You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Major Compaction是较为重量级的Compaction,负责将Level N中越出阈值的SSTable与Level N+1中相同数据范围内的SSTable进行合并,减少数据空间占用。
Major Compaction是LevelDB中最为复杂的操作之一,是LSM中第一道较为复杂的操作。
KipDB中Major Compaction的大体步骤为
目前Major压缩的大体步骤是
reacted with thumbs up emoji reacted with thumbs down emoji reacted with laugh emoji reacted with hooray emoji reacted with confused emoji reacted with heart emoji reacted with rocket emoji reacted with eyes emoji
-
Leveled Compaction层次结构
LevelDB中Leveled Compaction的LSM实现是由不同层级且虽等级逐步递增而以10的N次方逐级递增的SSTables组成。(类似金字塔)
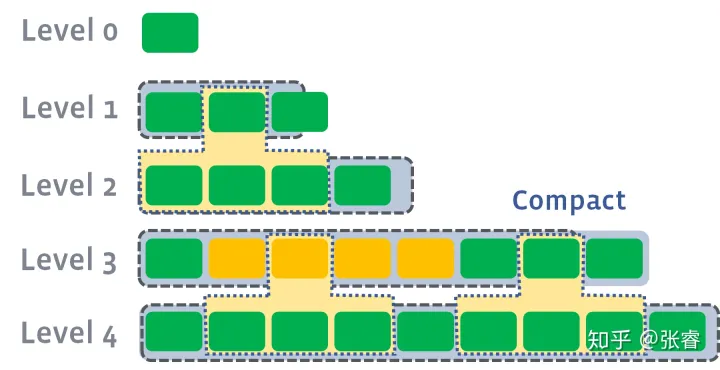
同时除了Level 0外,其余Level内的SSTables的数据排布彼此连续且有序,但不同Level之间的数据则是交错且重复的,及上一层Level的数据为下一层Level更稀疏的数据范围
Leveled Compaction排列有序的结构非常适合于读多写少的场景。
数据读取时,通过类似二分的方式(以SSTable的min/max key),可以直接确定数据可能存在的SSTable。
因此即使是大量数据的情况下(数据根据图上排布,使其充分形成金字塔型的排列),也仅仅需要读取 10(Level 0) + 6 x 1(Level N)个SSTable即可查询到对应的数据。
Size-tired Compaction则会查询所有SSTable数据范围重复。。。读放大和空间放大直接爆炸
Leveled Compaction Level 0 的性能瓶颈
上述的Level 0的SSTable排布中,一直有Level 0除外的备注。
而Level 0作为MemTable到SSTables的缓冲层,导致Level 0中的SSTable是数据范围交错且非有序的,因此读取时需要读取所有的Level 0SSTable才能获取到对应Key的数据。
Level 0在Leveled Compaction中起着非常关键的作用;
Leveled Compaction分为两级Compaction
Minor Compaction
Minor Compaction是轻量级的Compaction,主要将MemTable中的数据转移至Level 0中作为SSTable。
Minor Compaction将MemTable(内存缓冲数据)批量的写入硬盘,这也就是LSM写入性能较高的关键
Q: 为什么Level 0不与其他Level对齐,形成排布有序SSTable
A: 如果Level 0需要保持数据有序,那么实际已经类似Major Compaction造成比较严重的写放大,即每次Minor Compaction时都需要像Major Compactoin中一致需要读取Next Level交错范围的SSTable
而又因为MemTable中的数据是随机性较强的,非常容易导致数据范围过大而可能造成Next Level有非常多数量的SSTable与这个MemTable的数据范围重合,而造成每次Minor Compaction甚至可能造成比常规Major Compaction更大的写放大
(本身Minor Compaction造成Major Compaction时,有几率造成多Level的连锁Compaction而导致比较严重的写放大,这是Leveled Compaction造成的写放大问题之一)
因此这会导致更加严重的读放大问题
Major Compaction
Major Compaction是较为重量级的Compaction,负责将Level N中越出阈值的SSTable与Level N+1中相同数据范围内的SSTable进行合并,减少数据空间占用。
Major Compaction是LevelDB中最为复杂的操作之一,是LSM中第一道较为复杂的操作。
KipDB中Major Compaction的大体步骤为
目前Major压缩的大体步骤是
经过压缩测试,Level 1的SSTable总是较多,根据原理推断:
Level0的Key基本是无序的,容易生成大量的SSTable至Level1
而Level1-7的Key排布有序,故转移至下一层的SSTable数量较小
因此大量数据压缩的情况下Level 1的SSTable数量会较多
这也变相说明,每次Level 0中每次发生Major Compaction时,大多数Level 0 SSTable都会转移到Level 1中,此处容易造成较为大量的写放大
WAL-assisted Tiering: Painlessly Improving Your Favorite Log-Structured KV Store Instead of Building a New One | The International Symposium on Memory Systems
其中该论文的结论也基本验证了低Level使用内存进行优化时,可以减少至多50%以上的写流量
同时由于Level 0读取时几乎需要加载全量的SSTable(Tips: 加载SSTable并非为全量的SSTable数据加载,后继SSTable结构会延申其加载流程)
即使FilterBlock命中率较高,甚至是全命中的情况,仍然要加载SSTable本身的Meta信息(对于RocksDB来说,64MB的SSTable也会造成本身的Meta内容占比也绝对不会少)
同时Level 0的Major Compaction也会使多数Level 0 SSTable合并到下层,这也将进一步加剧了Level 0造成的读放大与写放大问题
这是Leveled Compaction结构中一项非常明显容易造成性能问题的地方,实际上有诸多论文针对Level 0进行优化:
MatrixKV: Reducing Write Stalls in LSM-tree
KipDB决定使用更为简单,但较为有效的方式进行优化:
将Level 0的SSTable使用IoType::Mem作为其Reader和Writer
Level 0 memorization by KKould · Pull Request #25 · KipData/KipDB
站在该PR的视角下,使用内存类型进行SSTable的存储是不充分的。
因为SSTable是Block-Based的,甚至对于内存类型来说,IndexBlock的稀疏索引与FilterBlock的查询过滤带来的效果是低于硬盘持久化的SSTable的。(因为Block的设计涉及到前缀压缩以及本身的数据压缩、编解码、以及为了减少查询IO而构造的IndexBlock二级索引)
SSTable结构解析
SSTable
拓展性SSTable示例:KipDB的SkipTable
站在Level 0的内存化场景去使用SSTable会发现其主要面向场景主要为硬盘,在内存场景下表现并不如,更简单的存储结构的内存占用更低并且不需要前缀拼接以及Block解压:SkipList(复用MemTable数据结构)
实际上,对SSTable进行抽象改造的案例是存在的,比如:
论文思路猜想:UniKV
ToplingZipTable
这些案例说明了不同Level是存在有不同的WorkLoad的,以最极端的两个Level 0与Level 6举例:
KipDB中目前抽象了Table并基于SkipList实现了SkipList用于Level 0中,充分利用SkipList在内存中高性能的效果
Feat/table multiple implementations by KKould · Pull Request #28 · KipData/KipDB
Beta Was this translation helpful? Give feedback.
All reactions