diff --git a/README.md b/README.md
index a02e97f..96afe9c 100644
--- a/README.md
+++ b/README.md
@@ -46,7 +46,7 @@ The top animation shows an example use case: an `Agent` randomly explores a 2D `
+A new wrapper contributed by [@SynapticSage](https://github.com/SynapticSage) allows `RatInABox` to natively support OpenAI's [`gymnasium`](https://gymnasium.farama.org) API for standardised and multiagent reinforment learning. This can be used to flexibly integrate `RatInABox` with other RL libraries such as Stable-Baselines3 etc. and to build non-trivial tasks with objectives and time dependent rewards. Check it out [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/ratinabox/contribs/TaskEnv_example_files/TaskEnvironment_basics.md). -->
## Get started
Many [demos](./demos/) are provided. Reading through the [example scripts](#example-scripts) (one simple and one extensive, duplicated at the bottom of the readme) these should be enough to get started. We also provide numerous interactive jupyter scripts as more in-depth case studies; for example one where `RatInABox` is used for [reinforcement learning](./demos/reinforcement_learning_example.ipynb), another for [neural decoding](./demos/decoding_position_example.ipynb) of position from firing rate. Jupyter scripts reproducing all figures in the [paper](./demos/paper_figures.ipynb) and [readme](./demos/readme_figures.ipynb) are also provided. All [demos](./demos/) can be run on Google Colab [](./demos/)
diff --git a/demos/README.md b/demos/README.md
index da6e587..1edb13c 100644
--- a/demos/README.md
+++ b/demos/README.md
@@ -4,18 +4,18 @@ In this folder we provide numerous "example scripts" or "demos" which will help
All demos can be run in Google Colab but, for best performance, it is recommended to use a local IDE.
In approximate order of complexity, these include:
-* [simple_example.ipynb](./simple_example.ipynb): a very simple tutorial for importing RiaB, initilising an Environment, Agent and some PlaceCells, running a brief simulation and outputting some data. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/simple_example.ipynb)
-* [extensive_example.ipynb](./extensive_example.ipynb): a more involved tutorial. More complex enivornment, more complex cell types and more complex plots are used. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/extensive_example.ipynb)
+* [simple_example.ipynb](./simple_example.ipynb): a very simple tutorial for importing RiaB, initilising an Environment, Agent and some PlaceCells, running a brief simulation and outputting some data. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/simple_example.ipynb)
+* [extensive_example.ipynb](./extensive_example.ipynb): a more involved tutorial. More complex enivornment, more complex cell types and more complex plots are used. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/extensive_example.ipynb)
* [list_of_plotting_functions.md](./list_of_plotting_fuctions.md): All the types of plots available for are listed and explained.
-* [readme_figures.ipynb](./readme_figures.ipynb): (Almost) all plots/animations shown in the root readme are produced from this script (plus some minor formatting done afterwards in powerpoint). [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/readme_figures.ipynb)
-* [paper_figures.ipynb](./paper_figures.ipynb): (Almost) all plots/animations shown in the paper are produced from this script (plus some major formatting done afterwards in powerpoint). [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/paper_figures.ipynb)
-* [decoding_position_example.ipynb](./decoding_position_example.ipynb): Postion is decoded from neural data generated with RatInABox using linear regression. Place cells, grid cell and boundary vector cells are compared. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/decoding_position_example.ipynb)
-* [conjunctive_gridcells_example.ipynb](./conjunctive_gridcells_example.ipynb): `GridCells` and `HeadDirectionCells` are minimally combined useing `FeedForwardLayer` to create head-direction-selective grid cells (aka. conjunctive cells).[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/conjunctive_gridcells_example.ipynb)
-* [splitter_cells_example.ipynb](./splitter_cells_example.ipynb): A simple simultaion demonstrating how `Splitter` cell data could be create in a figure-8 maze. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/splitter_cell_example.ipynb)
-* [deep_learning_example.ipynb](./deep_learning_example.ipynb): Here we showcase `NeuralNetworkNeurons`, a class of `Neurons` which has a small neural network embedded inside. We train them to take grid cells as inputs and output an arbitrary function as their rate map. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/deep_learning_example.ipynb)
-* [reinforcement_learning_example.ipynb](./reinforcement_learning_example.ipynb): RatInABox is use to construct, train and visualise a small two-layer network capable of model free reinforcement learning in order to find a reward hidden behind a wall. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb)
-* [actor_critic_example.ipynb](./actor_critic_example.ipynb): RatInABox is use to implement the actor critic algorithm using deep neural networks. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/actor_critic_example.ipynb)
-* [successor_features_example.ipynb](./successor_features_example.ipynb): RatInABox is use to learn successor features under random and biased motion policies. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/successor_features_example.ipynb)
-* [path_integration_example.ipynb](./path_integration_example.ipynb): RatInABox is use to construct, train and visualise a large multi-layer network capable of learning a "ring attractor" capable of path integrating a position estimate using only velocity inputs. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/path_integration_example.ipynb)
-* [vector_cell_demo.ipynb](./vector_cell_demo.ipynb): A demo for the Vector Cells (OVCs & BVCs) and how to simulate them with various parameters and different manifolds. Also includes a demo on how to pass custom manifolds for the cells. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/vector_cell_demo.ipynb)
+* [readme_figures.ipynb](./readme_figures.ipynb): (Almost) all plots/animations shown in the root readme are produced from this script (plus some minor formatting done afterwards in powerpoint). [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/readme_figures.ipynb)
+* [paper_figures.ipynb](./paper_figures.ipynb): (Almost) all plots/animations shown in the paper are produced from this script (plus some major formatting done afterwards in powerpoint). [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/paper_figures.ipynb)
+* [decoding_position_example.ipynb](./decoding_position_example.ipynb): Postion is decoded from neural data generated with RatInABox using linear regression. Place cells, grid cell and boundary vector cells are compared. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/decoding_position_example.ipynb)
+* [conjunctive_gridcells_example.ipynb](./conjunctive_gridcells_example.ipynb): `GridCells` and `HeadDirectionCells` are minimally combined useing `FeedForwardLayer` to create head-direction-selective grid cells (aka. conjunctive cells).[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/conjunctive_gridcells_example.ipynb)
+* [splitter_cells_example.ipynb](./splitter_cells_example.ipynb): A simple simultaion demonstrating how `Splitter` cell data could be create in a figure-8 maze. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/splitter_cell_example.ipynb)
+* [deep_learning_example.ipynb](./deep_learning_example.ipynb): Here we showcase `NeuralNetworkNeurons`, a class of `Neurons` which has a small neural network embedded inside. We train them to take grid cells as inputs and output an arbitrary function as their rate map. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/deep_learning_example.ipynb)
+* [reinforcement_learning_example.ipynb](./reinforcement_learning_example.ipynb): RatInABox is use to construct, train and visualise a small two-layer network capable of model free reinforcement learning in order to find a reward hidden behind a wall. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb)
+* [actor_critic_example.ipynb](./actor_critic_example.ipynb): RatInABox is use to implement the actor critic algorithm using deep neural networks. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/actor_critic_example.ipynb)
+* [successor_features_example.ipynb](./successor_features_example.ipynb): RatInABox is use to learn successor features under random and biased motion policies. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/successor_features_example.ipynb)
+* [path_integration_example.ipynb](./path_integration_example.ipynb): RatInABox is use to construct, train and visualise a large multi-layer network capable of learning a "ring attractor" capable of path integrating a position estimate using only velocity inputs. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/path_integration_example.ipynb)
+* [vector_cell_demo.ipynb](./vector_cell_demo.ipynb): A demo for the Vector Cells (OVCs & BVCs) and how to simulate them with various parameters and different manifolds. Also includes a demo on how to pass custom manifolds for the cells. [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/vector_cell_demo.ipynb)
diff --git a/demos/actor_critic_example.ipynb b/demos/actor_critic_example.ipynb
index b6ce41e..58a31b9 100644
--- a/demos/actor_critic_example.ipynb
+++ b/demos/actor_critic_example.ipynb
@@ -4,7 +4,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "# Case study: Reinforcement Learning (via Actor-Critic) [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/actor_critic_example.ipynb)\n",
+ "# Case study: Reinforcement Learning (via Actor-Critic) [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/actor_critic_example.ipynb)\n",
"### We use RatInABox to train an Agent to find a navigate towards rewards using the Actor-Critic algorithm. "
]
},
diff --git a/demos/conjunctive_gridcells_example.ipynb b/demos/conjunctive_gridcells_example.ipynb
index 529e7ff..95f1f43 100644
--- a/demos/conjunctive_gridcells_example.ipynb
+++ b/demos/conjunctive_gridcells_example.ipynb
@@ -4,7 +4,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "# Conjuctive grid cells [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/conjunctive_gridcells_example.ipynb)\n",
+ "# Conjuctive grid cells [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/conjunctive_gridcells_example.ipynb)\n",
"\n",
"In this demo we'll show a very simple way one could model conjuctive grid cells (Sargolini, 2006) by non-linearly combining `GridCells` and `HeadDirectionCells` using `FeedForwardLayer`.\n",
"\n",
diff --git a/demos/decoding_position_example.ipynb b/demos/decoding_position_example.ipynb
index cb76a72..ae09a18 100644
--- a/demos/decoding_position_example.ipynb
+++ b/demos/decoding_position_example.ipynb
@@ -5,7 +5,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/decoding_position_example.ipynb)"
+ "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/decoding_position_example.ipynb)"
]
},
{
diff --git a/demos/deep_learning_example.ipynb b/demos/deep_learning_example.ipynb
index 6b068ea..b1619cb 100644
--- a/demos/deep_learning_example.ipynb
+++ b/demos/deep_learning_example.ipynb
@@ -4,7 +4,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "# Deep Learning with RatInABox [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/deep_learning_example.ipynb)\n",
+ "# Deep Learning with RatInABox [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/deep_learning_example.ipynb)\n",
"\n",
"In this tutorial we will show how `NeuralNetworkNeurons` can be used as general function approximators to make RatInABox `Neurons` classes which can be \"trained\" to represent any function. \n",
"\n",
diff --git a/demos/extensive_example.ipynb b/demos/extensive_example.ipynb
index 2ef9d13..c83a963 100644
--- a/demos/extensive_example.ipynb
+++ b/demos/extensive_example.ipynb
@@ -5,7 +5,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/extensive_example.ipynb)"
+ "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/extensive_example.ipynb)"
]
},
{
diff --git a/demos/paper_figures.ipynb b/demos/paper_figures.ipynb
index c587c54..196e79f 100644
--- a/demos/paper_figures.ipynb
+++ b/demos/paper_figures.ipynb
@@ -5,7 +5,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/paper_figures.ipynb)"
+ "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/paper_figures.ipynb)"
]
},
{
diff --git a/demos/path_integration_example.ipynb b/demos/path_integration_example.ipynb
index 8f2a6a2..af605b0 100644
--- a/demos/path_integration_example.ipynb
+++ b/demos/path_integration_example.ipynb
@@ -5,7 +5,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/path_integration_example.ipynb)"
+ "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/path_integration_example.ipynb)"
]
},
{
diff --git a/demos/readme_figures.ipynb b/demos/readme_figures.ipynb
index e5327b1..f66c1e4 100644
--- a/demos/readme_figures.ipynb
+++ b/demos/readme_figures.ipynb
@@ -5,7 +5,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/readme_figures.ipynb)"
+ "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/readme_figures.ipynb)"
]
},
{
diff --git a/demos/reinforcement_learning_example.ipynb b/demos/reinforcement_learning_example.ipynb
index d8e0cb8..a07838c 100644
--- a/demos/reinforcement_learning_example.ipynb
+++ b/demos/reinforcement_learning_example.ipynb
@@ -5,7 +5,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb)"
+ "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb)"
]
},
{
@@ -16,7 +16,7 @@
"# Case study: Reinforcement Learning\n",
"### We use RatInABox to train a model-free RL agent to find a reward hidden behind a wall.\n",
"\n",
- "Important note for serious RL-ers: A new wrapper (see [here](https://github.com/TomGeorge1234/RatInABox/blob/dev/ratinabox/contribs/TaskEnv_example_files/TaskEnvironment_basics.md)) that means `RatInABox` can natively support the [`gymnasium`](https://gymnasium.farama.org) (strictly, [`pettingzoo`](https://pettingzoo.farama.org)) API for standardised and multiagent reinforment learning. This means it can flexibly integrate with other RL libraries e.g. Stable-Baselines3 etc. This wrapper can also be used to build tasks with complex objectives and time dependent rewards. The example shown in this jupyter _does not_ do this but instead gives a bare-bones \"core-`RatInABox`-only\" implementation of a simple TD learning algorithm. We recommend starting here and graduating to the `gym` API after. "
+ "Important note for serious RL-ers: A new wrapper (see [here](https://github.com/TomGeorge1234/RatInABox/blob/main/ratinabox/contribs/TaskEnv_example_files/TaskEnvironment_basics.md)) that means `RatInABox` can natively support the [`gymnasium`](https://gymnasium.farama.org) (strictly, [`pettingzoo`](https://pettingzoo.farama.org)) API for standardised and multiagent reinforment learning. This means it can flexibly integrate with other RL libraries e.g. Stable-Baselines3 etc. This wrapper can also be used to build tasks with complex objectives and time dependent rewards. The example shown in this jupyter _does not_ do this but instead gives a bare-bones \"core-`RatInABox`-only\" implementation of a simple TD learning algorithm. We recommend starting here and graduating to the `gym` API after. "
]
},
{
diff --git a/demos/simple_example.ipynb b/demos/simple_example.ipynb
index ca28a95..a877495 100644
--- a/demos/simple_example.ipynb
+++ b/demos/simple_example.ipynb
@@ -5,7 +5,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/simple_example.ipynb)"
+ "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/simple_example.ipynb)"
]
},
{
diff --git a/demos/splitter_cells_example.ipynb b/demos/splitter_cells_example.ipynb
index ac3201d..a6152f3 100644
--- a/demos/splitter_cells_example.ipynb
+++ b/demos/splitter_cells_example.ipynb
@@ -4,7 +4,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "# Splitter cells [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/splitter_cell_example.ipynb)\n",
+ "# Splitter cells [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/splitter_cell_example.ipynb)\n",
"\n",
"In this demo we'll show a very simple way one could model 'splitter cells' using RatInABox. A known type of splitter cells fire in the central arm of a figure-8 maze _selectively_ dependent on whether the agent just came from the _left_ or the _right_ arm. \n",
"\n",
diff --git a/demos/successor_features_example.ipynb b/demos/successor_features_example.ipynb
index 4a7e982..0189aa0 100644
--- a/demos/successor_features_example.ipynb
+++ b/demos/successor_features_example.ipynb
@@ -5,7 +5,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/successor_features_example.ipynb)"
+ "[](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/successor_features_example.ipynb)"
]
},
{
@@ -107279,7 +107279,7 @@
"G0twNJ9mxE+edS1HSK5qWLgIRynFL3/5y8hznMqf/MmfVDXOcu6wwuoCIpFILFjtMhu9vb288847\\\n",
"xuOuu3gNu7avwkHS4GZIOXHi0sPFwc9DWIbuw2XeejrP3kcKvPbsCCd6hyLnWM1k48aNVXtcARw4\\\n",
"cIDvfOc71orBYnkfEAQB3/jGNxgcHKz6GnfeeSf19fWRYoeG8hw7OsCpU8Ncf+MGpADJKQRFwEWT\\\n",
- "QGnJ8UKGU6U0qYsLSKHRGrJBks5CllOF6cd4169YTa0XX/Dev/3tb6uyjvj85z9vE9bPQ6LtjVre\\\n",
+ "QGnJ8UKGU6U0qYsLSKHRGrJBks5CllOF6cd4169YTa0XX/main/3tb6uyjvj85z9vE9bPQ6LtjVre\\\n",
"N1x11VW8+OKL9Pb2Go176qmnWLVqFTU1NUbjPnTNJi7e0MLL+7sITpXo9Yco50C5Gt8pMzUH0+93\\\n",
"6R7UvKhP0Bpr5OqarUb3gorHle/7PPvss8ZjoZJX9u1vf5s//uM/rro3ocViObcUi0X+8i//smrz\\\n",
"T6g0Vo5i2dJ5cohnnj5MZ+fwmZ9l0qNs3nCSU50jlEqVUwCNy+lSLTnhktlVJNEhWBcEnCi4lJUG\\\n",
diff --git a/demos/vector_cell_demo.ipynb b/demos/vector_cell_demo.ipynb
index 9fb42ac..200cf3b 100644
--- a/demos/vector_cell_demo.ipynb
+++ b/demos/vector_cell_demo.ipynb
@@ -4,7 +4,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "# Vector Cells: BVCs, OVCs and egocentric field of views [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/dev/demos/vector_cell_demo.ipynb)\n"
+ "# Vector Cells: BVCs, OVCs and egocentric field of views [](https://colab.research.google.com/github/RatInABox-Lab/RatInABox/blob/main/demos/vector_cell_demo.ipynb)\n"
]
},
{
diff --git a/docs/source/documentation.md b/docs/source/documentation.md
index 6d42083..255490e 100644
--- a/docs/source/documentation.md
+++ b/docs/source/documentation.md
@@ -43,7 +43,7 @@ Environment.add_wall([[x0,y0],[x1,y1]])
```
Here are some easy to make examples.
