SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
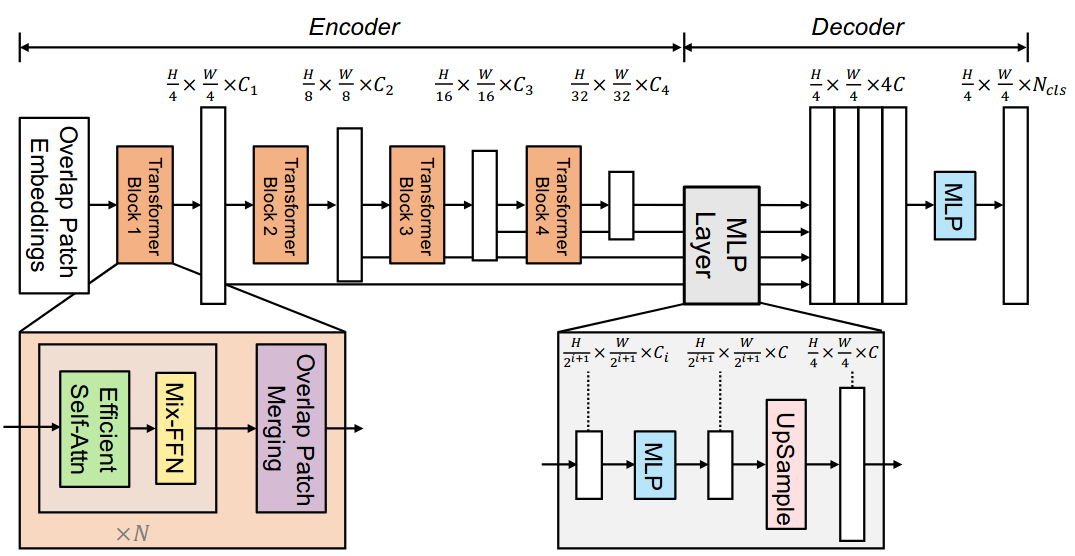
We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding, thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from different layers, and thus combining both local attention and global attention to render powerful representations. We show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters, being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C. Code will be released at: this http URL.
@article{xie2021segformer,
title={SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers},
author={Xie, Enze and Wang, Wenhai and Yu, Zhiding and Anandkumar, Anima and Alvarez, Jose M and Luo, Ping},
journal={arXiv preprint arXiv:2105.15203},
year={2021}
}We have provided pretrained models converted from SegFormer.
If you want to convert keys on your own, we also provide a script mit2mmseg.py in the tools directory to convert the key of models from the official repo to MMSegmentation style.
python tools/model_converters/mit2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}This script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| Segformer | MIT-B0 | 512x512 | 160000 | 2.1 | 38.17 | 37.85 | 38.97 | config | model | log |
| Segformer | MIT-B1 | 512x512 | 160000 | 2.6 | 37.80 | 42.13 | 43.74 | config | model | log |
| Segformer | MIT-B2 | 512x512 | 160000 | 3.6 | 26.80 | 46.80 | 48.12 | config | model | log |
| Segformer | MIT-B3 | 512x512 | 160000 | 4.8 | 19.19 | 48.25 | 49.58 | config | model | log |
| Segformer | MIT-B4 | 512x512 | 160000 | 6.1 | 14.54 | 49.09 | 50.72 | config | model | log |
| Segformer | MIT-B5 | 512x512 | 160000 | 7.2 | 11.89 | 49.13 | 50.22 | config | model | log |
| Segformer | MIT-B5 | 640x640 | 160000 | 11.5 | 10.60 | 50.19 | 51.41 | config | model | log |
Evaluation with AlignedResize:
| Method | Backbone | Crop Size | Lr schd | mIoU | mIoU(ms+flip) |
|---|---|---|---|---|---|
| Segformer | MIT-B0 | 512x512 | 160000 | 38.55 | 39.03 |
| Segformer | MIT-B1 | 512x512 | 160000 | 43.26 | 44.11 |
| Segformer | MIT-B2 | 512x512 | 160000 | 47.46 | 48.16 |
| Segformer | MIT-B3 | 512x512 | 160000 | 49.27 | 49.94 |
| Segformer | MIT-B4 | 512x512 | 160000 | 50.23 | 51.10 |
| Segformer | MIT-B5 | 512x512 | 160000 | 50.08 | 50.72 |
| Segformer | MIT-B5 | 640x640 | 160000 | 51.13 | 51.66 |
The lower fps result is caused by the sliding window inference scheme (window size:1024x1024).
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| Segformer | MIT-B0 | 1024x1024 | 160000 | 3.64 | 4.74 | 76.54 | 78.22 | config | model | log |
| Segformer | MIT-B1 | 1024x1024 | 160000 | 4.49 | 4.3 | 78.56 | 79.73 | config | model | log |
| Segformer | MIT-B2 | 1024x1024 | 160000 | 7.42 | 3.36 | 81.08 | 82.18 | config | model | log |
| Segformer | MIT-B3 | 1024x1024 | 160000 | 10.86 | 2.53 | 81.94 | 83.14 | config | model | log |
| Segformer | MIT-B4 | 1024x1024 | 160000 | 15.07 | 1.88 | 81.89 | 83.38 | config | model | log |
| Segformer | MIT-B5 | 1024x1024 | 160000 | 18.00 | 1.39 | 82.25 | 83.48 | config | model | log |
Note:
Original SegFormer paper uses different test_pipeline and image ratios in ms+flip. If you want to cite SegFormer original results as benchmark you may modify settings as below:
- We replace
AlignedResizein original implementation toResize + ResizeToMultiple. If you want to test by usingAlignedResize, you can change the dataset pipeline like this:
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
# resize image to multiple of 32, improve SegFormer by 0.5-1.0 mIoU.
dict(type='ResizeToMultiple', size_divisor=32),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]- Different from default setting of
ms+flip, SegFormer original repo adopts different image ratios for ADE20K dataset. To re-implement numerical results ofms+flip, you can change image ratios intools/test.pylike this:
if args.aug_test:
if cfg.data.test.type == 'ADE20KDataset':
# hard code index
cfg.data.test.pipeline[1].img_ratios = [
0.75, 0.875, 1.0, 1.125, 1.25
]