diff --git a/.circleci/test.yml b/.circleci/test.yml
index 5498c3b20..7d08ccf3a 100644
--- a/.circleci/test.yml
+++ b/.circleci/test.yml
@@ -99,7 +99,7 @@ jobs:
type: string
cuda:
type: enum
- enum: ["10.1", "10.2", "11.1","11.0"]
+ enum: ["10.1", "10.2", "11.1", "11.0"]
cudnn:
type: integer
default: 7
@@ -151,8 +151,7 @@ workflows:
pr_stage_test:
when:
- not:
- << pipeline.parameters.lint_only >>
+ not: << pipeline.parameters.lint_only >>
jobs:
- lint:
name: lint
@@ -164,7 +163,7 @@ workflows:
name: minimum_version_cpu
torch: 1.8.0
torchvision: 0.9.0
- python: 3.8.0 # The lowest python 3.6.x version available on CircleCI images
+ python: 3.8.0 # The lowest python 3.7.x version available on CircleCI images
requires:
- lint
- build_cpu:
@@ -188,8 +187,7 @@ workflows:
- hold
merge_stage_test:
when:
- not:
- << pipeline.parameters.lint_only >>
+ not: << pipeline.parameters.lint_only >>
jobs:
- build_cuda:
name: minimum_version_gpu
diff --git a/README.md b/README.md
index 163985b57..e5e8af2c9 100644
--- a/README.md
+++ b/README.md
@@ -71,14 +71,32 @@ And the figure of P6 model is in [model_design.md](docs/en/algorithm_description
## What's New
-💎 **v0.2.0** was released on 1/12/2022:
+### Highlight
-1. Support [YOLOv7](https://github.com/open-mmlab/mmyolo/tree/dev/configs/yolov7) P5 and P6 model
-2. Support [YOLOv6](https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov6/README.md) ML model
-3. Support [Grad-Based CAM and Grad-Free CAM](https://github.com/open-mmlab/mmyolo/blob/dev/demo/boxam_vis_demo.py)
-4. Support [large image inference](https://github.com/open-mmlab/mmyolo/blob/dev/demo/large_image_demo.py) based on sahi
-5. Add [easydeploy](https://github.com/open-mmlab/mmyolo/blob/dev/projects/easydeploy/README.md) project under the projects folder
-6. Add [custom dataset guide](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/user_guides/custom_dataset.md)
+We are excited to announce our latest work on real-time object recognition tasks, **RTMDet**, a family of fully convolutional single-stage detectors. RTMDet not only achieves the best parameter-accuracy trade-off on object detection from tiny to extra-large model sizes but also obtains new state-of-the-art performance on instance segmentation and rotated object detection tasks. Details can be found in the [technical report](https://arxiv.org/abs/2212.07784). Pre-trained models are [here](configs/rtmdet).
+
+[](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-dota-1?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-hrsc2016?p=rtmdet-an-empirical-study-of-designing-real)
+
+| Task | Dataset | AP | FPS(TRT FP16 BS1 3090) |
+| ------------------------ | ------- | ------------------------------------ | ---------------------- |
+| Object Detection | COCO | 52.8 | 322 |
+| Instance Segmentation | COCO | 44.6 | 188 |
+| Rotated Object Detection | DOTA | 78.9(single-scale)/81.3(multi-scale) | 121 |
+
+
+

+
@@ -191,6 +211,8 @@ Results and models are available in the [model zoo](docs/en/model_zoo.md).
YOLOv6RepPAFPN
YOLOXPAFPN
CSPNeXtPAFPN
+ YOLOv7PAFPN
+ PPYOLOECSPPAFPN
|
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 430400714..3c0fa5add 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -71,25 +71,46 @@ P6 模型图详见 [model_design.md](docs/zh_CN/algorithm_descriptions/model_des
## 最新进展
-💎 **v0.2.0** 版本已经在 2022.12.1 发布:
+### 亮点
-1. 支持 [YOLOv7](https://github.com/open-mmlab/mmyolo/tree/dev/configs/yolov7) P5 和 P6 模型
-2. 支持 [YOLOv6](https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov6/README.md) 中的 ML 大模型
-3. 支持 [Grad-Based CAM 和 Grad-Free CAM](https://github.com/open-mmlab/mmyolo/blob/dev/demo/boxam_vis_demo.py)
-4. 基于 sahi 支持 [大图推理](https://github.com/open-mmlab/mmyolo/blob/dev/demo/large_image_demo.py)
-5. projects 文件夹下新增 [easydeploy](https://github.com/open-mmlab/mmyolo/blob/dev/projects/easydeploy/README.md) 项目
-6. 新增 [自定义数据集教程](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/user_guides/custom_dataset.md)
+我们很高兴向大家介绍我们在实时目标识别任务方面的最新成果 RTMDet,包含了一系列的全卷积单阶段检测模型。 RTMDet 不仅在从 tiny 到 extra-large 尺寸的目标检测模型上实现了最佳的参数量和精度的平衡,而且在实时实例分割和旋转目标检测任务上取得了最先进的成果。 更多细节请参阅[技术报告](https://arxiv.org/abs/2212.07784)。 预训练模型可以在[这里](configs/rtmdet)找到。
+
+[](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-dota-1?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-hrsc2016?p=rtmdet-an-empirical-study-of-designing-real)
+
+| Task | Dataset | AP | FPS(TRT FP16 BS1 3090) |
+| ------------------------ | ------- | ------------------------------------ | ---------------------- |
+| Object Detection | COCO | 52.8 | 322 |
+| Instance Segmentation | COCO | 44.6 | 188 |
+| Rotated Object Detection | DOTA | 78.9(single-scale)/81.3(multi-scale) | 121 |
+
+
+
+
[10分钟换遍主干网络.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[实用类第二期]10分钟换遍主干网络.ipynb) |
+| | 内容 | 视频 | 课程中的代码 |
+| :-: | :--------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| 🌟 | 特征图可视化 | [](https://www.bilibili.com/video/BV188411s7o8) [](https://www.bilibili.com/video/BV188411s7o8) | [特征图可视化.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/%5B%E5%B7%A5%E5%85%B7%E7%B1%BB%E7%AC%AC%E4%B8%80%E6%9C%9F%5D%E7%89%B9%E5%BE%81%E5%9B%BE%E5%8F%AF%E8%A7%86%E5%8C%96.ipynb) |
+| 🌟 | 特征图可视化 Demo | [](https://www.bilibili.com/video/BV1je4y1478R/) [](https://www.bilibili.com/video/BV1je4y1478R/) | |
+| 🌟 | 配置全解读 | [](https://www.bilibili.com/video/BV1214y157ck) [](https://www.bilibili.com/video/BV1214y157ck) | [配置全解读文档](https://zhuanlan.zhihu.com/p/577715188) |
+| 🌟 | 源码阅读和调试「必备」技巧 | [](https://www.bilibili.com/video/BV1N14y1V7mB) [](https://www.bilibili.com/video/BV1N14y1V7mB) | [源码阅读和调试「必备」技巧文档](https://zhuanlan.zhihu.com/p/580885852) |
+| 🌟 | 工程文件结构简析 | [](https://www.bilibili.com/video/BV1LP4y117jS)[](https://www.bilibili.com/video/BV1LP4y117jS) | [工程文件结构简析文档](https://zhuanlan.zhihu.com/p/584807195) |
+| 🌟 | 10分钟换遍主干网络 | [](https://www.bilibili.com/video/BV1JG4y1d7GC) [](https://www.bilibili.com/video/BV1JG4y1d7GC) | [10分钟换遍主干网络文档](https://zhuanlan.zhihu.com/p/585641598)
[10分钟换遍主干网络.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[实用类第二期]10分钟换遍主干网络.ipynb) |
+| 🌟 | 基于 sahi 的大图推理 | [](https://www.bilibili.com/video/BV1EK411R7Ws/) [](https://www.bilibili.com/video/BV1EK411R7Ws/) | [10分钟轻松掌握大图推理.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[工具类第二期]10分钟轻松掌握大图推理.ipynb) |
+| 🌟 | 自定义数据集从标注到部署保姆级教程 | [](https://www.bilibili.com/video/BV1RG4y137i5) [](https://www.bilibili.com/video/BV1JG4y1d7GC) | [自定义数据集从标注到部署保姆级教程](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/user_guides/custom_dataset.md) |
发布历史和更新细节请参考 [更新日志](https://mmyolo.readthedocs.io/zh_CN/latest/notes/changelog.html)
@@ -103,7 +124,7 @@ conda activate open-mmlab
pip install openmim
mim install "mmengine>=0.3.1"
mim install "mmcv>=2.0.0rc1,<2.1.0"
-mim install "mmdet>=3.0.0rc3,<3.1.0"
+mim install "mmdet>=3.0.0rc5,<3.1.0"
git clone https://github.com/open-mmlab/mmyolo.git
cd mmyolo
# Install albumentations
@@ -149,6 +170,7 @@ MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也
- 进阶指南
+ - [模块组合](docs/zh_cn/advanced_guides/module_combination.md)
- [数据流](docs/zh_cn/advanced_guides/data_flow.md)
- [How to](docs/zh_cn/advanced_guides/how_to.md)
- [插件](docs/zh_cn/advanced_guides/plugins.md)
@@ -167,7 +189,7 @@ MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也
- [x] [RTMDet](configs/rtmdet)
- [x] [YOLOv6](configs/yolov6)
- [x] [YOLOv7](configs/yolov7)
-- [ ] [PPYOLOE](configs/ppyoloe)(仅推理)
+- [x] [PPYOLOE](configs/ppyoloe)
@@ -198,6 +220,8 @@ MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也
YOLOXCSPDarknet
EfficientRep
CSPNeXt
+ YOLOv7Backbone
+ PPYOLOECSPResNet
|
@@ -206,6 +230,8 @@ MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也
YOLOv6RepPAFPN
YOLOXPAFPN
CSPNeXtPAFPN
+ YOLOv7PAFPN
+ PPYOLOECSPPAFPN
|
diff --git a/configs/ppyoloe/README.md b/configs/ppyoloe/README.md
new file mode 100644
index 000000000..a7b232275
--- /dev/null
+++ b/configs/ppyoloe/README.md
@@ -0,0 +1,38 @@
+# PPYOLOE
+
+
+
+## Abstract
+
+PP-YOLOE is an excellent single-stage anchor-free model based on PP-YOLOv2, surpassing a variety of popular YOLO models. PP-YOLOE has a series of models, named s/m/l/x, which are configured through width multiplier and depth multiplier. PP-YOLOE avoids using special operators, such as Deformable Convolution or Matrix NMS, to be deployed friendly on various hardware.