- +
+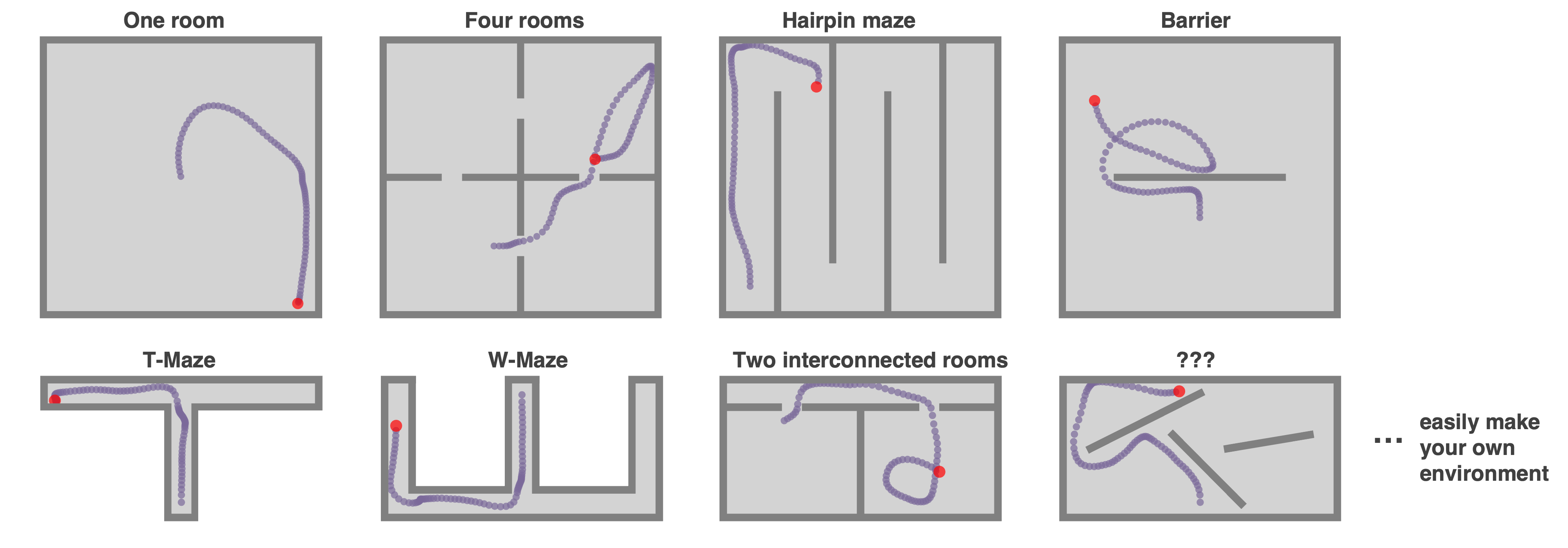 ### **Complex `Environment`s: Polygons, curves, and holes**
@@ -73,7 +73,7 @@ Env = Environment(params = {
```
-
### **Complex `Environment`s: Polygons, curves, and holes**
@@ -73,7 +73,7 @@ Env = Environment(params = {
```
- +
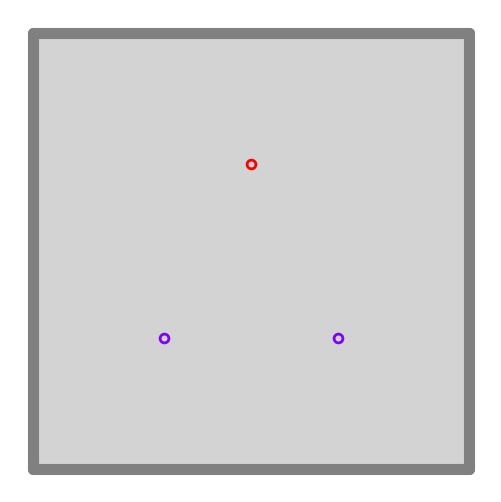
+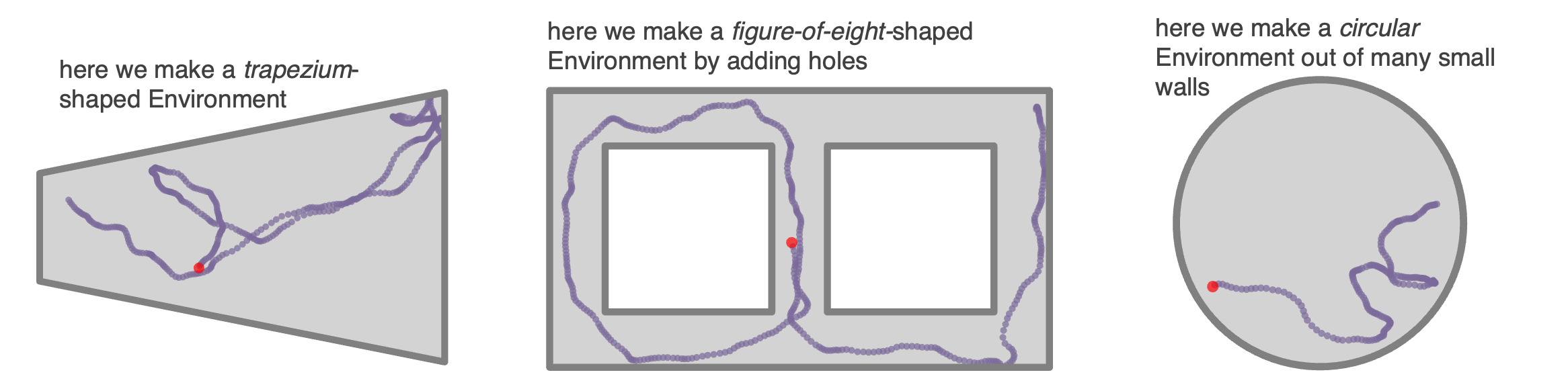 ### **Objects**
@@ -85,7 +85,7 @@ Envirnoment.add_object(object=[0.3,0.3],type=0)
Envirnoment.add_object(object=[0.7,0.3],type=0)
Envirnoment.add_object(object=[0.5,0.7],type=1)
```
-
### **Objects**
@@ -85,7 +85,7 @@ Envirnoment.add_object(object=[0.3,0.3],type=0)
Envirnoment.add_object(object=[0.7,0.3],type=0)
Envirnoment.add_object(object=[0.5,0.7],type=1)
```
- +
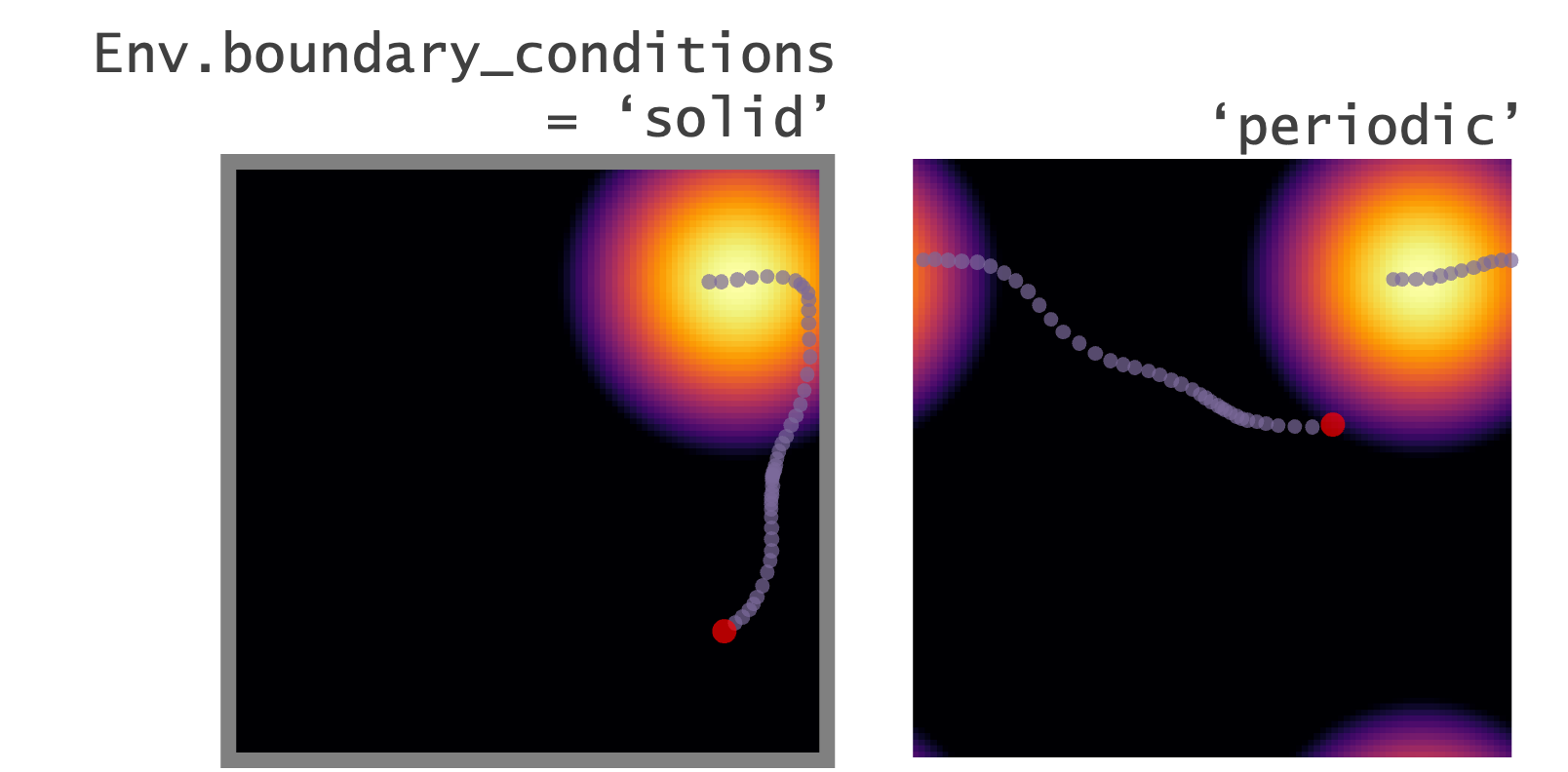
+ ### **Boundary conditions**
@@ -96,7 +96,7 @@ Env = Environment(
)
```
-
### **Boundary conditions**
@@ -96,7 +96,7 @@ Env = Environment(
)
```
- +
+ ### **1--or-2-dimensions**
`RatInABox` supports 1- or 2-dimensional `Environment`s. Almost all applicable features and plotting functions work in both. The following figure shows 1 minute of exploration of an `Agent` in a 1D environment with periodic boundary conditions spanned by 10 place cells.
@@ -106,7 +106,7 @@ Env = Environment(
)
```
-
### **1--or-2-dimensions**
`RatInABox` supports 1- or 2-dimensional `Environment`s. Almost all applicable features and plotting functions work in both. The following figure shows 1 minute of exploration of an `Agent` in a 1D environment with periodic boundary conditions spanned by 10 place cells.
@@ -106,7 +106,7 @@ Env = Environment(
)
```
- +
+ @@ -115,7 +115,7 @@ Env = Environment(
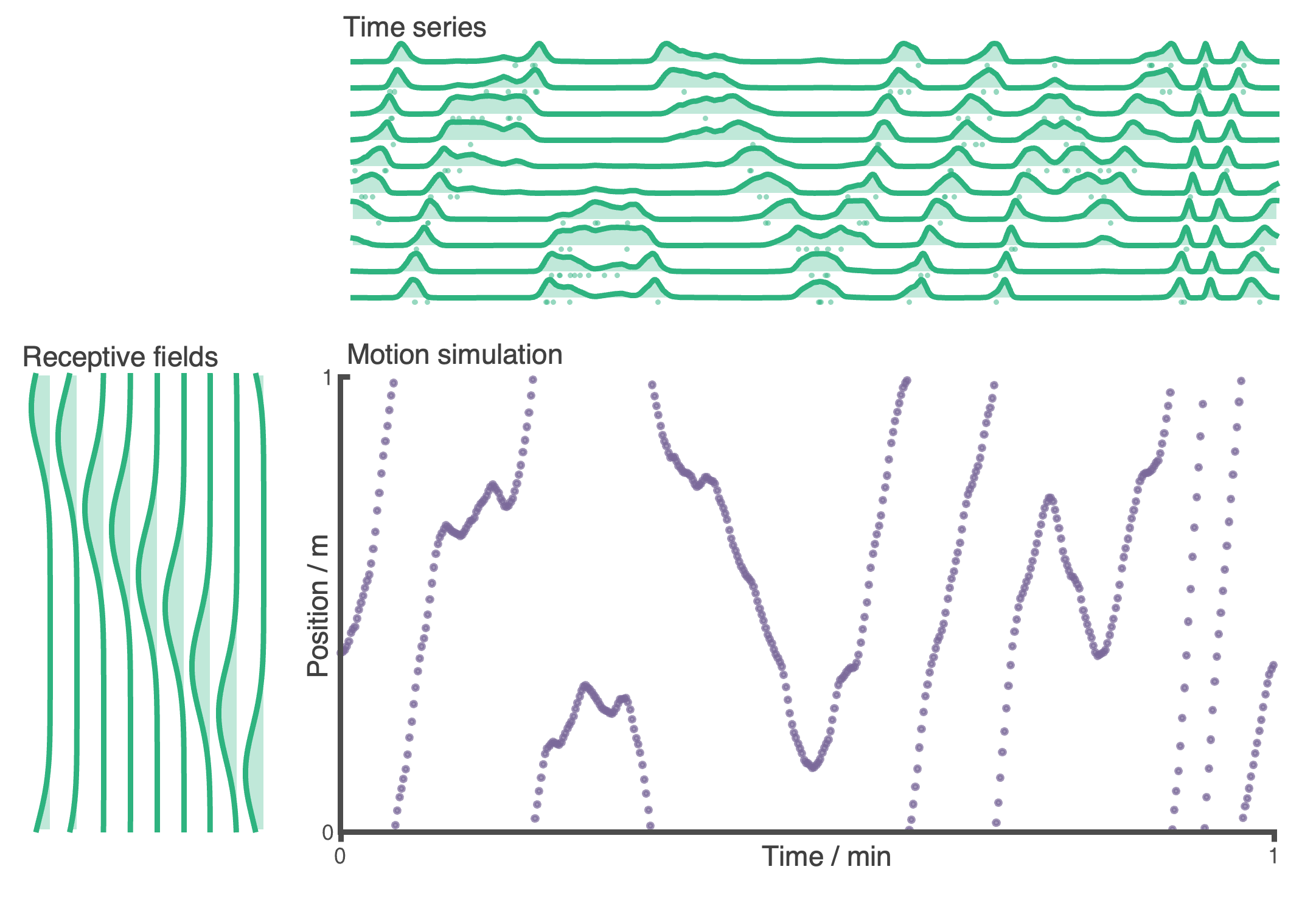
### **Random motion model**
By defaut the `Agent` follows a random motion policy. Random motion is stochastic but smooth. The speed (and rotational speed, if in 2D) of an Agent take constrained random walks governed by Ornstein-Uhlenbeck processes. You can change the means, variance and coherence times of these processes to control the shape of the trajectory. Default parameters are fit to real rat locomotion data from Sargolini et al. (2006):
-
@@ -115,7 +115,7 @@ Env = Environment(
### **Random motion model**
By defaut the `Agent` follows a random motion policy. Random motion is stochastic but smooth. The speed (and rotational speed, if in 2D) of an Agent take constrained random walks governed by Ornstein-Uhlenbeck processes. You can change the means, variance and coherence times of these processes to control the shape of the trajectory. Default parameters are fit to real rat locomotion data from Sargolini et al. (2006):
- +
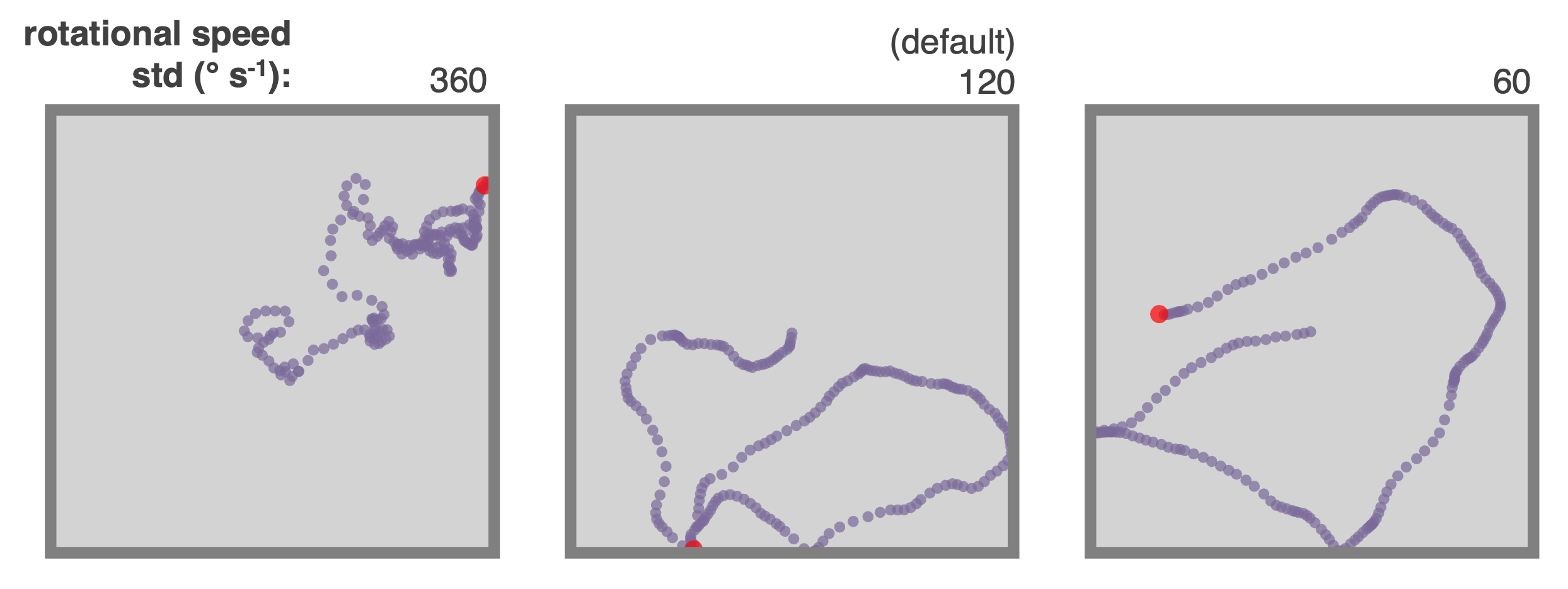
+ The default parameters can be changed to obtain different style trajectories. The following set of trajectories were generated by modifying the rotational speed parameter `Agent.rotational_velocity_std`:
@@ -126,7 +126,7 @@ Agent.rotation_velocity_std = 120 * np.pi/180 #radians
Agent.rotational_velocity_coherence_time = 0.08
```
-
The default parameters can be changed to obtain different style trajectories. The following set of trajectories were generated by modifying the rotational speed parameter `Agent.rotational_velocity_std`:
@@ -126,7 +126,7 @@ Agent.rotation_velocity_std = 120 * np.pi/180 #radians
Agent.rotational_velocity_coherence_time = 0.08
```
- +
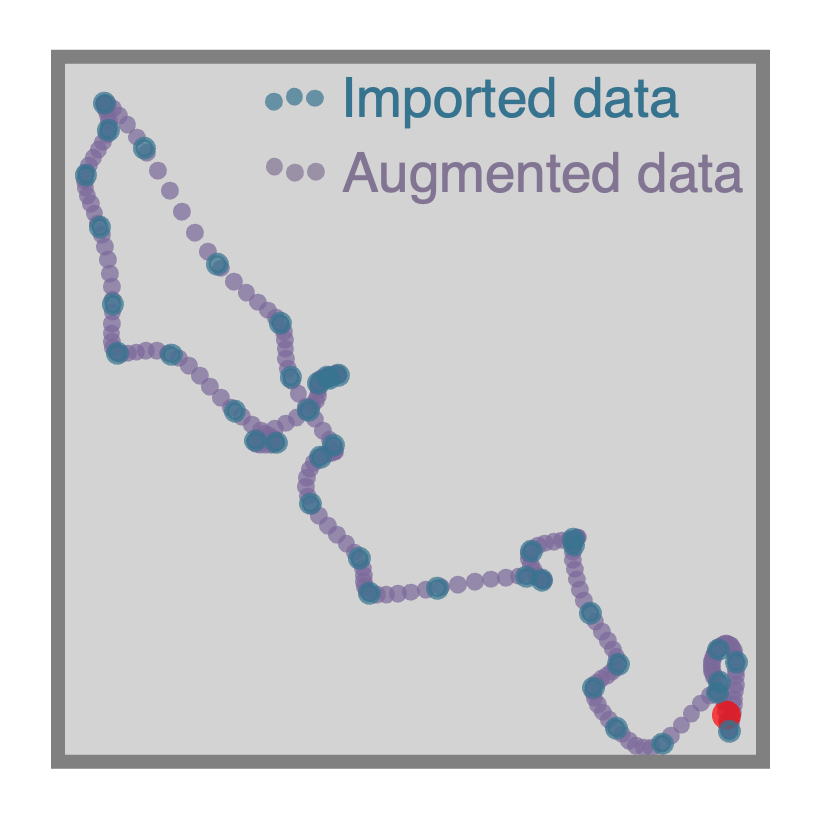
+ ### **Importing trajectories**
@@ -139,15 +139,15 @@ Agent.import_trajectory(times=array_of_times,
```
-
### **Importing trajectories**
@@ -139,15 +139,15 @@ Agent.import_trajectory(times=array_of_times,
```
- +
+ ### **Policy control**
-By default the movement policy is an random and uncontrolled (e.g. displayed above). It is possible, however, to manually pass a "drift_velocity" to the Agent on each `Agent.update()` step. This 'closes the loop' allowing, for example, Actor-Critic systems to control the Agent policy. As a demonstration that this method can be used to control the agent's movement we set a radial drift velocity to encourage circular motion. We also use RatInABox to perform a simple model-free RL task and find a reward hidden behind a wall (the full script is given as an example script [here](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb))
+By default the movement policy is an random and uncontrolled (e.g. displayed above). It is possible, however, to manually pass a "drift_velocity" to the Agent on each `Agent.update()` step. This 'closes the loop' allowing, for example, Actor-Critic systems to control the Agent policy. As a demonstration that this method can be used to control the agent's movement we set a radial drift velocity to encourage circular motion. We also use RatInABox to perform a simple model-free RL task and find a reward hidden behind a wall (the full script is given as an example script [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb))
```python
Agent.update(drift_velocity=drift_velocity)
```
-
### **Policy control**
-By default the movement policy is an random and uncontrolled (e.g. displayed above). It is possible, however, to manually pass a "drift_velocity" to the Agent on each `Agent.update()` step. This 'closes the loop' allowing, for example, Actor-Critic systems to control the Agent policy. As a demonstration that this method can be used to control the agent's movement we set a radial drift velocity to encourage circular motion. We also use RatInABox to perform a simple model-free RL task and find a reward hidden behind a wall (the full script is given as an example script [here](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb))
+By default the movement policy is an random and uncontrolled (e.g. displayed above). It is possible, however, to manually pass a "drift_velocity" to the Agent on each `Agent.update()` step. This 'closes the loop' allowing, for example, Actor-Critic systems to control the Agent policy. As a demonstration that this method can be used to control the agent's movement we set a radial drift velocity to encourage circular motion. We also use RatInABox to perform a simple model-free RL task and find a reward hidden behind a wall (the full script is given as an example script [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb))
```python
Agent.update(drift_velocity=drift_velocity)
```
- +
+ ### **Wall repelling**
Under the random motion policy, walls in the environment mildly "repel" the `Agent`. Coupled with the finite turning speed this replicates an effect (known as thigmotaxis, sometimes linked to anxiety) where the `Agent` is biased to over-explore near walls and corners (as shown in these heatmaps) matching real rodent behaviour. It can be turned up or down with the `thigmotaxis` parameter.
