Welcome to the Market Trade Processor Tests subproject!
This subproject is a part of Market Trade Processor project.
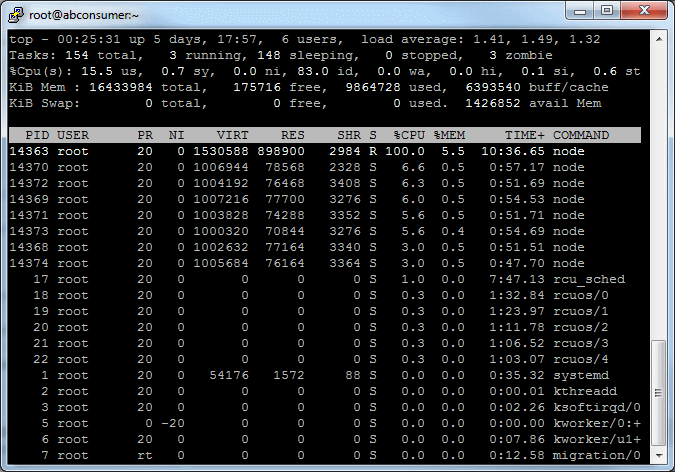
How to test the system properly? If your server is able to process thousand requests per a second it is not an easy task.
In order to make our system really distributed I've setup test servers in different data centers. Moreover, I made them at different hosting providers. It is just for test. If you want to have the best performance you should use servers from a single datacenter definetly.
There were no any load balancers were used in my installation.
Configuration
- 2 CPU cores, 750 Mb RAM.
- Provider: Rusonyx
Software
- CentOS 6.5
- Frontend UI
- Redis
- Storage RESTful endpoint
Configuration Standard_D3: 4 CPU cores, 14 Gb RAM Provider: Microsoft Azure
Software
- CentOS 7 x64
- RabbitMQ 3.5.1
- RabbitMQ configuration
Configuration
- The cheapest "high volume plan": 8 CPU cores, 16 Gb RAM
- Provider: Digital ocean
Software
- CentOS 7 x64
- Consumer endpoint
There were 2 servers deployed:
First server
- n1-highcpu-8: 8 CPU cores, 7.2 Gb RAM
- Provider: Google Cloud Platform
- CentOS 7 x64
- 10 worker processes.
Second server
- n1-highcpu-2: 2 CPU cores, 1.8 Gb RAM
- Provider: Google Cloud Platform
- CentOS 7 x64
- 4 worker processes.
I've prepared a little script for testing with Apache Benchmark. You can find it in scripts directory.
scripts/exec.sh
scripts/exec.sh --forceNote: Make sure that you apply your parameters at the begining of scripts/exec.sh.
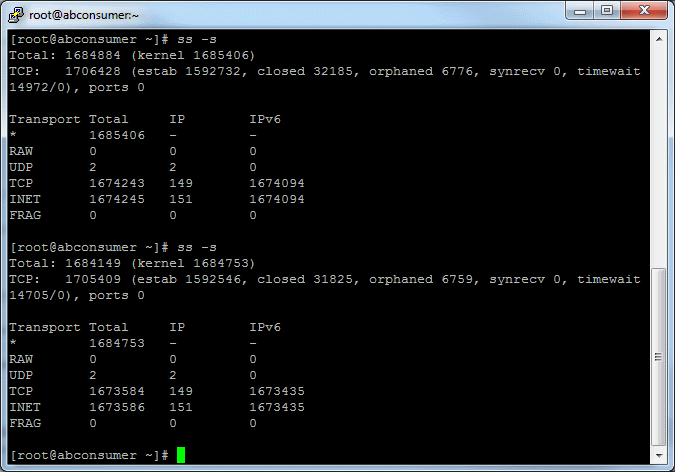
Apache Benchmark is a very good tool, but it is limited to not more than 20k concurent connections. proof
On the other hand ab is good enough. It is hard to imagine a better performance on a single server. Linux limits number of open sockets to 1024 by default, ab is able to open 20k concurent connections (of course after special tuning of your Linux machine).