+
+
+ 
+  +
+
+ 
+RTMDet-l model structure
+
+ 
+YOLOv5-l-P5 model structure
+
+ 
+YOLOv5-l-P6 model structure
+  +
+
+ 
+YOLOv6-s model structure
+
+ 
+YOLOv6-l model structure
+
- 
-YOLOX_l model structure
+ 
+YOLOX-l model structure
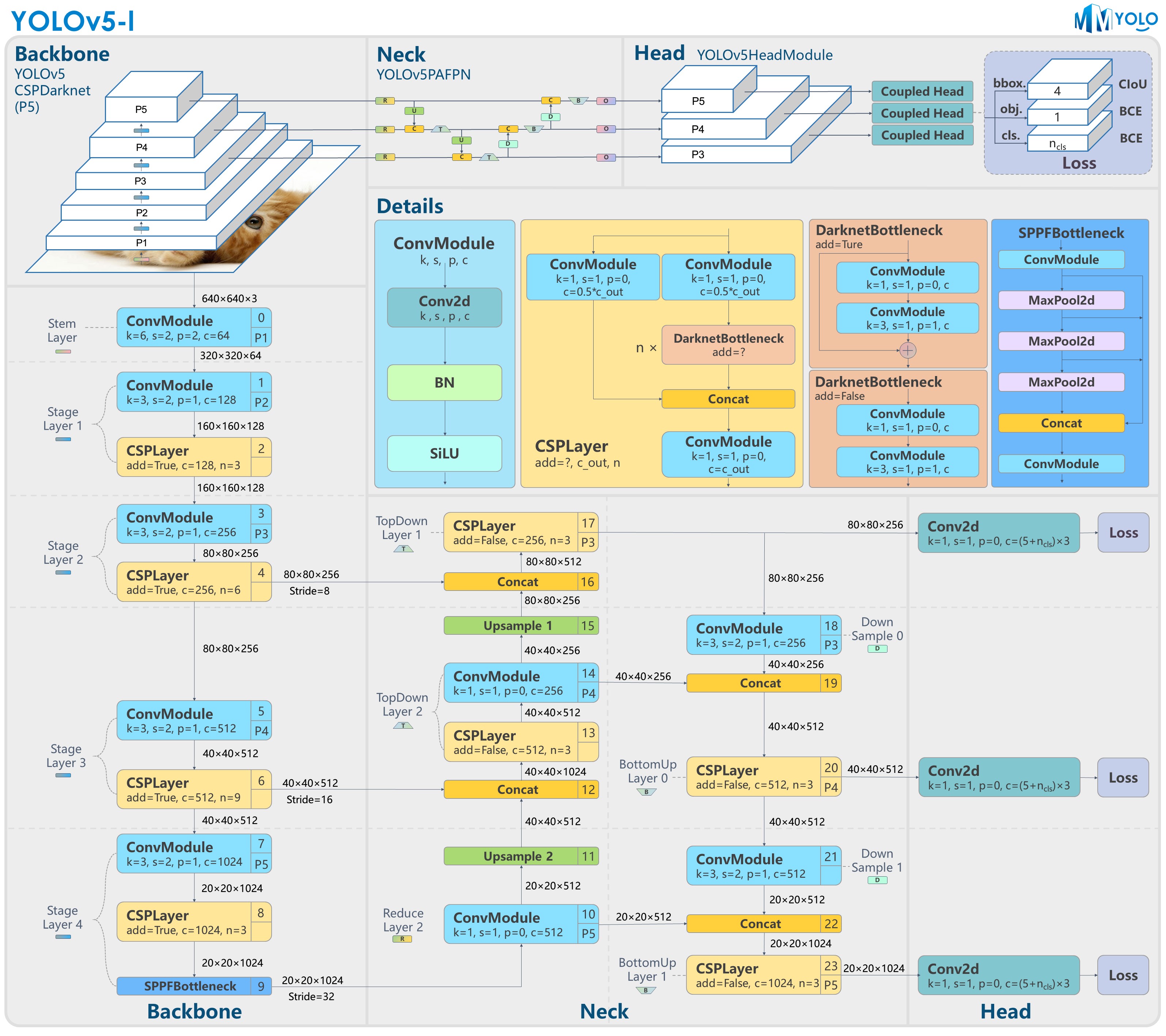
-Figure 1: YOLOv5-P5 model structure
+Figure 1: YOLOv5-l-P5 model structure
- 
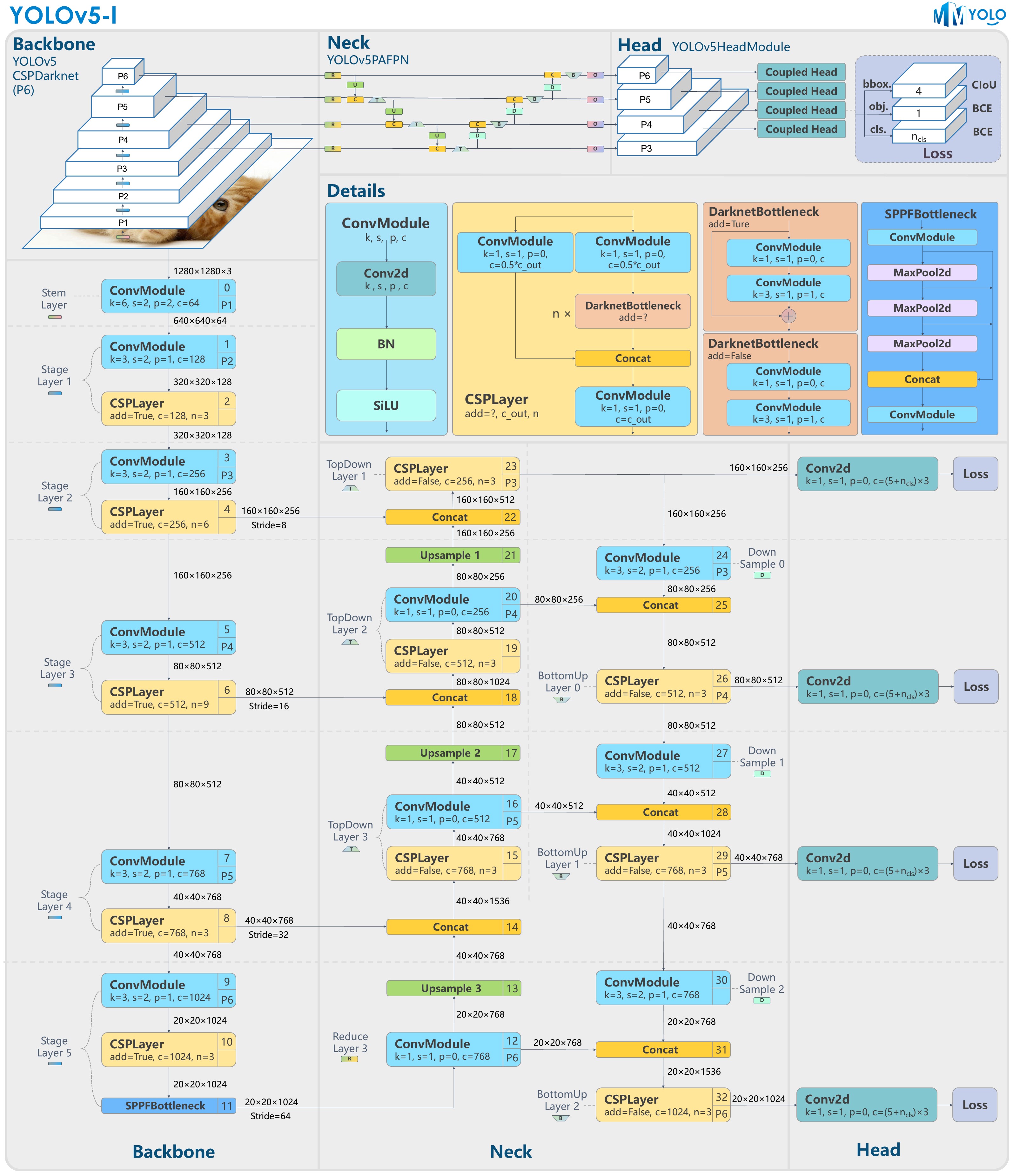
-Figure 2: YOLOv5-P6 model structure
+
+Figure 2: YOLOv5-l-P6 model structure
-图 1:YOLOv5-P5 模型结构
+图 1:YOLOv5-l-P5 模型结构
-
-图 2:YOLOv5-P6 模型结构
+
+图 2:YOLOv5-l-P6 模型结构
+
+图 1:YOLOv6-S 模型结构
+
+
+图 2:YOLOv6-L 模型结构
+  +
+在 N/T/S 模型中,YOLOv6 使用了 `EfficientRep` 作为骨干网络,其包含 1 个 `Stem Layer` 和 4 个 `Stage Layer`,具体细节如下:
+
+- `Stem Layer` 中采用 stride=2 的 `RepVGGBlock` 替换了 stride=2 的 6×6 `ConvModule`。
+- `Stage Layer` 结构与 YOLOv5 基本相似,将每个 `Stage layer` 的 1 个 `ConvModule` 和 1 个 `CSPLayer` 分别替换为 1 个 `RepVGGBlock` 和 1 个 `RepStageBlock`,如上图 Details 部分所示。其中,第一个 `RepVGGBlock` 会做下采样和 `Channel` 维度变换,而每个 `RepStageBlock` 则由 n 个 `RepVGGBlock` 组成。此外,仍然在第 4 个 `Stage Layer` 最后增加 `SPPF` 模块后输出。
+
+在 M/L 模型中,由于模型容量进一步增大,直接使用多个 `RepVGGBlock` 堆叠的 `RepStageBlock` 结构计算量和参数量呈现指数增长。因此,为了权衡计算负担和模型精度,在 M/L 模型中使用了 `CSPBep` 骨干网络,其采用 `BepC3StageBlock` 替换了小模型中的 `RepStageBlock` 。如下图所示,`BepC3StageBlock` 由 3 个 1×1 的 `ConvModule` 和多个子块(每个子块由两个 `RepVGGBlock` 残差连接)组成。
+
+
+
+在 N/T/S 模型中,YOLOv6 使用了 `EfficientRep` 作为骨干网络,其包含 1 个 `Stem Layer` 和 4 个 `Stage Layer`,具体细节如下:
+
+- `Stem Layer` 中采用 stride=2 的 `RepVGGBlock` 替换了 stride=2 的 6×6 `ConvModule`。
+- `Stage Layer` 结构与 YOLOv5 基本相似,将每个 `Stage layer` 的 1 个 `ConvModule` 和 1 个 `CSPLayer` 分别替换为 1 个 `RepVGGBlock` 和 1 个 `RepStageBlock`,如上图 Details 部分所示。其中,第一个 `RepVGGBlock` 会做下采样和 `Channel` 维度变换,而每个 `RepStageBlock` 则由 n 个 `RepVGGBlock` 组成。此外,仍然在第 4 个 `Stage Layer` 最后增加 `SPPF` 模块后输出。