@@ -155,20 +155,20 @@ Under the random motion policy, walls in the environment mildly "repel" the `Age
Αgent.thigmotaxis = 0.8 #1 = high thigmotaxis (left plot), 0 = low (right)
```
-
### **Wall repelling**
Under the random motion policy, walls in the environment mildly "repel" the `Agent`. Coupled with the finite turning speed this replicates an effect (known as thigmotaxis, sometimes linked to anxiety) where the `Agent` is biased to over-explore near walls and corners (as shown in these heatmaps) matching real rodent behaviour. It can be turned up or down with the `thigmotaxis` parameter.
@@ -155,20 +155,20 @@ Under the random motion policy, walls in the environment mildly "repel" the `Age
Αgent.thigmotaxis = 0.8 #1 = high thigmotaxis (left plot), 0 = low (right)
```
- +
+ ### **Multiple `Agent`s**
There is nothing to stop multiple `Agent`s being added to the same `Environment`. When plotting/animating trajectories set the kwarg `plot_all_agents=True` to visualise all `Agent`s simultaneously.
The following animation shows three `Agent`s in an `Environment`. Drift velocities are set so that `Agent`s weally locally attract one another creating "interactive" behaviour.
-
### **Multiple `Agent`s**
There is nothing to stop multiple `Agent`s being added to the same `Environment`. When plotting/animating trajectories set the kwarg `plot_all_agents=True` to visualise all `Agent`s simultaneously.
The following animation shows three `Agent`s in an `Environment`. Drift velocities are set so that `Agent`s weally locally attract one another creating "interactive" behaviour.
- +
+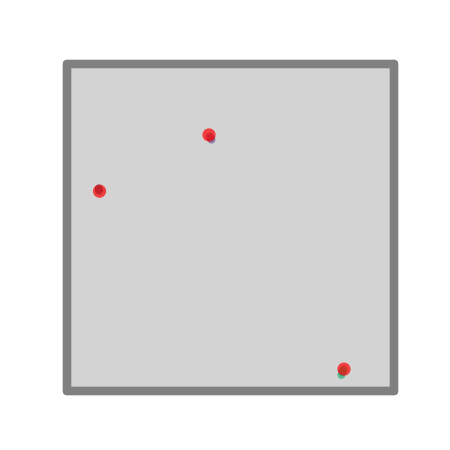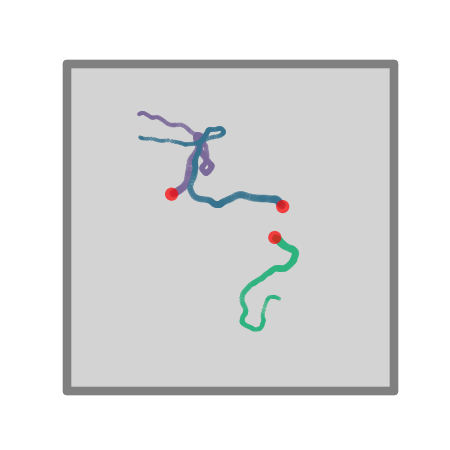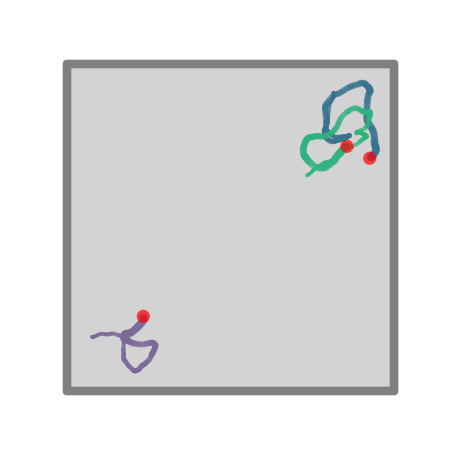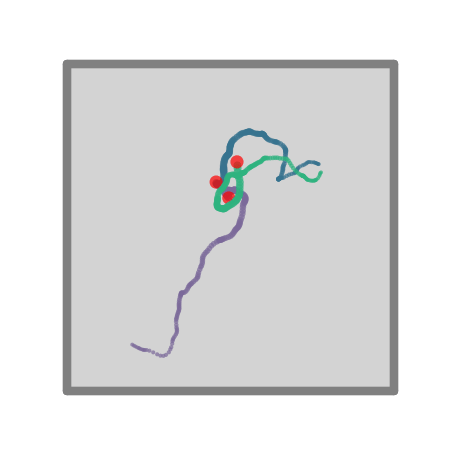 ### **Advanced `Agent` classes**
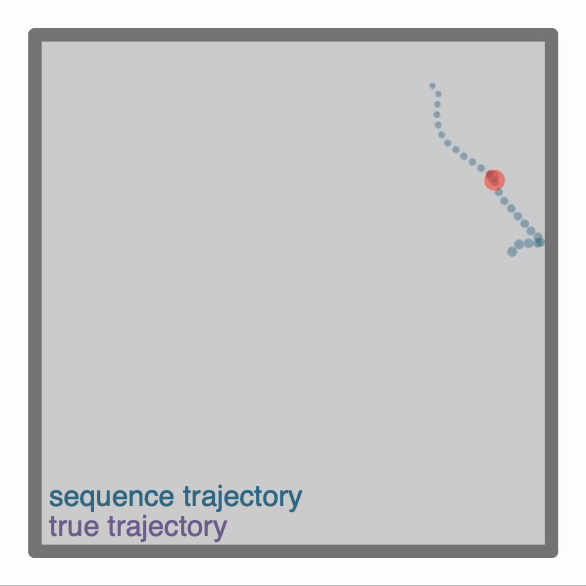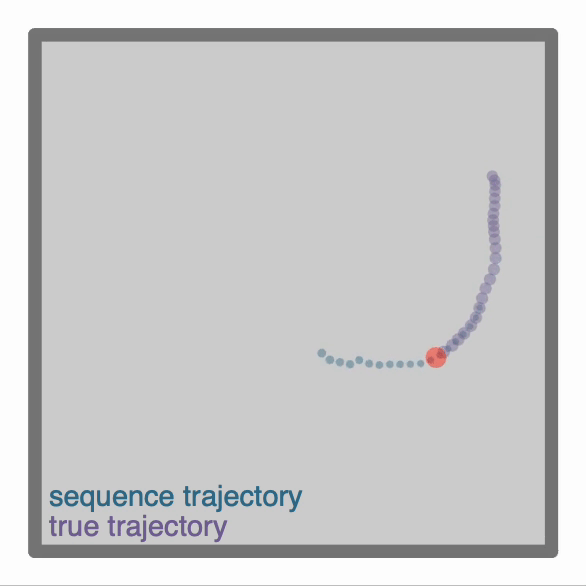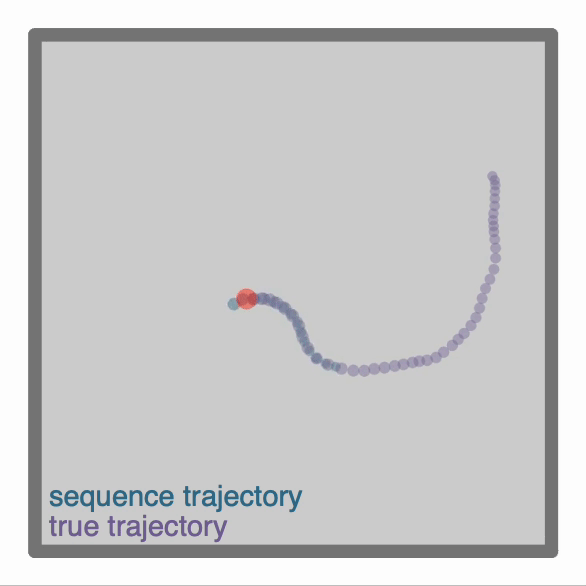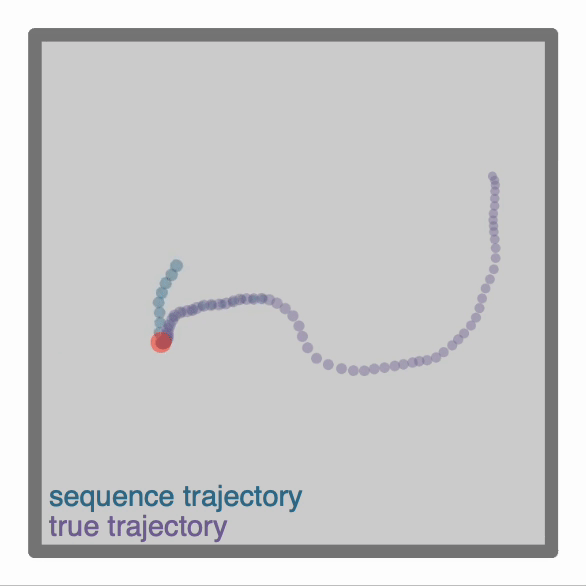
-One can make more advanced Agent classes, for example `ThetaSequenceAgent()` where the position "sweeps" (blue) over the position of an underlying true (regular) `Agent()` (purple), highly reminiscent of theta sequences observed when one decodes position from the hippocampal populaton code on sub-theta (10 Hz) timescales. This class can be found in the [`contribs`](https://github.com/RatInABox-Lab/RatInABox/tree/dev/ratinabox/contribs) directory.
+One can make more advanced Agent classes, for example `ThetaSequenceAgent()` where the position "sweeps" (blue) over the position of an underlying true (regular) `Agent()` (purple), highly reminiscent of theta sequences observed when one decodes position from the hippocampal populaton code on sub-theta (10 Hz) timescales. This class can be found in the [`contribs`](https://github.com/RatInABox-Lab/RatInABox/tree/main/ratinabox/contribs) directory.
-
### **Advanced `Agent` classes**
-One can make more advanced Agent classes, for example `ThetaSequenceAgent()` where the position "sweeps" (blue) over the position of an underlying true (regular) `Agent()` (purple), highly reminiscent of theta sequences observed when one decodes position from the hippocampal populaton code on sub-theta (10 Hz) timescales. This class can be found in the [`contribs`](https://github.com/RatInABox-Lab/RatInABox/tree/dev/ratinabox/contribs) directory.
+One can make more advanced Agent classes, for example `ThetaSequenceAgent()` where the position "sweeps" (blue) over the position of an underlying true (regular) `Agent()` (purple), highly reminiscent of theta sequences observed when one decodes position from the hippocampal populaton code on sub-theta (10 Hz) timescales. This class can be found in the [`contribs`](https://github.com/RatInABox-Lab/RatInABox/tree/main/ratinabox/contribs) directory.
- +
+ ## (iii) `Neurons` features
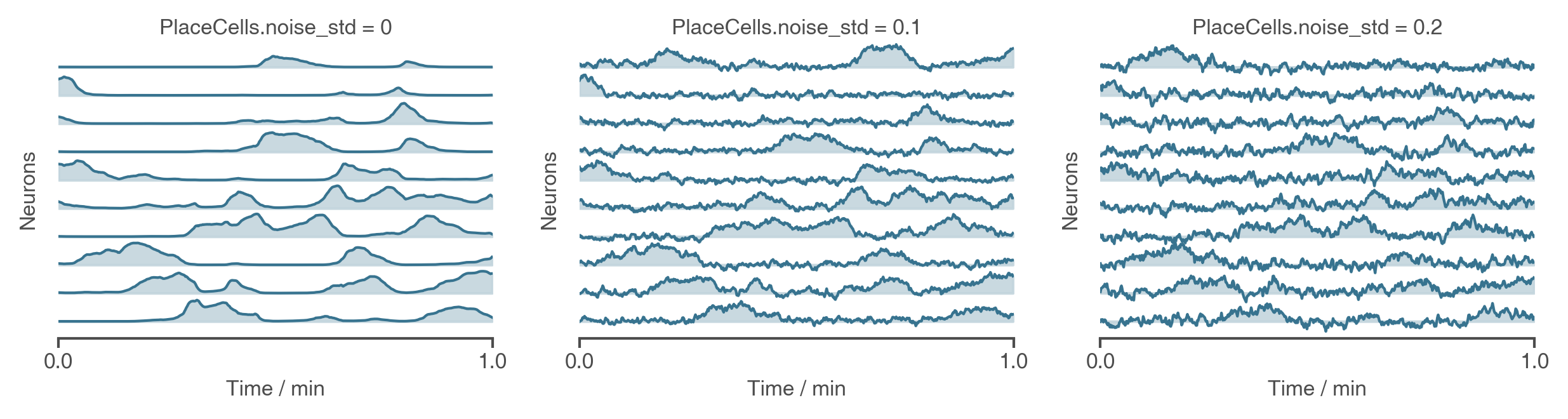
@@ -201,7 +201,7 @@ PCs = PlaceCells(Ag,params={
})
```
-
## (iii) `Neurons` features
@@ -201,7 +201,7 @@ PCs = PlaceCells(Ag,params={
})
```
- +
+ ### Spiking
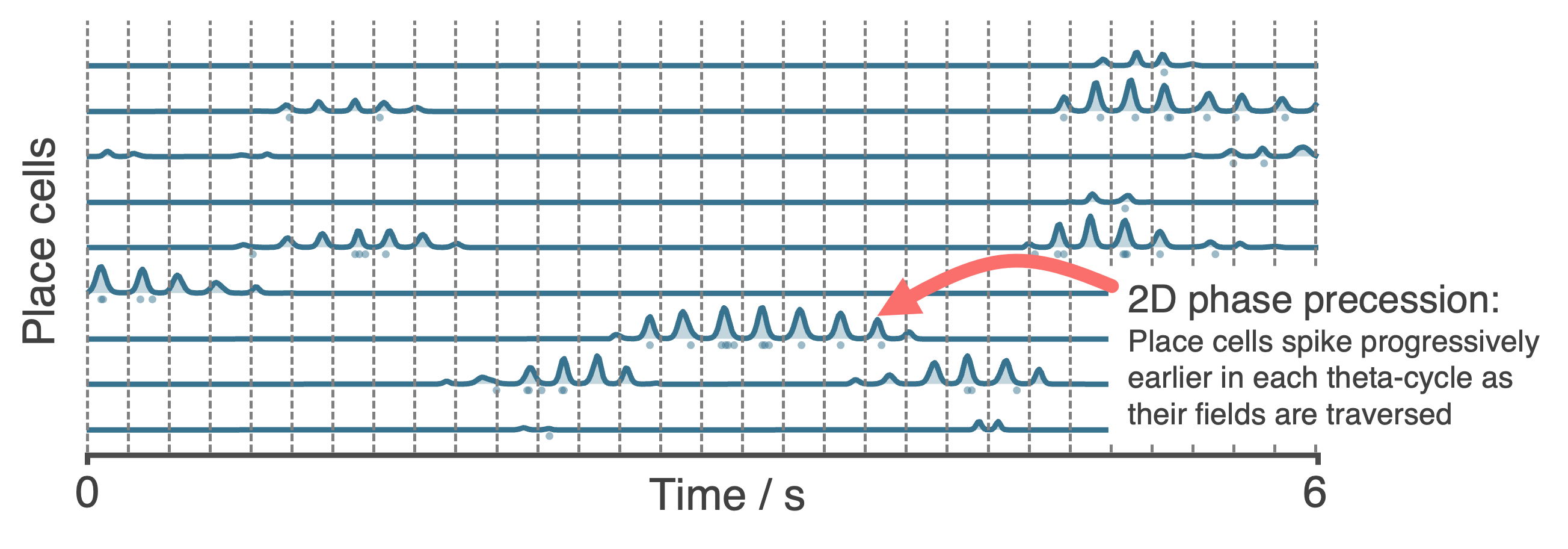
All neurons are rate based. However, at each update spikes are sampled as though neurons were Poisson neurons. These are stored in `Neurons.history['spikes']`. The max and min firing rates can be set with `Neurons.max_fr` and `Neurons.min_fr`.
@@ -209,7 +209,7 @@ All neurons are rate based. However, at each update spikes are sampled as though
Neurons.plot_ratemap(spikes=True)
```
-
### Spiking
All neurons are rate based. However, at each update spikes are sampled as though neurons were Poisson neurons. These are stored in `Neurons.history['spikes']`. The max and min firing rates can be set with `Neurons.max_fr` and `Neurons.min_fr`.