Perhaps some other tools like JMeter, Siege, Tsung or Yandex tank are better choice, but I've decided to use multiserver installation of Apache Benchmark. AB just does some very basic measurements and we don't need to build complex scenarios with extended reports. Thus it is good enough.
How to distribute our installation of AB? Bees with Machine Guns is the answer. It is is “An utility for arming (creating) many bees (micro EC2 instances) to attack (load test) targets (web applications)”. In other words it simulates traffic originating from several different sources to hit the target. Each source is a “bee” which is an EC2 micro instance, which will load test the target using Apache’s ab.
ab often has a lot of failed connections if you use it from other datacenters. On the other hand I have never seen ab errors when I execute it in a local network with a consumer server. I think that it is because of network troubles.
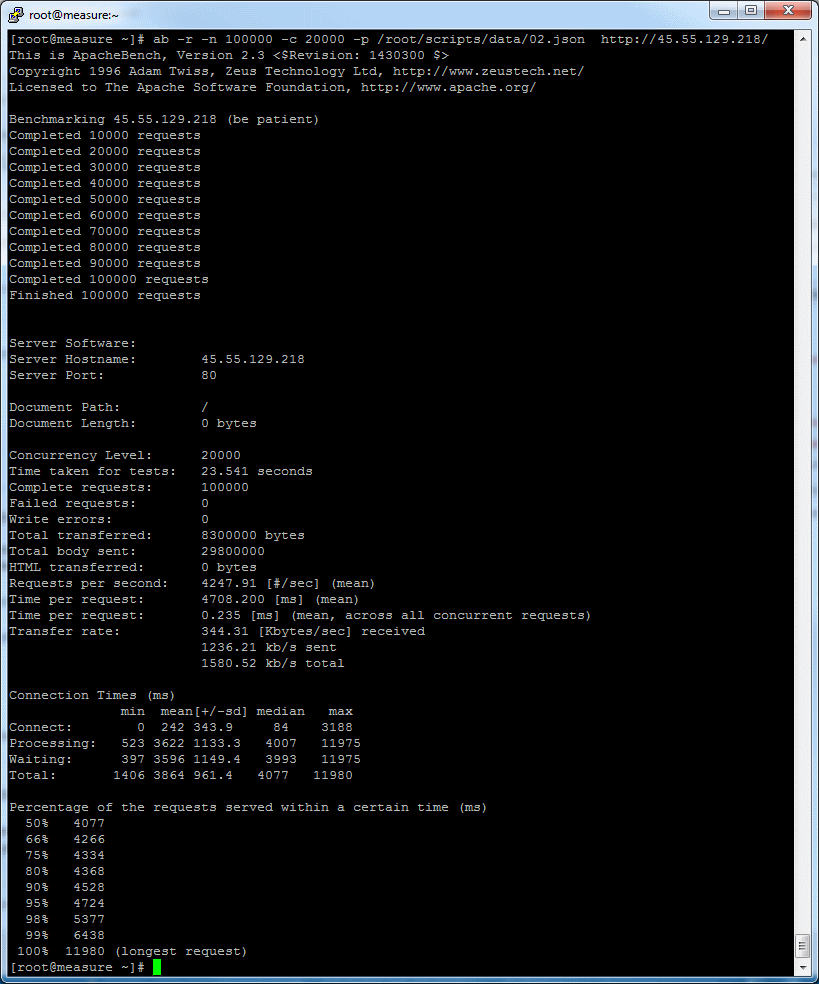
Total time: 23.5 seconds; Requests per second: 4,247.
Note. I've realized that the results depends on the server location significantly. This test was made from the Digital ocean server.
Note 2. Make sure that your servers are able to open the necessary number of connections. Please check How to tune Linux server section for details.