+
+在 M/L 模型中,由于模型容量进一步增大,直接使用多个 `RepVGGBlock` 堆叠的 `RepStageBlock` 结构计算量和参数量呈现指数增长。因此,为了权衡计算负担和模型精度,在 M/L 模型中使用了 `CSPBep` 骨干网络,其采用 `BepC3StageBlock` 替换了小模型中的 `RepStageBlock` 。如下图所示,`BepC3StageBlock` 由 3 个 1×1 的 `ConvModule` 和多个子块(每个子块由两个 `RepVGGBlock` 残差连接)组成。
+
+ +
#### 1.2.2 Neck
+Neck 部分结构仍然在 YOLOv5 基础上进行了模块的改动,同样采用 `RepStageBlock` 或 `BepC3StageBlock` 对原本的 `CSPLayer` 进行了替换,需要注意的是,Neck 中 `Down Sample` 部分仍然使用了 stride=2 的 3×3 `ConvModule`,而不是像 Backbone 一样替换为 `RepVGGBlock`。
+
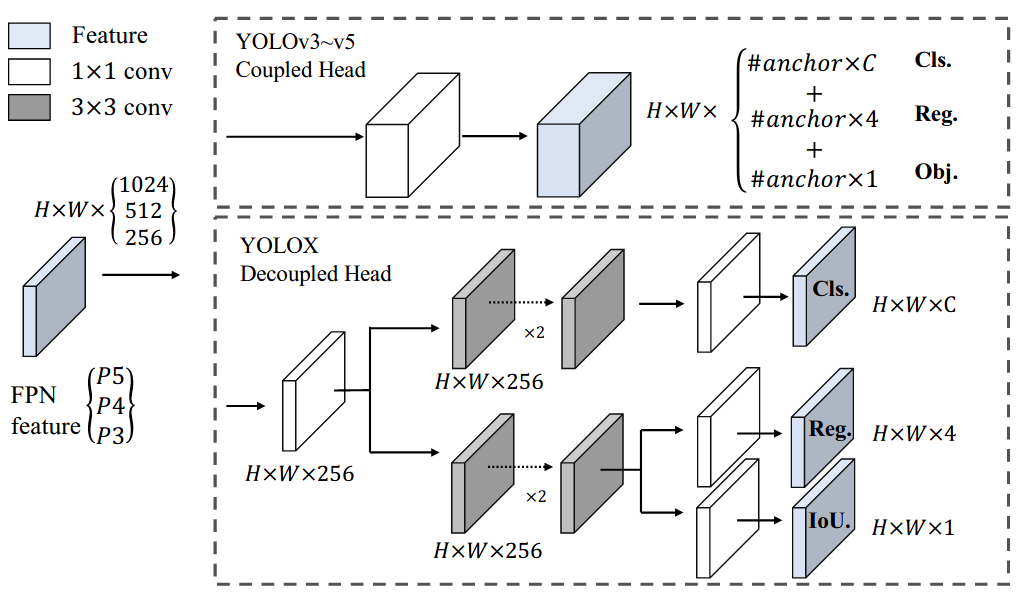
#### 1.2.3 Head
+不同于传统的 YOLO 系列检测头,YOLOv6 参考了 FCOS 和 YOLOX 中的做法,将分类和回归分支解耦成两个分支进行预测并且去掉了 obj 分支。同时,采用了 hybrid-channel 策略构建了更高效的解耦检测头,将中间 3×3 的 `ConvModule` 减少为 1 个,在维持精度的同时进一步减少了模型耗费,降低了推理延时。此外,需要说明的是,YOLOv6 在 Backobone 和 Neck 部分使用的激活函数是 `ReLU`,而在 Head 部分则使用的是 `SiLU`。
+
+由于 YOLOv6 是解耦输出,分类和 bbox 检测通过不同卷积完成。以 COCO 80 类为例:
+
+- P5 模型在输入为 640x640 分辨率情况下,其 Head 模块输出的 shape 分别为 `(B,4,80,80)`, `(B,80,80,80)`, `(B,4,40,40)`, `(B,80,40,40)`, `(B,4,20,20)`, `(B,80,20,20)`。
+
### 1.3 正负样本匹配策略
YOLOv6 采用的标签匹配策略与 [TOOD](https://arxiv.org/abs/2108.07755)
diff --git a/docs/zh_cn/article.md b/docs/zh_cn/article.md
index 6c999e5cd..706f11d0e 100644
--- a/docs/zh_cn/article.md
+++ b/docs/zh_cn/article.md
@@ -7,18 +7,14 @@
### 文章
- [社区协作,简洁易用,快来开箱新一代 YOLO 系列开源库](https://zhuanlan.zhihu.com/p/575615805)
-
- [MMYOLO 社区倾情贡献,RTMDet 原理社区开发者解读来啦!](https://zhuanlan.zhihu.com/p/569777684)
-
- [玩转 MMYOLO 基础类第一期: 配置文件太复杂?继承用法看不懂?配置全解读来了](https://zhuanlan.zhihu.com/p/577715188)
-
- [玩转 MMYOLO 工具类第一期: 特征图可视化](https://zhuanlan.zhihu.com/p/578141381?)