@@ -209,7 +209,7 @@ All neurons are rate based. However, at each update spikes are sampled as though
Neurons.plot_ratemap(spikes=True)
```
- +
+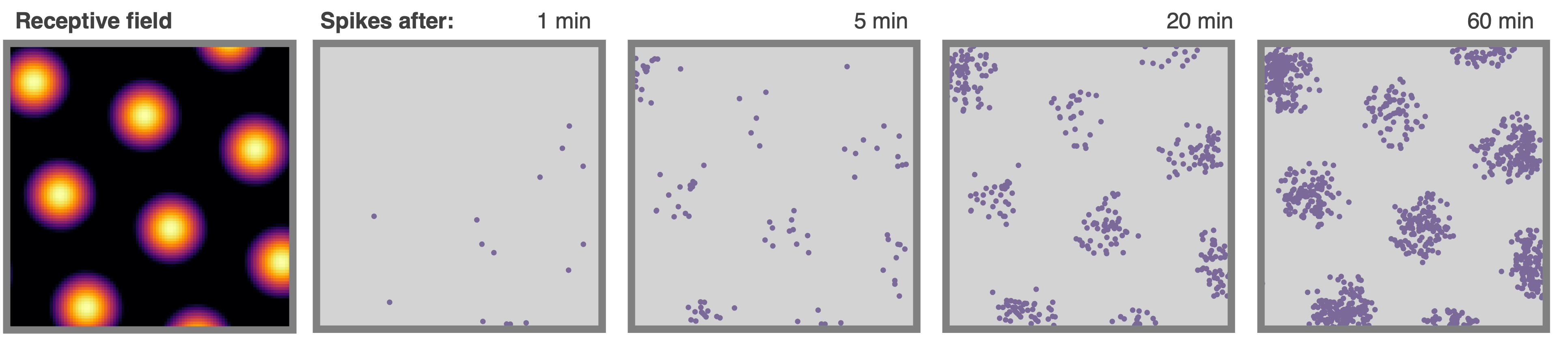 ### **Rate maps**
@@ -221,7 +221,7 @@ Neurons.plot_rate_map() #attempts to plot "ground truth" rate map
Neurons.plot_rate_map(method="history") #plots rate map by firing-rate-weighted position heatmap
```
-
### **Rate maps**
@@ -221,7 +221,7 @@ Neurons.plot_rate_map() #attempts to plot "ground truth" rate map
Neurons.plot_rate_map(method="history") #plots rate map by firing-rate-weighted position heatmap
```
- +
+ ### **Place cell models**
@@ -235,17 +235,17 @@ Place cells come in multiple types (given by `params['description']`), or it wou
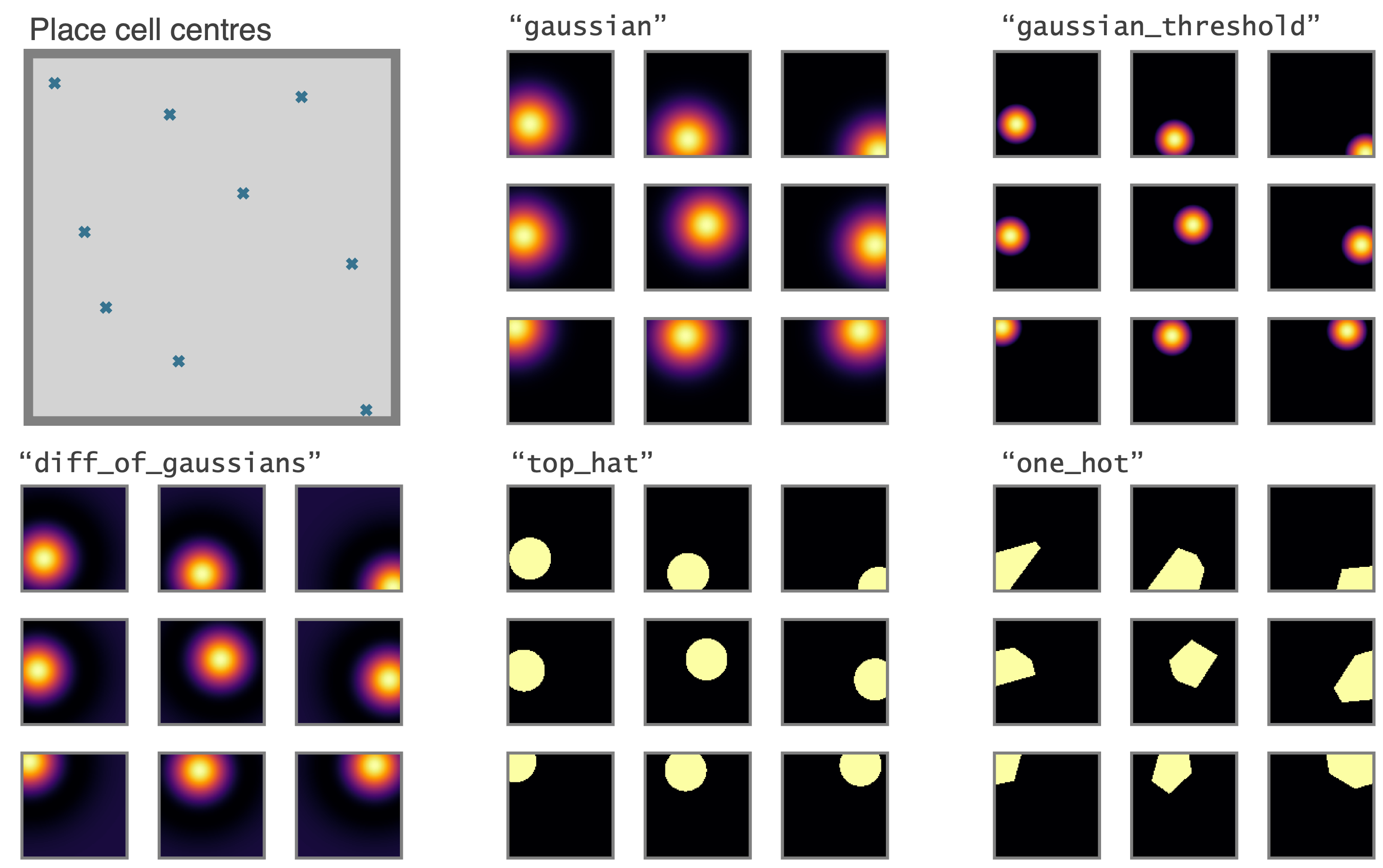
This last place cell type, `"one_hot"` is particularly useful as it essentially rediscretises space and tabularises the state space (gridworld again). This can be used to contrast and compare learning algorithms acting over continuous vs discrete state spaces. This figure compares the 5 place cell models for population of 9 place cells (top left shows centres of place cells, and in all cases the `"widths"` parameters is set to 0.2 m, or irrelevant in the case of `"one_hot"`s)
-
### **Place cell models**
@@ -235,17 +235,17 @@ Place cells come in multiple types (given by `params['description']`), or it wou
This last place cell type, `"one_hot"` is particularly useful as it essentially rediscretises space and tabularises the state space (gridworld again). This can be used to contrast and compare learning algorithms acting over continuous vs discrete state spaces. This figure compares the 5 place cell models for population of 9 place cells (top left shows centres of place cells, and in all cases the `"widths"` parameters is set to 0.2 m, or irrelevant in the case of `"one_hot"`s)
- +
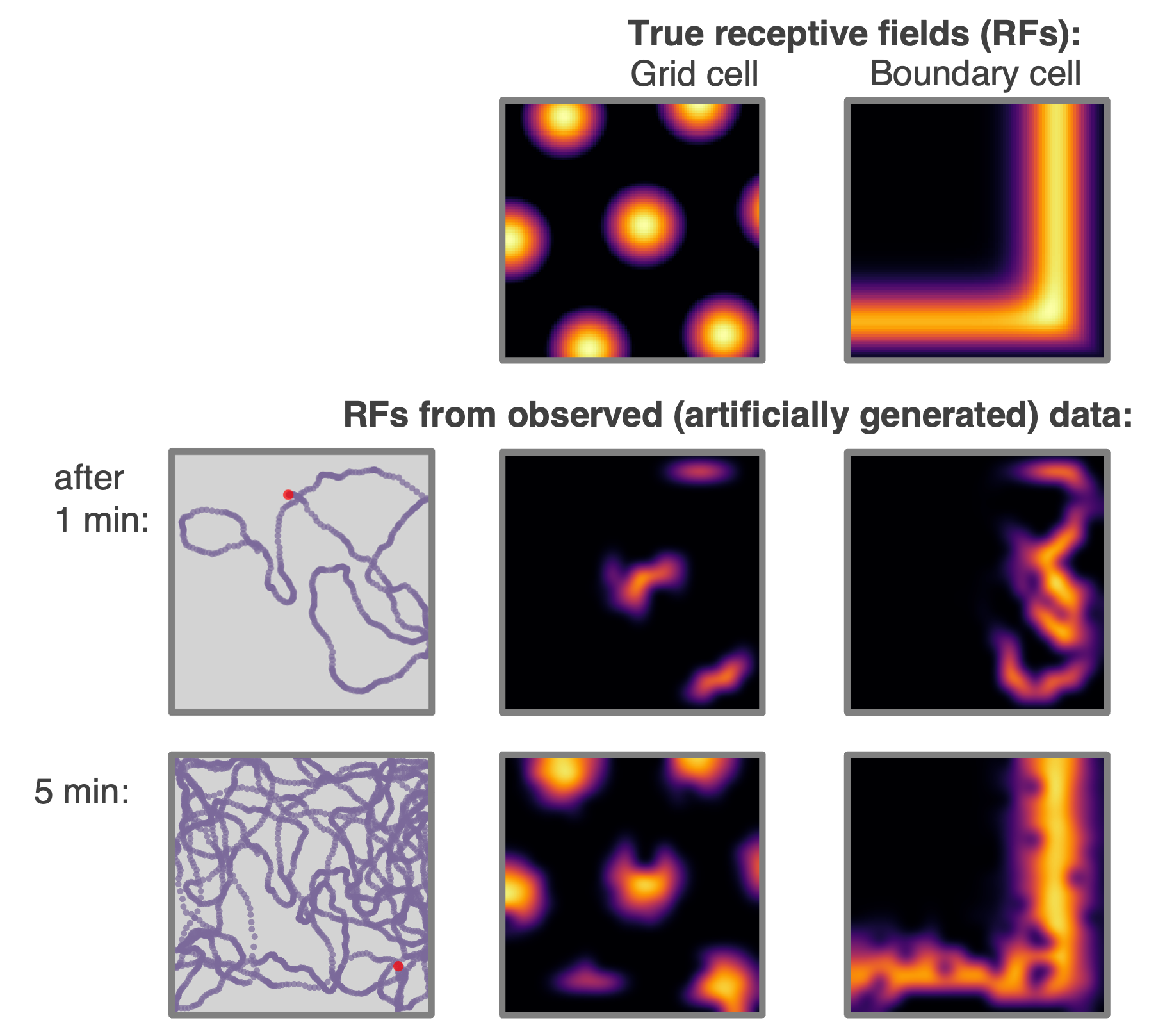
+ These place cells (with the exception of `"one_hot"`s) can all be made to phase precess by instead initialising them with the `PhasePrecessingPlaceCells()` class currently residing in the `contribs` folder. This figure shows example output data.
-
These place cells (with the exception of `"one_hot"`s) can all be made to phase precess by instead initialising them with the `PhasePrecessingPlaceCells()` class currently residing in the `contribs` folder. This figure shows example output data.
- +
+ ### **Geometry of `PlaceCells`**
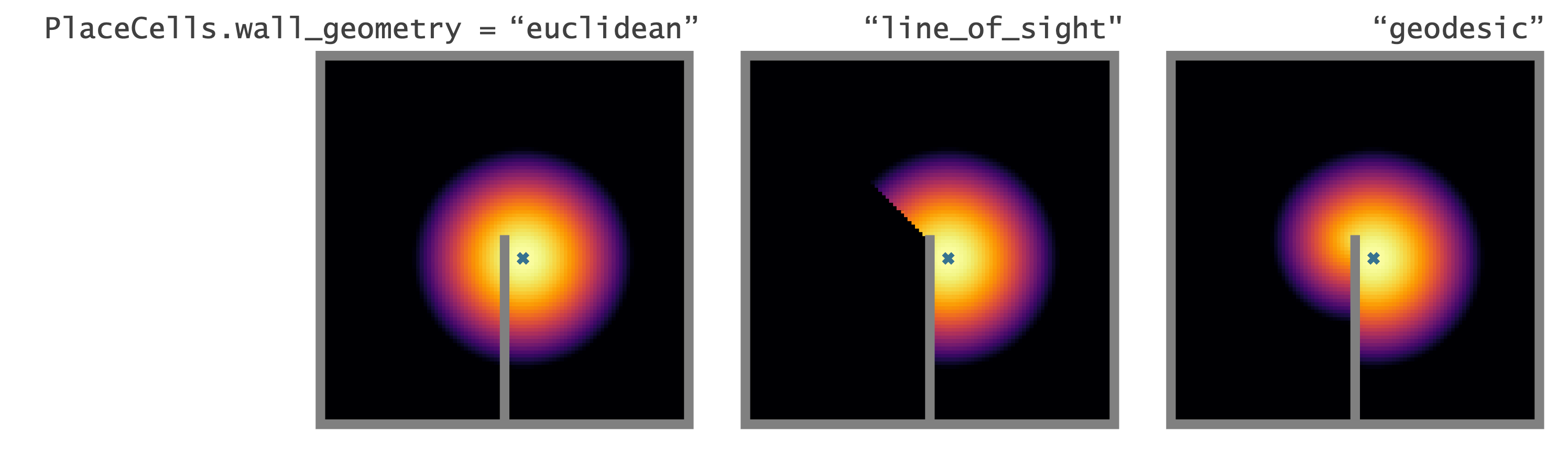
Choose how you want `PlaceCells` to interact with walls in the `Environment`. We provide three types of geometries.
-
### **Geometry of `PlaceCells`**
Choose how you want `PlaceCells` to interact with walls in the `Environment`. We provide three types of geometries.
- +
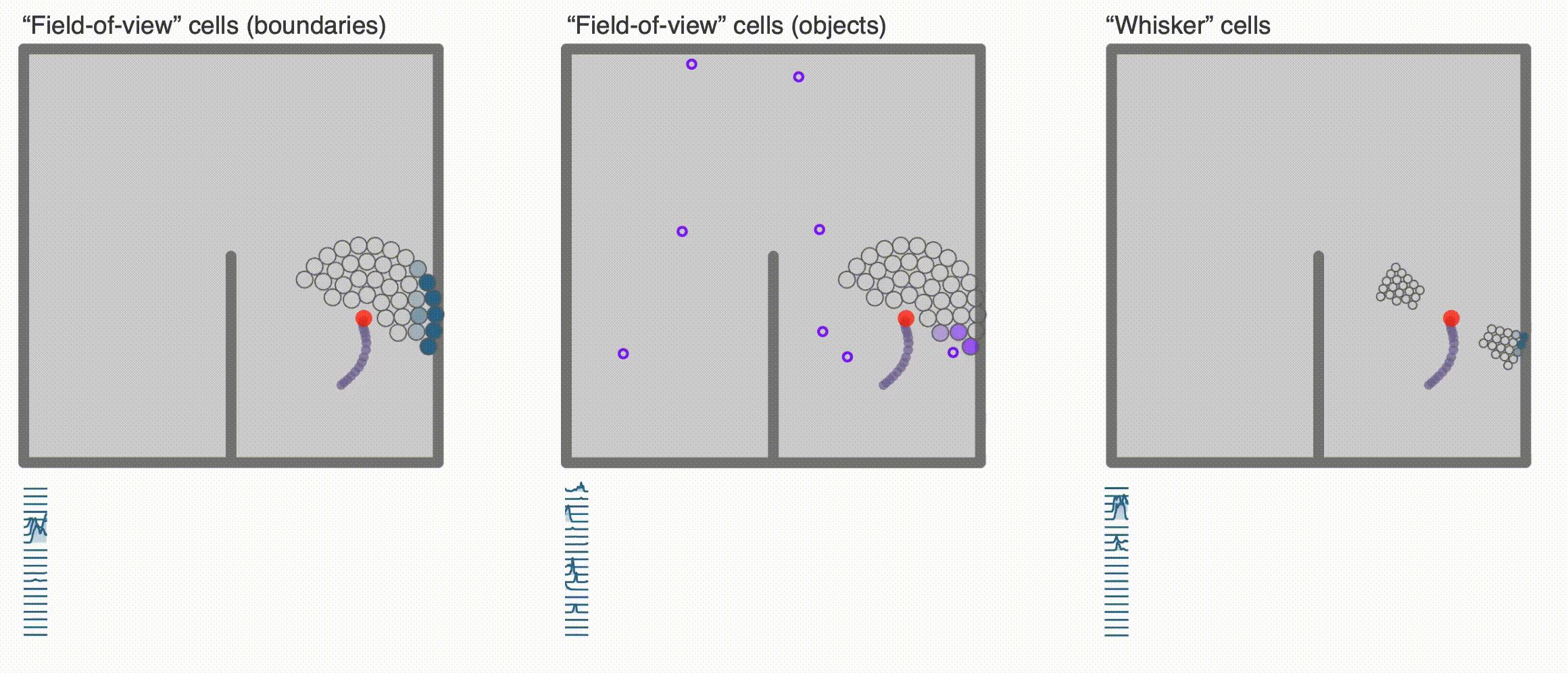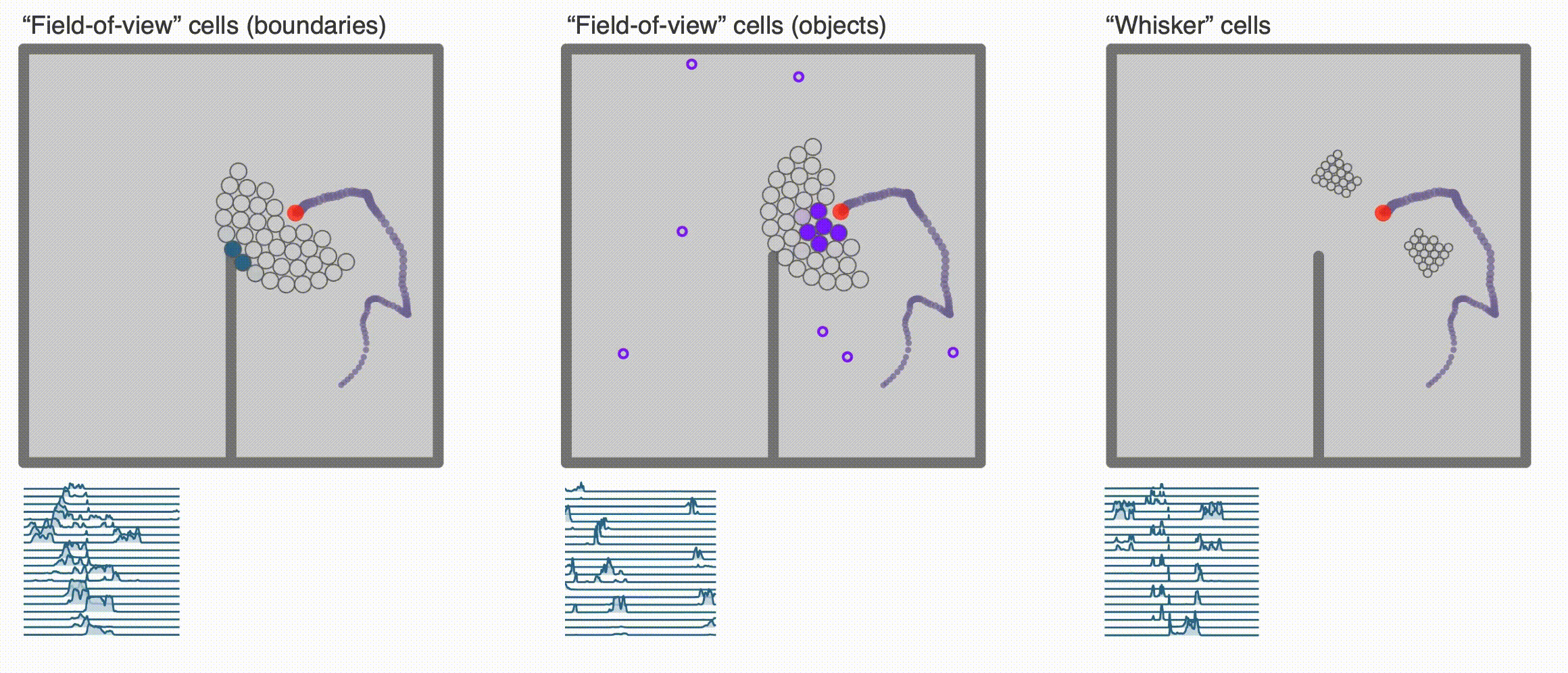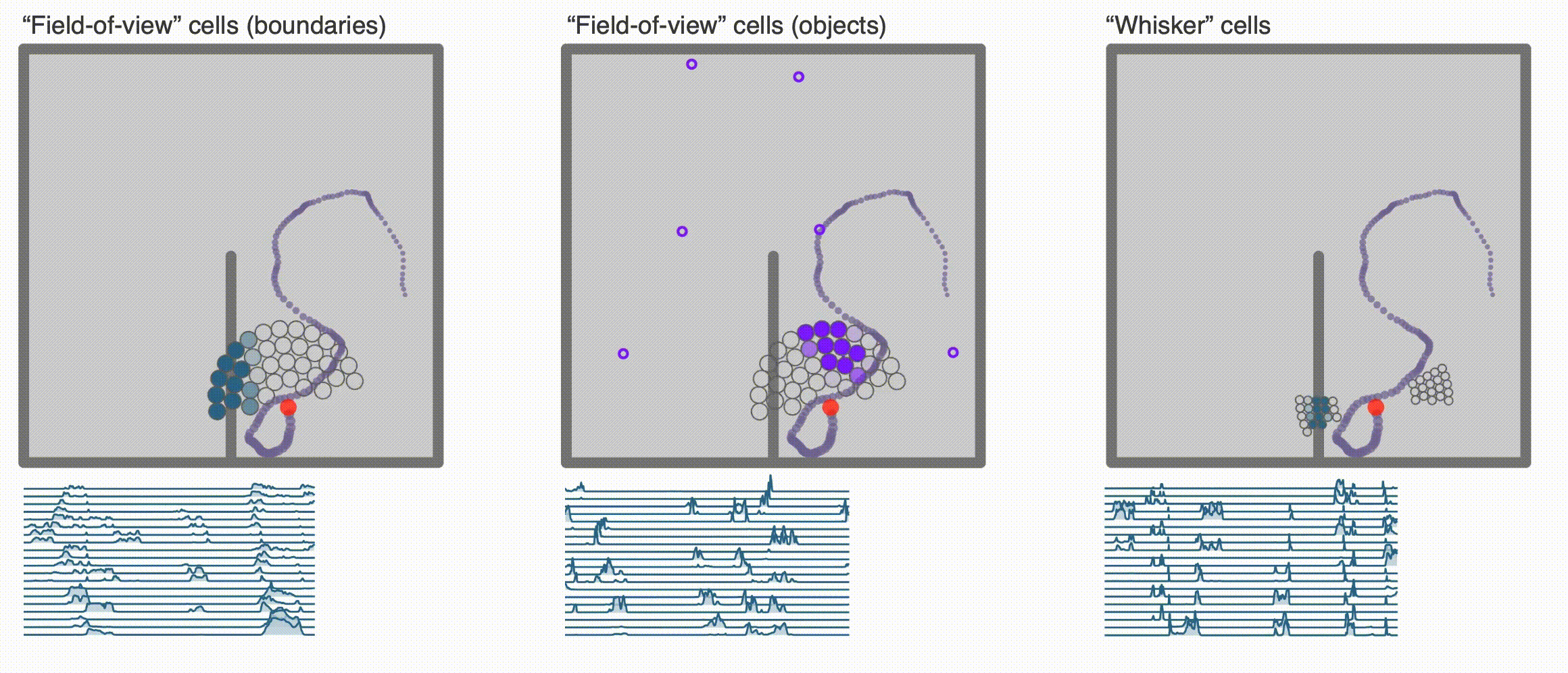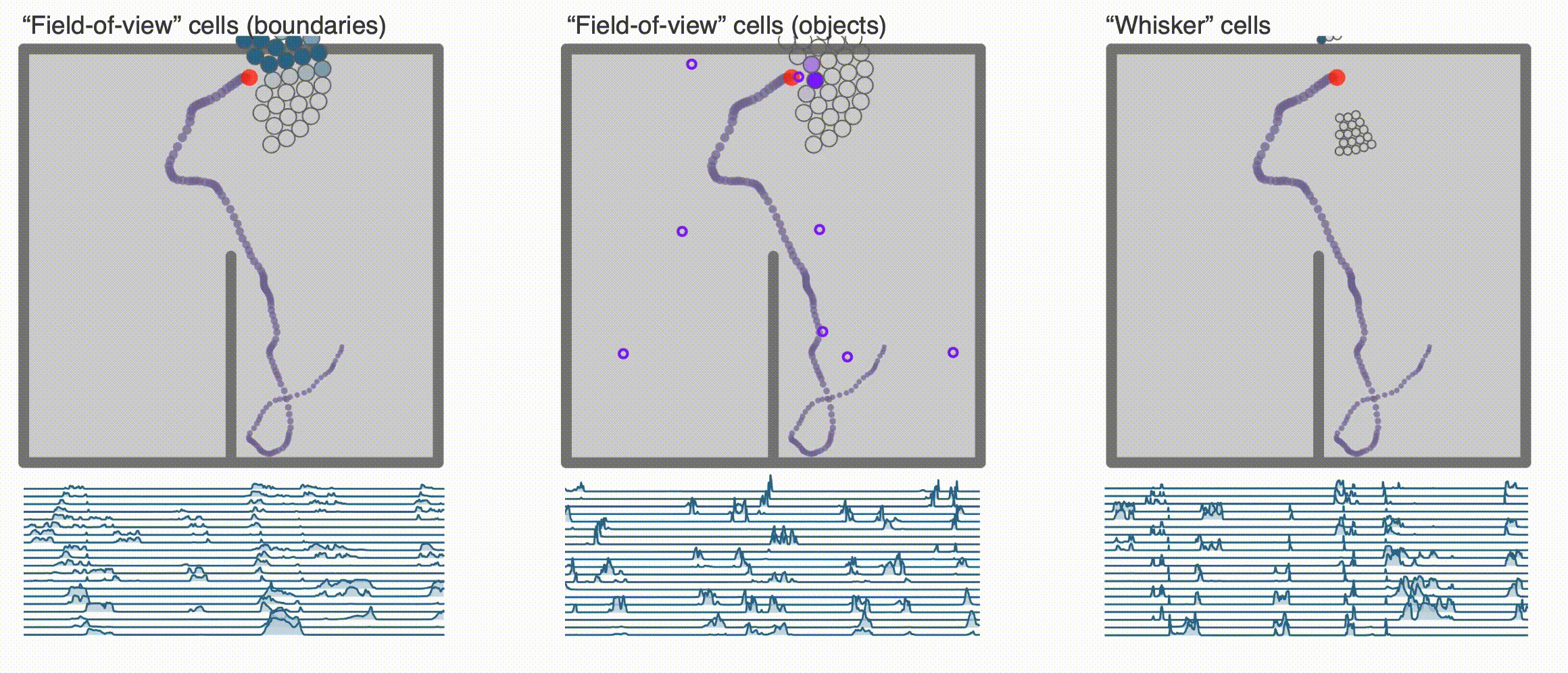
+ ### **Egocentric encodings**
@@ -266,15 +266,15 @@ BVCs_whiskers = FieldOfViewBVCs(Ag,params={
})
```
-
### **Egocentric encodings**
@@ -266,15 +266,15 @@ BVCs_whiskers = FieldOfViewBVCs(Ag,params={
})
```
- +
+ ### **Reinforcement Learning and Successor Features**
-A dedicated `Neurons` class called `SuccessorFeatures` learns the successor features for a given feature set under the current policy. See [this demo](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/successor_features_example.ipynb) for more info.
