Should I use Paddle.io.DataLoader to prepare data for PaddleOCR #7009
-
|
Hey, I'm trying to utilize Paddle.io.DataLoader to run PaddleOCR on a large number of images stored on disk. The code looks like this: However the data return from dataloader is a tensor, while PaddleOCR requires input type to be Basically, I'm interested in knowing how to achieve the best efficiency during the inference stage. So far from the "quick_start" guide, we're feeding images to PaddleOCR one by one, is there any "batch inference" method? I also notice there is a "use_mp" option where we could utilize multi-processing to speed up the inference, however since we're using GPU to do inference, I guess "use_mp" won't be of help here. |
Beta Was this translation helpful? Give feedback.
Replies: 2 comments 7 replies
-
|
|
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the prompt reply!
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
I see, thanks!! |
Beta Was this translation helpful? Give feedback.
-
|
Hey @andyjpaddle I've tried out both the Dataloader as well as the multiprocessing to speed up inference, and it indeed gets a boost in speed. However, it comes with a new problem: I'm using either I was wondering what choices I have to tackle this problem. Resizing the images? Casting image datatype from I'm also surprised how much GPU memory it requires to just process one image. Sometimes on this error page, I can see it is asking for 10GB+. Is this normal given that we have three models (det + cls + rec)? |
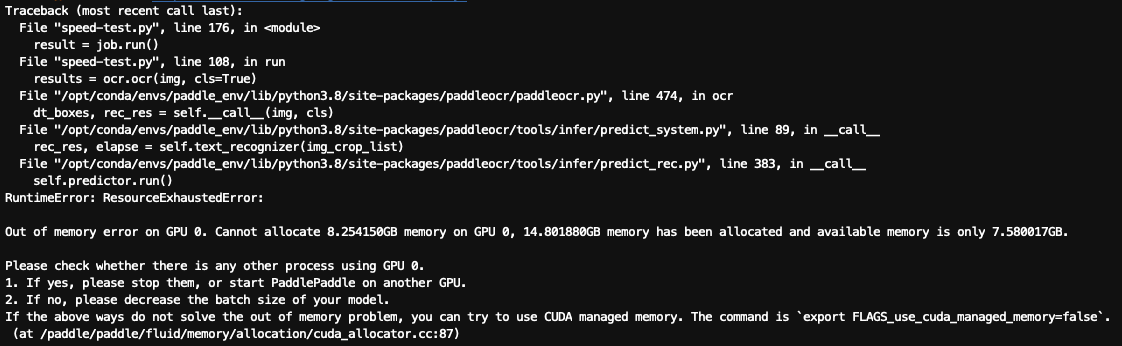
Beta Was this translation helpful? Give feedback.
-
|
It seems like it's not normal, maybe there is memory leak. You can test only one speed method once and see the GPU memory used. |
Beta Was this translation helpful? Give feedback.
-
|
@bdeng3 Do you manage to use both dataloader and use_mp to speed up the inference? Thanks in advance. |
Beta Was this translation helpful? Give feedback.
Paddle.io.DataLoaderdoesn't work.Since the input batch size must be 1 if
detis used, so if you want to speed the inference, you can useuse_mphttps://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/tools/infer/predict_system.py#L207, if you only use the
rec, you can setrec_batch_numto a big number in herehttps://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/tools/infer/utility.py#L86