-
- [玩转 MMYOLO 实用类第二期:源码阅读和调试「必备」技巧文档](https://zhuanlan.zhihu.com/p/580885852)
-
- [玩转 MMYOLO 基础类第二期:工程文件结构简析](https://zhuanlan.zhihu.com/p/584807195)
-
- [玩转 MMYOLO 实用类第二期:10分钟换遍主干网络文档](https://zhuanlan.zhihu.com/p/585641598)
+- [MMYOLO 自定义数据集从标注到部署保姆级教程](https://zhuanlan.zhihu.com/p/595497726)
+- [满足一切需求的 MMYOLO 可视化:测试过程可视化](https://zhuanlan.zhihu.com/p/593179372)
### 视频
diff --git a/docs/zh_cn/get_started.md b/docs/zh_cn/get_started.md
index c1371f379..880942c36 100644
--- a/docs/zh_cn/get_started.md
+++ b/docs/zh_cn/get_started.md
@@ -6,7 +6,8 @@
| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
| :------------: | :----------------------: | :----------------------: | :---------------------: |
-| main | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| main | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
@@ -15,7 +16,7 @@
本节中,我们将演示如何用 PyTorch 准备一个环境。
-MMYOLO 支持在 Linux,Windows 和 macOS 上运行。它需要 Python 3.6 以上,CUDA 9.2 以上和 PyTorch 1.7 以上。
+MMYOLO 支持在 Linux,Windows 和 macOS 上运行。它需要 Python 3.7 以上,CUDA 9.2 以上和 PyTorch 1.7 以上。
```{note}
如果你对 PyTorch 有经验并且已经安装了它,你可以直接跳转到[下一小节](#安装流程)。否则,你可以按照下述步骤进行准备
@@ -54,7 +55,7 @@ conda install pytorch torchvision cpuonly -c pytorch
pip install -U openmim
mim install "mmengine>=0.3.1"
mim install "mmcv>=2.0.0rc1,<2.1.0"
-mim install "mmdet>=3.0.0rc3,<3.1.0"
+mim install "mmdet>=3.0.0rc5,<3.1.0"
```
**注意:**
@@ -144,7 +145,7 @@ inference_detector(model, 'demo/demo.jpg')
- 对于 Ampere 架构的 NVIDIA GPU,例如 GeForce 30 系列 以及 NVIDIA A100,CUDA 11 是必需的。
- 对于更早的 NVIDIA GPU,CUDA 11 是向后兼容 (backward compatible) 的,但 CUDA 10.2 能够提供更好的兼容性,也更加轻量。
-请确保你的 GPU 驱动版本满足最低的版本需求,参阅 NVIDIA 官方的 [CUDA工具箱和相应的驱动版本关系表](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)。
+请确保你的 GPU 驱动版本满足最低的版本需求,参阅 NVIDIA 官方的 [CUDA 工具箱和相应的驱动版本关系表](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)。
```{note}
如果按照我们的最佳实践进行安装,CUDA 运行时库就足够了,因为我们提供相关 CUDA 代码的预编译,不需要进行本地编译。
@@ -214,7 +215,7 @@ pip install "mmcv>=2.0.0rc1" -f https://download.openmmlab.com/mmcv/dist/cu116/t
!pip3 install openmim
!mim install "mmengine==0.1.0"
!mim install "mmcv>=2.0.0rc1,<2.1.0"
-!mim install "mmdet>=3.0.0.rc1"
+!mim install "mmdet>=3.0.0rc5,<3.1.0"
```
**步骤 2.** 使用源码安装 MMYOLO:
@@ -239,7 +240,7 @@ print(mmyolo.__version__)
#### 通过 Docker 使用 MMYOLO
-我们提供了一个 [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/master/docker/Dockerfile) 来构建一个镜像。请确保你的 [docker版本](https://docs.docker.com/engine/install/) >=`19.03`。
+我们提供了一个 [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/master/docker/Dockerfile) 来构建一个镜像。请确保你的 [docker 版本](https://docs.docker.com/engine/install/) >=`19.03`。
温馨提示;国内用户建议取消掉 [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/master/docker/Dockerfile#L19-L20) 里面 `Optional` 后两行的注释,可以获得火箭一般的下载提速:
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index 15bcae2a2..5ce41a6b7 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -57,6 +57,7 @@
notes/faq.md
notes/changelog.md
notes/compatibility.md
+ notes/conventions.md
.. toctree::
:maxdepth: 2
diff --git a/docs/zh_cn/notes/changelog.md b/docs/zh_cn/notes/changelog.md
index ac5df1dc2..7f5a9b3d8 100644
--- a/docs/zh_cn/notes/changelog.md
+++ b/docs/zh_cn/notes/changelog.md
@@ -1,5 +1,72 @@
# 更新日志
+## v0.3.0 (8/1/2023)
+
+### 亮点
+
+1. 实现了 [RTMDet](https://github.com/open-mmlab/mmyolo/blob/dev/configs/rtmdet/README.md) 的快速版本。RTMDet-s 8xA100 训练只需要 14 个小时,训练速度相比原先版本提升 2.6 倍。
+2. 支持 [PPYOLOE](https://github.com/open-mmlab/mmyolo/blob/dev/configs/ppyoloe/README.md) 训练。
+3. 支持 [YOLOv5](https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov5/crowdhuman/yolov5_s-v61_8xb16-300e_ignore_crowdhuman.py) 的 `iscrowd` 属性训练。
+4. 支持 [YOLOv5 正样本分配结果可视化](https://github.com/open-mmlab/mmyolo/blob/dev/projects/assigner_visualization/README.md)
+5. 新增 [YOLOv6 原理和实现全解析文档](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/algorithm_descriptions/yolov6_description.md)
+
+### 新特性
+
+01. 新增 `crowdhuman` 数据集 (#368)
+02. EasyDeploy 中支持 TensorRT 推理 (#377)
+03. 新增 `YOLOX` 结构图描述 (#402)
+04. 新增视频推理脚本 (#392)
+05. EasyDeploy 中支持 `YOLOv7` 部署 (#427)
+06. 支持从 CLI 中的特定检查点恢复训练 (#393)
+07. 将元信息字段设置为小写(#362、#412)
+08. 新增模块组合文档 (#349, #352, #345)
+09. 新增关于如何冻结 backbone 或 neck 权重的文档 (#418)
+10. 在 `how_to.md` 中添加不使用预训练权重的文档 (#404)
+11. 新增关于如何设置随机种子的文档 (#386)
+12. 将 `rtmdet_description.md` 文档翻译成英文 (#353)
+
+### Bug 修复
+
+01. 修复设置 `--class-id-txt` 时输出注释文件中的错误 (#430)
+02. 修复 `YOLOv5` head 中的批量推理错误 (#413)
+03. 修复某些 head 的类型提示(#415、#416、#443)
+04. 修复 expected a non-empty list of Tensors 错误 (#376)
+05. 修复 `YOLOv7` 训练中的设备不一致错误(#397)
+06. 修复 `LetterResize` 中的 `scale_factor` 和 `pad_param` 值 (#387)
+07. 修复 readthedocs 的 docstring 图形渲染错误 (#400)
+08. 修复 `YOLOv6` 从训练到验证时的断言错误 (#378)
+09. 修复 `np.int` 和旧版 builder.py 导致的 CI 错误 (#389)
+10. 修复 MMDeploy 重写器 (#366)
+11. 修复 MMYOLO 单元测试错误 (#351)
+12. 修复 `pad_param` 错误 (#354)
+13. 修复 head 推理两次的错误(#342)
+14. 修复自定义数据集训练 (#428)
+
+### 完善
+
+01. 更新 `useful_tools.md` (#384)
+02. 更新英文版 `custom_dataset.md` (#381)
+03. 重写函数删除上下文参数 (#395)
+04. 弃用 `np.bool` 类型别名 (#396)
+05. 为自定义数据集添加新的视频链接 (#365)
+06. 仅为模型导出 onnx (#361)
+07. 添加 MMYOLO 回归测试 yml (#359)
+08. 更新 `article.md` 中的视频教程 (#350)
+09. 添加部署 demo (#343)
+10. 优化 debug 模式下大图的可视化效果(#346)
+11. 改进 `browse_dataset` 的参数并支持 `RepeatDataset` (#340, #338)
+
+### 视频
+
+1. 发布了 [基于 sahi 的大图推理](https://www.bilibili.com/video/BV1EK411R7Ws/)
+2. 发布了 [自定义数据集从标注到部署保姆级教程](https://www.bilibili.com/video/BV1RG4y137i5)