-
### **Reinforcement Learning and Successor Features**
-A dedicated `Neurons` class called `SuccessorFeatures` learns the successor features for a given feature set under the current policy. See [this demo](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/successor_features_example.ipynb) for more info.
- +A dedicated `Neurons` class called `SuccessorFeatures` learns the successor features for a given feature set under the current policy. See [this demo](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/successor_features_example.ipynb) for more info.
+
+A dedicated `Neurons` class called `SuccessorFeatures` learns the successor features for a given feature set under the current policy. See [this demo](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/successor_features_example.ipynb) for more info.
+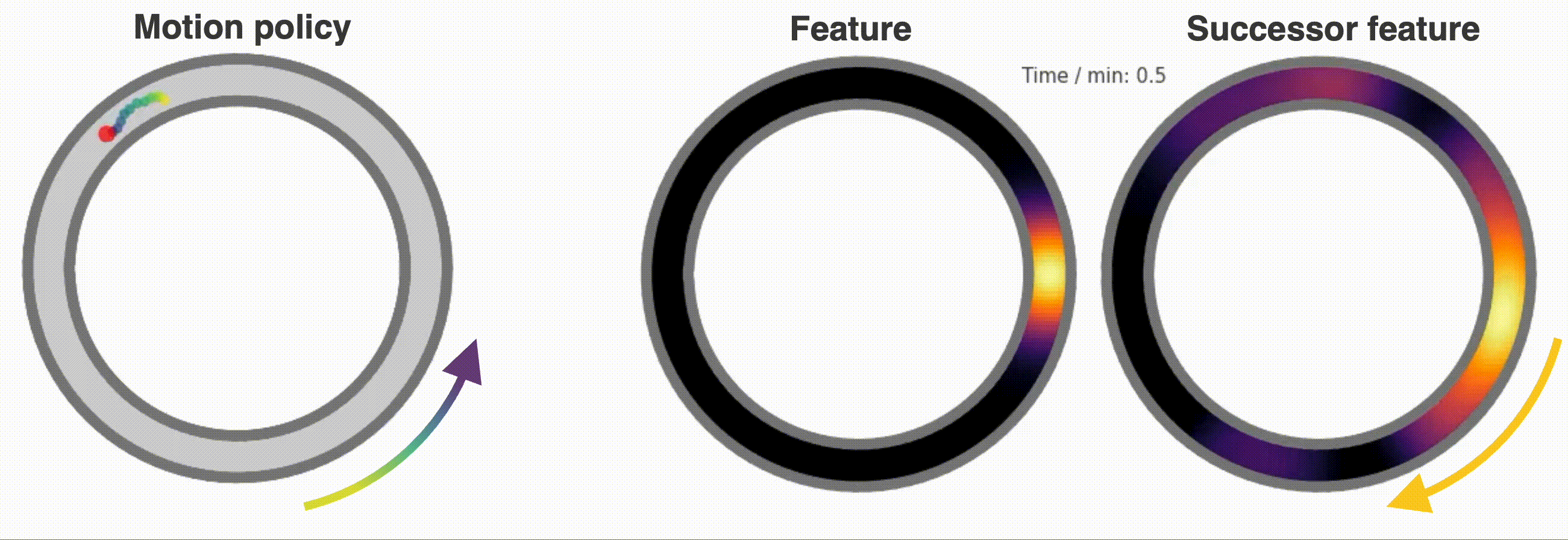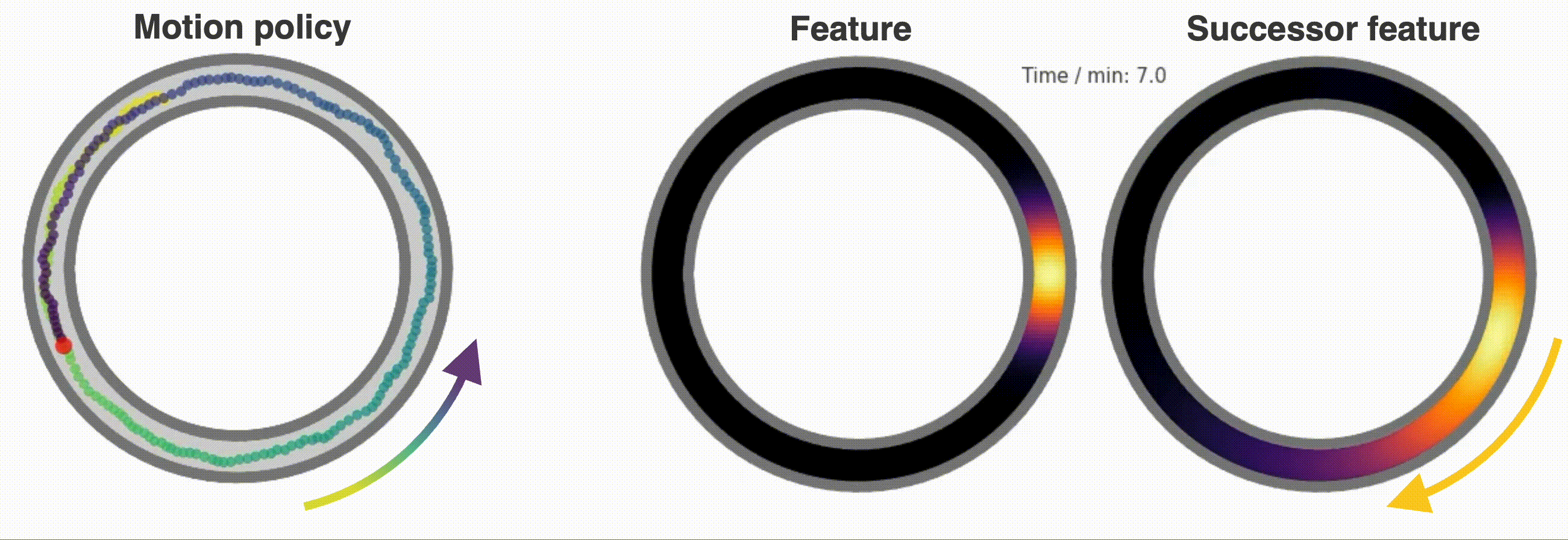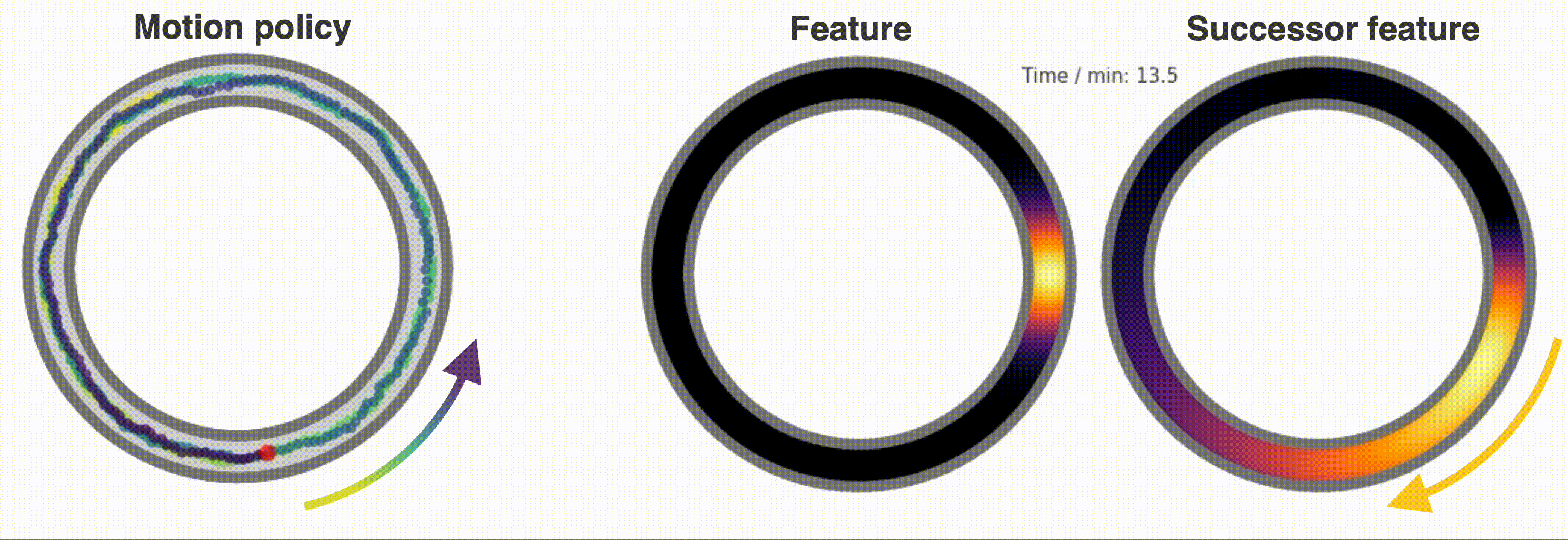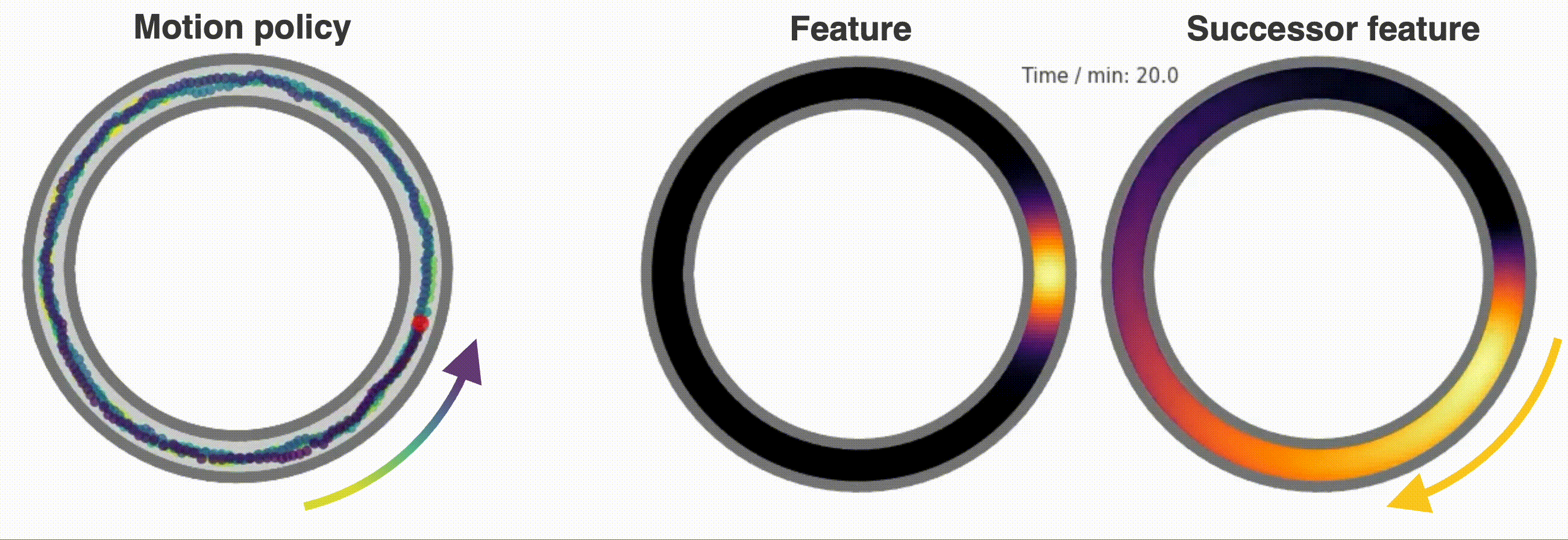 -`SuccessorFeatures` are a specific instance of a more general class of neurons called `ValueNeuron`s which learn value function for any reward density under the `Agent`s motion policy. This can be used to do reinforcement learning tasks such as finding rewards hidden behind walls etc as shown in [this demo](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb).
+`SuccessorFeatures` are a specific instance of a more general class of neurons called `ValueNeuron`s which learn value function for any reward density under the `Agent`s motion policy. This can be used to do reinforcement learning tasks such as finding rewards hidden behind walls etc as shown in [this demo](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb).
-We also have a working examples of and actor critic algorithm using deep neural networks [here](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/actor_critic_example.ipynb)
+We also have a working examples of and actor critic algorithm using deep neural networks [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/actor_critic_example.ipynb)
Finally, we are working on a dedicated subpackage -- (`RATS`: RL Agent Toolkit and Simulator) -- to host all this RL stuff and more so keep an eye out.
@@ -285,15 +285,15 @@ Perhaps you want to generate really complex cell types (more complex than just `
* `FeedForwardLayer` linearly sums their inputs with a set of weights.
* `NeuralNetworkNeurons` are more general, they pass their inputs through a user-provided deep neural network (for this we use `pytorch`).
-
-`SuccessorFeatures` are a specific instance of a more general class of neurons called `ValueNeuron`s which learn value function for any reward density under the `Agent`s motion policy. This can be used to do reinforcement learning tasks such as finding rewards hidden behind walls etc as shown in [this demo](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb).
+`SuccessorFeatures` are a specific instance of a more general class of neurons called `ValueNeuron`s which learn value function for any reward density under the `Agent`s motion policy. This can be used to do reinforcement learning tasks such as finding rewards hidden behind walls etc as shown in [this demo](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb).
-We also have a working examples of and actor critic algorithm using deep neural networks [here](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/actor_critic_example.ipynb)
+We also have a working examples of and actor critic algorithm using deep neural networks [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/actor_critic_example.ipynb)
Finally, we are working on a dedicated subpackage -- (`RATS`: RL Agent Toolkit and Simulator) -- to host all this RL stuff and more so keep an eye out.
@@ -285,15 +285,15 @@ Perhaps you want to generate really complex cell types (more complex than just `
* `FeedForwardLayer` linearly sums their inputs with a set of weights.
* `NeuralNetworkNeurons` are more general, they pass their inputs through a user-provided deep neural network (for this we use `pytorch`).
