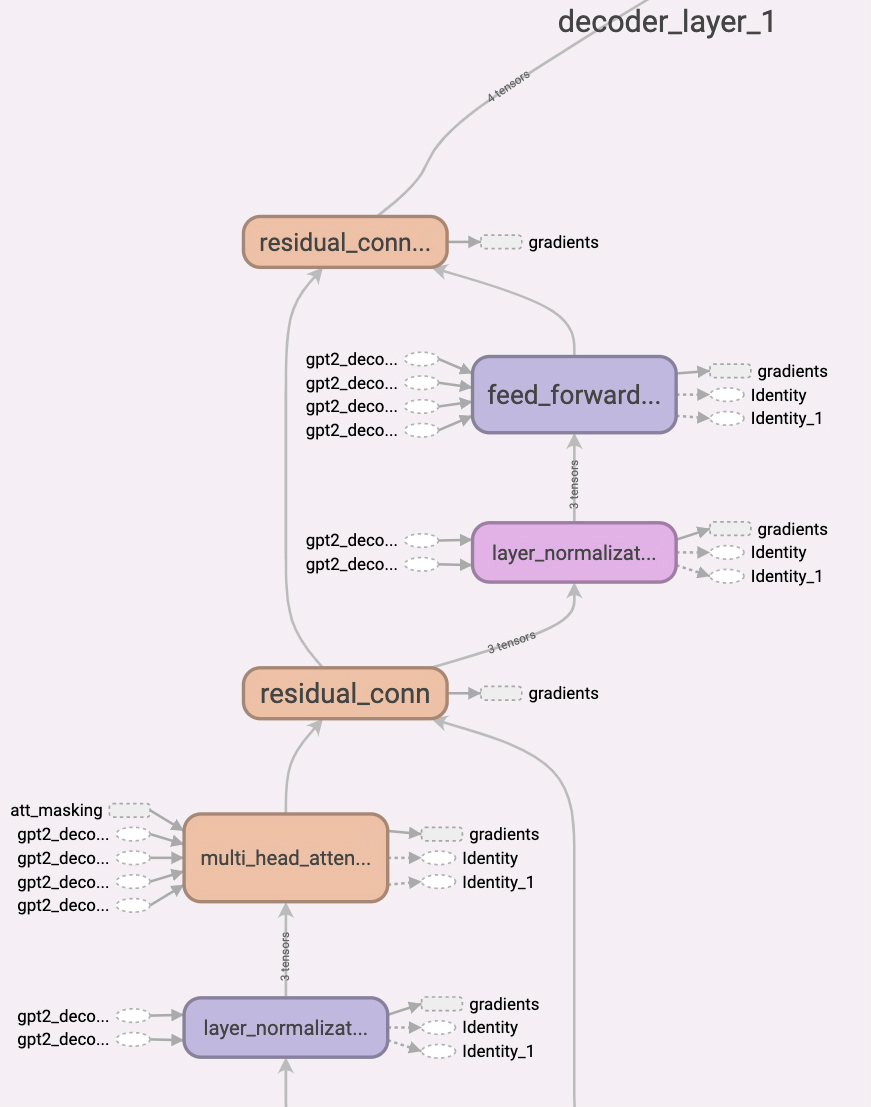
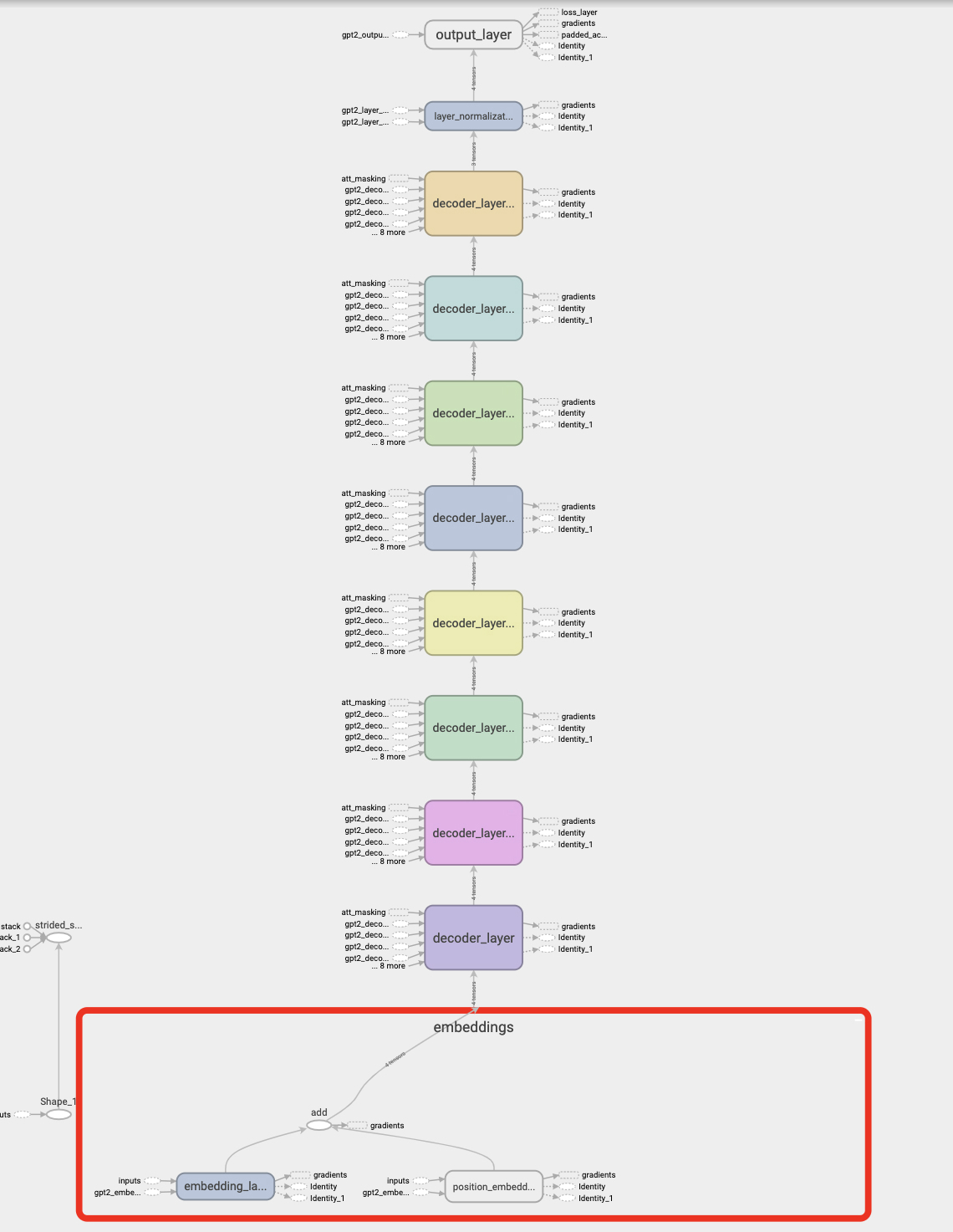
Originally implemented in tensorflow 1.14 by OapenAi :- "openai/gpt-2". OpenAi GPT-2 Paper:-"Language Models are Unsupervised Multitask Learners"
**This repository has OpenAi GPT-2 pre-training and sequence generation implementation in tensorflow 2.0, **
Requirements
- python >= 3.6
- setuptools==41.0.1
- ftfy==5.6
- tqdm==4.32.1
- Click==7.0
- sentencepiece==0.1.83
- tensorflow-gpu==2.3.0
- numpy==1.16.4
Setup
$ git clone https://github.com/akanyaani/gpt-2-tensorflow2.0
$ cd gpt-2-tensorflow2.0
$ pip install -r requirements.txt
You can pre-train the model using sample data available in repository or you can download the data using this github repo https://github.com/eukaryote31/openwebtext
Pre-Training model on sample data available in repository
$ python pre_process.py --help
Options:
--data-dir TEXT training data path [default: /data/scraped]
--vocab-size INTEGER byte pair vocab size [default: 24512]
--min-seq-len INTEGER minimum sequence length [default: 15]
--max-seq-len INTEGER maximum sequence length [default: 512]
--help Show this message and exit.
>> python pre_process.py
Pre-Training model on openwebtext or any other data
>> python pre_process.py --data-dir=data_directory --vocab-size=32000
$ python train_gpt2.py --help
Options:
--num-layers INTEGER No. of decoder layers [default: 8]
--embedding-size INTEGER Embedding size [default: 768]
--num-heads INTEGER Number of heads [default: 8]
