Toward Explainable and Fine-Grained 3D Grounding through Referring Textual Phrases [Arxiv] [Project]

Recent progress in 3D scene understanding has explored visual grounding (3DVG) to localize a target object through a language description. However, existing methods only consider the dependency between the entire sentence and the target object, ignoring fine-grained relationships between contexts and non-target ones. In this paper, we extend 3DVG to a more fine-grained and interpretable task, called 3D Phrase Aware Grounding (3DPAG). The 3DPAG task aims to localize the target objects in a 3D scene by explicitly identifying all phrase-related objects and then conducting the reasoning according to contextual phrases. To tackle this problem, we manually labeled about {227K phrase-level annotations} using a self-developed platform, from 88K sentences of widely used 3DVG datasets, i.e., Nr3D, Sr3D and ScanRefer. By tapping on our datasets, we can extend previous 3DVG methods to the fine-grained phrase-aware scenario. It is achieved through the proposed novel phrase-object alignment optimization and phrase-specific pre-training, boosting conventional 3DVG performance as well. Extensive results confirm significant improvements, i.e., previous state-of-the-art method achieves 3.9%, 3.5% and 4.6% overall accuracy gains on Nr3D, Sr3D and ScanRefer respectively.
We provide the phrase-level annotations for Nr3D, Sr3D and ScanRefer. The annotations are stored in the json format under the data folder. Each json file contains the annotations for one dataset. The format of the json file is as follows:
{
"scene_id": "scene0000_00", # scene id in ScanNet
"object_id": "2", # object id in ScanNet
"ann_id": "0", # annotation id
"description": "this is a long table. it is facing four bar stools.", # description