- +
+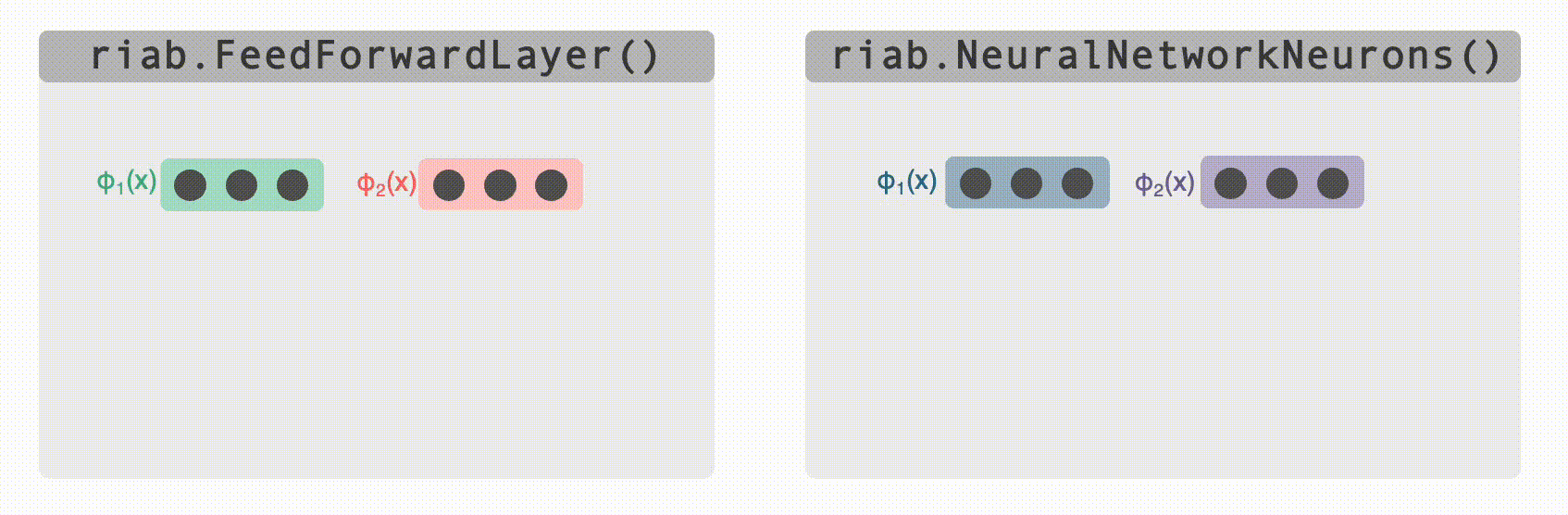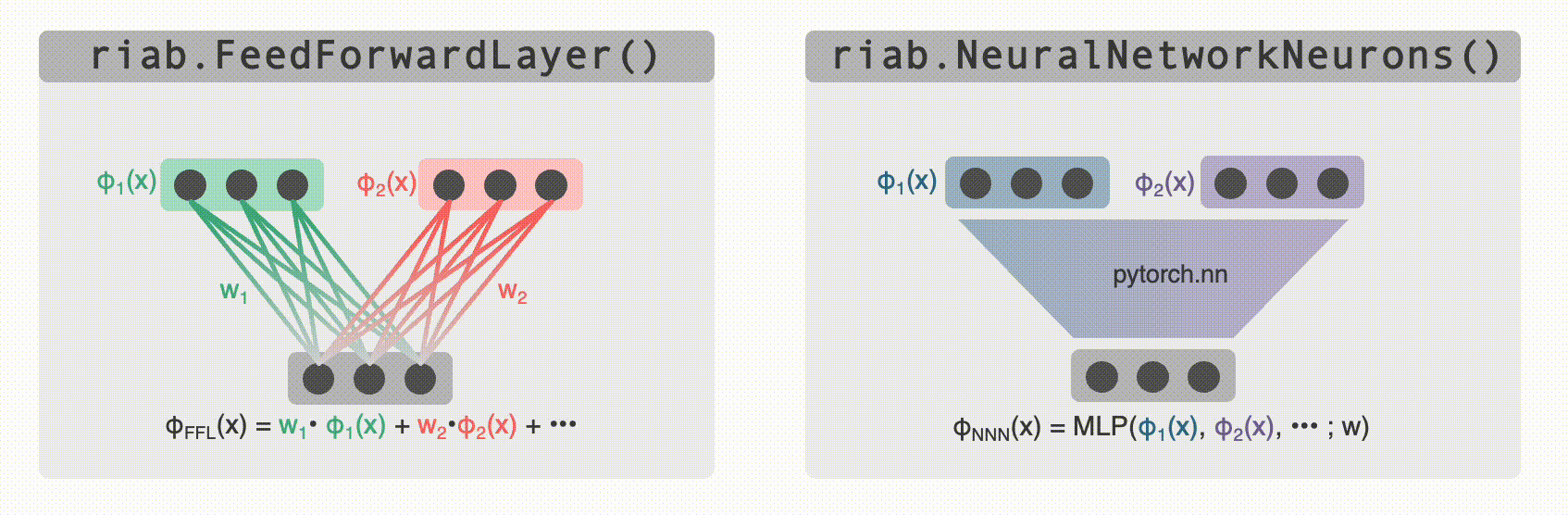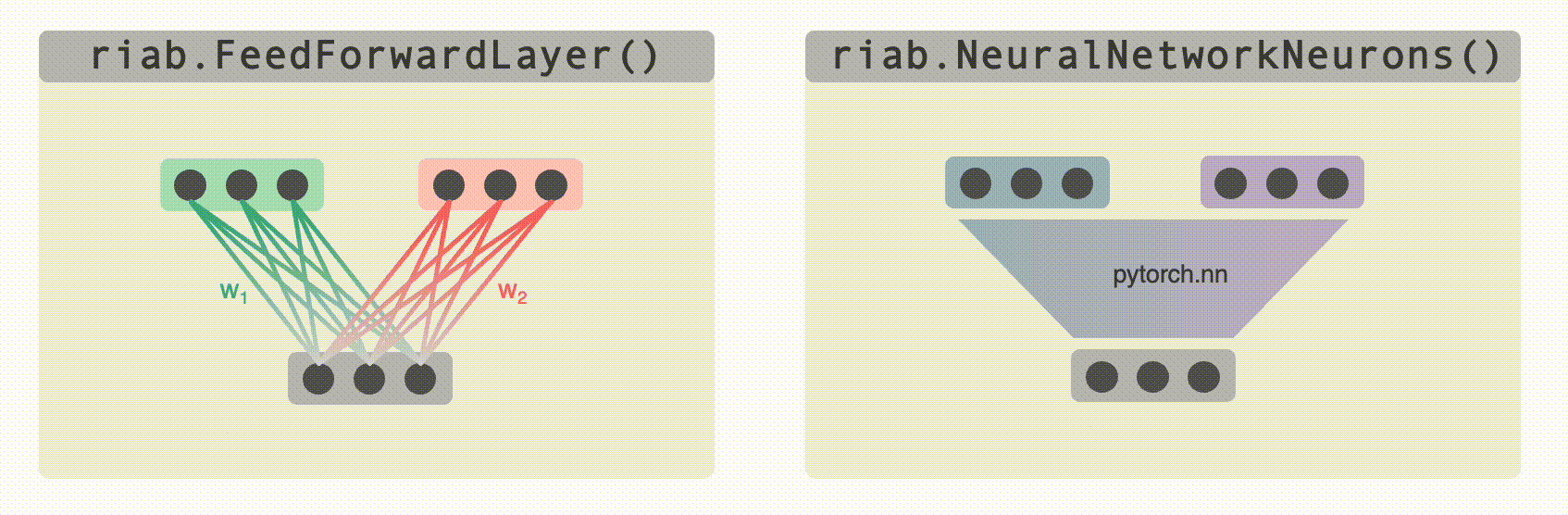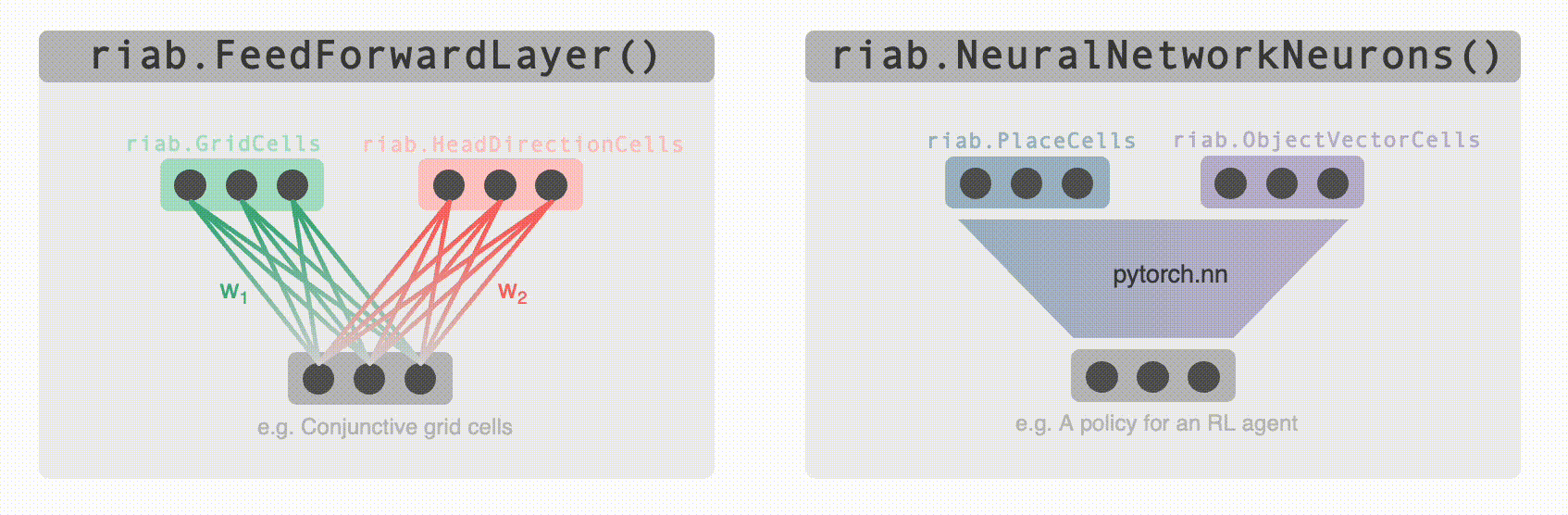 -Both of these classes can be used as the building block for constructing complex multilayer networks of `Neurons` (e.g. `FeedForwardLayers` are `RatInABox.Neurons` in their own right so can be used as inputs to other `FeedForwardLayers`). Their parameters can be accessed and set (or "trained") to create neurons with complex receptive fields. In the case of `DeepNeuralNetwork` neurons the firing rate attached to the computational graph is stored so gradients can be taken. Examples can be found [here (path integration)](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/path_integration_example.ipynb), [here (reinforcement learning)](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb), [here (successor features)](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/successor_features_example.ipynb) and [here (actor_critic_demo)](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/actor_critic_example.ipynb).
+Both of these classes can be used as the building block for constructing complex multilayer networks of `Neurons` (e.g. `FeedForwardLayers` are `RatInABox.Neurons` in their own right so can be used as inputs to other `FeedForwardLayers`). Their parameters can be accessed and set (or "trained") to create neurons with complex receptive fields. In the case of `DeepNeuralNetwork` neurons the firing rate attached to the computational graph is stored so gradients can be taken. Examples can be found [here (path integration)](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/path_integration_example.ipynb), [here (reinforcement learning)](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb), [here (successor features)](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/successor_features_example.ipynb) and [here (actor_critic_demo)](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/actor_critic_example.ipynb).
### **Creating your own `Neuron` types**
-We encourage users to create their own subclasses of `Neurons`. This is easy to do, see comments in the `Neurons` class within the [code](https://github.com/RatInABox-Lab/RatInABox/blob/dev/ratinabox/Neurons.py) for explanation. By forming these classes from the parent `Neurons` class, the plotting and analysis features described above remain available to these bespoke Neuron types.
+We encourage users to create their own subclasses of `Neurons`. This is easy to do, see comments in the `Neurons` class within the [code](https://github.com/RatInABox-Lab/RatInABox/blob/main/ratinabox/Neurons.py) for explanation. By forming these classes from the parent `Neurons` class, the plotting and analysis features described above remain available to these bespoke Neuron types.
## (iv) Figures and animations
`RatInABox` is built to be highly visual. It is easy to plot or animate data and save these plots/animations. Here are some tips
@@ -321,4 +321,4 @@ Neurons.plot_rate_timeseries() # plots activities of the neurons over time
Neurons.animate_rate_timeseries() # animates the activity of the neurons over time
```
-Most plotting functions accept `fig` and `ax` as optional arguments and if passed will plot ontop of these. This can be used to make comolex or multipanel figures. For a comprehensive list of plotting functions see [here](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/list_of_plotting_fuctions.md).
+Most plotting functions accept `fig` and `ax` as optional arguments and if passed will plot ontop of these. This can be used to make comolex or multipanel figures. For a comprehensive list of plotting functions see [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/list_of_plotting_fuctions.md).
diff --git a/docs/source/get-started/africa.md b/docs/source/get-started/africa.md
index 7008a16..697a5e6 100644
--- a/docs/source/get-started/africa.md
+++ b/docs/source/get-started/africa.md
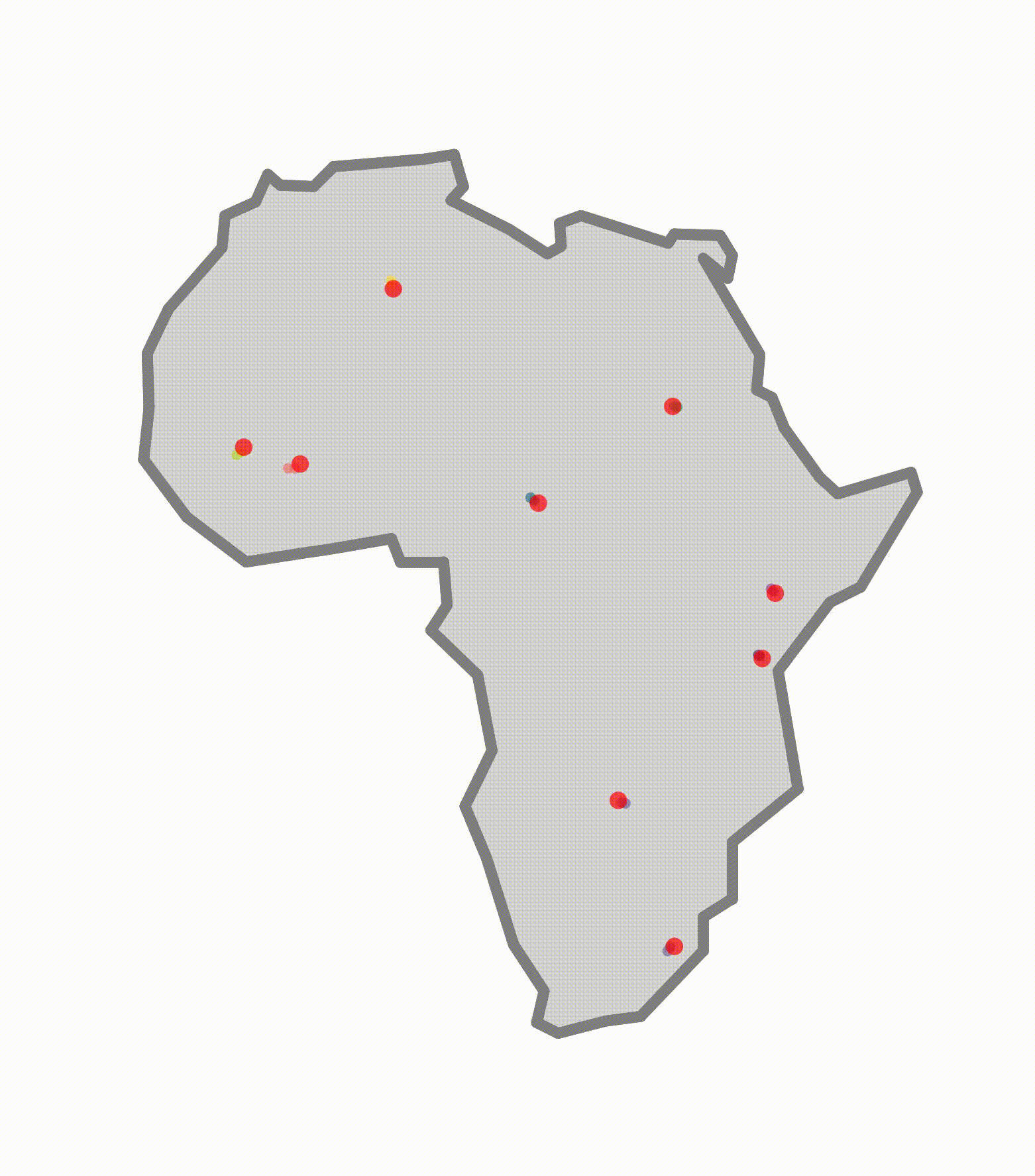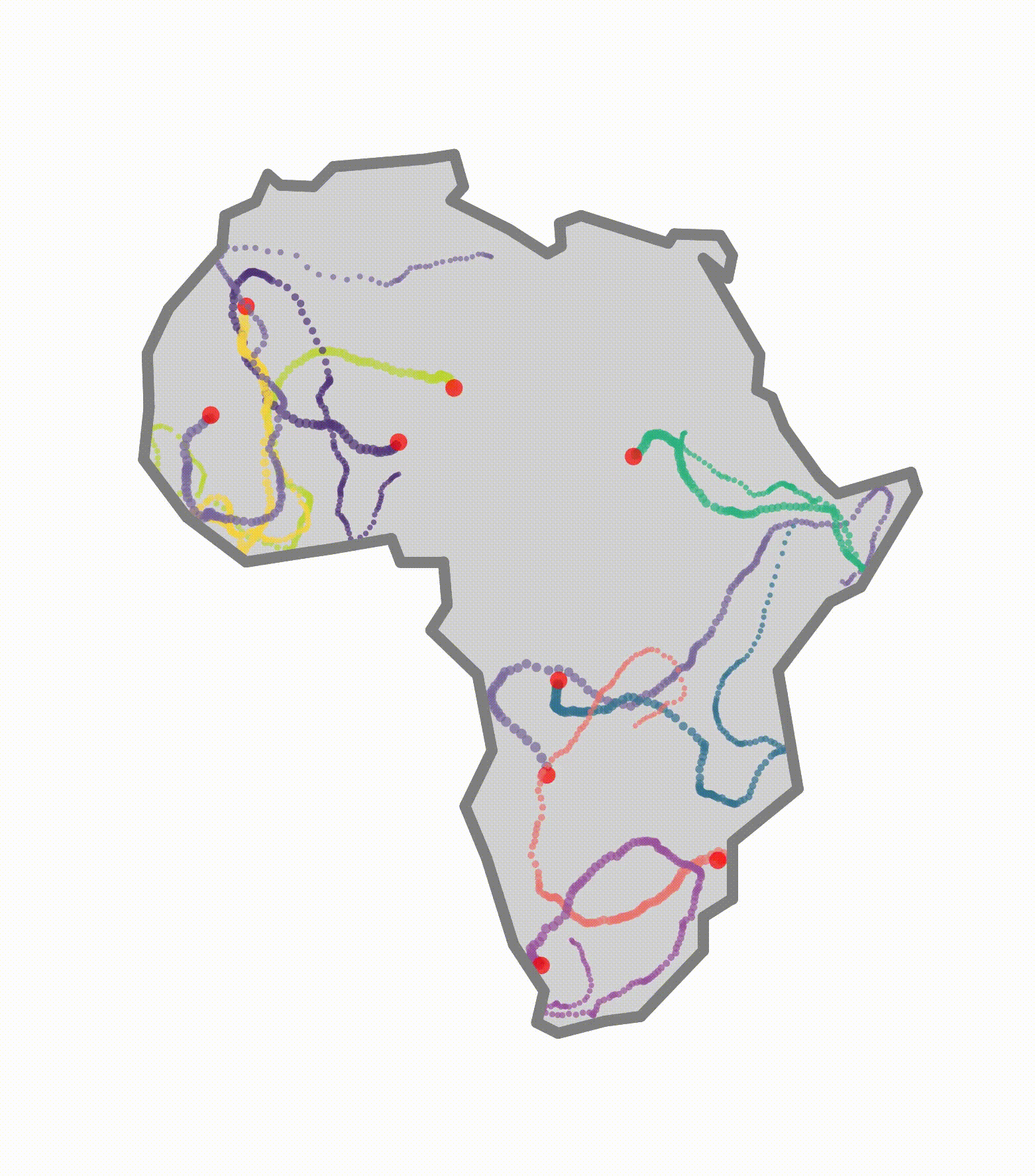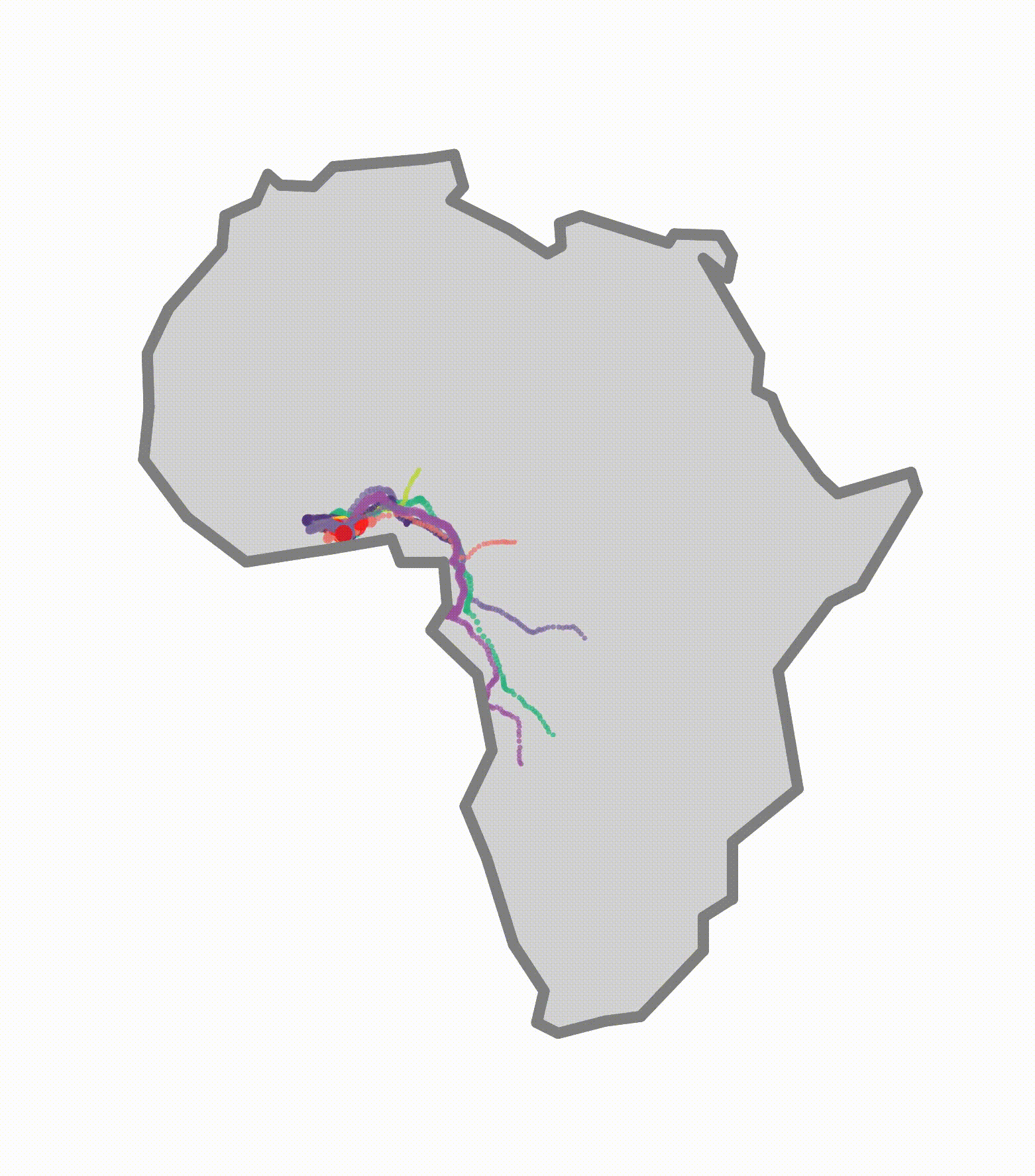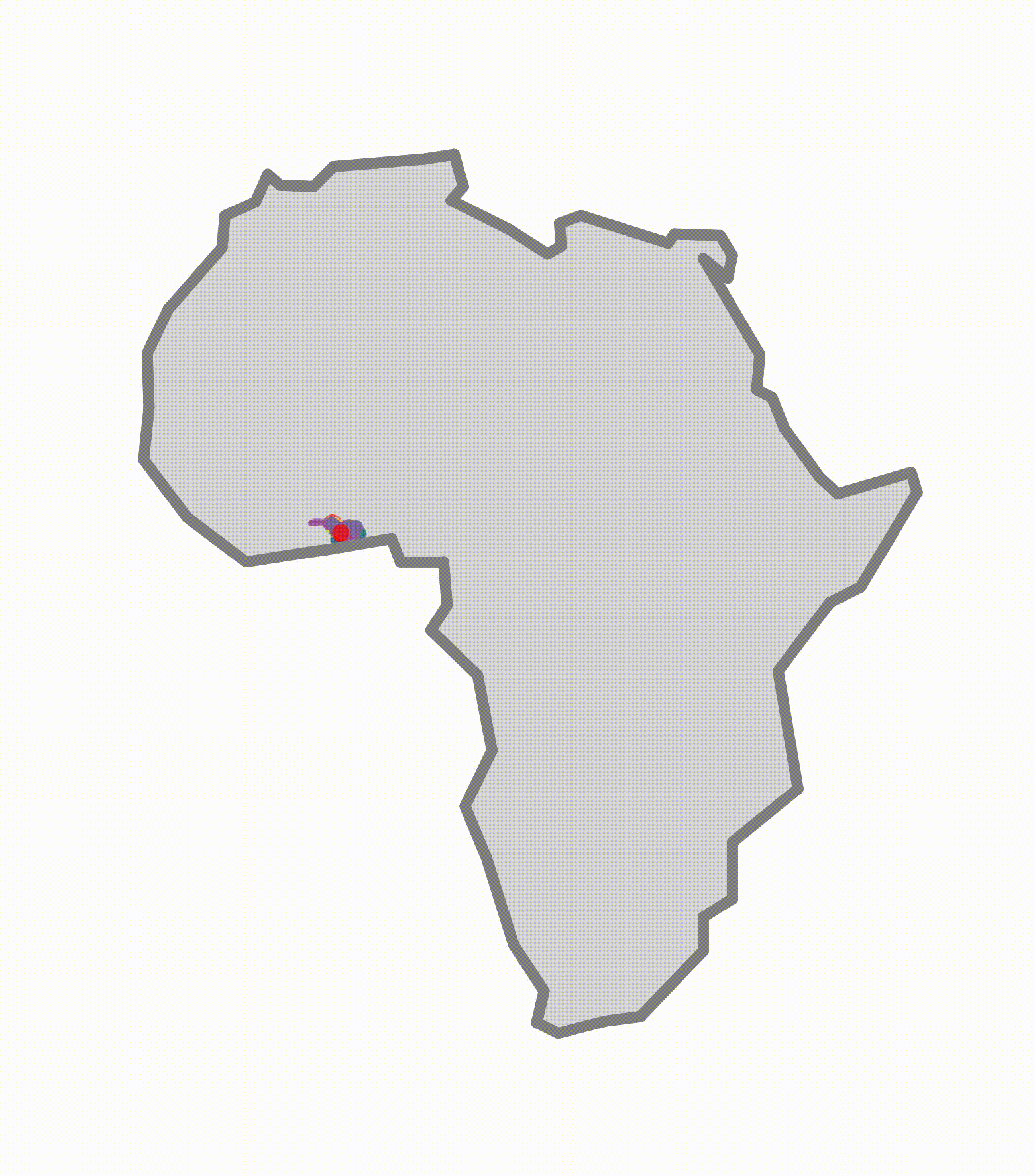
@@ -2,7 +2,7 @@
This animation was made by students on the [TReND in Africa computational neuroscience summer school](https://trendinafrica.org/computational-neuroscience-basics/). Code is provided below.