--dff INTEGER Filter Size [default: 3072]
--max-seq-len INTEGER Seq length [default: 515]
--vocab-size INTEGER Vocab size [default: 24512]
--optimizer TEXT optimizer type [default: adam]
--batch-size INTEGER batch size [default: 8]
--learning-rate FLOAT learning rate [default: 0.001]
--graph-mode BOOLEAN TF run mode [default: False]
--distributed BOOLEAN distributed training [default: False]
--help Show this message and exit.
>> python train_gpt2.py \
--num-layers=8 \
--num-heads=8 \
--dff=3072 \
--embedding-size=768 \
--batch-size=32 \
--learning-rate=5e-5
--graph-mode=True
Distributed training on multiple gpu.
>> python train_gpt2.py \
--num-layers=8 \
--num-heads=8 \
--dff=3072 \
--embedding-size=768 \
--batch-size=32 \
--learning-rate=5e-5 \
--distributed=True \
--graph-mode=True
Start TensorBoard through the command line.
$ tensorboard --logdir /log
After pretraining your model, you can generate sequences by giving some context to model. Open this notebook and load the pretrained model and pass context to model it will return the generated sequence.
$ sequence_generator.ipynb
TO DO
1. Parallel Preprocessing.
2. Shared weights across layers.
3. Factorized embedding.
4. Fine-Tuning wrapper.
References:
- "Openai/gpt-2"
- "Huggingface pytorch-transformers"
- "Tensorflow Transformers"
- "The Illustrated GPT-2 "
Contribution
- Your issues and PRs are always welcome.
Author
- Abhay Kumar
- Author Email : [email protected]
- Follow me on Twitter
License
Computation Graph of GPT-2 Model.