Test node configuration
- The cheapest plan: 1 CPU core, 512 Mb RAM
- Provider: Digital ocean
Software
- CentOS 7 x64
- Apache Benchmark
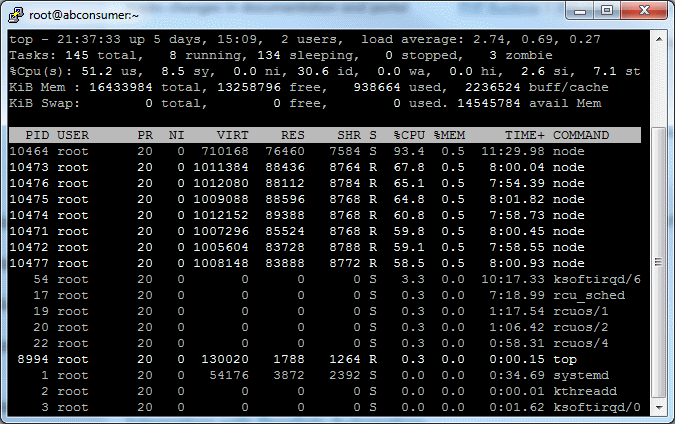
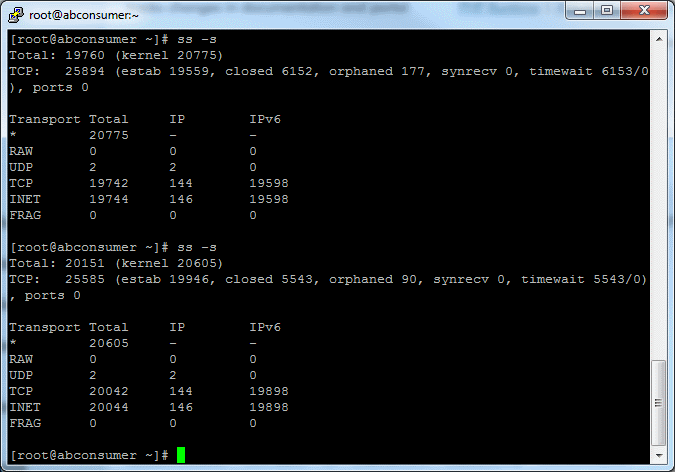
Total time: 25 minutes 4 seconds; Requests per second: 1329.
18 AWS micto instances were used to emulate 360k concurrent requests. Each of 18 bees will fire 111111 rounds, 20000 at a time.
Test node configuration