-
-Both of these classes can be used as the building block for constructing complex multilayer networks of `Neurons` (e.g. `FeedForwardLayers` are `RatInABox.Neurons` in their own right so can be used as inputs to other `FeedForwardLayers`). Their parameters can be accessed and set (or "trained") to create neurons with complex receptive fields. In the case of `DeepNeuralNetwork` neurons the firing rate attached to the computational graph is stored so gradients can be taken. Examples can be found [here (path integration)](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/path_integration_example.ipynb), [here (reinforcement learning)](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb), [here (successor features)](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/successor_features_example.ipynb) and [here (actor_critic_demo)](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/actor_critic_example.ipynb).
+Both of these classes can be used as the building block for constructing complex multilayer networks of `Neurons` (e.g. `FeedForwardLayers` are `RatInABox.Neurons` in their own right so can be used as inputs to other `FeedForwardLayers`). Their parameters can be accessed and set (or "trained") to create neurons with complex receptive fields. In the case of `DeepNeuralNetwork` neurons the firing rate attached to the computational graph is stored so gradients can be taken. Examples can be found [here (path integration)](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/path_integration_example.ipynb), [here (reinforcement learning)](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb), [here (successor features)](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/successor_features_example.ipynb) and [here (actor_critic_demo)](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/actor_critic_example.ipynb).
### **Creating your own `Neuron` types**
-We encourage users to create their own subclasses of `Neurons`. This is easy to do, see comments in the `Neurons` class within the [code](https://github.com/RatInABox-Lab/RatInABox/blob/dev/ratinabox/Neurons.py) for explanation. By forming these classes from the parent `Neurons` class, the plotting and analysis features described above remain available to these bespoke Neuron types.
+We encourage users to create their own subclasses of `Neurons`. This is easy to do, see comments in the `Neurons` class within the [code](https://github.com/RatInABox-Lab/RatInABox/blob/main/ratinabox/Neurons.py) for explanation. By forming these classes from the parent `Neurons` class, the plotting and analysis features described above remain available to these bespoke Neuron types.
## (iv) Figures and animations
`RatInABox` is built to be highly visual. It is easy to plot or animate data and save these plots/animations. Here are some tips
@@ -321,4 +321,4 @@ Neurons.plot_rate_timeseries() # plots activities of the neurons over time
Neurons.animate_rate_timeseries() # animates the activity of the neurons over time
```
-Most plotting functions accept `fig` and `ax` as optional arguments and if passed will plot ontop of these. This can be used to make comolex or multipanel figures. For a comprehensive list of plotting functions see [here](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/list_of_plotting_fuctions.md).
+Most plotting functions accept `fig` and `ax` as optional arguments and if passed will plot ontop of these. This can be used to make comolex or multipanel figures. For a comprehensive list of plotting functions see [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/list_of_plotting_fuctions.md).
diff --git a/docs/source/get-started/africa.md b/docs/source/get-started/africa.md
index 7008a16..697a5e6 100644
--- a/docs/source/get-started/africa.md
+++ b/docs/source/get-started/africa.md
@@ -2,7 +2,7 @@
This animation was made by students on the [TReND in Africa computational neuroscience summer school](https://trendinafrica.org/computational-neuroscience-basics/). Code is provided below.
- +
+ ```python
diff --git a/docs/source/get-started/examples.md b/docs/source/get-started/examples.md
index 8f70cb7..e8a86ef 100644
--- a/docs/source/get-started/examples.md
+++ b/docs/source/get-started/examples.md
@@ -1,6 +1,6 @@
# Example scripts
-In the folder called [demos](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/) we provide numerous script and demos which will help when learning `RatInABox`. In approximate order of complexity, these include:
-* [simple_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/simple_example.ipynb): a very simple tutorial for importing RiaB, initialising an Environment, Agent and some PlaceCells, running a brief simulation and outputting some data. Code copied here for convenience.
+In the folder called [demos](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/) we provide numerous script and demos which will help when learning `RatInABox`. In approximate order of complexity, these include:
+* [simple_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/simple_example.ipynb): a very simple tutorial for importing RiaB, initialising an Environment, Agent and some PlaceCells, running a brief simulation and outputting some data. Code copied here for convenience.
```python
import ratinabox #IMPORT
from ratinabox.Environment import Environment
@@ -20,13 +20,13 @@ print(PCs.history['firingrate'][:10])
fig, ax = Ag.plot_trajectory()
fig, ax = PCs.plot_rate_timeseries()
```
-* [extensive_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/extensive_example.ipynb): a more involved tutorial. More complex enivornment, more complex cell types and more complex plots are used.
-* [list_of_plotting_functions.md](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/list_of_plotting_fuctions.md): All the types of plots available for are listed and explained.
-* [readme_figures.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/readme_figures.ipynb): (Almost) all plots/animations shown in the root readme are produced from this script (plus some minor formatting done afterwards in powerpoint).
-* [paper_figures.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/paper_figures.ipynb): (Almost) all plots/animations shown in the paper are produced from this script (plus some major formatting done afterwards in powerpoint).
-* [decoding_position_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/decoding_position_example.ipynb): Postion is decoded from neural data generated with RatInABox. Place cells, grid cell and boundary vector cells are compared.
-* [splitter_cells_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/splitter_cells_example.ipynb): A simple simultaion demonstrating how `Splittre` cell data could be create in a figure-8 maze.
-* [reinforcement_learning_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb): RatInABox is use to construct, train and visualise a small two-layer network capable of model free reinforcement learning in order to find a reward hidden behind a wall.
-* [actor_critic_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/actor_critic_example.ipynb): RatInABox is use to implement the actor critic algorithm using deep neural networks.
-* [successor_features_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/successor_features_example.ipynb): RatInABox is use to learn and visualise successor features under random and biased motion policies.
-* [path_integration_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/path_integration_example.ipynb): RatInABox is use to construct, train and visualise a large multi-layer network capable of learning a "ring attractor" capable of path integrating a position estimate using only velocity inputs.
+* [extensive_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/extensive_example.ipynb): a more involved tutorial. More complex enivornment, more complex cell types and more complex plots are used.
+* [list_of_plotting_functions.md](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/list_of_plotting_fuctions.md): All the types of plots available for are listed and explained.
+* [readme_figures.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/readme_figures.ipynb): (Almost) all plots/animations shown in the root readme are produced from this script (plus some minor formatting done afterwards in powerpoint).
+* [paper_figures.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/paper_figures.ipynb): (Almost) all plots/animations shown in the paper are produced from this script (plus some major formatting done afterwards in powerpoint).
+* [decoding_position_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/decoding_position_example.ipynb): Postion is decoded from neural data generated with RatInABox. Place cells, grid cell and boundary vector cells are compared.
+* [splitter_cells_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/splitter_cells_example.ipynb): A simple simultaion demonstrating how `Splittre` cell data could be create in a figure-8 maze.
+* [reinforcement_learning_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb): RatInABox is use to construct, train and visualise a small two-layer network capable of model free reinforcement learning in order to find a reward hidden behind a wall.
+* [actor_critic_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/actor_critic_example.ipynb): RatInABox is use to implement the actor critic algorithm using deep neural networks.
+* [successor_features_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/successor_features_example.ipynb): RatInABox is use to learn and visualise successor features under random and biased motion policies.
+* [path_integration_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/path_integration_example.ipynb): RatInABox is use to construct, train and visualise a large multi-layer network capable of learning a "ring attractor" capable of path integrating a position estimate using only velocity inputs.
diff --git a/docs/source/get-started/from-scratch.md b/docs/source/get-started/from-scratch.md
index 738869f..f102be8 100644
--- a/docs/source/get-started/from-scratch.md
+++ b/docs/source/get-started/from-scratch.md
@@ -2,6 +2,6 @@
From zero to animated trajectories and boundary vector cell data in 60 seconds (incl. writing the code)
-
```python
diff --git a/docs/source/get-started/examples.md b/docs/source/get-started/examples.md
index 8f70cb7..e8a86ef 100644
--- a/docs/source/get-started/examples.md
+++ b/docs/source/get-started/examples.md
@@ -1,6 +1,6 @@
# Example scripts
-In the folder called [demos](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/) we provide numerous script and demos which will help when learning `RatInABox`. In approximate order of complexity, these include:
-* [simple_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/simple_example.ipynb): a very simple tutorial for importing RiaB, initialising an Environment, Agent and some PlaceCells, running a brief simulation and outputting some data. Code copied here for convenience.
+In the folder called [demos](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/) we provide numerous script and demos which will help when learning `RatInABox`. In approximate order of complexity, these include:
+* [simple_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/simple_example.ipynb): a very simple tutorial for importing RiaB, initialising an Environment, Agent and some PlaceCells, running a brief simulation and outputting some data. Code copied here for convenience.
```python
import ratinabox #IMPORT
from ratinabox.Environment import Environment
@@ -20,13 +20,13 @@ print(PCs.history['firingrate'][:10])
fig, ax = Ag.plot_trajectory()
fig, ax = PCs.plot_rate_timeseries()
```
-* [extensive_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/extensive_example.ipynb): a more involved tutorial. More complex enivornment, more complex cell types and more complex plots are used.
-* [list_of_plotting_functions.md](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/list_of_plotting_fuctions.md): All the types of plots available for are listed and explained.
-* [readme_figures.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/readme_figures.ipynb): (Almost) all plots/animations shown in the root readme are produced from this script (plus some minor formatting done afterwards in powerpoint).
-* [paper_figures.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/paper_figures.ipynb): (Almost) all plots/animations shown in the paper are produced from this script (plus some major formatting done afterwards in powerpoint).
-* [decoding_position_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/decoding_position_example.ipynb): Postion is decoded from neural data generated with RatInABox. Place cells, grid cell and boundary vector cells are compared.
-* [splitter_cells_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/splitter_cells_example.ipynb): A simple simultaion demonstrating how `Splittre` cell data could be create in a figure-8 maze.
-* [reinforcement_learning_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb): RatInABox is use to construct, train and visualise a small two-layer network capable of model free reinforcement learning in order to find a reward hidden behind a wall.
-* [actor_critic_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/actor_critic_example.ipynb): RatInABox is use to implement the actor critic algorithm using deep neural networks.
-* [successor_features_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/successor_features_example.ipynb): RatInABox is use to learn and visualise successor features under random and biased motion policies.
-* [path_integration_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/path_integration_example.ipynb): RatInABox is use to construct, train and visualise a large multi-layer network capable of learning a "ring attractor" capable of path integrating a position estimate using only velocity inputs.
+* [extensive_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/extensive_example.ipynb): a more involved tutorial. More complex enivornment, more complex cell types and more complex plots are used.
+* [list_of_plotting_functions.md](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/list_of_plotting_fuctions.md): All the types of plots available for are listed and explained.
+* [readme_figures.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/readme_figures.ipynb): (Almost) all plots/animations shown in the root readme are produced from this script (plus some minor formatting done afterwards in powerpoint).
+* [paper_figures.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/paper_figures.ipynb): (Almost) all plots/animations shown in the paper are produced from this script (plus some major formatting done afterwards in powerpoint).
+* [decoding_position_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/decoding_position_example.ipynb): Postion is decoded from neural data generated with RatInABox. Place cells, grid cell and boundary vector cells are compared.
+* [splitter_cells_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/splitter_cells_example.ipynb): A simple simultaion demonstrating how `Splittre` cell data could be create in a figure-8 maze.
+* [reinforcement_learning_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb): RatInABox is use to construct, train and visualise a small two-layer network capable of model free reinforcement learning in order to find a reward hidden behind a wall.
+* [actor_critic_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/actor_critic_example.ipynb): RatInABox is use to implement the actor critic algorithm using deep neural networks.
+* [successor_features_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/successor_features_example.ipynb): RatInABox is use to learn and visualise successor features under random and biased motion policies.
+* [path_integration_example.ipynb](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/path_integration_example.ipynb): RatInABox is use to construct, train and visualise a large multi-layer network capable of learning a "ring attractor" capable of path integrating a position estimate using only velocity inputs.
diff --git a/docs/source/get-started/from-scratch.md b/docs/source/get-started/from-scratch.md
index 738869f..f102be8 100644
--- a/docs/source/get-started/from-scratch.md
+++ b/docs/source/get-started/from-scratch.md
@@ -2,6 +2,6 @@
From zero to animated trajectories and boundary vector cell data in 60 seconds (incl. writing the code)
- +
+ diff --git a/docs/source/get-started/index.md b/docs/source/get-started/index.md
index d5a73ff..50576bb 100644
--- a/docs/source/get-started/index.md
+++ b/docs/source/get-started/index.md
@@ -1,5 +1,5 @@
# Get started
-Many [demos](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/) are provided. Reading through the [example scripts](./examples) (one simple and one extensive, duplicated at the bottom of the readme) these should be enough to get started. We also provide numerous interactive jupyter scripts as more in-depth case studies; for example one where `RatInABox` is used for [reinforcement learning](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb), another for [neural decoding](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/decoding_position_example.ipynb) of position from firing rate. Jupyter scripts reproducing all figures in the [paper](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/paper_figures.ipynb) and [readme](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/readme_figures.ipynb) are also provided. All [demos](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/) can be run on Google Colab [](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/)
+Many [demos](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/) are provided. Reading through the [example scripts](./examples) (one simple and one extensive, duplicated at the bottom of the readme) these should be enough to get started. We also provide numerous interactive jupyter scripts as more in-depth case studies; for example one where `RatInABox` is used for [reinforcement learning](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb), another for [neural decoding](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/decoding_position_example.ipynb) of position from firing rate. Jupyter scripts reproducing all figures in the [paper](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/paper_figures.ipynb) and [readme](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/readme_figures.ipynb) are also provided. All [demos](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/) can be run on Google Colab [](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/)
## Installing and Importing
**Requirements** are minimal (`python3`, `numpy`, `scipy` and `matplotlib`, listed in `setup.cfg`) and will be installed automatically.
diff --git a/docs/source/index.md b/docs/source/index.md
index 49fb15a..e3a2910 100644
--- a/docs/source/index.md
+++ b/docs/source/index.md
@@ -8,7 +8,7 @@ With `RatInABox` you can:
* **Generate artificial neuronal data** for various location- or velocity-selective cells found in the brain (e.g., but not limited to, Hippocampal cell types), or build your own more complex cell types.
* **Build and train complex multi-layer networks** of cells, powered by data generated with `RatInABox`.
-
diff --git a/docs/source/get-started/index.md b/docs/source/get-started/index.md
index d5a73ff..50576bb 100644
--- a/docs/source/get-started/index.md
+++ b/docs/source/get-started/index.md
@@ -1,5 +1,5 @@
# Get started
-Many [demos](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/) are provided. Reading through the [example scripts](./examples) (one simple and one extensive, duplicated at the bottom of the readme) these should be enough to get started. We also provide numerous interactive jupyter scripts as more in-depth case studies; for example one where `RatInABox` is used for [reinforcement learning](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/reinforcement_learning_example.ipynb), another for [neural decoding](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/decoding_position_example.ipynb) of position from firing rate. Jupyter scripts reproducing all figures in the [paper](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/paper_figures.ipynb) and [readme](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/readme_figures.ipynb) are also provided. All [demos](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/) can be run on Google Colab [](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/)
+Many [demos](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/) are provided. Reading through the [example scripts](./examples) (one simple and one extensive, duplicated at the bottom of the readme) these should be enough to get started. We also provide numerous interactive jupyter scripts as more in-depth case studies; for example one where `RatInABox` is used for [reinforcement learning](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/reinforcement_learning_example.ipynb), another for [neural decoding](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/decoding_position_example.ipynb) of position from firing rate. Jupyter scripts reproducing all figures in the [paper](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/paper_figures.ipynb) and [readme](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/readme_figures.ipynb) are also provided. All [demos](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/) can be run on Google Colab [](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/)
## Installing and Importing
**Requirements** are minimal (`python3`, `numpy`, `scipy` and `matplotlib`, listed in `setup.cfg`) and will be installed automatically.
diff --git a/docs/source/index.md b/docs/source/index.md
index 49fb15a..e3a2910 100644
--- a/docs/source/index.md
+++ b/docs/source/index.md
@@ -8,7 +8,7 @@ With `RatInABox` you can:
* **Generate artificial neuronal data** for various location- or velocity-selective cells found in the brain (e.g., but not limited to, Hippocampal cell types), or build your own more complex cell types.