"position_start": "35", # phrase start pos
"position_end": "49", # phrase end pos
"labeled_id": "30", # object id of phrase
"labeled_phrase": "four bar stools", # phrase
"is_sure": 1 # confidence of annotation
},The annotation platform is under platform folder.
We build based on ScanRefer_Browser.
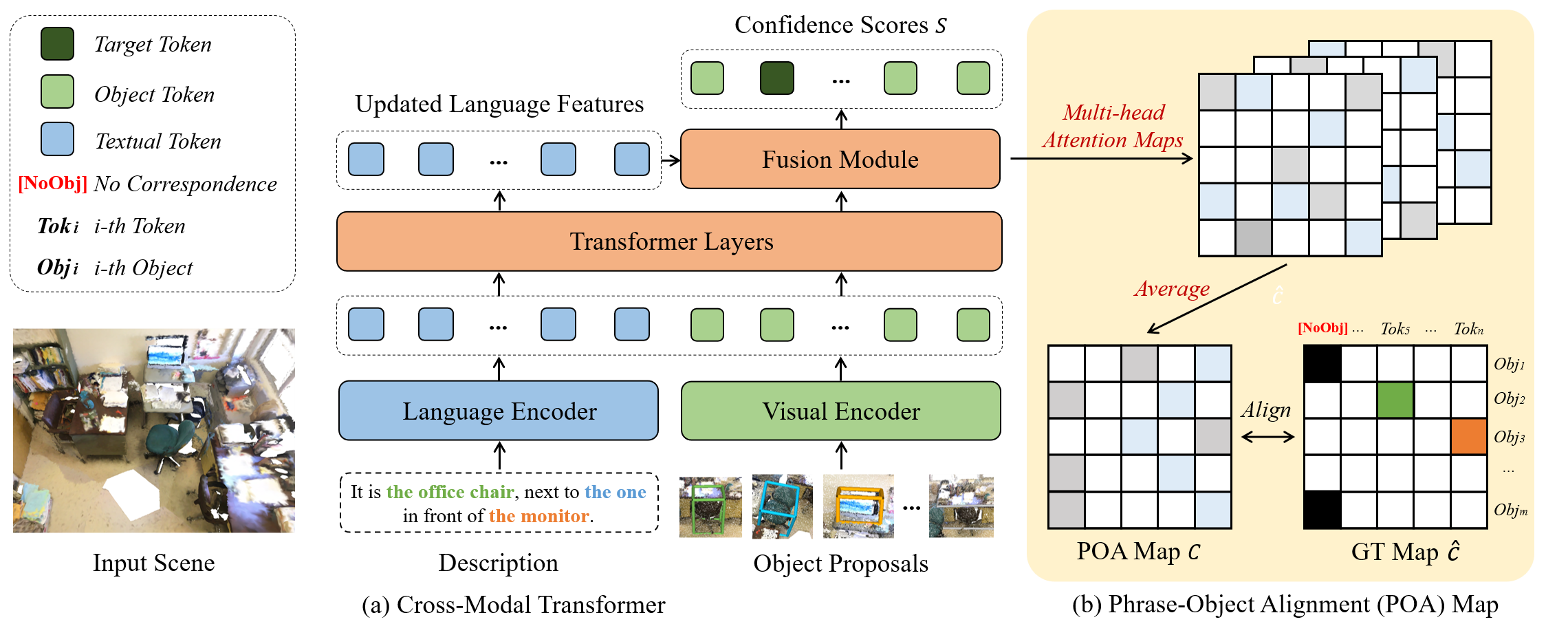
Part (a) illustrates our baseline model, i.e., cross-modal transformer, and part (b) shows the process of optimizing the phrase-object alignment map.
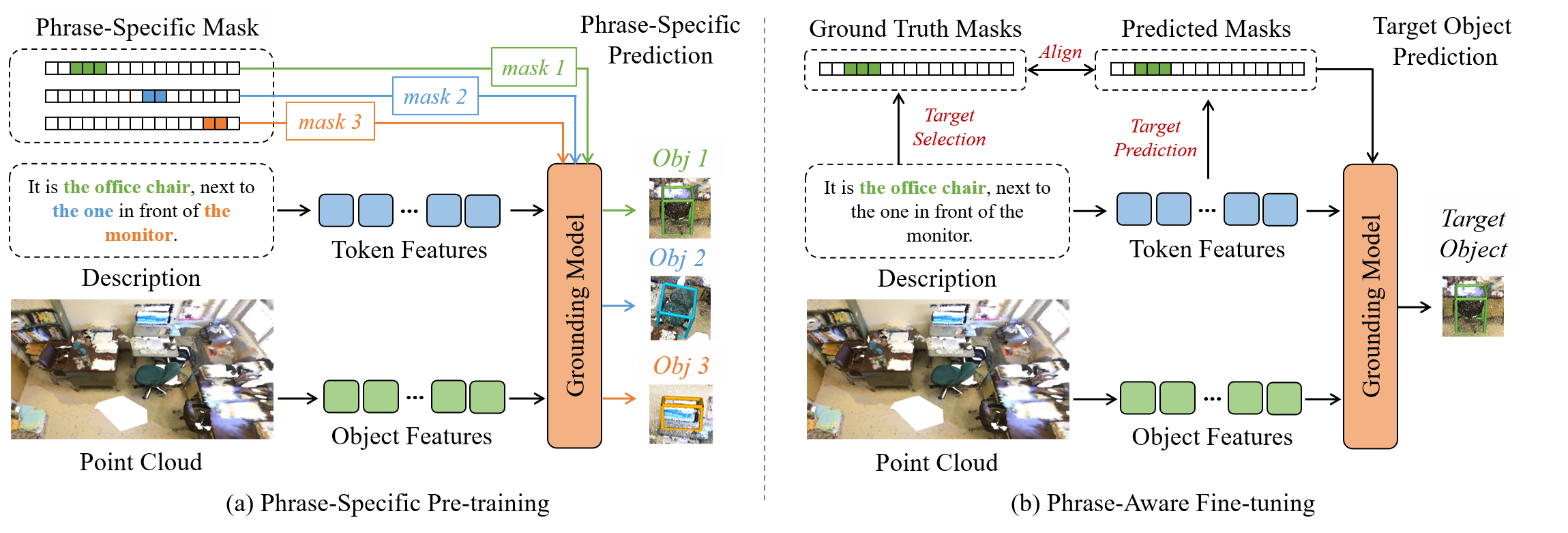
In the phrase-specific pre-training stage, we generate the phrase-specific masks according to the grounding truth phrases, e.g., setting the position of “the office chair” to 1 and other positions to 0. Then, we design the network to predict the corresponding object of the selected phrase. During the fine-tuning stage, we only predict the target object referred by the whole sentence.
We visualize the visual grounding results of SAT and ours. The left four examples are our correct predictions while SAT is not. The right two examples show the representative failures for both current SOTA model SAT and our PhraseRefer. The green/red/blue colors illustrate the correct/incorrect/GT boxes. The target class for each query is shown in red color. We provide rendered scenes in the first row for better visualization. Best viewed in color.

We show examples of 3DPAG prediction and POA map of our method.The corresponding phrase and bounding box are drawn in the same color. Best viewed in color.

If you find our work helpful, please consider citing
@article{yuan2022toward,
title={Toward Explainable and Fine-Grained 3D Grounding through Referring Textual Phrases},
author={Yuan, Zhihao and Yan, Xu and Li, Zhuo and Li, Xuhao and Guo, Yao and Cui, Shuguang and Li, Zhen},
journal={arXiv preprint arXiv:2207.01821},
year={2022}
}