- t2.micro: 1 CPU core, 1 Gb RAM
- Provider: Amazon Web Services
Software
- CentOS 7 x64
- Apache Benchmark
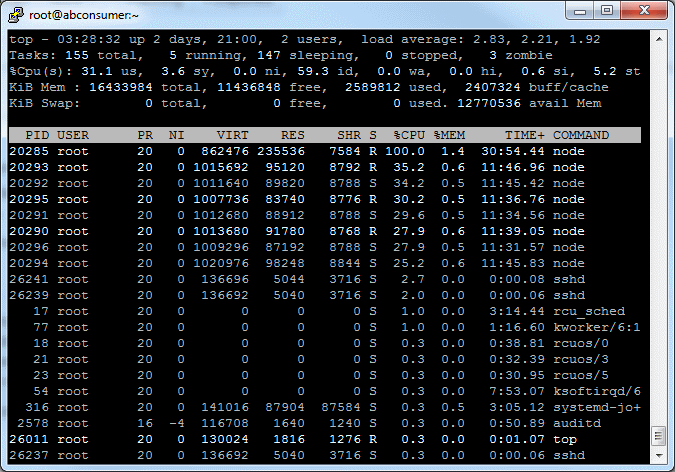
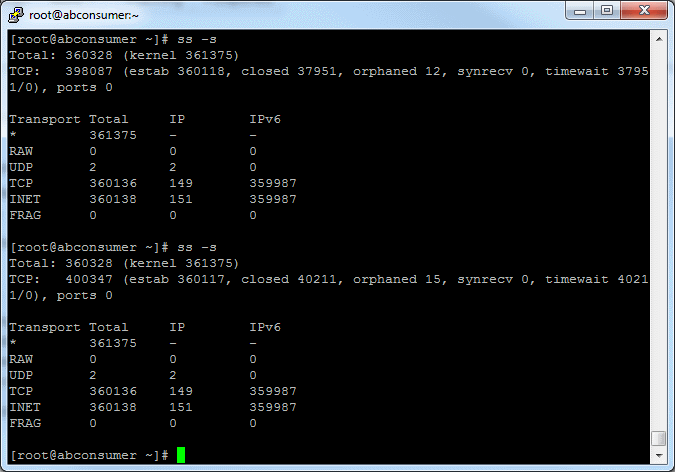
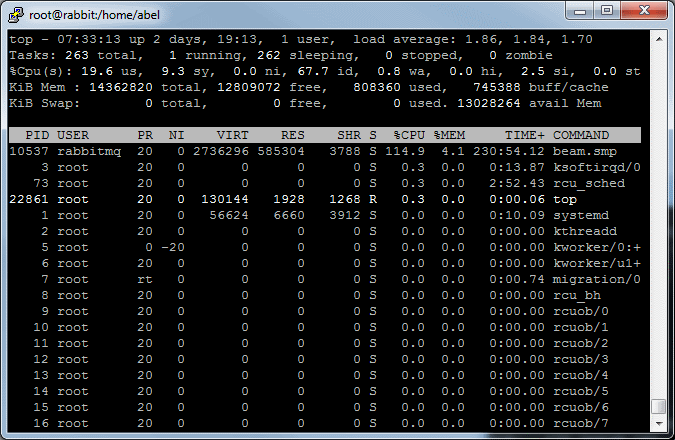
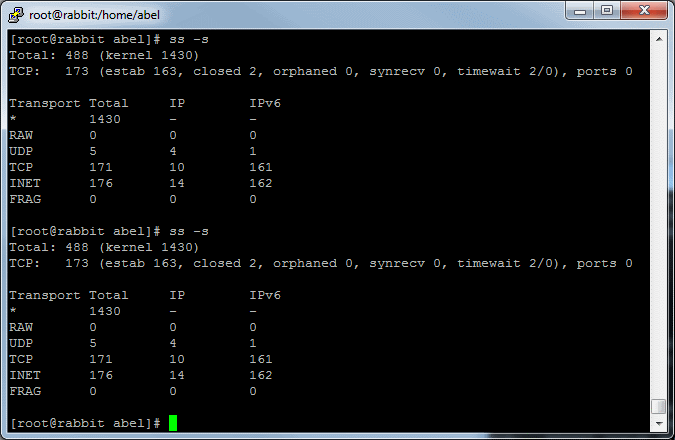
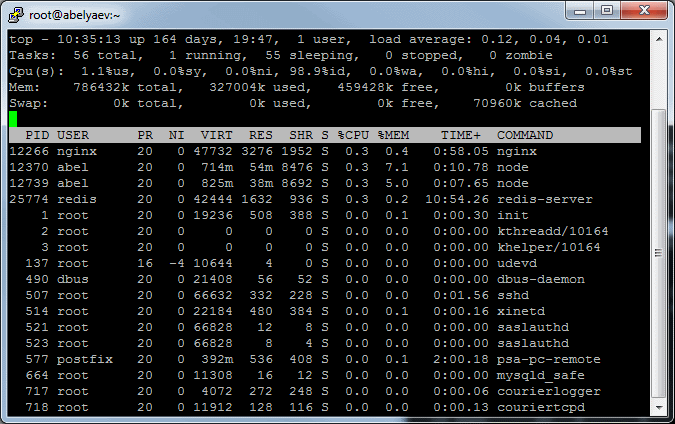
Total time: 51 minutes 49 seconds; Requests per second: 643. Each of 50 bees will fire 40000 rounds, 20000 at a time.
