character of '}'
i++;
return result;
}
}
}解析 Object 的代码就完成了。
接着试着解析 Array,下面是 Array 的语法图:
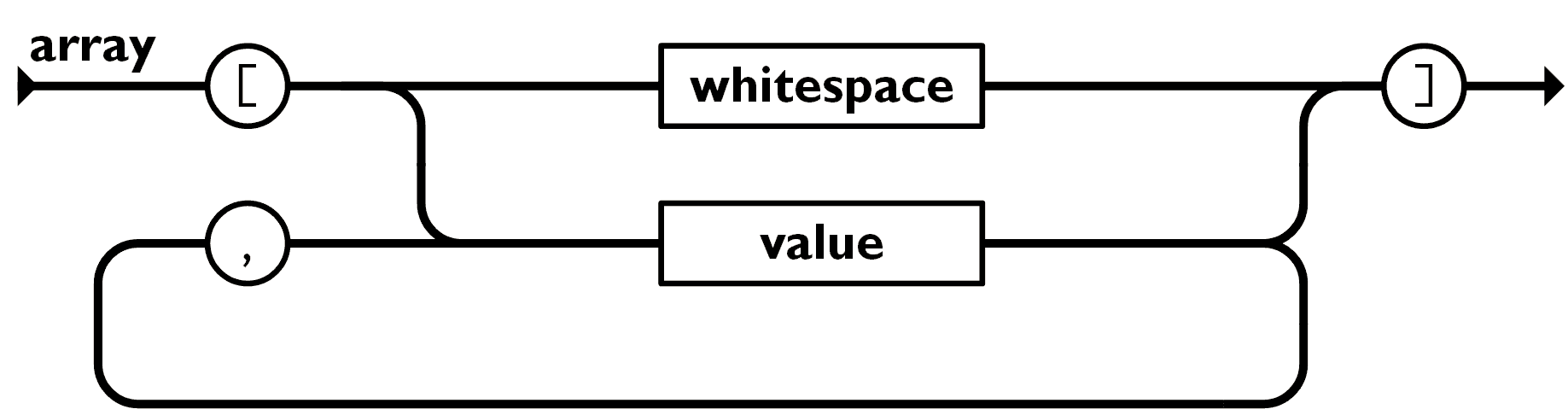
我们只需要吃逗号和 parseValue 即可:
function fakeParseJSON(str) {
// ...
function parseArray() {
if (str[i] === '[') {
i++;
skipWhitespace();
const result = [];
let initial = true;
while (str[i] !== ']') {
if (!initial) {
eatComma();
}
const value = parseValue();
result.push(value);
initial = false;
}
// move to the next character of ']'
i++;
return result;
}
}
}接下来到了有趣的 value 语法图,可以看到 value 是许多种基础类型的 “或” 关系组成的:
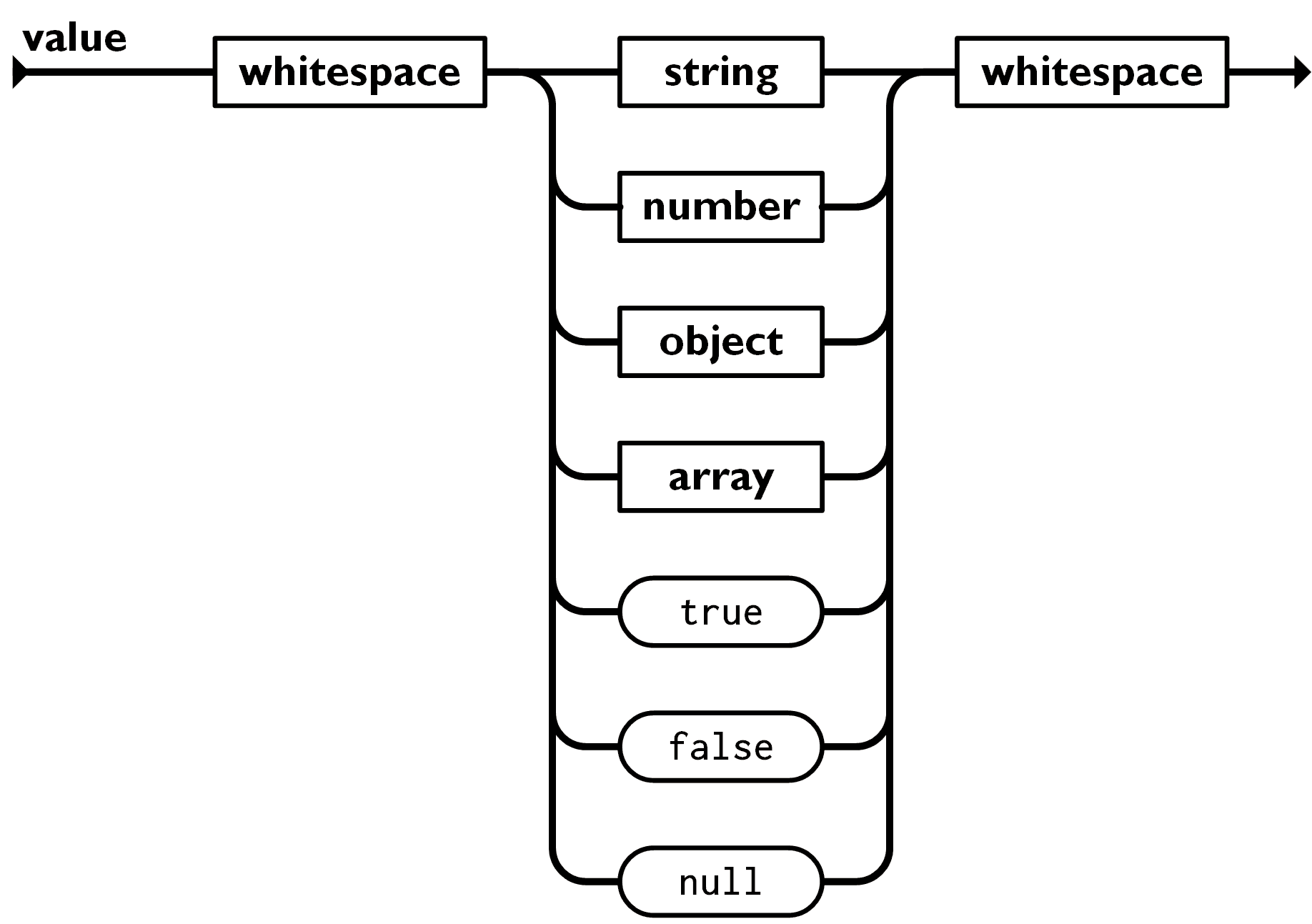
我们只需要继续拆解分析即可:
function fakeParseJSON(str) {
// ...
function parseValue() {
skipWhitespace();
const value =
parseString() ??
parseNumber() ??
parseObject() ??
parseArray() ??
parseKeyword('true', true) ??
parseKeyword('false', false) ??
parseKeyword('null', null);
skipWhitespace();
return value;
}
}其中 parseKeyword 函数用来解析一些保留关键字,比如将 "true" 解析成布尔类型 true:
function fakeParseJSON(str) {