+
+### 贡献者
+
+总共 28 位开发者参与了本次版本
+
+谢谢 @RangeKing, @PeterH0323, @Nioolek, @triple-Mu, @matrixgame2018, @xin-li-67, @tang576225574, @kitecats, @Seperendity, @diplomatist, @vaew, @wzr-skn, @VoyagerXvoyagerx, @MambaWong, @tianleiSHI, @caj-github, @zhubochao, @lvhan028, @dsghaonan, @lyviva, @yuewangg, @wang-tf, @satuoqaq, @grimoire, @RunningLeon, @hanrui1sensetime, @RangiLyu, @hhaAndroid
+
## v0.2.0(1/12/2022)
### 亮点
diff --git a/docs/zh_cn/notes/compatibility.md b/docs/zh_cn/notes/compatibility.md
index a3ad54d2d..a92521efc 100644
--- a/docs/zh_cn/notes/compatibility.md
+++ b/docs/zh_cn/notes/compatibility.md
@@ -2,6 +2,8 @@
## MMYOLO v0.3.0
+### METAINFO 修改
+
为了和 OpenMMLab 其他仓库统一,将 Dataset 里 `METAINFO` 的所有键从大写改为小写。
| 在 v0.3.0 之前 | v0.3.0 及之后 |
@@ -9,3 +11,37 @@
| CLASSES | classes |
| PALETTE | palette |
| DATASET_TYPE | dataset_type |
+
+### 关于图片 shape 顺序的说明
+
+在 OpenMMLab 2.0 中, 为了与 OpenCV 的输入参数相一致,图片处理 pipeline 中关于图像 shape 的输入参数总是以 `(width, height)` 的顺序排列。
+相反,为了计算方便,经过 pipeline 和 model 的字段的顺序是 `(height, width)`。具体来说在每个数据 pipeline 处理的结果中,字段和它们的值含义如下:
+
+- img_shape: (height, width)
+- ori_shape: (height, width)
+- pad_shape: (height, width)
+- batch_input_shape: (height, width)
+
+以 `Mosaic` 为例,其初始化参数如下所示:
+
+```python
+@TRANSFORMS.register_module()
+class Mosaic(BaseTransform):
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ center_ratio_range: Tuple[float, float] = (0.5, 1.5),
+ bbox_clip_border: bool = True,
+ pad_val: float = 114.0,
+ prob: float = 1.0) -> None:
+ ...
+
+ # img_scale 顺序应该是 (width, height)
+ self.img_scale = img_scale
+
+ def transform(self, results: dict) -> dict:
+ ...
+
+ results['img'] = mosaic_img
+ # (height, width)
+ results['img_shape'] = mosaic_img.shape[:2]
+```
diff --git a/docs/zh_cn/notes/conventions.md b/docs/zh_cn/notes/conventions.md
new file mode 100644
index 000000000..7c2370ffb
--- /dev/null
+++ b/docs/zh_cn/notes/conventions.md
@@ -0,0 +1,37 @@
+# 默认约定
+
+如果你想把 MMYOLO 修改为自己的项目,请遵循下面的约定。
+
+## 关于图片 shape 顺序的说明
+
+在OpenMMLab 2.0中, 为了与 OpenCV 的输入参数相一致,图片处理 pipeline 中关于图像 shape 的输入参数总是以 `(width, height)` 的顺序排列。
+相反,为了计算方便,经过 pipeline 和 model 的字段的顺序是 `(height, width)`。具体来说在每个数据 pipeline 处理的结果中,字段和它们的值含义如下:
+
+- img_shape: (height, width)
+- ori_shape: (height, width)
+- pad_shape: (height, width)
+- batch_input_shape: (height, width)
+
+以 `Mosaic` 为例,其初始化参数如下所示:
+
+```python
+@TRANSFORMS.register_module()
+class Mosaic(BaseTransform):
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ center_ratio_range: Tuple[float, float] = (0.5, 1.5),
+ bbox_clip_border: bool = True,
+ pad_val: float = 114.0,
+ prob: float = 1.0) -> None:
+ ...
+
+ # img_scale 顺序应该是 (width, height)
+ self.img_scale = img_scale
+
+ def transform(self, results: dict) -> dict:
+ ...
+
+ results['img'] = mosaic_img
+ # (height, width)
+ results['img_shape'] = mosaic_img.shape[:2]
+```
diff --git a/docs/zh_cn/overview.md b/docs/zh_cn/overview.md
index 1515b038b..6856b132f 100644
--- a/docs/zh_cn/overview.md
+++ b/docs/zh_cn/overview.md
@@ -51,8 +51,9 @@ MMYOLO 文件结构和 MMDetection 完全一致。为了能够充分复用 MMDet
5. 参考以下教程深入了解:
- - [数据流](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id1)
+ - [模块组合](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id1)
+ - [数据流](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id2)
- [How to](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#how-to)
- - [插件](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id3)
+ - [插件](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id4)
6. [解读文章和资源汇总](article.md)
diff --git a/docs/zh_cn/user_guides/useful_tools.md b/docs/zh_cn/user_guides/useful_tools.md
index 259854274..56243ed28 100644
--- a/docs/zh_cn/user_guides/useful_tools.md
+++ b/docs/zh_cn/user_guides/useful_tools.md
@@ -75,47 +75,62 @@ python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
### 可视化数据集
-脚本 `tools/analysis_tools/browse_dataset.py` 能够帮助用户去直接窗口可视化 config 配置中数据处理部分,同时可以选择保存可视化图片到指定文件夹内。
-
```shell
-python tools/analysis_tools/browse_dataset.py ${CONFIG} \
- [--out-dir ${OUT_DIR}] \
- [--not-show] \
- [--show-interval ${SHOW_INTERVAL}]
+python tools/analysis_tools/browse_dataset.py \
+ ${CONFIG_FILE} \
+ [-o, --output-dir ${OUTPUT_DIR}] \
+ [-p, --phase ${DATASET_PHASE}] \
+ [-n, --show-number ${NUMBER_IMAGES_DISPLAY}] \
+ [-i, --show-interval ${SHOW_INTERRVAL}] \
+ [-m, --mode ${DISPLAY_MODE}] \
+ [--cfg-options ${CFG_OPTIONS}]
```
-例子:
+**所有参数的说明**:
-1. 使用 `config` 文件 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 可视化图片,图片直接弹出显示,同时保存到目录 `work_dirs/browse_dataset`:
+- `config` : 模型配置文件的路径。
+- `-o, --output-dir`: 保存图片文件夹,如果没有指定,默认为 `'./output'`。
+- **`-p, --phase`**: 可视化数据集的阶段,只能为 `['train', 'val', 'test']` 之一,默认为 `'train'`。
+- **`-n, --show-number`**: 可视化样本数量。如果没有指定,默认展示数据集的所有图片。
+- **`-m, --mode`**: 可视化的模式,只能为 `['original', 'transformed', 'pipeline']` 之一。 默认为 `'transformed'`。
+- `--cfg-options` : 对配置文件的修改,参考[学习配置文件](./config.md)。
```shell
-python tools/analysis_tools/browse_dataset.py 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py' \
- --out-dir 'work_dirs/browse_dataset'
+`-m, --mode` 用于设置可视化的模式,默认设置为 'transformed'。
+- 如果 `--mode` 设置为 'original',则获取原始图片;
+- 如果 `--mode` 设置为 'transformed',则获取预处理后的图片;
+- 如果 `--mode` 设置为 'pipeline',则获得数据流水线所有中间过程图片。
```
-2. 使用 `config` 文件 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 可视化图片,图片直接弹出显示,每张图片持续 `10` 秒,同时保存到目录 `work_dirs/browse_dataset`:
+**示例**:
+
+1. **'original'** 模式 :
```shell
-python tools/analysis_tools/browse_dataset.py 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py' \
- --out-dir 'work_dirs/browse_dataset' \
- --show-interval 10
+python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py --phase val --output-dir tmp --mode original
```
-3. 使用 `config` 文件 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 可视化图片,图片直接弹出显示,每张图片持续 `10` 秒,图片不进行保存:
+- `--phase val`: 可视化验证集, 可简化为 `-p val`;
+- `--output-dir tmp`: 可视化结果保存在 "tmp" 文件夹, 可简化为 `-o tmp`;
+- `--mode original`: 可视化原图, 可简化为 `-m original`;
+- `--show-number 100`: 可视化100张图,可简化为 `-n 100`;
+
+2.**'transformed'** 模式 :
```shell
-python tools/analysis_tools/browse_dataset.py 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py' \
- --show-interval 10
+python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py
```
-4. 使用 `config` 文件 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 可视化图片,图片不直接弹出显示,仅保存到目录 `work_dirs/browse_dataset`:
+3.**'pipeline'** 模式 :
```shell
-python tools/analysis_tools/browse_dataset.py 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py' \
- --out-dir 'work_dirs/browse_dataset' \
- --not-show
+python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py -m pipeline
```
+
+
#### 1.2.2 Neck
+Neck 部分结构仍然在 YOLOv5 基础上进行了模块的改动,同样采用 `RepStageBlock` 或 `BepC3StageBlock` 对原本的 `CSPLayer` 进行了替换,需要注意的是,Neck 中 `Down Sample` 部分仍然使用了 stride=2 的 3×3 `ConvModule`,而不是像 Backbone 一样替换为 `RepVGGBlock`。
+
#### 1.2.3 Head
+不同于传统的 YOLO 系列检测头,YOLOv6 参考了 FCOS 和 YOLOX 中的做法,将分类和回归分支解耦成两个分支进行预测并且去掉了 obj 分支。同时,采用了 hybrid-channel 策略构建了更高效的解耦检测头,将中间 3×3 的 `ConvModule` 减少为 1 个,在维持精度的同时进一步减少了模型耗费,降低了推理延时。此外,需要说明的是,YOLOv6 在 Backobone 和 Neck 部分使用的激活函数是 `ReLU`,而在 Head 部分则使用的是 `SiLU`。
+
+由于 YOLOv6 是解耦输出,分类和 bbox 检测通过不同卷积完成。以 COCO 80 类为例:
+
+- P5 模型在输入为 640x640 分辨率情况下,其 Head 模块输出的 shape 分别为 `(B,4,80,80)`, `(B,80,80,80)`, `(B,4,40,40)`, `(B,80,40,40)`, `(B,4,20,20)`, `(B,80,20,20)`。
+
### 1.3 正负样本匹配策略
YOLOv6 采用的标签匹配策略与 [TOOD](https://arxiv.org/abs/2108.07755)
diff --git a/docs/zh_cn/article.md b/docs/zh_cn/article.md
index 6c999e5cd..706f11d0e 100644
--- a/docs/zh_cn/article.md
+++ b/docs/zh_cn/article.md
@@ -7,18 +7,14 @@
### 文章
- [社区协作,简洁易用,快来开箱新一代 YOLO 系列开源库](https://zhuanlan.zhihu.com/p/575615805)
-
- [MMYOLO 社区倾情贡献,RTMDet 原理社区开发者解读来啦!](https://zhuanlan.zhihu.com/p/569777684)
-
- [玩转 MMYOLO 基础类第一期: 配置文件太复杂?继承用法看不懂?配置全解读来了](https://zhuanlan.zhihu.com/p/577715188)
-
- [玩转 MMYOLO 工具类第一期: 特征图可视化](https://zhuanlan.zhihu.com/p/578141381?)
-
- [玩转 MMYOLO 实用类第二期:源码阅读和调试「必备」技巧文档](https://zhuanlan.zhihu.com/p/580885852)
-
- [玩转 MMYOLO 基础类第二期:工程文件结构简析](https://zhuanlan.zhihu.com/p/584807195)
-
- [玩转 MMYOLO 实用类第二期:10分钟换遍主干网络文档](https://zhuanlan.zhihu.com/p/585641598)
+- [MMYOLO 自定义数据集从标注到部署保姆级教程](https://zhuanlan.zhihu.com/p/595497726)
+- [满足一切需求的 MMYOLO 可视化:测试过程可视化](https://zhuanlan.zhihu.com/p/593179372)
### 视频
diff --git a/docs/zh_cn/get_started.md b/docs/zh_cn/get_started.md
index c1371f379..880942c36 100644
--- a/docs/zh_cn/get_started.md
+++ b/docs/zh_cn/get_started.md
@@ -6,7 +6,8 @@
| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
| :------------: | :----------------------: | :----------------------: | :---------------------: |
-| main | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| main | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
@@ -15,7 +16,7 @@
本节中,我们将演示如何用 PyTorch 准备一个环境。
-MMYOLO 支持在 Linux,Windows 和 macOS 上运行。它需要 Python 3.6 以上,CUDA 9.2 以上和 PyTorch 1.7 以上。
+MMYOLO 支持在 Linux,Windows 和 macOS 上运行。它需要 Python 3.7 以上,CUDA 9.2 以上和 PyTorch 1.7 以上。
```{note}
如果你对 PyTorch 有经验并且已经安装了它,你可以直接跳转到[下一小节](#安装流程)。否则,你可以按照下述步骤进行准备
@@ -54,7 +55,7 @@ conda install pytorch torchvision cpuonly -c pytorch
pip install -U openmim
mim install "mmengine>=0.3.1"
mim install "mmcv>=2.0.0rc1,<2.1.0"
-mim install "mmdet>=3.0.0rc3,<3.1.0"
+mim install "mmdet>=3.0.0rc5,<3.1.0"
```
**注意:**
@@ -144,7 +145,7 @@ inference_detector(model, 'demo/demo.jpg')
- 对于 Ampere 架构的 NVIDIA GPU,例如 GeForce 30 系列 以及 NVIDIA A100,CUDA 11 是必需的。
- 对于更早的 NVIDIA GPU,CUDA 11 是向后兼容 (backward compatible) 的,但 CUDA 10.2 能够提供更好的兼容性,也更加轻量。
-请确保你的 GPU 驱动版本满足最低的版本需求,参阅 NVIDIA 官方的 [CUDA工具箱和相应的驱动版本关系表](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)。
+请确保你的 GPU 驱动版本满足最低的版本需求,参阅 NVIDIA 官方的 [CUDA 工具箱和相应的驱动版本关系表](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)。
```{note}
如果按照我们的最佳实践进行安装,CUDA 运行时库就足够了,因为我们提供相关 CUDA 代码的预编译,不需要进行本地编译。
@@ -214,7 +215,7 @@ pip install "mmcv>=2.0.0rc1" -f https://download.openmmlab.com/mmcv/dist/cu116/t
!pip3 install openmim
!mim install "mmengine==0.1.0"
!mim install "mmcv>=2.0.0rc1,<2.1.0"
-!mim install "mmdet>=3.0.0.rc1"
+!mim install "mmdet>=3.0.0rc5,<3.1.0"
```
**步骤 2.** 使用源码安装 MMYOLO:
@@ -239,7 +240,7 @@ print(mmyolo.__version__)
#### 通过 Docker 使用 MMYOLO
-我们提供了一个 [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/master/docker/Dockerfile) 来构建一个镜像。请确保你的 [docker版本](https://docs.docker.com/engine/install/) >=`19.03`。
+我们提供了一个 [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/master/docker/Dockerfile) 来构建一个镜像。请确保你的 [docker 版本](https://docs.docker.com/engine/install/) >=`19.03`。
温馨提示;国内用户建议取消掉 [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/master/docker/Dockerfile#L19-L20) 里面 `Optional` 后两行的注释,可以获得火箭一般的下载提速:
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index 15bcae2a2..5ce41a6b7 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -57,6 +57,7 @@
notes/faq.md
notes/changelog.md
notes/compatibility.md
+ notes/conventions.md
.. toctree::
:maxdepth: 2
diff --git a/docs/zh_cn/notes/changelog.md b/docs/zh_cn/notes/changelog.md
index ac5df1dc2..7f5a9b3d8 100644
--- a/docs/zh_cn/notes/changelog.md
+++ b/docs/zh_cn/notes/changelog.md
@@ -1,5 +1,72 @@
# 更新日志
+## v0.3.0 (8/1/2023)
+
+### 亮点
+
+1. 实现了 [RTMDet](https://github.com/open-mmlab/mmyolo/blob/dev/configs/rtmdet/README.md) 的快速版本。RTMDet-s 8xA100 训练只需要 14 个小时,训练速度相比原先版本提升 2.6 倍。
+2. 支持 [PPYOLOE](https://github.com/open-mmlab/mmyolo/blob/dev/configs/ppyoloe/README.md) 训练。
+3. 支持 [YOLOv5](https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov5/crowdhuman/yolov5_s-v61_8xb16-300e_ignore_crowdhuman.py) 的 `iscrowd` 属性训练。
+4. 支持 [YOLOv5 正样本分配结果可视化](https://github.com/open-mmlab/mmyolo/blob/dev/projects/assigner_visualization/README.md)
+5. 新增 [YOLOv6 原理和实现全解析文档](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/algorithm_descriptions/yolov6_description.md)
+
+### 新特性
+
+01. 新增 `crowdhuman` 数据集 (#368)
+02. EasyDeploy 中支持 TensorRT 推理 (#377)
+03. 新增 `YOLOX` 结构图描述 (#402)
+04. 新增视频推理脚本 (#392)
+05. EasyDeploy 中支持 `YOLOv7` 部署 (#427)
+06. 支持从 CLI 中的特定检查点恢复训练 (#393)
+07. 将元信息字段设置为小写(#362、#412)
+08. 新增模块组合文档 (#349, #352, #345)
+09. 新增关于如何冻结 backbone 或 neck 权重的文档 (#418)
+10. 在 `how_to.md` 中添加不使用预训练权重的文档 (#404)
+11. 新增关于如何设置随机种子的文档 (#386)
+12. 将 `rtmdet_description.md` 文档翻译成英文 (#353)
+
+### Bug 修复
+
+01. 修复设置 `--class-id-txt` 时输出注释文件中的错误 (#430)
+02. 修复 `YOLOv5` head 中的批量推理错误 (#413)
+03. 修复某些 head 的类型提示(#415、#416、#443)
+04. 修复 expected a non-empty list of Tensors 错误 (#376)
+05. 修复 `YOLOv7` 训练中的设备不一致错误(#397)
+06. 修复 `LetterResize` 中的 `scale_factor` 和 `pad_param` 值 (#387)
+07. 修复 readthedocs 的 docstring 图形渲染错误 (#400)
+08. 修复 `YOLOv6` 从训练到验证时的断言错误 (#378)
+09. 修复 `np.int` 和旧版 builder.py 导致的 CI 错误 (#389)
+10. 修复 MMDeploy 重写器 (#366)
+11. 修复 MMYOLO 单元测试错误 (#351)
+12. 修复 `pad_param` 错误 (#354)
+13. 修复 head 推理两次的错误(#342)
+14. 修复自定义数据集训练 (#428)
+
+### 完善
+
+01. 更新 `useful_tools.md` (#384)
+02. 更新英文版 `custom_dataset.md` (#381)
+03. 重写函数删除上下文参数 (#395)
+04. 弃用 `np.bool` 类型别名 (#396)
+05. 为自定义数据集添加新的视频链接 (#365)
+06. 仅为模型导出 onnx (#361)
+07. 添加 MMYOLO 回归测试 yml (#359)
+08. 更新 `article.md` 中的视频教程 (#350)
+09. 添加部署 demo (#343)
+10. 优化 debug 模式下大图的可视化效果(#346)
+11. 改进 `browse_dataset` 的参数并支持 `RepeatDataset` (#340, #338)
+
+### 视频
+
+1. 发布了 [基于 sahi 的大图推理](https://www.bilibili.com/video/BV1EK411R7Ws/)
+2. 发布了 [自定义数据集从标注到部署保姆级教程](https://www.bilibili.com/video/BV1RG4y137i5)
+
+### 贡献者
+
+总共 28 位开发者参与了本次版本
+
+谢谢 @RangeKing, @PeterH0323, @Nioolek, @triple-Mu, @matrixgame2018, @xin-li-67, @tang576225574, @kitecats, @Seperendity, @diplomatist, @vaew, @wzr-skn, @VoyagerXvoyagerx, @MambaWong, @tianleiSHI, @caj-github, @zhubochao, @lvhan028, @dsghaonan, @lyviva, @yuewangg, @wang-tf, @satuoqaq, @grimoire, @RunningLeon, @hanrui1sensetime, @RangiLyu, @hhaAndroid
+
## v0.2.0(1/12/2022)
### 亮点
diff --git a/docs/zh_cn/notes/compatibility.md b/docs/zh_cn/notes/compatibility.md
index a3ad54d2d..a92521efc 100644
--- a/docs/zh_cn/notes/compatibility.md
+++ b/docs/zh_cn/notes/compatibility.md
@@ -2,6 +2,8 @@
## MMYOLO v0.3.0
+### METAINFO 修改
+
为了和 OpenMMLab 其他仓库统一,将 Dataset 里 `METAINFO` 的所有键从大写改为小写。
| 在 v0.3.0 之前 | v0.3.0 及之后 |
@@ -9,3 +11,37 @@
| CLASSES | classes |
| PALETTE | palette |
| DATASET_TYPE | dataset_type |
+
+### 关于图片 shape 顺序的说明
+
+在 OpenMMLab 2.0 中, 为了与 OpenCV 的输入参数相一致,图片处理 pipeline 中关于图像 shape 的输入参数总是以 `(width, height)` 的顺序排列。
+相反,为了计算方便,经过 pipeline 和 model 的字段的顺序是 `(height, width)`。具体来说在每个数据 pipeline 处理的结果中,字段和它们的值含义如下:
+
+- img_shape: (height, width)
+- ori_shape: (height, width)
+- pad_shape: (height, width)
+- batch_input_shape: (height, width)
+
+以 `Mosaic` 为例,其初始化参数如下所示:
+
+```python
+@TRANSFORMS.register_module()
+class Mosaic(BaseTransform):
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ center_ratio_range: Tuple[float, float] = (0.5, 1.5),
+ bbox_clip_border: bool = True,
+ pad_val: float = 114.0,
+ prob: float = 1.0) -> None:
+ ...
+
+ # img_scale 顺序应该是 (width, height)
+ self.img_scale = img_scale
+
+ def transform(self, results: dict) -> dict:
+ ...
+
+ results['img'] = mosaic_img
+ # (height, width)
+ results['img_shape'] = mosaic_img.shape[:2]
+```
diff --git a/docs/zh_cn/notes/conventions.md b/docs/zh_cn/notes/conventions.md
new file mode 100644
index 000000000..7c2370ffb
--- /dev/null
+++ b/docs/zh_cn/notes/conventions.md
@@ -0,0 +1,37 @@
+# 默认约定
+
+如果你想把 MMYOLO 修改为自己的项目,请遵循下面的约定。
+
+## 关于图片 shape 顺序的说明
+
+在OpenMMLab 2.0中, 为了与 OpenCV 的输入参数相一致,图片处理 pipeline 中关于图像 shape 的输入参数总是以 `(width, height)` 的顺序排列。
+相反,为了计算方便,经过 pipeline 和 model 的字段的顺序是 `(height, width)`。具体来说在每个数据 pipeline 处理的结果中,字段和它们的值含义如下:
+
+- img_shape: (height, width)
+- ori_shape: (height, width)
+- pad_shape: (height, width)
+- batch_input_shape: (height, width)
+
+以 `Mosaic` 为例,其初始化参数如下所示:
+
+```python
+@TRANSFORMS.register_module()
+class Mosaic(BaseTransform):
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ center_ratio_range: Tuple[float, float] = (0.5, 1.5),
+ bbox_clip_border: bool = True,
+ pad_val: float = 114.0,
+ prob: float = 1.0) -> None:
+ ...
+
+ # img_scale 顺序应该是 (width, height)
+ self.img_scale = img_scale
+
+ def transform(self, results: dict) -> dict:
+ ...