50 AWS micto instances were used to emulate 1 million concurrent requests.
Test node configuration
- t2.micro: 1 CPU core, 1 Gb RAM
- Provider: Amazon Web Services
Software
- CentOS 7 x64
- Apache Benchmark
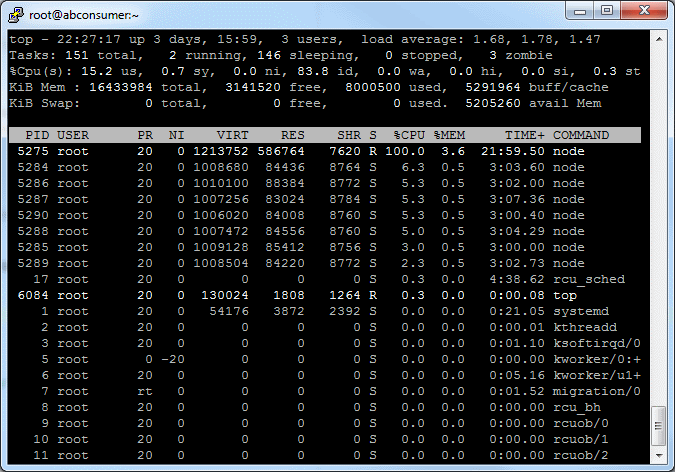
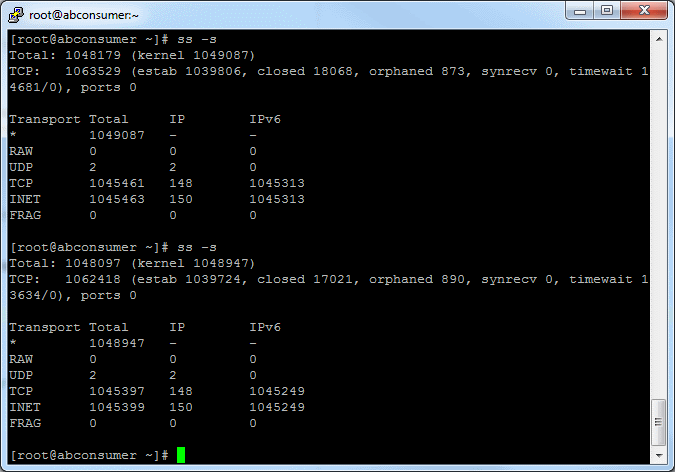
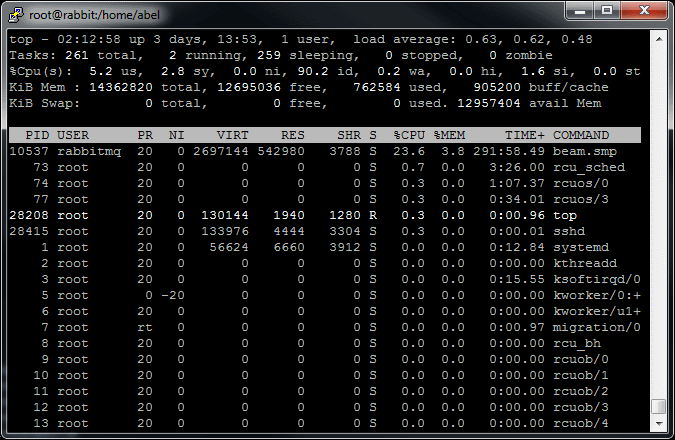
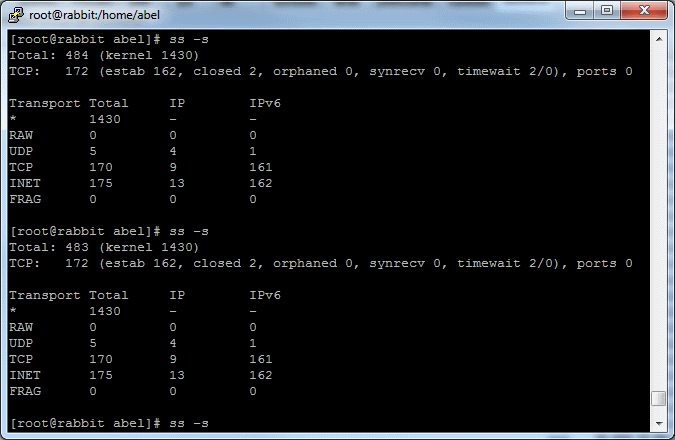
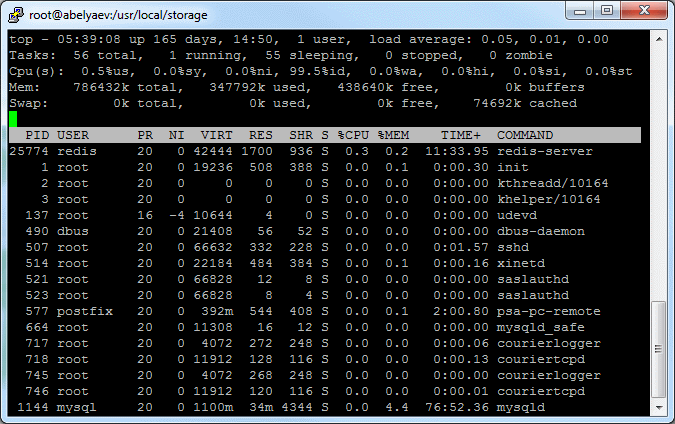
Actually for such large numbers you should make some tricks:
-
Increase the maximum number of open file descriptors.