// ...
function parseKeyword(name, value) {
if (str.slice(i, i + name.length) === name) {
i += name.length;
return value;
}
}
}如上所示,只要在 name 与对应字符相等时,返回第二个传入参数即可。
一个完整的语法解析功能需要包含错误处理,错误的情况主要分两种:
- 非法字符。
- 非正常结尾。
原文提到的 JSON 错误提示优化非常棒,想想你在开发中突然看到下面的提示,是不是很蒙圈:
Unexpected token "a"
既然我们是自己写的 JSON 解析器,就可以进行更友好的异常提示,比如:
// show
{ "b"a
^
JSON_ERROR_001 Unexpected token "a".
Expecting a ":" over here, eg:
{ "b": "bar" }
^
You can learn more about valid JSON string in http://goo.gl/xxxxx
更多 Demo 可以查看 原文。
这篇文章通过一个具体的例子解释如何做语法分析,对于词法解析入门非常直观,如果你想更深入理解语法解析,或者写一个通用语法解析器,可以阅读语法解析系列入门文章,笔者通过实际例子带你一步一步做一个完备的词法解析工具!
语法解析入门系列文章,建议阅读顺序:
- 精读《手写 SQL 编译器 - 词法分析》
- 精读《手写 SQL 编译器 - 文法介绍》
- 精读《手写 SQL 编译器 - 语法分析》
- 精读《手写 SQL 编译器 - 回溯》
- 精读《手写 SQL 编译器 - 语法树》
- 精读《手写 SQL 编译器 - 错误提示》
- 精读《手写 SQL 编译器 - 性能优化之缓存》
- 精读《手写 SQL 编译器 - 智能提示》
syntax-parser 这个零依赖的通用语法解析库就是根据上述文章一步一步完成的,看完了上面文章,就彻底理解了这个库的源码。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)