* **Build and train complex multi-layer networks** of cells, powered by data generated with `RatInABox`.
- +
+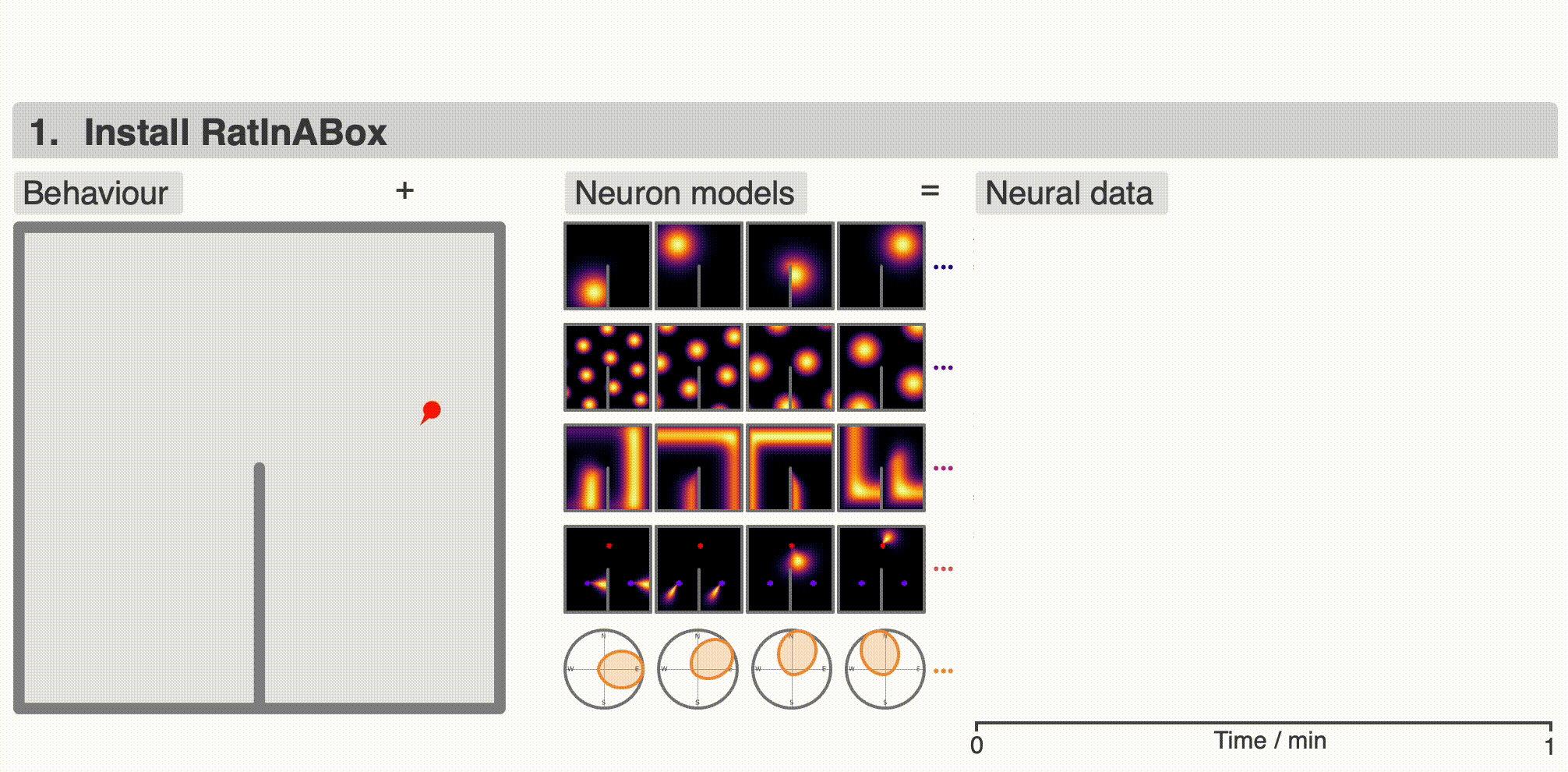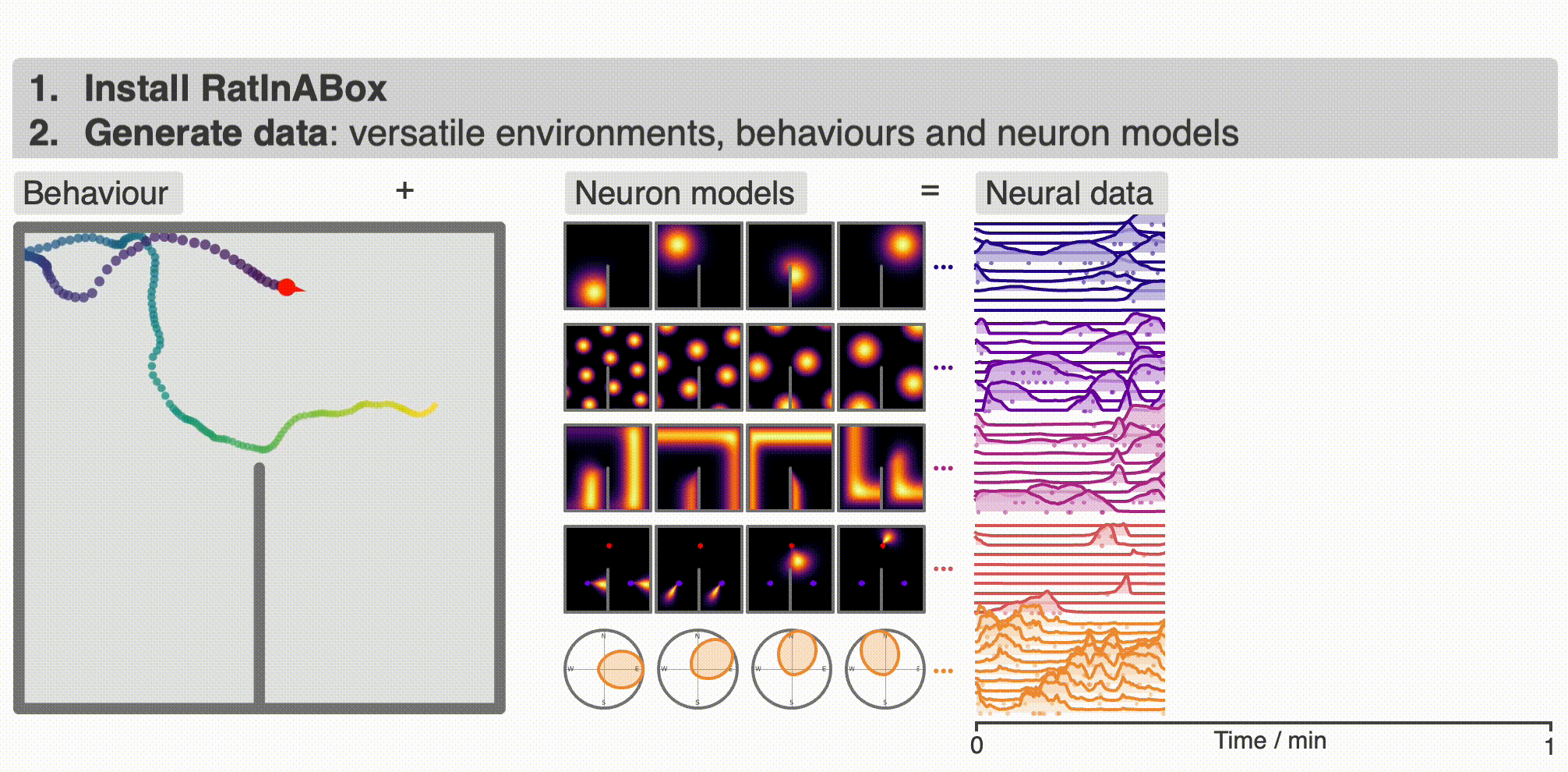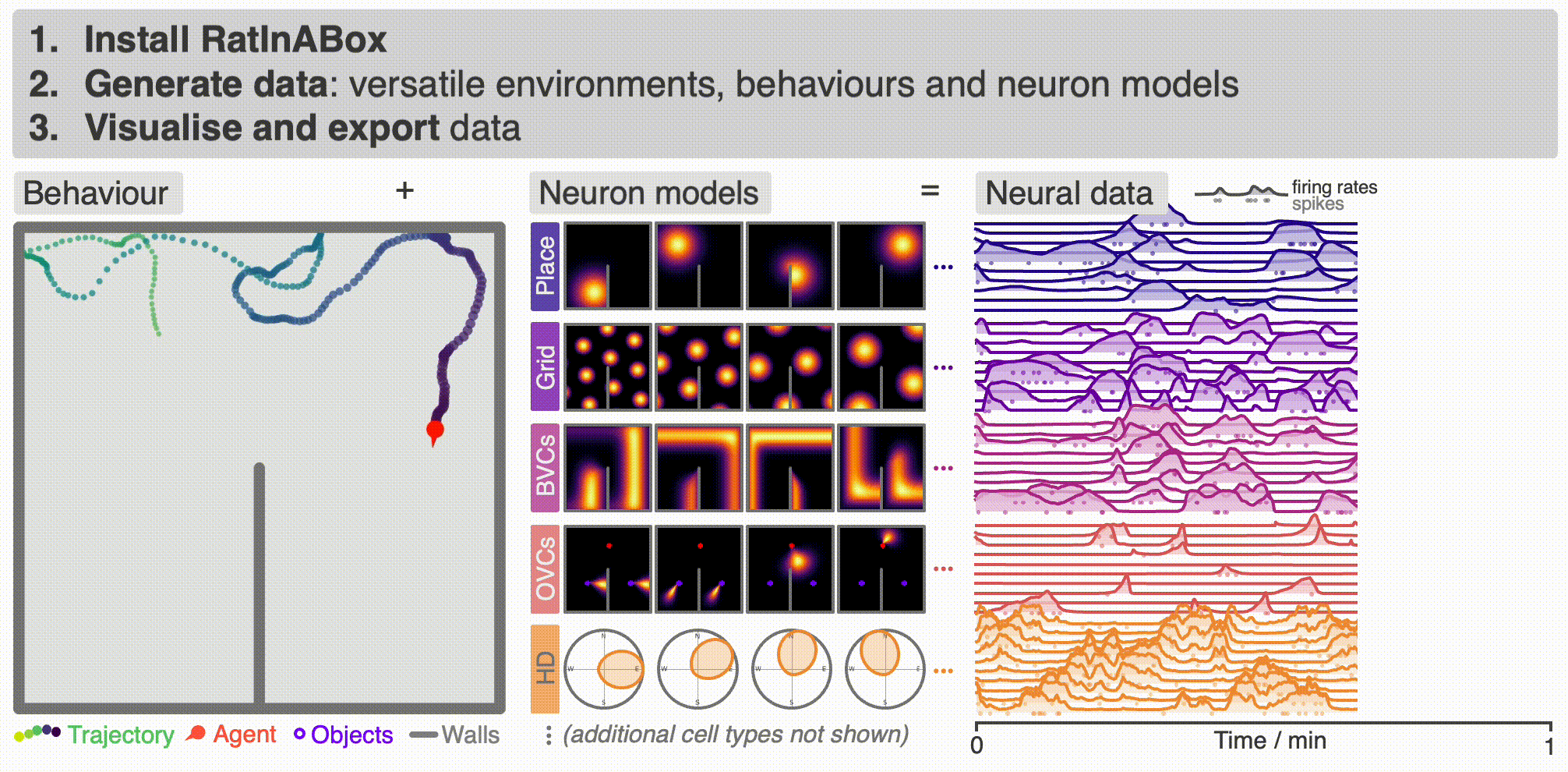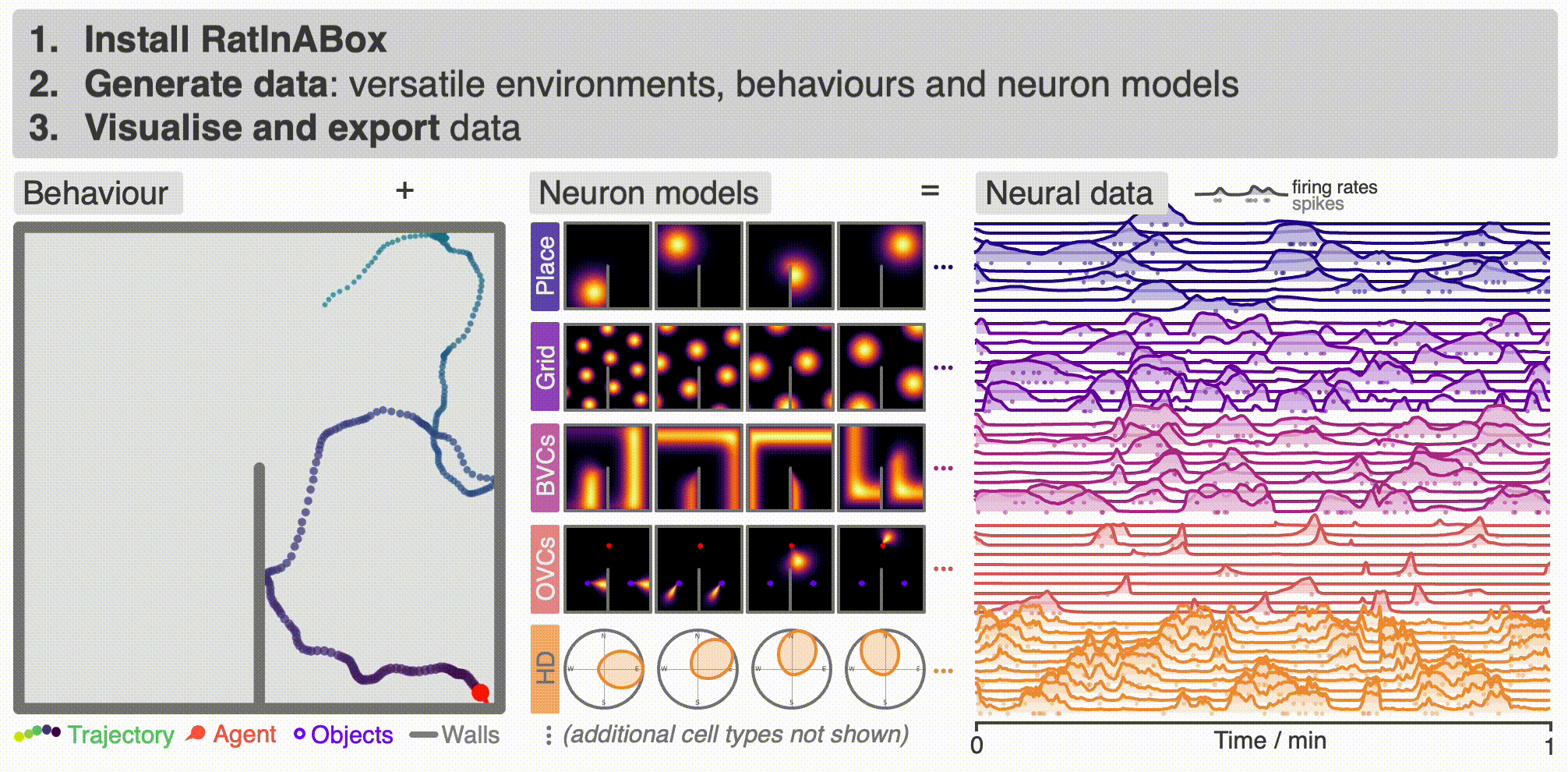 `RatInABox` is an open source project welcoming [contributions](#contribute). If you use `RatInABox` please [cite](#cite) the paper and consider giving this repository a star ☆. It contains three classes:
@@ -39,17 +39,17 @@ The top animation shows an example use case: an `Agent` randomly explores a 2D `
* **Fast**: Simulating 1 minute of exploration in a 2D environment with 100 place cells (dt=10 ms) take just 2 seconds on a laptop (no GPU needed).
* **Precise**: No more prediscretised positions, tabular state spaces, or jerky movement policies. It's all continuous.
* **Easy**: Sensible default parameters mean you can have realisitic simulation data to work with in <10 lines of code.
-* **Visual** Plot or animate trajectories, firing rate timeseries', spike rasters, receptive fields, heat maps, velocity histograms...using the plotting functions ([summarised here](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/list_of_plotting_fuctions.md)).
+* **Visual** Plot or animate trajectories, firing rate timeseries', spike rasters, receptive fields, heat maps, velocity histograms...using the plotting functions ([summarised here](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/list_of_plotting_fuctions.md)).
+## Announcement about support for OpenAI's `gymnasium`
`RatInABox` is an open source project welcoming [contributions](#contribute). If you use `RatInABox` please [cite](#cite) the paper and consider giving this repository a star ☆. It contains three classes:
@@ -39,17 +39,17 @@ The top animation shows an example use case: an `Agent` randomly explores a 2D `
* **Fast**: Simulating 1 minute of exploration in a 2D environment with 100 place cells (dt=10 ms) take just 2 seconds on a laptop (no GPU needed).
* **Precise**: No more prediscretised positions, tabular state spaces, or jerky movement policies. It's all continuous.
* **Easy**: Sensible default parameters mean you can have realisitic simulation data to work with in <10 lines of code.
-* **Visual** Plot or animate trajectories, firing rate timeseries', spike rasters, receptive fields, heat maps, velocity histograms...using the plotting functions ([summarised here](https://github.com/RatInABox-Lab/RatInABox/blob/dev/demos/list_of_plotting_fuctions.md)).
+* **Visual** Plot or animate trajectories, firing rate timeseries', spike rasters, receptive fields, heat maps, velocity histograms...using the plotting functions ([summarised here](https://github.com/RatInABox-Lab/RatInABox/blob/main/demos/list_of_plotting_fuctions.md)).
+## Announcement about support for OpenAI's `gymnasium`  API
+A new wrapper contributed by [@SynapticSage](https://github.com/SynapticSage) allows `RatInABox` to natively support OpenAI's [`gymnasium`](https://gymnasium.farama.org) API for standardised and multiagent reinforment learning. This can be used to flexibly integrate `RatInABox` with other RL libraries such as Stable-Baselines3 etc. and to build non-trivial tasks with objectives and time dependent rewards. Check it out [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/ratinabox/contribs/TaskEnv_example_files/TaskEnvironment_basics.md). -->
## Contribute
`RatInABox` is open source project and we actively encourage all contributions from example bug fixes to documentation or new cell types. Feel free to make a pull request (you will need to fork the repository first) or raise and issue.
-We have a dedicated [contribs](https://github.com/RatInABox-Lab/RatInABox/tree/dev/ratinabox/contribs) directory where you can safely add awesome scripts and new `Neurons` classes etc.
+We have a dedicated [contribs](https://github.com/RatInABox-Lab/RatInABox/tree/main/ratinabox/contribs) directory where you can safely add awesome scripts and new `Neurons` classes etc.
Questions? Just ask! Ideally via opening an issue so others can see the answer too.
API
+A new wrapper contributed by [@SynapticSage](https://github.com/SynapticSage) allows `RatInABox` to natively support OpenAI's [`gymnasium`](https://gymnasium.farama.org) API for standardised and multiagent reinforment learning. This can be used to flexibly integrate `RatInABox` with other RL libraries such as Stable-Baselines3 etc. and to build non-trivial tasks with objectives and time dependent rewards. Check it out [here](https://github.com/RatInABox-Lab/RatInABox/blob/main/ratinabox/contribs/TaskEnv_example_files/TaskEnvironment_basics.md). -->
## Contribute
`RatInABox` is open source project and we actively encourage all contributions from example bug fixes to documentation or new cell types. Feel free to make a pull request (you will need to fork the repository first) or raise and issue.
-We have a dedicated [contribs](https://github.com/RatInABox-Lab/RatInABox/tree/dev/ratinabox/contribs) directory where you can safely add awesome scripts and new `Neurons` classes etc.
+We have a dedicated [contribs](https://github.com/RatInABox-Lab/RatInABox/tree/main/ratinabox/contribs) directory where you can safely add awesome scripts and new `Neurons` classes etc.
Questions? Just ask! Ideally via opening an issue so others can see the answer too.