echo 20000500 > /proc/sys/fs/nr_open ulimit -n 20000500 ulimit -S -n 20000500
-
Increase
fs.file-maxin/etc/sysctl.conf. -
Increase posix 'nofile' limit in consumer.js
-
Prepare the hive with 500 bees.
- Your subnet has to have more than 500 IPs.
- You also should have ~4Gb RAM for your hive management node.
-
Exec
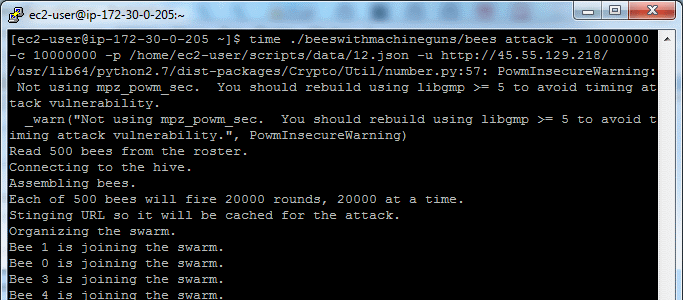
... and wait till your server die :)
I have tried several times, but my server processes were killed with unknown reason.
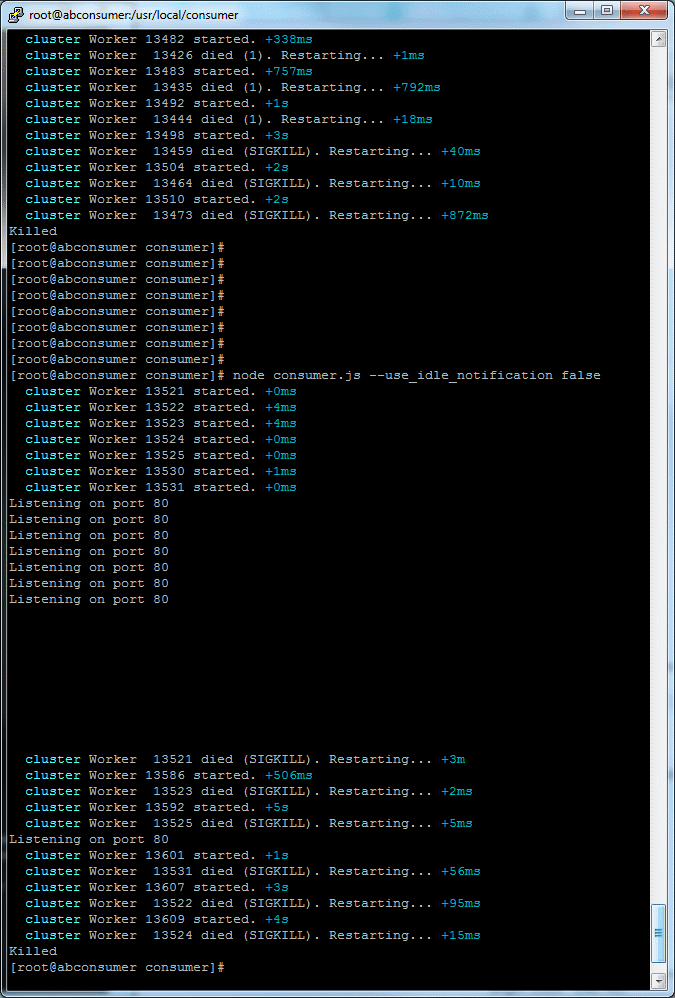
Actually I've realized that I just need more than 16Gb RAM to handle 10 million concurrent connections. My server ran out of RAM with ~1.7M concurrent connections.