+
+ results['img'] = mosaic_img
+ # (height, width)
+ results['img_shape'] = mosaic_img.shape[:2]
+```
diff --git a/docs/zh_cn/overview.md b/docs/zh_cn/overview.md
index 1515b038b..6856b132f 100644
--- a/docs/zh_cn/overview.md
+++ b/docs/zh_cn/overview.md
@@ -51,8 +51,9 @@ MMYOLO 文件结构和 MMDetection 完全一致。为了能够充分复用 MMDet
5. 参考以下教程深入了解:
- - [数据流](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id1)
+ - [模块组合](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id1)
+ - [数据流](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id2)
- [How to](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#how-to)
- - [插件](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id3)
+ - [插件](https://mmyolo.readthedocs.io/zh_CN/latest/advanced_guides/index.html#id4)
6. [解读文章和资源汇总](article.md)
diff --git a/docs/zh_cn/user_guides/useful_tools.md b/docs/zh_cn/user_guides/useful_tools.md
index 259854274..56243ed28 100644
--- a/docs/zh_cn/user_guides/useful_tools.md
+++ b/docs/zh_cn/user_guides/useful_tools.md
@@ -75,47 +75,62 @@ python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
### 可视化数据集
-脚本 `tools/analysis_tools/browse_dataset.py` 能够帮助用户去直接窗口可视化 config 配置中数据处理部分,同时可以选择保存可视化图片到指定文件夹内。
-
```shell
-python tools/analysis_tools/browse_dataset.py ${CONFIG} \
- [--out-dir ${OUT_DIR}] \
- [--not-show] \
- [--show-interval ${SHOW_INTERVAL}]
+python tools/analysis_tools/browse_dataset.py \
+ ${CONFIG_FILE} \
+ [-o, --output-dir ${OUTPUT_DIR}] \
+ [-p, --phase ${DATASET_PHASE}] \
+ [-n, --show-number ${NUMBER_IMAGES_DISPLAY}] \
+ [-i, --show-interval ${SHOW_INTERRVAL}] \
+ [-m, --mode ${DISPLAY_MODE}] \
+ [--cfg-options ${CFG_OPTIONS}]
```
-例子:
+**所有参数的说明**:
-1. 使用 `config` 文件 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 可视化图片,图片直接弹出显示,同时保存到目录 `work_dirs/browse_dataset`:
+- `config` : 模型配置文件的路径。
+- `-o, --output-dir`: 保存图片文件夹,如果没有指定,默认为 `'./output'`。
+- **`-p, --phase`**: 可视化数据集的阶段,只能为 `['train', 'val', 'test']` 之一,默认为 `'train'`。
+- **`-n, --show-number`**: 可视化样本数量。如果没有指定,默认展示数据集的所有图片。
+- **`-m, --mode`**: 可视化的模式,只能为 `['original', 'transformed', 'pipeline']` 之一。 默认为 `'transformed'`。
+- `--cfg-options` : 对配置文件的修改,参考[学习配置文件](./config.md)。
```shell
-python tools/analysis_tools/browse_dataset.py 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py' \
- --out-dir 'work_dirs/browse_dataset'
+`-m, --mode` 用于设置可视化的模式,默认设置为 'transformed'。
+- 如果 `--mode` 设置为 'original',则获取原始图片;
+- 如果 `--mode` 设置为 'transformed',则获取预处理后的图片;
+- 如果 `--mode` 设置为 'pipeline',则获得数据流水线所有中间过程图片。
```
-2. 使用 `config` 文件 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 可视化图片,图片直接弹出显示,每张图片持续 `10` 秒,同时保存到目录 `work_dirs/browse_dataset`:
+**示例**:
+
+1. **'original'** 模式 :
```shell
-python tools/analysis_tools/browse_dataset.py 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py' \
- --out-dir 'work_dirs/browse_dataset' \
- --show-interval 10
+python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py --phase val --output-dir tmp --mode original
```
-3. 使用 `config` 文件 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 可视化图片,图片直接弹出显示,每张图片持续 `10` 秒,图片不进行保存:
+- `--phase val`: 可视化验证集, 可简化为 `-p val`;
+- `--output-dir tmp`: 可视化结果保存在 "tmp" 文件夹, 可简化为 `-o tmp`;
+- `--mode original`: 可视化原图, 可简化为 `-m original`;
+- `--show-number 100`: 可视化100张图,可简化为 `-n 100`;
+
+2.**'transformed'** 模式 :
```shell
-python tools/analysis_tools/browse_dataset.py 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py' \
- --show-interval 10
+python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py
```
-4. 使用 `config` 文件 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 可视化图片,图片不直接弹出显示,仅保存到目录 `work_dirs/browse_dataset`:
+3.**'pipeline'** 模式 :
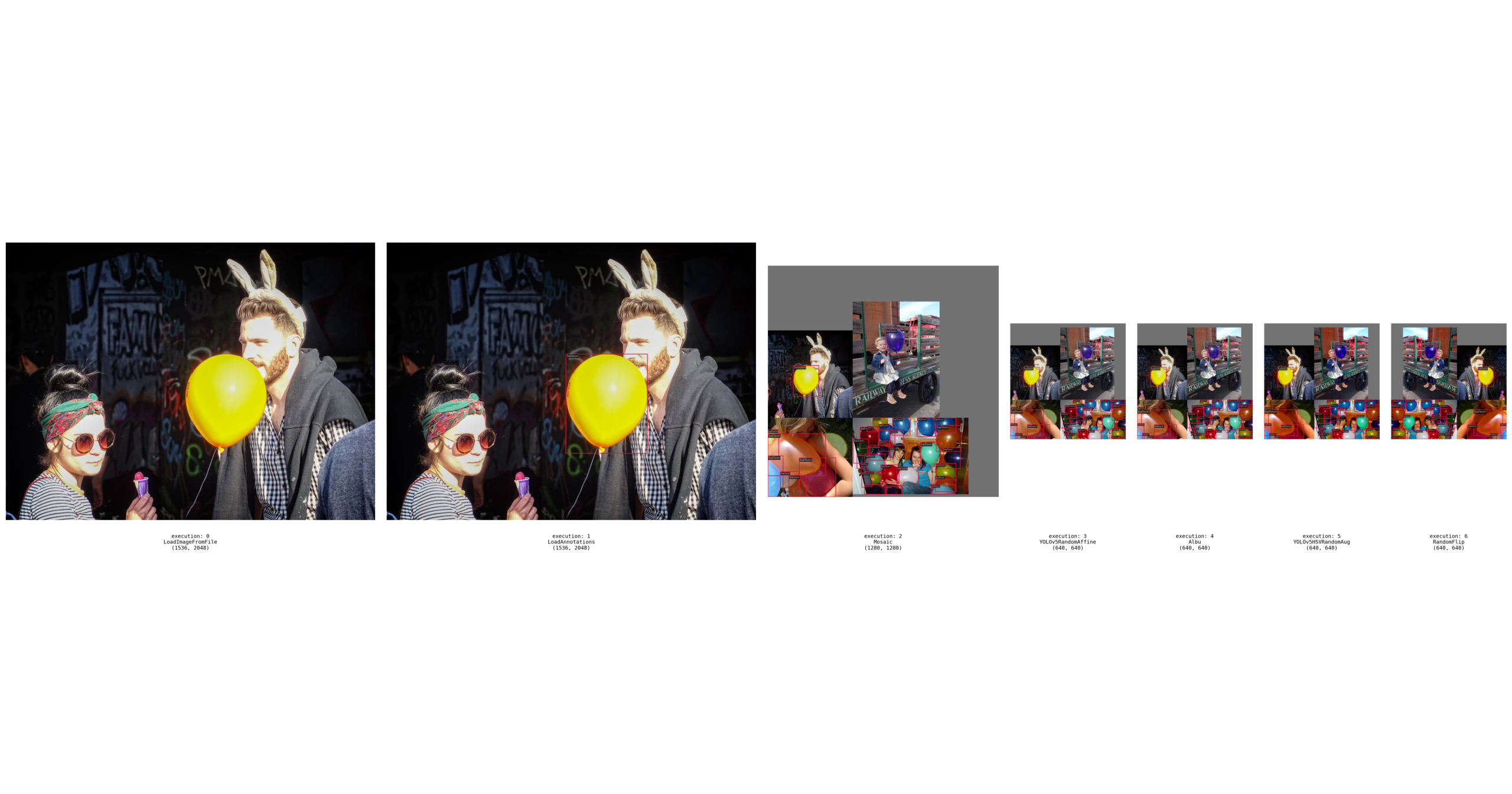
```shell
-python tools/analysis_tools/browse_dataset.py 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py' \
- --out-dir 'work_dirs/browse_dataset' \
- --not-show
+python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py -m pipeline
```
+
+ 
+ |